抗遮挡的单目深度估计算法
2021-01-22马成齐李学华张兰杰
马成齐,李学华,张兰杰,向 维,2
1.北京信息科技大学 信息与通信工程学院,北京100101
2.詹姆斯库克大学 工程学院,昆士兰 凯恩斯4878
近年来,随着深度学习技术的迅速发展,产生了越来越多的智能化技术。例如与深度估计有着密切联系的图像编辑、VR(Virtual Reality)、AR(Augmented Reality)、3D场景解析和自动驾驶技术等。在深度学习技术问世之前,利用普通相机只能捕获场景的二维平面信息,无法获取到场景中的深度值。虽然通过使用多个摄像头以及激光和雷达设备,能够获取到深度信息,但激光和雷达不能完美地与相机对准,会导致测量的深度值产生误差。因此,有学者开始采用深度学习技术替代传统的激光雷达,在获取深度信息的同时节约了成本。
使用深度学习技术进行单目深度估计可分为监督型和自监督型。在监督型单目深度估计中,较为经典的是Eigen 和Fergus[1]设计的一个包含粗糙网络和细化网络的系统。该系统中的粗糙网络用于对图像做全局预测,细化网络用于对全局预测的结果进行局部优化,整个网络采用了较早的AlexNet 架构。2015 年,Eigen 和Fergus[2]改进了上述系统,在原有的两个网络中增加了一个采样网络,加深了网络结构,同时将AlexNet架构更换为层数更深的VGG 架构,使得输出的深度图与使用AlexNet架构相比更为清晰。2018年,Fu等人[3]提出了编码解码深度估计网络,采用洞卷积型网络来更好地提取图像的多尺度特征,相比以往的监督型方法,输出的深度图分辨率更高。以上监督型方法在训练过程中都需要地面真实深度,即需要大量密集标注后的数据集。但在实际中,数据集的深度信息标签普遍是稀疏的,采用监督型单目深度估计不能较好地对场景进行密集估计。
不同于监督型方法,自监督方法在网络输入部分使用的是左右两个相机在同一水平位置上拍摄出的图像[4](即同步立体对),或者单目视频[5]中相邻帧组合的一组图像。采用自监督方法进行单目深度估计,较为经典的是Zhou等人[6]设计的系统,该系统把未作任何标记的单目视频中的每一帧图像都作为训练集,使用深度估计网络和相机位姿网络对上述训练集进行训练。之后采用视图合成方法,将深度网络估计出的深度信息与相机位姿网络结合,恢复出与目标图像相邻的另一幅图像。最后将恢复出的图像与目标图像做差,通过最小化损失函数使网络收敛。Godard[4]则采用同步立体对图像作为训练集,利用图像重建损失对深度网络进行训练,输出视差图,之后与目标图像相结合,得到估计的深度图,进一步提升了准确率。Mahjourian等人[7]提出了一种将场景中的三维损失与单目视频中的二维损失结合的方法,同时结合掩码将无用的信息去除,最终得到了较好的深度图。但由于现有数据集存在物体间遮挡以及物体运动问题,采用自监督方法估计出的深度图都会存在伪影。
为了解决以上问题,本文提出了一种抗遮挡的自监督单目深度估计方法。主要贡献如下:(1)提出了一种新颖的网络架构,将U-Net[8]架构与残差网络(Residual Network,ResNet)[9]融合,并且保证了输入和输出的图像分辨率一致。(2)使用最小化光度重投影损失函数与自动掩蔽损失来处理物体被遮挡的问题,使估计出的深度图更加清晰,减少了边界伪影。(3)基于KITTI数据集[10],验证了本文方法的有效性,相比于文献[4,11-13]中提到的四种方法,本文方法呈现了较好的估计结果。
1 自监督深度估计网络模型
本章将从深度网络模型的构造及损失函数的选择来介绍本文提出的自监督单目深度估计方法。
1.1 深度网络结构
本文的网络架构采用了深度网络和相机位姿网络协同工作的架构。其中,深度网络使用U-Net 和ResNet34 相融合的编码、解码架构,输入为某时刻的单帧图像;位姿网络的编码器和深度网络相同,输入为三帧相邻时刻的图像。网络的损失函数由光度重投影和边缘感知平滑函数两部分构成。其中,最小化光度重投影函数结合了自动掩蔽损失,用于解决物体遮挡和运动带来的影响。本文网络架构如图1所示。
1.1.1 U-Net架构
U-Net 网络架构是一种轻量级的全卷积神经网络,可以分为两个部分:收缩路径对应的是编码器部分,而扩展路径对应的是解码器部分。在收缩路径中,通过池化层将特征通道的数量加倍,同时考虑到卷积会导致边界像素的损失,该网络进行了适当的剪裁。相反,在扩展路径中,通过上采样将特征通道数量减半,最后与收缩路径中经过剪裁后的特征图进行连接。图2 给出了U-Net架构示意图。

