基于深度网络模型压缩的广告点击率预估模型
2021-01-22李致贤张红梅
李致贤, 张红梅
(桂林电子科技大学 广西高校云计算与复杂系统重点实验室,广西 桂林 541004)
随着互联网的发展,互联网广告在广告营销产业所占比重在逐年增加,成为很多互联网广告公司重要收入来源。许多互联网公司构建了不同的广告系统来提高互联网广告的转化率,并以此为用户提供更好的服务体验。
广告点击率预估模型是广告系统的核心组成部分,其最初采用LR的方法[1],该模型简单易用,却忽略了特征间的非线性关系。为了利用特征间的组合信息,2010年Rendle[2]提出了FM(factorization machine)模型,该模型在原有的线性模型的基础增加二次多项式组合部分,采用矩阵分解的方法将二阶特征组合系数进行分解,提高了点击率预估效果。随着近几年深度学习的不断发展以及深度学习对多维数据复杂关系处理的优越性,推荐系统领域将深度学习的方法引入其中。许多学者针对特征交互方面做出改进,现有模型可分为并行结构和串行结构2种。并行结构是低维特征组合部分和深度神经网络部分分开计算,输出层将两部分的计算结果合并,并采用sigmoid函数输出,代表模型有DCN[3]、Deep FM[4]、xDeepFM[5]。串行结构是将低维特征组合的结果作为深度神经网络的输入,经深度神经网络的特征交互最终由输出层输出,代表模型有FNN[6]、SNN[7]、PNN[8]。采用深度学习模型捕捉高维特征间的非线性关系可提高广告点击率预估的正确率。然而以上基于深度学习的点击率预估模型忽略了不同的特征组合对于点击率预估结果重要程度的不同,难以有效捕捉高阶特征组合间的非线性关系。注意力机制类似于人类的视觉系统,可以有效发现数据的“焦点”,捕捉重要特征组合。AMF模型在FM模型基础上增加了注意力网络,对交互特征加权,来表示对不同特征交叉组合间不同的关注度,因其更贴合现实场景,取得了不错的效果[9]。温瑶瑶[10]将注意力模型与极深因子分解机结合,通过注意力模型筛选极深因子分解机得到的重要高阶特征组合,增强模型解释性的同时提高模型性能。这2个模型虽然仍存在高阶特征间非线性关系捕捉不足,但证明了注意力机制对于广告点击率预估的有效性。2018年Song等[11]提出的AutoInt模型仅采用多头注意力机制对特征间非线性关系进行捕捉,虽然模型效果较优,但由于高阶特征间非线性关系捕捉不足,仍需要进一步对其优化。另外,大多数点击率预估模型致力于提高预估准确率建立复杂的网络模型,导致模型难以在实际场景应用,对复杂点击率预估模型压缩势在必行。鉴于此,提出一种基于深度网络模型压缩的深度学习广告点击率预估模型,提高广告点击率预估准确率的同时,增强模型的可用性。
1 相关定义
1)点击率预估。令x∈Rw表示用户u的特征和项目v的特征的级联,其中w是级联特征的维数。点击率预估是指根据特征向量x预测用户u点击项目v的概率。
2)字节。字节指数据集中多个同类特征的集合,例如性别字节有男性和女性,兴趣字节有篮球、足球、游泳、登山等。
3)低阶特征组合和高阶特征组合。特征组合的选取是点击率预估的重要环节,通过将多个特征同时表达在特征空间,使模型更好拟合,提升模型性能。在点击率预估中低阶特征组合指一阶和二阶的特征组合,高阶特征组合指二阶以上的特征组合。
4)one-hot编码。one-hot编码又称“独热”编码,指采用N位状态寄存器对N个状态进行编码,每个状态都有独立的寄存器位,且这些寄存器只有一位有效。因为推荐系统数据集中的离散型数据不具序列性,所以在数据预处理过程中离散型数据不能以简单的数值直接替换,而要采用one-hot编码。
2 基于深度网络模型压缩的深度学习广告点击率预估模型
2.1 soft-MADR模型
为更好地捕捉特征组合间的非线性关系,实现广告点击率的准确预估,提出了基于深度网络模型压缩的广告点击率预估模型(soft-MADR模型)。将未经模型蒸馏的原始模型称为MADR模型,其点击率预估结构如图1所示。

