基于熵权层次分析法的云平台负载预测
2021-01-20王宗杰
王宗杰,郭 举,2+
(1.北京科技大学 计算机与通信工程学院,北京 100083;2.北京起重运输机械设计研究院 研发中心,北京 100007)
0 引 言
通过将底层硬件资源抽象为虚拟机节点[1],云平台可持续稳定地处理频繁且种类多样的用户请求,但同时产生了计算节点间负载不均衡的问题。伴随着云计算技术的迅猛发展[2],出现了不同种类[3]的负载均衡技术[4],缓解了云平台负载不均衡的问题[5]。目前国内外关于云平台的负载均衡技术理论研究和工程实践产生了大量的研究成果。文献[6]利用层次分析法分析4种影响云平台负载的因素,计算云平台的负载值。该负载值能较好反映当前平台的资源利用情况,但使用单一的主观赋权法所得权值具有主观片面性。文献[7]利用熵权法建立了对输电方案的模糊评价模型,提取了评价指标的有效信息,但使用单一客观赋权法所得结果不全面。文献[8]利用指数平滑法预测了云平台的负载值,预测值由历史负载值加权平均得到。该模型系统资源占用小,但负载误差会逐步增大,预测精度较低。文献[9]提出基于支持向量机的云平台资源分配策略,实现对云平台资源的动态分配。文献[10]利用哈希算法将数据存放到不同的数据节点上,实现各节点的负载均衡。文献[11]提出了能量感知资源管理算法,动态调整虚拟机资源分配情况。针对前人研究存在的问题,提出了更全面的负载评估模型和负载预测算法,实验结果验证了其有效性。
1 云平台负载评估预测方案
云平台负载评估预测方案包含负载评估和负载预测两部分内容。负载评估阶段选取4种评价指标,利用层次分析法和熵权法计算出云平台负载序列值。然后,采用差分整合移动平均自回归模型 (autoregressive integrated moving average model,ARIMA)和BP(back propagation)模型和BP神经网络分别处理负载序列的线性部分和非线性部分,最终得出云平台负载预测值。
1.1 层次分析法
层次分析法(analytic hierarchy process,AHP)是对一些较为复杂模糊的问题作出决策的多准则决策分析方法[12],主要目标是解决多目标的复杂问题,它本质上是一种建立在对问题定性和定量基础上的决策分析方法。为了得到被评价属性的权值,它采用决策者主观经验判断各个属性之间的相对重要程度,建立评价矩阵,随后逐步计算得出各个属性的权值,适用于一些定量方法难以应用的复杂问题。
本文采用AHP法赋权计算主观权重,主要方法和步骤如下:
步骤1 构建递阶层次结构模型。
步骤2 根据各属性指标的相对重要程度,建立判断矩阵
其中,c、m、d、n依次代表计算资源、内存资源、硬盘资源、带宽资源。Wij表示资源i对资源j的重要程度,其取值依照九分位比例标尺。判断矩阵完成之后,需依照式(1)、式(2)对其进行完整性检查
(1)
(2)
步骤3 计算权重向量
采用方根法计算权重向量。将判断矩阵WA中的元素按照每行相乘得到新向量WT,再将该新向量的每个分量开n次方(此处n为4)得到向量WL,最后将所得向量WL进行归一化处理即得权重向量W。
步骤4 一致性检验

表1 平均随机一致性指标
步骤5 调整判断矩阵
若判断矩阵通过步骤4的一致性检验,则归一化后的权重向量即是各因素的权重系数。否则需对判断矩阵进行调整,直至满足一致性检验。
1.2 熵权法
熵最早由香农引入信息论,目前已经在金融经济、制造技术等众多领域得到了众多应用。一般来说,信息熵Ej越小的指标,其变异程度越大,包含的信息量也越多,对综合评价的影响也越大,那么分配的权重也应该越大;反之,该指标分配的权重越小。熵权法(entropy wright method,EWM)的原始数据来源于评价过程中,这一方面可以充分利用历史数据对权重的影响程度,但另一方面也造成熵权法在确定指标时会随着样本的变化而变化,对数据样本具有依赖性,限制了对其的应用。
本文在建立评价模型时,采用熵权法获得各指标的客观权重,具体计算步骤如下:
步骤1 构建初始矩阵并进行标准化处理
对于给定的N个对象,M个指标P1,P2…PM, 其中Pi={p1,p2,…pN}, 构建初始矩阵X
对初始矩阵采用归一法进行标准化处理,得新的矩阵Y,其中