图2 U-Net结构图
本文使用的KITTI数据集涉及市区、乡村和高速公路等场景采集的真实图像,包含内容较多。每张图像中的车辆最多可达15辆,行人最多可达30个,且会出现不同程度的遮挡与截断问题。如果采用普通深度网络对KITTI 数据集进行训练,随着网络层数的加深,预测的准确率将呈现先上升,后饱和再下降的趋势。因此,为了更加准确地提取图像中的深度信息,将ResNet34 与U-Net 网络融合,使用ResNet34 网络参数作为U-Net 架构中的编码器部分,解决了随着网络层数的加深,出现预测准确率下降以及梯度消失和爆炸的问题。
1.1.2 ResNet34结构
ResNet34的结构图如图3所示,每两个卷积块组成一个building block,结构为:Conv(3×3)-BN-ReLUConv(3×3)-BN,其中BN(Batch Normalization)层为批量归一化层。在整个模型中,每个卷积核卷积步长皆为2,卷积核的输出部分统一采用了ReLU激活函数。
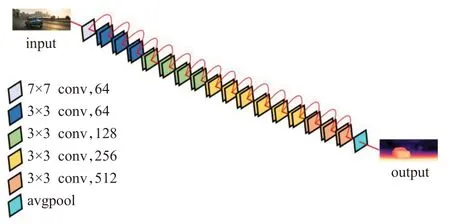
图3 ResNet34结构图
与编码器对应,深度网络的解码器部分采用了步长为1,大小为3×3的卷积核,具体信息如表1所示。为了更好地减少深度图中的伪影,本文将解码器中采用的补零填充方式更换为了反射填充。该方法在样本处于图像边界之外时,能够返回原图像中与边界像素相似的值。

表1 解码器信息
整个深度网络的设计可以防止在对目标进行深度估计和图像重建时,训练目标陷入局部最小值。同时,编解码的结构能够保证输入图像和输出图像分辨率一致。但采用单目视频中的帧序列进行深度估计时,无法保证拍摄每帧图像时的相机位姿是一致的,因此本文加入了相机位姿网络。
1.2 位姿网络结构
Godard[4]设计的自监督方法,采用同步立体对进行训练,会导致相机位姿估计只能进行一次离线矫正,无法考虑每个时刻相机位姿以及物体间的遮挡所带来的影响。因此,本文在训练网络时采用了单目视频中的连续帧作为输入,在对图像深度进行估计的同时,还需要估计单目视频中帧与帧之间的摄像机姿态。通过姿态估计约束深度网络,实现从帧序列中的某一幅图像预测出与其相邻的另一帧图像,同时采用最小化光度重投影来处理遮挡问题,采用自动掩蔽损失处理运动带来的伪影问题。
位姿网络采用了与深度网络相同的结构设计,编码器部分仍然采用标准的ResNet34,解码器部分的所有卷积核以及输出部分统一采用了ReLU函数。
1.3 损失函数
本文使用的损失函数是两个部分的加权,即结合了自动掩蔽损失的光度重投影误差函数和边缘感知平滑函数。其中,最小化光度重投影用来处理物体遮挡问题,而自动掩蔽损失用来处理运动带来的伪影问题。
1.3.1 最小化光度重投影函数
自监督单目深度估计通过训练网络从一幅图像的视觉角度预测目标图像的出现,通过深度网络和相机位姿网络以及损失函数来执行目标图像的合成。但在新建视图时存在一个问题,即每个像素可能存在多个不正确的深度,会导致最终的深度图出现模糊以及伪影。本文将这一问题转化为训练时光度重投影误差的最小化。其中光度重投影误差Lp表达式为:

式中,It为目标图像,It′为源视图,pe 为光度重投影误差,由L1和SSIM组成,表达式为:
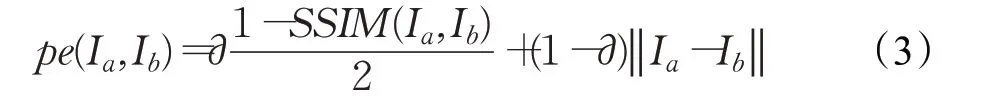
其中,损失函数L1 用于将目标图像中的像素值与估计图像中的像素值做差,并取绝对值。损失函数SSIM(Structural Similarity index)用于衡量目标图像与估计图像的相似度。Tt→t′表示每个源视图相对于目标图像的相机姿态。在单目训练中,通常采用与目标图像相邻的两帧图像作为输入,该输入方式可能会使目标图像的前一帧和后一帧像素之间存在遮挡和去遮挡问题。当损失函数迫使网络去匹配这些像素时,将会包含被遮挡的像素,导致最终的深度图出现伪影,估计效果较差。
本文采用最小化光度重投影误差替代原有的光度重投影误差,表达式为:

即在每个进行匹配的像素处,取光度重投影误差的最小值作为投影误差,而不是原有的对光度重投影误差取平均值,有效降低了投影误差,从而减少了深度图中的伪影,具体实现方式如图4所示。
1.3.2 自动掩蔽损失
自监督单目深度估计采用的KITTI 数据集是假定场景为静态情况下,运动的摄像机拍摄的街道物体图像。因此,如果场景中存在移动物体,或者有物体与摄像机保持了相对静止,都会对预测的深度图产生很大影响。该问题可以理解为对于运动的物体,自监督单目深度估计方法预测出的深度图将存在无限深度的洞[11]。本文采用自动掩蔽损失[14]来处理该问题,函数表达式为:
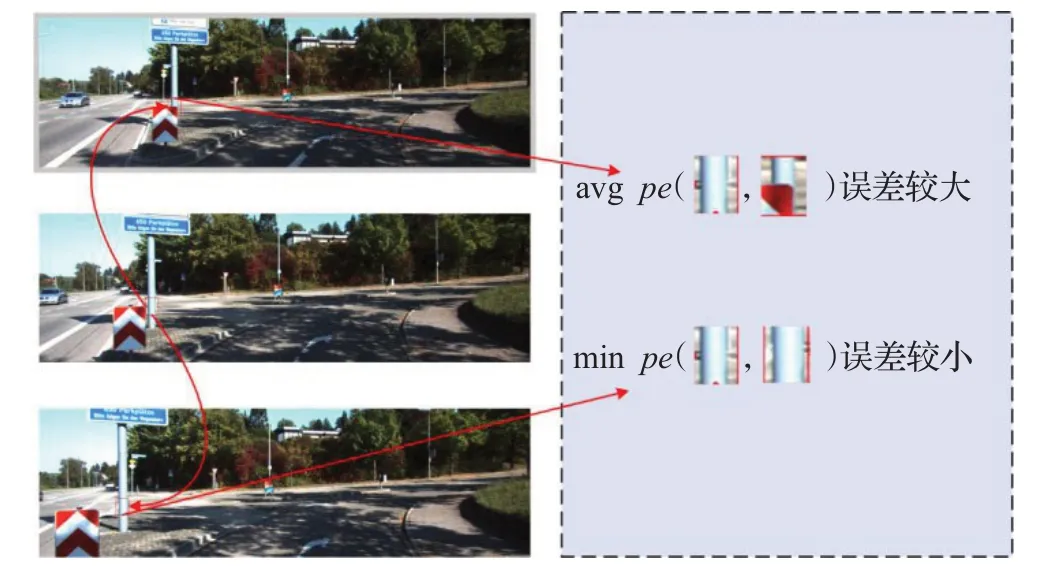
图4 外观损失图

