基于深度学习的小目标检测算法综述
2021-01-22战荫伟
刘 洋,战荫伟
广东工业大学 计算机学院,广州510006
目标检测是结合了目标定位和识别两个任务的一项基础计算机视觉任务,其目的是在图像的复杂背景中找到若干目标,对每一个目标给出一个精确目标包围盒并判断该包围盒中的目标所属的类别[1]。深度学习的流行使得目标检测技术获益匪浅,目前,深度学习已被广泛应用于整个目标检测领域,包括通用目标检测和特定领域目标检测。其中,小目标检测是目前计算机视觉领域中的一个热点难点问题。由于小目标的分辨率和信息量有限,使得小目标检测任务成为现阶段计算机视觉领域中的一项巨大挑战。小目标检测任务在民用、军事、安防等各个领域中也有着十分重要的作用,譬如无人机对地面车辆、行人等的目标检测,遥感卫星图像的地面目标检测,无人驾驶中远处行人车辆以及交通标志的识别,医学成像中一些早期病灶和肿块的检测,自动工业检查定位材料上的小缺陷等[2-8]。随着现实生活中计算机视觉系统的逐渐复杂化和智能化,小目标的检测任务也需要更多的关注。
本文针对目标检测特别是小目标检测问题,首先归纳了常用的数据集,系统性地总结了常用的目标检测方法,以及小目标检测面临的挑战,梳理了基于深度学习的小目标检测方法的最新工作,并简要评述,最后对其优劣进行总结及未来可能发展方向进行讨论。
1 数据集与评价指标
1.1 数据集
为了更好地进行研究,出现了许多目标检测数据集。数据集在整个目标检测领域的发展历史中占据了重要位置,数据量充足且具有针对性的数据集是开发先进的目标检测算法的关键,也是不同算法用于对比的一个评价基准。在过去十年里,目标检测领域出现了许多知名的数据集,包括SUN、PASCAL VOC、ImageNet、MS COCO、Open Image 等[9-14]。而针对一些特定领域的目标检测,尤其是应用领域中有大量小目标需要检测的情况,譬如航拍图像中的物体检测、遥感卫星图像中的物体检测等,也提出了许多相关数据集。相关数据集对比如表1所示。
早期加州理工学院提出的Caltech数据库[15-16],包含Caltech101和Caltech256两个数据集,但缺乏类间差异,目前已经很少使用。针对这一问题,SUN数据集在场景的多样化上进行推进。PASCAL VOC挑战赛是早期计算机视觉界中最重要的比赛之一,在2005 年到2012 年每年都会举办,包含多种任务,如图像分类、目标检测、语义分割和动作检测等,大大推动了目标检测的发展。ImageNet数据集的数据量相比于VOC数据集扩大了两个数量级,由于数据量太大同时标注的物体大多居于图片中心,缺乏多样性,目标检测领域中也很少使用。MS COCO 数据集是目前最具有挑战性的目标检测数据集,值得一提的是,相比于VOC 和ImageNet 数据集,MS COCO数据集具有更多的小目标以及更密集的目标分布(平均每张图像包含7.2个目标),所以也更为贴近现实环境。继MS COCO数据集之后,针对视觉关系的检测,推出了规模空前开放图像检测(Open Image Detection)挑战赛,包含600 个对象类别和1 910 000 张图像。DOTA数据集[17]针对航空图像,包含2 806张尺寸大约为4 000×4 000 的航空图像,15 个类别共计188 000 个实例。对于航拍图像中的较小的车辆目标检测,2016 年Razakarivony等人[18]建立了VEDAI数据库。同年Zhu等人[19]提出一种针对交通标志进行检测的方法,并建立TT100k 数据集,这也是迄今为止最大的交通标志数据集,拥有100 000张图像和128类共计30 000个实例。而在行人检测方面,常用的KITTI数据集[20]和CityPerson数据集[21]中的行人尺寸都比较大,不适用于较小的行人,针对这一问题,Yu等人[22]建立TinyPerson数据集用于微小行人的检测,相应标注示例如图1所示。