图1 点击率预估模块结构
该模型网络结构分为输入层、嵌入层、特征交互层和点击率预估层4层。其广告点击率预估实现流程为:输入层输入的稀疏数据经嵌入层转换为维度固定的特征向量,然后输入至特征交互层;由多头注意力网络和结合残差网络的深度神经网络构成。其中多头注意力网络通过将输入的特征向量映射到不同的低维空间,对输入的特征向量预处理,捕捉全局重要的特征组合信息。将特征组合信息送入结合残差网络的深度神经网络中,进一步捕捉高阶特征组合信息,经点击率预估层预测并输出结果。
2.2 特征嵌入
在推荐系统数据集中,将离散特征以one-hot编码,使原本稀疏的数据更加稀疏。为了便于训练以及减少内存,采用Embedding方法[12]对稀疏数据压缩处理,在尽量不损失信息的前提下,转换为一个稠密嵌入表示,
ei=Vifi,
(1)
其中Vi为字节fi的嵌入矩阵,Embedding通过模型的迭代将每个字节fi(i∈[1,n],n为字段总数)的取值映射为一个固定维度d的稠密嵌入向量ei。针对不同类型特征,对其进行不同的处理:1)针对单值离散特征,直接采用Embedding方法将其表示在低维空间。2)针对多值离散特征,为了与多值输入兼容,将多值离散特征表示为相应特征嵌入向量的平均值。3)针对连续特征,为了使特征组合时离散特征和连续特征能够正常交互,在相同的低维空间表示连续特征,从而与离散特征保持相同的维度d。
不同类型的数据经嵌入层处理后,将每个样本中所有字节的特征对应的稠密嵌入向量拼接,从而建立对应的映射关系表e,
e=[e1,e2,…,en]。
(2)
2.3 特征交互
特征交互是广告点击率预估模型的重要模块,经Embedding转化的稠密向量ei在同一低维空间模拟高维特征组合,以得到有意义的特征组合。本点击率预估模块采用多头注意力模型对嵌入特征初步整合,提取相对重要的特征组合,再将其送入结合残差网络的深度神经网络进行更高维度特征组合的捕捉,增加模型的泛化能力,完成对模型整体特征组合信息的捕捉。
2.3.1 多头注意力网络

ψh(em,ek)=〈Wh,Qem,Wh,Kek〉;
(3)
(4)
(5)
(6)

2.3.2 深度神经网络
深度神经网络(deep neural networks,简称DNN)是深度学习的一种基础网络,其内部的神经网络层如图2所示,包括输入层、隐藏层、输出层。通常情况下,第一层为输入层,最后一层为输出层,中间层都是隐藏层。从输入层开始,将上一层的输出结果作为第二层的输入,以此计算至最后一层网络结构,这个过程为前向传播。前向传播结束,为使计算的输出更好地拟合样本,采用反向传播算法更新每层权重,以最小化损失函数。前向传播和反向传播反复迭代多次,直至达到停止准则。

图2 深度神经网络结构
2.3.3 残差网络
残差网络由一系列残差块组成。图3为残差网络的基本单元残差块。多层神经网络学习一个潜在恒等映射H(x)=x比较困难,残差块使模型由学习一个恒等映射H(x)=x变为学习一个残差函数F(x)=H(x)-x,只要F(x)=0,即构成恒等映射H(x)=x。残差网络更新某一节点参数时,由于H(x)=F(x)+x求导后始终不为0,就可保证该节点参数更新不发生梯度消失或梯度爆炸现象。另外由于学习F(x)=0比H(x)=x简单,残差网络学习的更新参数能够更快收敛。

图3 残差块
2.4 点击率预估
特征交互层输出的是一组包含权重的特征组合向量,对于最终的点击率预估,使用简单的非线性投影将其转化为点击概率,
(7)
(8)
2.5 模型压缩模块
模型压缩模块旨在利用模型蒸馏技术对点击率预估模块进行轻量化处理,减少模型参数,降低内存资源占用的同时加快点击率预估的效率,提高模型的可用性。其步骤如下:
1)使用训练数据训练点击率预估模块。使用的样本标签为实际标签,即“硬目标”。
2)计算教师模型的“软目标”。利用训练好的点击率预估模块分别计算多头注意力层、深度神经网络层和点击率预估层输出的特征概率信息,
(9)
其中T为温度参数,zi为归一化层的输入。
3)训练学生模型。训练含有“硬目标”的训练样本的同时训练教师模型输出的“软目标”的训练样本。损失函数采用均方误差函数,
L=αLsoft+(1-α)Lhard,
(10)
(11)
其中α为权重系数,k为样本数。
4)将温度参数T设为1,并输出压缩的学生模型。
2.6 模型结构
综上所述,提出一种基于深度网络模型压缩的广告点击率预估模型如图4所示。

图4 基于深度网络模型压缩的soft-MADR模型
模型工作流程如下:
1)数据预处理。数据预处理包括数据清洗、连续型数据归一化处理、离散数据one-hot编码以及4∶1划分训练集和测试集。
2)模型训练。预处理后的数据经嵌入层、特征交互层自底向上逐层训练,并采用反向传播更新每层参数。
3)训练MADR模型的同时进行模型蒸馏,得到soft-MADR模型。
4)采用soft-MADR模型进行点击率预估。
3 实验结果与分析
3.1 数据集
本次实验选用的数据集为Avazu数据集。Avazu是一家来自德国的技术类网络广告公司,Avazu数据集(http://www.kaggle.com/c/avazu-ctr-prediction)是该公司公开发布在网络上广告的真实数据集。数据集的样本数为40 428 967,字节数为24,特征数为1 544 488。
3.2 实验参数设置
实验中不同的参数设置会影响模型的训练结果,进而影响广告点击率预估的准确率。通过相关文献和大量实验,确定相对较优参数设置。实验模型参数设置如表1所示。
3.3 实验评价标准
本次实验评价指标为fAUC、fLogloss和模型运行时间。fAUC指ROC曲线下与坐标轴围成的面积,常作为衡量二分类模型优劣的一种评价指标,表示预测的正例排在负例前的概率。其计算式为:

表1 实验模型参数设置
(12)
rTP=nTP/(nTP+nFN),
(13)
rFP=nFP/(nFP+nFN),
(14)
其中:nTP为样本正确判断为正类(少数类)的样本数;nTN为样本正确判断为负类(多数类)的样本数;nFP为样本错误判断为负类的实际正类样本数;nFN样本错误判断为正类的实际负类样本数。
反映样本的平均偏差的对数损失函数为
(15)

3.4 实验分析
实验环境为Windows 10教育版64位系统,Intel(R) Xeon(R) CPU E5-2620 V4@2.10 GHz Anaconda3 2019.10(Python 3.7.4 64-bit)。
对比本模型(soft-MADR模型)与基线模型的fAUC、fLogloss和模型运行时间,其中基线模型分为只使用单一特征的LR线性模型、考虑二阶特征组合的FM模型和能够捕获高阶特征交互的模型3类。为确保实验的有效性,实验数据均为10次实验数据的平均值。表2为soft-MADR模型与基线模型性能对比。由表2可知,soft-MADR模型性能均优于其他模型,说明soft-MADR模型能够有效捕捉高维特征组合间的非线性关系。其中soft-MADR模型的fLogloss值最低,这表示该模型的点击率预估的准确率较高;fAUC的值最高,表明模型正确分类的性能较好。
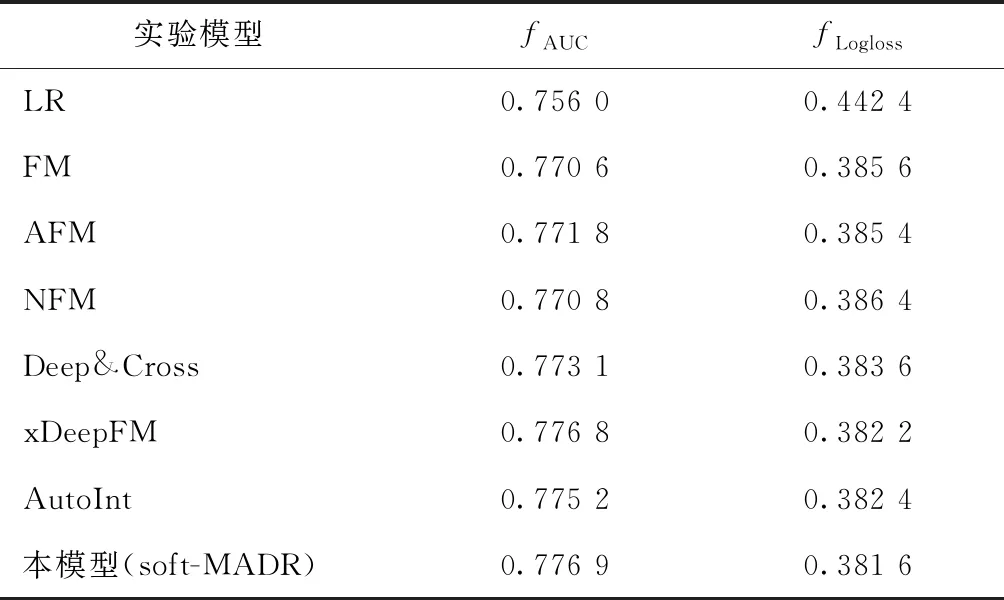
表2 soft-MADR模型与基线模型性能对比
图5为模型运行时间对比。从图5可看出,本模型运行时间仅高于LR模型,而模型性能远远优于LR模型,这表明该模型在实际应用的综合优势。综合各方面指标,本模型性能及可用性更好。

图5 模型运行时间对比
4 结束语
针对广告点击率预估模型难以有效捕捉高阶特征组合的非线性关系且模型复杂度较高、实际应用困难的问题,提出了一种基于深度网络模型压缩的深度学习广告点击率预估模型,该模型提高了点击率预估的准确率,且降低了运行时间。模型采用多头注意力网络对特征进行初步交互,使用结合了残差的深度神经网络进一步提取高阶特征组合,提高模型点击率预估能力。在训练MADR模型的同时使用模型蒸馏对其轻量化处理,得到soft-MADR模型,减少模型参数,提高模型的广告点击率预估效率。在Avazu数据集上实验结果表明,本模型具有更好的性能和可用性。由于该模型参数有很多的不确定性,检测率会受到学习率、迭代次数等因素的影响,下一步研究如何有效选取模型参数。