自动掩蔽损失函数会过滤掉从当前某一个帧序列到下一个帧序列中不改变外观的物体,进而使深度网络过滤掉和摄像机具有相同速度的物体。[]为艾弗森括号,当括号内的条件满足时,μ 的值为1,不满足则μ 为0。由于未经过形变的源图像It′ 的重投影误差要低于经过形变的图像It′→t的误差,因此使用μ 来忽略原始的光度重投影误差像素损失。
1.3.3 边缘感知平滑函数
最后,结合使用边缘感知平滑函数Ls,表达式为:

由于深度不连续的问题一般会发生在图像的梯度上,因此对视差梯度增加了L1惩罚项,用于预测出较为平滑的视差。
最终,本文提出的深度估计网络模型的损失函数为:

其中,λ 为常数,取值为0.001,光度重投影误差中的∂取值为0.85。其中∂和λ 的取值参考了Godard[4]的设置,该取值是目前最常用的最佳参数设置,Lp为SSIM与L1的组合。
2 实验过程及结果分析
本章采用本文的深度估计网络模型对KITTI 数据集进行深度估计,并对结果进行分析,同时与目前四种单目深度估计模型算法在同一个场景下进行了对比。
2.1 KITTI数据集
本次实验选用的KITTI数据集,是当前最大的自动驾驶场景下的计算机视觉算法测评数据集,包含了城市、住宅、道路、校园和行人。使用整个raw data的数据对网络进行训练以及测试,其中每张图像的分辨率为1 242×375。
2.2 实验步骤
本文在单目深度训练中使用了相邻三帧图像的序列长度,以50%的几率对输入图像进行了水平翻转以及范围统一为±0.1 的随机亮度、对比度、饱和度和色调的抖动,相机位姿网络也采用上述操作。在对输入数据进行训练时,本模型使用Adam 算法[15]替代传统的随机梯度下降(Stochastic Gradient Descent,SGD)算法,可以更高效地更新深度网络中的权重。训练周期为20 个,每个周期的批处理数量为12。由于采用了U-Net 对称性网络架构,输入及输出的图像分辨率均为1 242×375。在训练的前15 个周期使用了1×10-4的学习率,在后面的5 个周期中将学习率降低为1×10-5。训练使用的服务器CPU为E5-2650 v4,GPU为NVIDIA TITAN V,系统为Ubuntu16.04.6。整个输入输出网络采用Pytorch搭建,训练时间为30个小时。
与以往单目深度估计算法类似,本文也使用Eigen[2]的数据拆分方法对KITTI数据集进行了拆分,拆分后的39 810张图像用于训练,4 424张图像用于验证,同时将相机的中心点设置为图像的中心点,相机的焦距设置为KITTI 数据集中所有焦距的平均值。为了便于和以往方法进行对比,在测试结果中,按照标准的对比方法将深度限制在80 m范围。
2.3 实验结果与分析
本节重点对比了本文的单目深度估计算法与其他作者的单目深度估计算法的估计结果。为了更加清晰准确地对结果进行比较,测试时采用了相同的道路场景。
2.3.1 算法结果
图5给出了本文结果与Godard[4]、Luo等人[11]、Ranjan等人[12]以及Yin等人[13]的方法对比效果图。从图5 可以看出,相比其他四种方法,本文的单目深度估计算法在场景图a中可以清晰地显示出行人和远处车辆的轮廓,而其他方法所估计出的行人较为模糊,或者存在深度值不统一及颜色不一致。在场景图b中,对于街道中被立柱遮挡的汽车,本文算法也可以显示出其轮廓,且立柱的显示效果好于其他四种算法。从场景图c中可以看出,和其他四种算法相比,只有本文算法可以清晰地显示被行人遮挡的立柱。