由此也可以看出,目前通用目标检测数据集已经相对完善,但是对于小目标的数据集仍旧十分匮乏,只有一些特定领域下的小目标数据集。这主要有两方面原因,一方面小目标的检测在一定程度上还不够受重视,标注人员也会忽视,标注的时候也容易出现偏差;另一方面,某些应用场景中,小目标的出现属于个别现象,导致这类样本稀缺训练集分布不均匀,训练效果不理想。小目标数据集的标注和数据量的不足,也是阻碍小目标检测相关工作进展的重要因素。
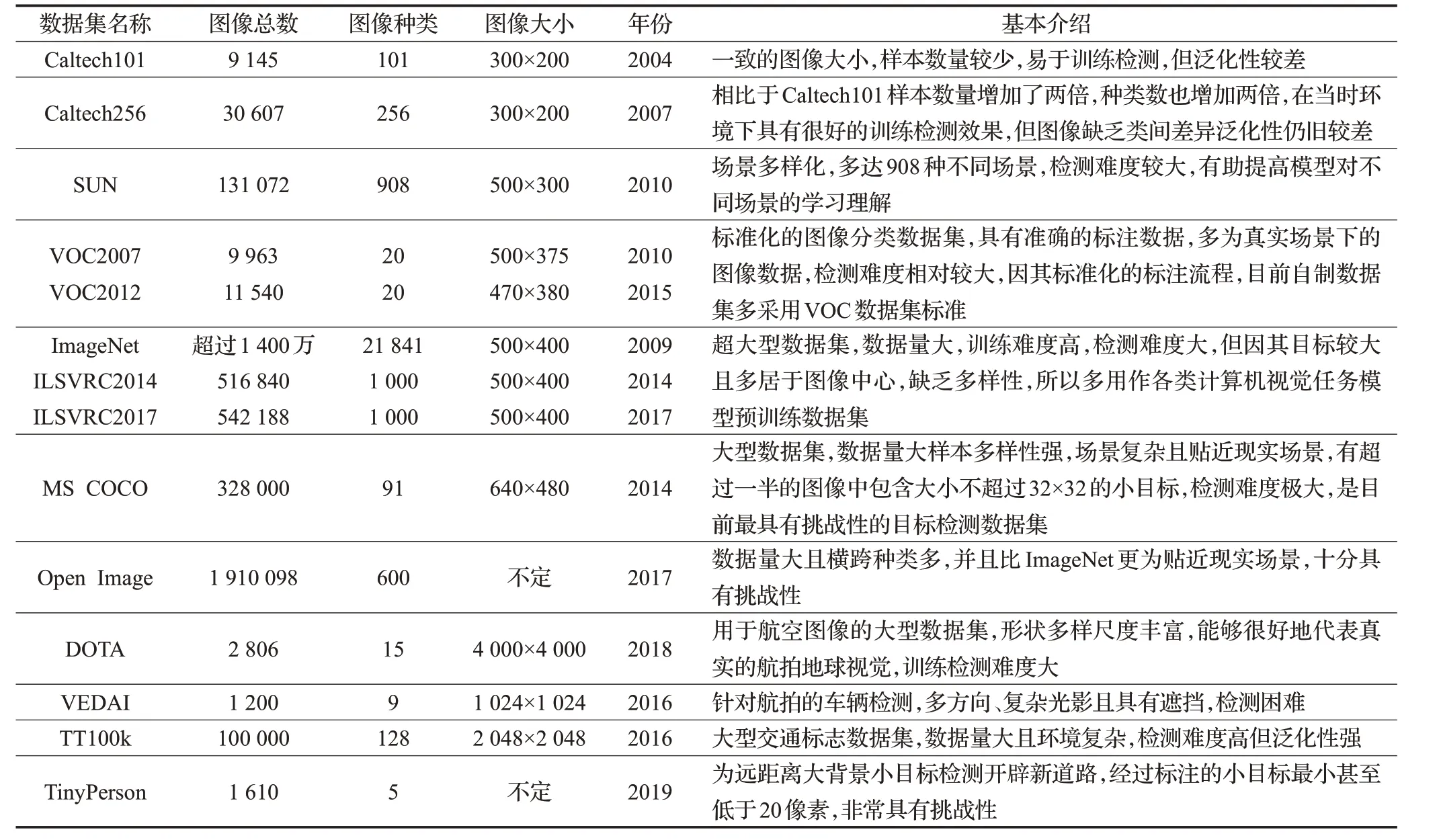
表1 相关目标检测数据集对比

图1 TinyPerson数据集示例
1.2 评价指标
在介绍算法之前,需要了解几个常见的目标检测评价指标术语。假定待分类目标只有正例(positive)和负例(negative)两种,则有以下四个指标:(1)TP(True Positives),被正确识别成正例的正例;(2)FP(False Positives),被错误识别成正例的负例;(3)TN(True Negatives),被正确识别成负例的负例;(4)FN(False Negatives),被错误识别成负例的正例。
则有如下定义,准确率(Precision)指预测的总实例中,被正确识别成正例的正例数所占的比率,如式(1);召回率(Recall)指待测试的所有正例样本中,被正确识别成正例的正例数,如式(2);一般来说,准确率和召回率成反比的关系。
以召回率为横坐标轴,准确率为纵坐标轴,在一定阈值的基础上形成的曲线被称之为P-R 曲线,P-R 曲线所围成的面积,即为平均精度(Average Precision),简称为AP。通常情况下,性能越好的分类器,AP 值越高。对多个类别求平均AP 值,即为mAP(mean Average Precision),mAP 通常用以表示模型在多个类别上的性能好坏。

图2 目标检测发展时间轴
2 目标检测算法
目标检测的方法主要分为两大类:基于传统人工特征的目标检测方法和基于深度学习的目标检测方法,如图2所示。
2.1 传统目标检测算法
早期的目标检测算法大多是基于手工特征构建的。基本思路[23]如图3 所示,先在输入的原始图像上寻找可能存在目标的区域,然后对每一个区域进行特征提取,并送入分类器模型进行判断,最后分类器模型认为是目标的区域进行筛选等后处理操作从而得到结果。由于当时缺乏有效的图像表示,人们别无选择,只能设计复杂的特征表示,并使用各种加速技术来耗尽有限的计算资源。

图3 传统目标检测方法基本流程
2.1.1 VJ检测器
19年前,Viola和Jones设计了一款高效的人脸检测器,比当时其他检测器的速度提升了几十倍,这是人脸检测乃至计算机视觉领域发展的一项里程碑,为了纪念这项工作,人们将之命名为Viola-Jones(VJ)检测器[24-25]。VJ 检测器采用滑动窗口的检测方法,采用Haar 特征来描述每一个窗口,并引入了积分图来加速Haar 特征的提取,使得每个窗口的计算复杂度与窗口大小无关,结合Adaboost 算法[26]进行特征的选择,并引入级联思想,减少背景窗口计算量,增加人脸目标计算量,提升精度的同时降低了计算规模。
2.1.2 HOG特征
方向梯度直方图(HOG)特征[27]最早是由Dalal等人对于行人检测问题提出的一种局部特征。顾名思义,HOG特征通过计算图片某一区域中不同方向上的梯度值进行累积形成直方图,作为这片区域的特征。HOG特征能较好地提取图像的局部细节信息,在图像的几何形变、光学畸变等情况下,都具有较好的特征不变性,多年来,HOG 特征一直是许多目标检测器和各类计算机视觉系统的基础。
