基于GIoU的YOLOv3车辆识别方法
2021-01-22程海博熊显名
程海博, 熊显名,2
(1.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004;2.桂林电子科技大学 广西高校光电信息处理重点实验室,广西 桂林 541004)
近年来,随着AI技术的飞速发展,深度学习在车辆检测、车型识别[1]、车牌识别、人脸识别等领域得到了广泛的应用。传统的机器视觉技术在对车辆进行识别时,从图像中提取可供计算机理解的图像特征信息,而计算机对图像的理解可分为分类、检测与分割等3种方向。对车辆进行检测除了需要对目标进行分类判断外,还需要得到该目标的位置,因此检测难度较大。传统的目标检测方法多为滑动窗口检测,对人为设定的特征进行提取与匹配,存在计算量大、特征单一的问题。1998年Lecun等[2]提出卷积神经网络结构LeNet5并用于手写数字识别,从此神经网络算法进入了许多目标检测研究者的视线。2012年Krizhevsky等[3]提出了网络结构AlexNet,并获得ImageNet2012挑战赛冠军,深度学习算法迎来了研究的热潮。随着计算机性能的不断提升、计算机硬件的迭代,深度学习逐渐替代了基于手选特征的传统检测方法。基于检测的方法不同,车辆检测可分为区域提名的two-stage检测算法,如R-CNN[4]、SPP-Net[5]、Fast R-CNN[6]、Faster R-CNN[7]等,端到端的one-stage检测算法,如YOLO[8]、YOLO9000[9]、YOLOv3[10]、SSD[11]等。其中,Faster R-CNN检测准确率高,但速度慢,YOLOv3检测速度快,但准确率低。为此,提出一种GIoU-YOLOv3车辆检测方法,在不降低检测速度的同时提高了检测准确率。