图5 实验结果对比图
图6给出了未加入任何优化组件、加入自动掩蔽损失单独组件、加入最小化光度重投影误差单独组件,以及同时加入自动掩蔽损失和最小化光度重投影误差两个组件的效果图。从图中可以看出,当未加入最小化光度重投影和自动掩蔽损失时,估计的深度图效果较为模糊,存在伪影,同时远方的无限深度出现洞,而且运动物体较为模糊。例如场景图a 中,行人在一个固定位置时,估计出的整个行人的深度图像素值不统一,存在一定误差,同时远处行驶的汽车也未显示出来。场景图b中,正前方有大面积无限深度的洞,同时左侧的立柱由于遮挡也没有清晰显示出来。场景图c中,被行人遮挡的立柱显示较为模糊,存在伪影。
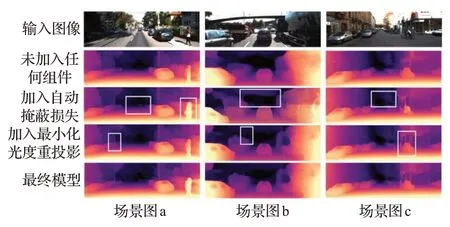
图6 组件对比实验图
当单独加入自动掩蔽损失后,场景图a中远方运动的汽车可以估计出清晰的效果,同时右侧运动的行人深度值统一,颜色一致。场景图b 中,正前方无限深度的洞明显减弱,画面有了分割。场景图c和场景图b相似,洞的效果也明显减弱。
当单独加入最小化光度重投影组件后,在场景图a中,左侧的树木枝干可以估计出清晰效果。在场景图b中,前方被遮挡的立柱也可以估计出较为清晰的效果。在场景图c 中,效果更加明显,被行人遮挡的立柱也可以清晰看出估计结果。
最终将自动掩蔽损失和最小化光度重投影误差两个组件同时加入到网络模型中后,估计出的效果得到了进一步提升,被遮挡的立柱以及运动的车辆及行人整体同时都呈现出较为清晰的估计结果,正前方无限深度画面边界分割更加细致。
为了对比本文算法在不同遮挡下的效果,图7给出了KITTI 数据集(场景a)以及数据集之外的两组场景(场景b和c)的效果图。从图中可知,对于场景a中的单一物体车辆、树木以及低纹理区域,并且遮挡物体和被遮挡物体之间存在一定距离时,本文算法的估计效果较好。对于在场景b 中,树木上方的枝干繁多,分布较为密集,本文方法的估计效果有所下降,但对于距离较远的低纹理区域,如下方枝干,依然可以估计出清晰的效果图。在场景c 中,由于房屋右侧被密集的树叶遮挡,估计效果也有所下降。因此,本文方法对于所拍摄的街道和公路中的行人、车辆等这种运动物体间造成的单一遮挡有较好效果。

图7 遮挡对比实验图
2.3.2 算法性能分析
与标准差(Standard Deviation)和平均绝对误差(Mean Absolute Error,MAE)相比,均方根误差(Root Mean Square Error,RMSE)对深度图中的异常值更加敏感。因此,本实验选取了RMSE函数和平方绝对误差(Square Relative error,Sq Rel)函数作为网络模型算法的评估指标,表达式分别为:

其中,ypred表示估计出的深度图,而ygt表示地面真实深度图。RMSE 函数用来衡量观测值同真值之间的误差。表2和表3所示分别给出了本文单目深度估计算法和其他四种算法的RMSE 和Sq Rel 的对比结果。从表中可以看出,相比其他四种方法,使用本文方法获得的深度图的RMSE和Sq Rel都是最小的。

表2 RMSE指标结果对比

表3 Sq Rel指标结果对比
3 结束语
针对单目深度估计中由于物体遮挡导致的图像估计准确度较低的问题,本文提出了一种优化方法。在网络结构中,将U-Net 和ResNet 相结合,通过使用最小化光度重投影损失函数,来处理单目视频中相邻帧间的遮挡问题,同时结合了自动掩蔽损失,解决了运动物体带来的干扰,使深度估计的结果更加清晰,减少了伪影问题。最后,使用KITTI数据集验证了本文优化方法的可行性,相比于目前四种单目深度估计模型算法,本文方法估计出深度图的RMSE误差和Sq Rel误差都是较优的。