2.1.3 可变部件模型(DPM)
针对HOG 特征处理遮挡问题表现较差的不足,2008年Felzenszwalb等人[28]提出了DPM算法,而后联合Girshick 等人进行了各种改进[29-31],在当时表现优异,连续获得VOC 挑战赛2007、2008、2009 三年的冠军。DPM 算法采用一种“分而治之”的思想,可以将训练检测过程看作是对象的各个部件的学习以及各个部件检测的集合,并对HOG 特征进行改进,取消了HOG 特征中的块,只保留了单元。并在后续改进中,结合了一些其他的重要技术思想来提高精度,如难例挖掘、边界盒回归等,对现在仍有着深刻的影响。
2.2 基于深度学习的目标检测算法
随着人工特征对目标检测算法的性能推进趋于饱和,人们开始将目光转向深度卷积网络上,相比于人工特征,深度神经网络提取出的特征虽然可解释性不强,但是在语义的表示能力上远远超过传统人工特征,因此基于深度学习的目标检测方法逐步取代了基于人工特征的方法,以卷积神经网络为代表的深度学习模型逐渐成为主流。基于深度学习的目标检测方法根据检测思想的不同可以分为两阶段(two stage)方法和单阶段(one stage)方法。
2.2.1 两阶段目标检测方法
2014 年,Girshick 等人[32]率先打破目标检测发展缓慢的僵局,提出了RCNN 算法,开创性地将候选区域生成和深度学习的分类方法结合起来。其背后的思想很简单,如图4所示:先通过选择性搜索[33]提取出一组对象候选框,然后将每个候选框重新调整为固定大小的图像,并将其输入到卷积神经网络模型中,以提取特征。最后,利用线性支持向量机分类器对每个区域内的目标进行预测和分类。虽然在当时RCNN 已经取得了很大的进步,但是其缺点也很明显:由于一张图像生成超过2 000 个候选框,在大量重叠的候选框进行了冗余的计算导致检测的速度极慢,在GPU 上运行一副图像大约需要14 s。

图4 RCNN算法结构
同年晚些时候,He等人[34]提出了SPPNet方法,设计了一种空间金字塔池化层,能够从不同大小的特征图中提取相同长度的特征向量,实现了多尺度输入,大大节省了计算时间。但是仍然存在一些不足,模型训练仍然是多阶段的。Girshick[35]在2015 年提出了Fast RCNN算法,做出了进一步改进,创新性地提出了多任务损失,同时训练分类器和包围盒回归器,实现了检测阶段的端到端训练,精度和速度都大大提高。虽然Fast RCNN结合了RCNN 和SPPNet 的优点,但由于候选框的选取仍是使用选择性搜索,检测速度仍旧受到限制。所以,Ren等人[36]在不久之后针对这一缺陷提出Faster RCNN算法,引入了RPN网络,使得候选框生成几乎不需要成本。Faster RCNN算法使用锚点(anchor)来生成初始候选区域,再通过RPN 来判断该区域是属于目标还是背景,将属于目标的区域送入后续结构中处理。
从RCNN到Faster RCNN,一个目标检测系统中的大部分模块都逐渐集成到一个统一的端到端的框架中,Faster RCNN是首个端到端,接近实时的深度学习目标检测器。在RCNN系列的开创性工作之后,针对这一系列的改进工作也如雨后春笋。Dai等人[37]提出了基于区域的全卷积网络(RFCN),改进了ROI pooling层以后的网络,以全卷积得到的位置敏感得分图代替全连接,大幅提升检测速度。He 等人[38]提出的Mask-RCNN,融合了分割和检测任务,使用插值对ROI 进行对齐,进一步提高了检测精度。在2017 年,Lin 等人[39]基于Faster RCNN提出了特征金字塔网络(FPN)。在此之前,大多基于深度学习的检测器只在网络的顶层进行检测,虽然CNN 的深层特征有利于类别识别,但是不利于目标的定位。为此,在FPN中开发了具有横向连接的自顶向下的体系结构,用于在所有层级上都能提取较强的语义信息。FPN在各种尺度的检测任务上取得了巨大进步,现如今已成为许多最新检测模型的基本组成部分。