1 基于Darknet-53的YOLOv3模型
车辆识别系统示意图如图1所示,采用GIoU[12]代替了YOLOv3中的IoU评价标准。

图1 车辆识别系统示意图
视频车辆识别步骤为:先将视频逐帧放入YOLOv3框架中,并将不同分辨率的图像缩放至416×416像素然后输入网络,然后根据已训练的特征权重经卷积计算出相应的分类概率值,并结合GIoU值进行最后的分类判断。
1.1 车辆特征提取
为了较快地识别车辆型号的同时得到较好的分类结果,结合GIoU的YOLOv3车辆识别模型进行车辆的特征提取。车辆特征提取网络结构如图2所示。YOLOv3采用Darknet-53作为特征提取的网络,该网络使用步长为2的卷积操作代替最大池化和平均池化进行降采样,并使用1×1卷积,减少网络的通道数,以加速计算。
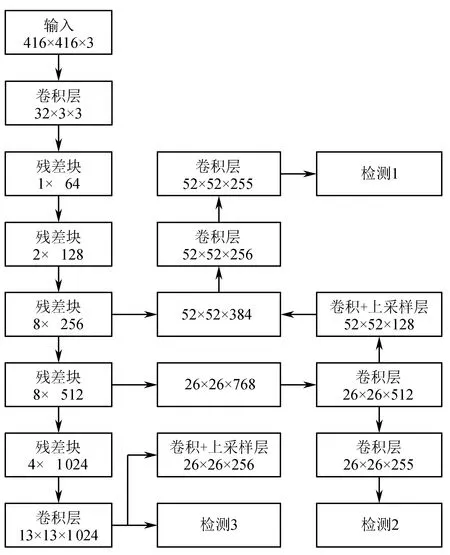
图2 车辆特征提取网络结构
残差块结构如图3所示,残差块由一系列卷积层和1个捷径通路组成。网络中共有5次降采样,网络最终输出可达32倍降采样。为了提高检测性能,该网络分别在32倍降采样、16倍降采样、8倍降采样3个尺度进行目标检测,并且使用步长为2的上采样将高倍降采样所获取的深层特征信息共享给低倍降采样层,使网络能同时学习深层与浅层特征。

图3 残差块结构
1.2 目标边界框评价标准