2.2.2 单阶段目标检测方法
基于深度学习的单阶段目标检测的一般流程有所不同,如图5 所示,因为此类方法往往没有在候选区域上分类的过程,而是直接回归输出类别。

图5 单阶段目标检测方法基本流程
2016年,Redmon等人[40]提出了YOLO算法,这是深度学习时代的第一款单阶段目标检测算法,它的速度非常快。如图6 所示,该网络将图像分割成网格,同时预测每个网格区域的包围盒bounding box和分类概率,单个神经网络可经过一次运算从完整图像上得到结果,有利于对检测性能进行端到端的优化。不过YOLO 也有着泛化能力弱、检测精度较低的问题,其后Redmon 等人[41-42]陆续推出了YOLO9000和YOLOv3逐步改进这些问题。

图6 YOLO算法结构
而后在2016年,结合了RCNN的anchor机制和YOLO的回归思想,Liu等人[43]提出了SSD算法,引入了多尺度的检测方法,在每一个尺度提取的特征图上都进行检测。Lin等人[44]为了研究单阶段检测方法在精度上落后于两阶段检测方法,在2017 年提出了RetinaNet。他们认为训练过程中的类别的不平衡导致了单阶段方法在精度上的劣势,因此提出了Focal Loss来代替传统的交叉熵,改进了背景样本的权重,使得模型在训练过程中更偏向于较难检测的目标样本。
3 小目标检测
尽管近年来目标检测取得了巨大进展,但是上述方法也只是对于常规的目标检测问题有较好效果,提取出的特征对于小目标的表示能力较差,对于小目标的检测效果不太理想。根据MS COCO数据集的定义,通常将尺寸小于32×32 像素的目标定义为小目标。Huang 等人[45]的研究表明,现阶段的检测器,小目标的平均精度大约比大目标低10 倍,这并非说明卷积神经网络所提取的特征表示能力不够,而是小目标的分辨率太低,能提供给模型的信息较少,这也是目前限制目标检测发展的瓶颈之一,越来越多的专家学者们也将目光转向小目标检测领域并开展研究,目前也已提出一系列有效的改进方法。
3.1 基于多尺度的小目标检测方法
现有通用目标检测的卷积模型,大多采用卷积模型的最顶端特征进行预测,小目标的信息量较少,所以需要更好地利用图像的细节信息。在一个卷积神经网络中,低层的特征往往能很好地表示图像的纹理、边缘等细节信息,而高层特征往往能很好地表示图像的语义信息,但是相应的随着卷积池化的进行也会忽略掉一些细节信息。针对这一因素,Liu 等人[43]率先引入多尺度的思想,提出了SSD 算法,在每一个尺度提取的特征图上都进行预测,对小目标的检测相比于YOLO算法有较好的提升。虽然浅层的特征能更好地表示细节信息,但由于语义信息的不丰富,加之小目标所对应的anchor 较少,无法得到充分的训练,实际应用中SSD 的效果仍旧不尽如人意。Fu 等人[46]针对SSD 对于小目标因为对应anchor 较少训练不充分做出改进,如图7 所示,采用ResNet[47]替换了SSD 中的VGG[48]模型,并使用反卷积(Deconvolution)层,将图片分成更小的格子,从而减少漏检率。但由于DSSD引入了ResNet模型,有着更为复杂的残差连接和横向连接,并且在模型中的预测模块和反卷积模块添加了额外层,引入了额外开销,导致DSSD算法在预测速度上并不如SSD算法。

图7 SSD与DSSD算法结构