YOLOv3实现了End-to-End的目标检测模型,如图4所示,其将输入的图像分成S×S的单元格。若目标的中心点在某单元格中,则这个单元格负责这个目标的预测。每个单元格使用B个边界框预测目标的位置与置信度。

图4 图像划分示意图
YOLOv3采用边界框所含目标的可能性与IoU的乘积作为置信度来评判检测算法的优劣,
F=PcI,
(1)
其中:Pc为目标的中心点,当网格中有检测目标的中心点时,Pc=1,否则Pc=0;I为人工标记框与预测框的比值,用来评价模型预测框的准确性。
2 基于GIoU的优化目标函数
在目标检测算法中,用IoU评价方法进行评估,
(2)
其中A、B为图像的2个区域。2个区域的不同重叠方式示意图如图5所示,图中(a)、(b)、(c)的3种重叠方式的IoU值都为0.45,但是重叠方式不同,可提取的关键信息也不同。IoU难以正确区分2个对象的不同对齐方式,也难以反映2个对象之间的重叠方式。预测框与真实框相交的IoU可以直接用作目标函数进行优化,但预测框与真实框非相交的IoU则难以优化。
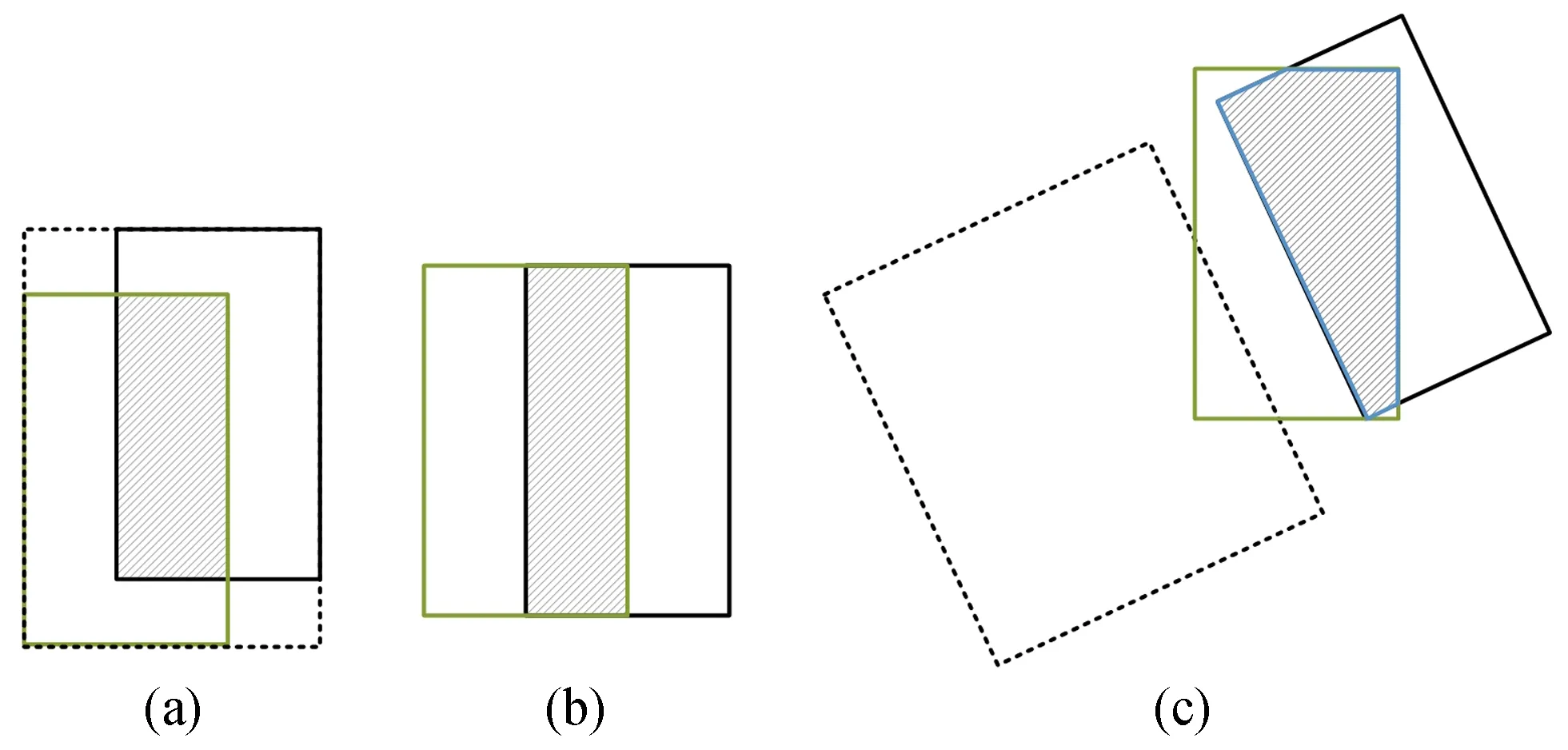
图5 不同重叠方式示意图
采用GIoU评价方法对非相交的IoU进行优化,其计算式为
(3)
其中:A为预测框;B为真实框;C为包含A与B的最小框;I为IoU值;G为GIoU值。与IoU类似,GIoU评价方法也可作为目标函数进行优化,其损失函数为
LGIoU=1-G。
(4)
由于GIoU评价方法引入了包含A与B的最小交集C,在A、B不重合时依然可以对目标函数进行优化。
GIoU评价方法的计算步骤为:
输入:预测框Bp=(x1,p,y1,p,x2,p,y2,p),真实框Bg=(x1,g,y1,g,x2,g,y2,g);输出:LGIoU。
1)计算Bp与Bg的面积:
2)计算Bp与Bg的重叠面积Ix,y:
3)找到Bp∩Bg的最小区域Bc:
4)计算Bc面积:Bc=(x2,c-x1,c)×(y2,c-y1,c);

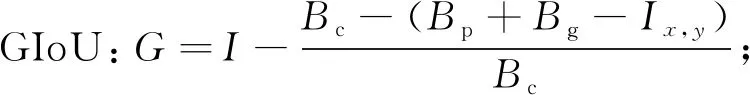
7)计算最终损失LGIoU=1-G。
3 实验与分析
实验在Windows 10系统完成,其中CPU为I7-7700HQ,GPU为RTX1060 6 GiB,内存为24 GiB,开发环境为Python3.69、OPPENCV、CUDA10、Tensorflow1.13等。
3.1 训练数据与预测
实验选取VOC2007数据集中899张公交车与小轿车图片完成网络的迁移训练与验证,其中根据公交车和小轿车的数量随机选取90张图片作为测试集。部分样本实验预测图如图6所示。实验中,IoU阈值为0.5,GIoU阈值为0.3。

图6 部分样本预测实验图
3.2 模型检测结果
采用平均精度对公交车和小轿车预测性能分别进行评估,并采用多类平均精度对模型总体性能进行评估。平均精度为查准率与召回率组成的P-R曲线与x、y轴所围成的面积占总面积的比率。查准率rP与召回率rR的计算式为:
(5)
其中:nTP为正类样本判断为正类的数量;nTN为负类样本判断为负类的数量;nFP为负类样本判断为正类的数量;nFN为正类样本判断为负类的数量。