Singh 等人[49]从数据集的角度思考,认为目前数据集中的目标物体尺度差异较大,小目标相对于待检测图片而言尺寸过小,提出一种多尺度的训练方法——图像金字塔的尺度归一化(SNIP),在金字塔的每一个尺度上进行训练,高效地使用所有训练数据,虽对小目标的检测效果有显著提升,但是速度较慢。
Lin 等人[44]提出的特征金字塔网络(FPN)使用采样的方式融合了细节信息较多的底层特征和语义信息较多的高层特征,虽然效率略有降低,但增强了所提取出的深度特征对于小目标的表达能力,效果也优于一般通用检测方法,而后也衍生出众多基于FPN 的改进方法。Cao 等人[50]将FPN 的思想结合至SSD,从而提升SSD 算法对小目标的检测效果,由于其注重模型的轻量化,参数略少,背景信息中的噪声无法更好地筛除,相比于同使用特征融合思想的DSSD 算法精度略低。Liu 等人[51]在FPN的基础上,将模型最底层的特征与最高层的特征相连接,缩短了顶层与底层之间的信息路径,进一步增强了每一层特征图之间的联系。
Shrivastava 等人[52]提出一种类似FPN 的结构,用另一种方式实现了Top-Down 的特征融合,提升小目标的检测效果,该算法的融合并不像FPN一样采用单纯的加权叠加,而是利用卷积进行融合,该算法核心在于其Top-Down Modulation 模块,该模块核心结构可以自行选择,但由于是卷积进行特征融合,导致每新加一个该模块网络就要逐步训练一次,训练过程较为繁琐,不一定适用实际场景。其后Ghiasi 等人[53]和Xu 等人[54]相继提出NAS-FPN和Auto-FPN对FPN算法进行优化,不同于之前的人工设计的网络结构,将Auto-ML技术应用于目标检测上,使得神经网络自动搜索设计从而提升FPN算法的效率。Guo等人[55]为更好地利用多尺度特征,引入一种新的特征金字塔结构——AugFPN,利用一致性监督在特征融合前缩小语义差距,并采用残差特征以减少卷积池化过程中的信息丢失,最后提出一种Soft-ROI选择方法以更好地学习特征,在ResNet50 网络上平均精度提升了2.3 个百分点,但模型的复杂化导致在相同条件下,采用AugFPN算法的训练时间和帧率都要逊于FPN 算法,如在ResNet50 网络上训练每个epoch,采用AugFPN的Faster RCNN需要1.1 h,而采用FPN的只需0.9 h,帧率则分别为11.1 帧和13.4 帧。Rashwan 等人[56]认为之前的多尺度方法并没有考虑长宽尺度的因素,提出MatrixNet 模型,如图8 所示,并在MS COCO 数据集上达到了47.8%的平均精度,高于其他任何现有最先进的单阶段目标检测方法,不过该方法虽然采用了基于矩阵的层级预测机制,但并未考虑将不同层级的语义信息结合,比如高层低分辨率和底层高分辨率,同时结合所提出的长宽尺度思想,或许可以在精度上更进一步。

图8 MatrixNet模型结构
由此也可以看出,为了得到更好的效果,获取更多有效的小目标特征信息,多尺度的检测模型也从最初的单层特征,向多层特征融合转变,同时多层特征融合也从最开始的简单加权叠加,逐步发展为卷积融合以及在模型上添加一定的残差特征块等,模型的逐步冗余复杂化,虽然能逐步提高检测效果,但导致其更难在实际场景中得到应用。因此一些学者也开始在模型的轻量化上做研究,并提出了一些优秀模型,如MobileNet[57-59]、ShuffleNet[60-61]等,并将其应用于现有的一些优秀方法中,模型相关介绍如表2所示。在降低模型复杂度的情况下如何更好地保持检测精度也是一个重难点问题,在应用轻量化模型的同时,研究人员也提出一些结合轻量化策略的目标检测方法,如表3所示。
3.2 基于超分辨率的小目标检测方法