分别将基于GIoU与IoU的YOLOv3模型进行迁移训练,其中GIoU-YOLOv3训练的批量大小为4,训练50个迭代后损失下降至5;IoU-YOLOv3训练批量为32,训练400个迭代后损失下降至20。图7为IoU-YOLOv3公交车平均精度,图8为IoU-YOLOv3小轿车平均精度,图9为GIoU-YOLOv3公交车平均精度,图10为GIoU-YOLOv3小轿车平均精度。
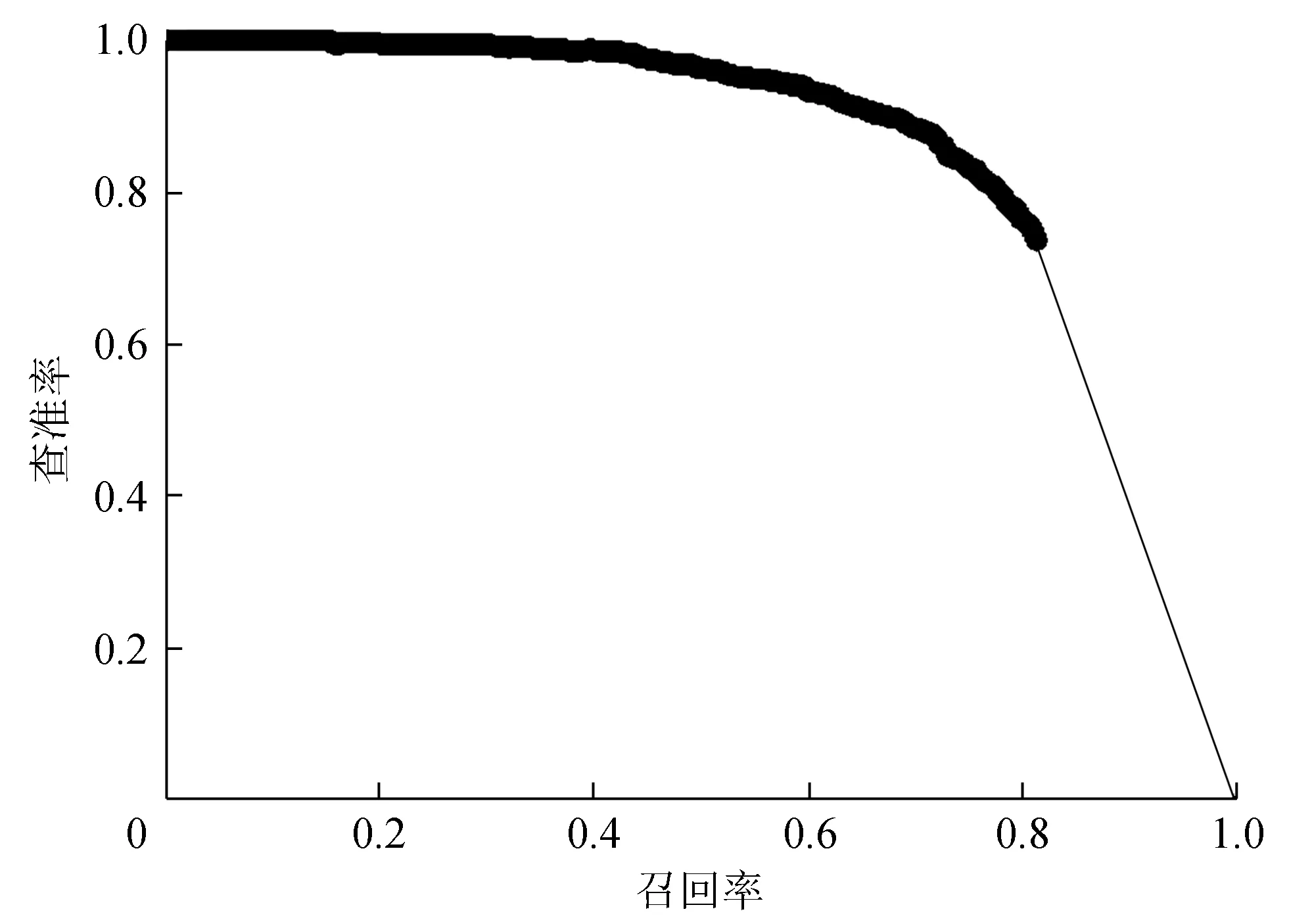
图8 IoU-YOLOv3小轿车平均精度
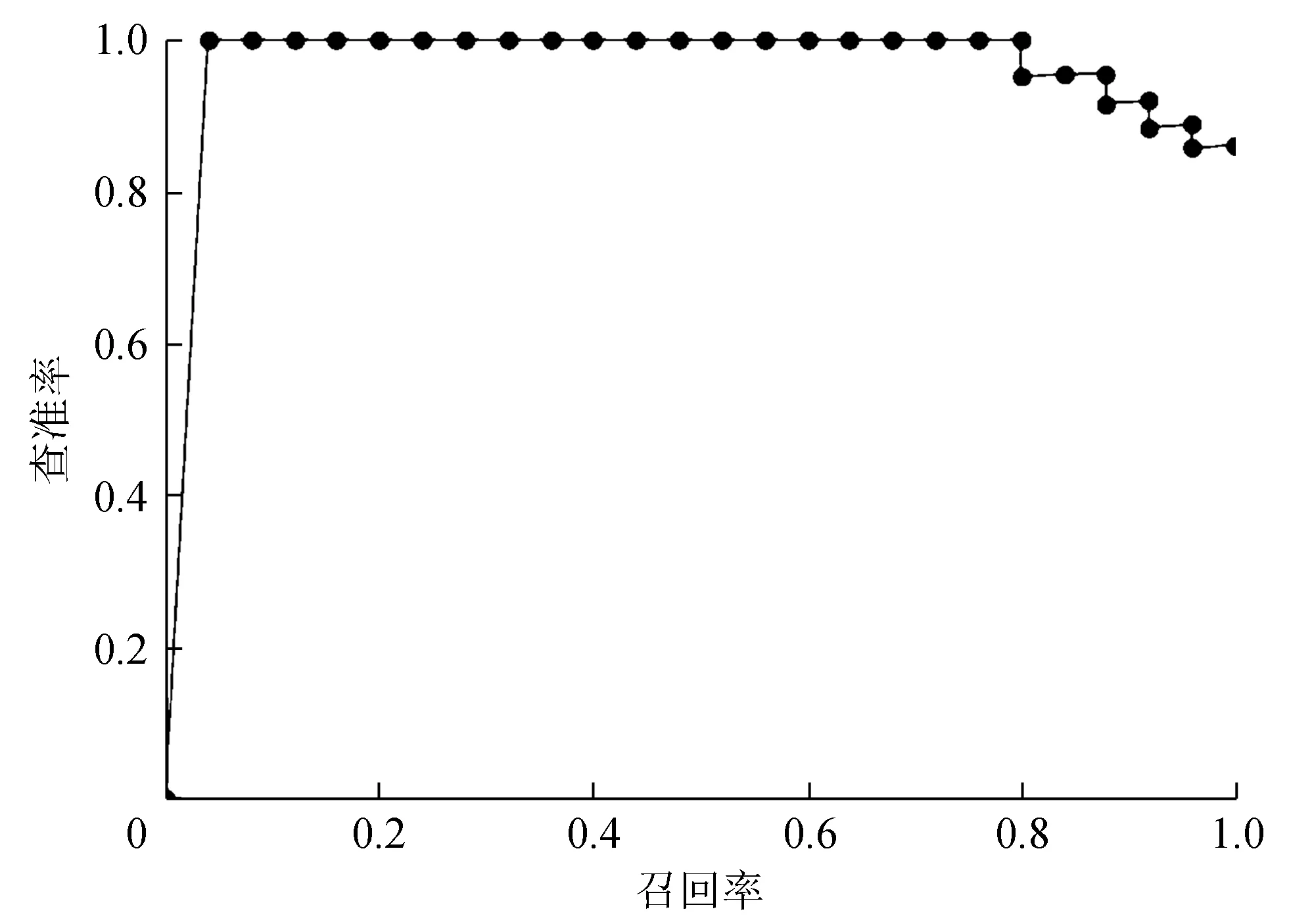
图9 GIoU-YOLOv3公交车平均精度

图10 GIoU-YOLOv3小轿车平均精度
3.3 结果分析
基于GIoU与IoU评价方法的YOLOv3模型对VOC 2007数据集的公交车与小轿车样本测试结果如表1所示。从表1可以看出,在车辆识别中,基于IoU的YOLOv3模型对公交车与小轿车的平均精度分别为83.11%与77.66%,而基于GIoU的本方法的平均精度分别达到了98.34%与93.61%。由实验结果可知,本方法对公交车与小轿车的识别相对于IoU方法提高了15%的mAP。

表1 公交车与小轿车样本测试结果
4 结束语
针对视频车辆识别方法检测精度不高的问题,提出一种基于GIoU改进的YOLOv3视频车辆识别方法。对实验目标车型的样本进行迁移学习的同时,使用GIoU代替传统IoU评价方法进行训练,对公交车、小轿车检测的平均精度分别达到了98.34%与93.61%,mAP达95.97%,提高了视频车型识别精度,实现了车辆的精准识别。后期将增加训练集与车型种类,进一步优化多车型、高精度的车辆检测方法。