由于小目标在图像中所占像素少、分辨率低,所以小目标检测的另一种直接方法是生成高分辨率图像作为检测模型的输入。Hu等人[67]利用双线性插值获得了两次上采样的输入图像来训练卷积模型,Fookes等人[68]使用传统的超分辨率技术来更好地识别人脸。虽然这样提升了输入图像的分辨率有益于小目标的检测,但也带来了其他问题,超分辨率模型与检测模型是相互独立训练的,经由超分辨率模型生成的高分辨率输入图像中也包括无需检测以及对检测不必要的对象和因素,而输入图像分辨率的增加使得整体架构过分沉重,模型的训练和预测时间都会大幅增加,降低了在实际应用的可能性。Haris 等人[69]也针对这一问题提出一种端到端联合训练超分辨率模型和检测模型的架构,但仍旧有大量与检测任务无关的图像执行超分辨率从而拉低整体效率。

表2 轻量级网络简要介绍及对比

表3 结合轻量化策略的目标检测方法
随着深度学习在超分辨率技术上[70]的逐步应用,人们开始将目光从输入图像的分辨率提升转移到了特征的分辨率提升。Krishna等人[71]基于Faster RCNN算法将超分辨率网络整合进目标检测模型中,从而提升提取特征的效果,但是由于小目标本身包含的信息量不足,所提取的特征在经过超分辨率后效果仍旧不是很好。而后Ledig等人[72]首次将生成对抗网络(GAN)[73]应用于超分辨率技术上并超越了以往的基于深度卷积网络的超分辨率模型,与双线性插值调整图像分辨率的方式相比,利用GAN来进行超分辨率生成的图片质量更高、伪影更少,虽然相比于以往的超分辨率方法效率较低,但这也给小目标检测的特征增强开拓了新的研究思路。Li等人[74]认为小目标的特征虽然包含的信息量少,但是与常规目标特征之间是具有某种映射关系的,于是率先将生成对抗网络应用于小目标检测上,提出了感知生成对抗网络(Perceptual GAN),利用GAN 来学习这种映射关系并缩小小目标与常规目标之间的特征差距以达到提升小目标检测效果的目的。如图9所示,Perceptual GAN 分为生成器与判别器两个子网络,先利用包含常规目标的图像训练判别器的底层卷积与感知分支,而后利用生成器训练包含小目标的图像,生成小目标特征的超分表示,通过判别器的对抗分支来区分小目标特征的超分表示与常规目标特征,引入Perceptual Los 联合交替训练,不断提高生成器的生成能力和判别器的判别能力,使生成器生成的小目标超分特征逐渐接近常规目标特征,最终在TT100k数据集上相比于Faster RCNN算法的小目标检测率取得了较为明显的提升。随后Bai 等人[75]也提出一种利用GAN来针对ROI进行超分辨率的小目标检测算法——SOD-MTGAN,并可于任何现有的检测器结合使用,但由于针对ROI 区域,忽略了小目标的上下文信息。Noh等人[76]的工作证明,现有用于小目标的特征级超分辨率模型缺乏直接的监督,训练不稳定,限制了超分辨率特征的质量,同时在针对整体图像特征的超分辨率任务时,高低分辨率特征对的相对感受野差别不大,而小目标检测所针对的小目标特征差异较大,也会对生成效果带来影响。
总之,目前基于多尺度的方法通常通过结合多个低层特征来增强高层特征,以增加特征维度和信息量,无法保证所构造的特征对小目标具有足够的可解释性和区分性,而目前的基于超分辨率的小目标检测方法相对而言解释性较强,效果也十分可观,在MS COCO、TT100k 等数据集上也取得了十分具有竞争力的结果,但是硬件要求相对较高,极度依赖海量的数据,未来仍有大幅的提升空间。
3.3 其他方法
除开基于多尺度和超分辨率的小目标检测方法外,还有一些比较优秀的方法。Takeki 等人[77]针对天空大背景下的小目标鸟类识别,提出了一种联合了语义分割方法的小目标检测方法,并利用了小目标的弱语义性,将全卷积网络的变体和卷积网络结合并集成支持向量机,但是仅针对该特定环境难以进行扩展。在遥感卫星图像小目标检测领域中,Ren 等人[78]对Faster RCNN 的RPN 模块进行研究,提出常规RPN 模块对应的anchor框尺度太大,无法覆盖遥感数据集中的小目标,所以专门设计对应小目标尺度的RPN 模块,并结合上下文信息以改进模型性能,并在他们自制的SORSI遥感数据集(包含5 216 张轮船图像和706 张飞机图像)上达到了78.9%的平均精度,但受限于训练样本,对于复杂场景中的遥感目标和密集的小型光学遥感目标效果依旧不佳。在小人脸检测方面,Zhang 等人[79]参考OHEM[80]中的难负例挖掘思想,在图像级和特征级上动态地给训练图像分配难度分数,以判断图像是否已被很好地检测或是对进一步的训练有用,充分利用那些未被完美检测的图像以更好地监督接下来的学习过程,并在WIDER FACE数据集上获得了优异表现,尤其是hard子集上也达到了89.7%的精度。Luo 等人[81]提出一种四分支人脸检测体系结构,将大中小脸分开进行处理,并采用特征融合技术的同时增加更多的anchor匹配小脸,进一步提高了对小人脸的检测能力。

图9 Preceptual GAN模型结构
Chen等人[82]在RCNN的基础上进行扩展,改进后的RCNN 模型可以针对小目标检测任务生成更小的候选框,虽然在精度上有所提升,但是对计算资源要求太大,效率低,无法实现实时检测。Eggert 等人[83]也在RCNN的基础上进行改进,对如何anchor 尺寸进行探讨,并对特征图分辨率与小目标检测效果的关系进行研究,而后修改了候选框的生成方法用于公司商标的检测[84]。Cai等人[85]提出,现有的检测模型的检测结果,bounding box并不是特别准,很容易被噪声干扰,经过研究发现,对于不同的IoU 阈值,阈值越高,网络对于准确度较高的候选框的效果也就越好。针对这一结论,提出一种级联区域卷积神经网络模型(Cascade RCNN),引入不同的IoU阈值,训练多个级联检测器,提高了小目标的检测精度和bounding box 的定位精度,在Faster RCNN、R-FCN、FPN 三种two-stage 检测器作为基准的情况下均能稳定提升3到4个百分点,但正因为不同阶段的IoU阈值不同,容易导致在前两个stage中表现较好的样本在第三个stage中获得低分被判为负样本,虽然其采用了三个stage分数平均的策略用以平衡,但仍旧会有一定的正样本被误判。
Zoph等人[86]表示,未来的轻量化模型提取特征的能力必然有限,从数据增强方面入手是增强检测效果的利器,并假设当提出的特征足够好,利用数据增强可以摆脱当前算法严重的数据驱动依赖。Kisantal 等人[87]认为,小目标检测精度低主要有两个原因,一是现有公共数据集中含有小目标的图片较少,二是即便图片中含有小目标,但是出现次数少模型训练不充分,针对这点提出了一种过度采样复制粘贴小目标以增强数据的手段。如图10 所示,通过复制图像中小目标粘贴到图像中的不同位置,增加了图像中小目标的数量和位置多样性,同时相对应匹配的anchor 数目也会增强,从而降低了漏检率,以Mask RCNN 算法为基准,在MS COCO数据集上相比未进行数据增强的方法,小目标的检测精度提高了7.1 个百分点。除此之外,还有一些学者也提出了一些基于深度学习的小目标检测算法,如表4所示。

图10 通过复制粘贴小目标以达到数据增强的例子
4 总结与展望
本文系统地阐述了近些年来目标检测领域的研究进展,包括传统的目标检测方法和基于深度学习的目标检测方法,并对时下热门的相关数据集进行了综述与分析。重点关注目标检测领域中较为困难的小目标检测问题,分析了近几年来国内外在小目标检测问题上的一些改进算法,希望能给相关领域内的科研人员带来新的研究思路。虽然现有小目标检测算法已经取得了一些成果,但精度依然很低,随着现实生活中部署的计算机视觉系统的逐渐复杂化,小目标检测的精度要求也会逐渐提高,通过对上述技术的总结分析,提出以下几点观点。

表4 其他基于深度学习的小目标检测方法
(1)结合传统方法进行小目标检测。虽然基于深度学习的方法是近年来的主流,但大量工作表明由于小目标包含的信息量少,语义信息不充分,利用深度卷积网络提取的特征虽然语义信息充分,对于小目标而言效果却不是很好。考虑研究一些对小目标更具有表征能力的特征,结合一些非深度学习的方法用以特征提取,如随机森林、图像的局部秩等,或许可以起到更好的效果。
(2)引入注意力机制。现如今的多尺度检测网络已经可以很好地利用来自网络浅层的特征信息,但浅层特征同时也有来自图像背景的噪声信息,考虑引入注意力机制来进行检测可以有助于减少不必要的浅层特征信息,以提高小目标的检测效果。如2018年Hu等人提出的SENet[101],其作为通道上的注意力机制,强化重要通道的特征,弱化非重要通道的特征,可以灵活地嵌入各种网络结构中以提升效果,作为一款轻量级结构,额外增加的计算量相对较少。除了通道上的注意力机制,还有空间方向的注意力机制,通过空间方向的变换,使得目标样本的局部空间特征更容易被学习,相比于通道方向的,计算量略微有所增加,但可以获得更高的精度。可以考虑将二者进行结合,针对小目标灵活设计结构,以获得更低的计算代价和更高的精度。
(3)构建更为完善的小目标检测数据集。虽然现有的VOC 数据集、COCO 数据集都得到了研究人员的广泛认同,但深度学习方法的发展始终离不开数据。而上述数据集中的小目标样本仍旧不够充分,样本的不平衡、样本量的不够,都阻碍着小目标检测的发展,因此仍需要考虑建立一个专门的小目标检测数据集,或者另辟蹊径,采用某种数据增强的方式来建立小目标的仿真数据集,也不失为是一个补充训练样本的好办法。
(4)模型的轻量化,以提高检测系统的实时性、准确性和鲁棒性。随着时代发展,各个领域中小目标检测的需求也逐渐增多,而在目前的研究中,为了提高精度,往往模型都十分冗余,比如增加超分辨率模块导致运算量的大幅提升。要想在实际应用中发挥效果,必须保证模型的实时性、准确性和鲁棒性。因此如何保证模型的轻量化的同时又不失准确性也将会成为未来的研究热点。
(5)在模型训练过程中,着重针对小目标进行训练。现下的模型对大中目标检测效果好,对小目标检测效果差也是由于在训练过程中对小目标的监督不够完善,小目标的损失对整体的模型损失贡献较少,考虑在训练过程中专门针对小目标着重采样,提高训练质量。
(6)基于anchor-free的小目标检测方法研究。虽然现在的基于anchor的目标检测方法已经十分出色,在单阶段与两阶段方法上都得到了广泛应用,但仍旧存在许多不足。由于基于anchor 的方法都有一组预先定义的尺度框,导致对尺度较小的目标不够敏感,或者需要专门预设针对小目标的尺度框,但这样对硬件的要求极高。同时预设的尺度框多为负样本,容易造成正负样本的不平衡从而影响训练效果。所以考虑研究无锚点的方法进行小目标检测,最近也有一些研究证明anchor-free的方法一样可以达到接近基于anchor 的目标检测方法的效果,将anchor-free 的方法用以小目标检测,或许也能使小目标检测的研究得到推动。
目前基于深度学习的方法已成为主流趋势,并从简单的模型逐渐向复杂模型进行演化,多尺度特征融合、通过更高的分辨率提升小目标的检测效果、数据的增强等,都是小目标检测未来发展的趋势。虽然现有小目标检测算法已经取得了一些成果,但精度依然很低,随着现实生活中部署的计算机视觉系统的逐渐复杂化,小目标检测的精度和实时性要求也会逐渐提高,还有很长的一段路要走,未来可以考虑引入注意力机制以及在高分辨率轻量级网络上进行发展。