(3)
步骤2 计算各指标的信息熵
由上面对信息熵的定义,可得一组数据的信息熵为
(4)
其中,pij由式(5)给出,若pij=0,则都定义
(5)
步骤3 计算各指标的权重
根据信息熵的计算公式,可计算出各个指标的信息熵为Ei,利用式(6)可计算出各个指标的权重
(6)
1.3 自回归积分移动平均模型
基于时间序列的预测技术通过统计分析收集的历史数据,获得一般的事物变化趋势,对数据进行不同程度的处理,减少外界因素对变化规律的影响,最终对事物的发生进行预测。ARIMA是一种较常用的基于时间序列的预测模型[13]。
本文利用ARIMA模型对ARMA(自回归滑动平均模型)模型进一步优化,解决了ARMA只能分析平稳序列的问题。ARIMA实质是ARMA模型与查分运算的组合形式,首先通过一定阶数的差分处理时间序列数据,使不平稳数据成为平稳数据,接下来就可以使用ARMA模型对差分后的数据进行拟合。ARIMA模型在时间序列分析方法中应用的比较广泛,建模流程如图1所示。

图1 ARIMA建模流程
首先对时间序列数据进行平稳性检测、白噪声检验处理,其后通过自相关函数和偏相关函数PACF确立ARIMA模型的参数范围,并通过数据拟合确定最终模型参数。最后使用ARIMA模型预测时间序列数据。
1.4 BP神经网络
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前被广泛应用在预测领域的模型。BP神经网络主要依靠自身的训练,自主训练某些数据规律,不需要提前给出输入输出之间的映射关系。在应用时,只需给出输入值,即可给出最接近期望输出值的预测结果。BP神经网络实现预测的核心是BP算法,其思想利用梯度搜索技术和梯度下降法,最终获得输出值和实际值的误差的均方差最小。BP神经网络的拓扑结构如图2所示。
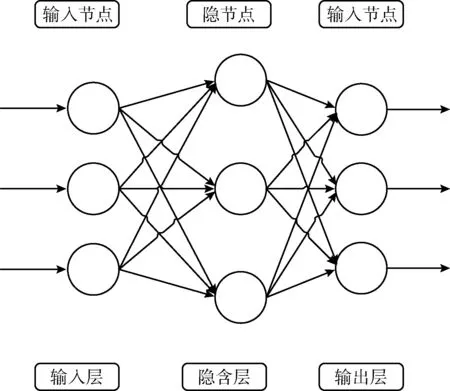
图2 BP神经网络拓扑结构
BP神经网络首先根据业务目标选取样本数据。之后进行数据预处理操作。对于短期变化剧烈的数据不适合直接作为输入数据。输入数据序列越稳定均匀,对于建模预测就越有利。一般建立BP神经网络之前,首先会对数据进行归一化处理,得到平滑的数据序列作为网络的输入,归一化处理后,一定程度上降低最终预测结果中的无效噪声。
其次根据负载特点,设计网络结构并给出网络的相关参数,包括网络层数、输入输出节点书、隐含层节点数、激活函数等。正确设计这些参数,对于预测效果至关重要。
模型建立完成之后,开始训练数据样本集。当网络训练的次数达到上限或输出的数据误差满足要求时,输出训练好的模型并对负载值进行预测。其训练过程如图3所示。
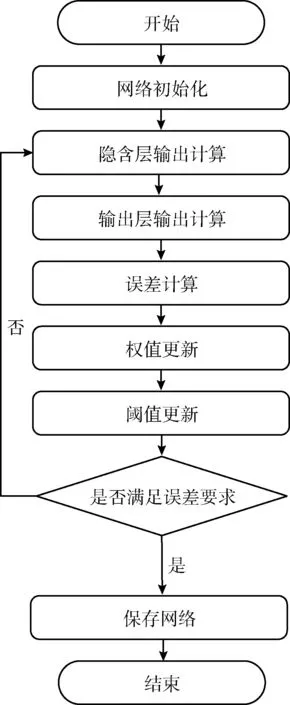
图3 BP神经网络训练过程
1.5 基于ARIMA-BP的云平台负载预测模型
对于云平台的负载值来说,它受到内部因素和外部因素的影响,因此云平台的负载值中隐含了线性特征和非线性特征,是线性特征影响因素和非线性特征影响因素的综合反映。
对于负载值的预测可以使用适应处理分析线性时间序列的模型和适应处理分析非线性时间序列的模型组成的组合模型对其分析处理。
本文使用线性拟合能力较好的ARIMA模型和非线性拟合能力较好的BP神经模型构成组合预测模型,对云平台的负载值进行分析预测。ARIMA模型可以提取出云平台负载值的线性特性,BP神经网络可以提取出云平台负载值的非线性特征,两者结合构成的组合模型不仅弥补了只采用单一预测模型分析的不足之处,又能够充分发挥各个预测模型的优势之处。组合模型的整体流程如图4所示。
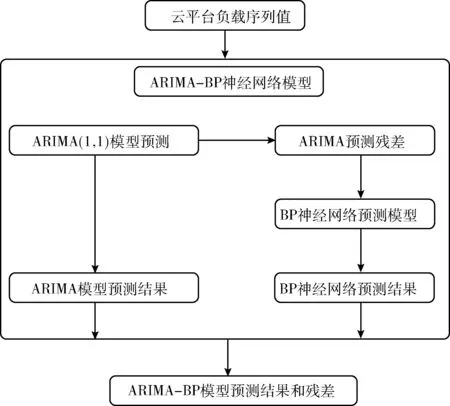
图4 基于ARIMA-BP的组合模型原理
2 实验验证
2.1 建立基于熵权层次分析法的动态评估模型
2.1.1 动态主观权重
首先构建判断矩阵,本文选取CPU、内存、磁盘、网络4个因素作为评价指标,则判断矩为4行4列的矩阵WA。该矩阵的取值根据当前时刻系统运行负载的变化情况和以往经验。在判断矩阵WA中,4列元素从左到右依次代表CPU、内存、外部磁盘、网络带宽4种影响云平台负载变化的评价因素
为了下一步计算,需要对该判断矩阵的列向量进行归一化处理,之后得到新的矩阵WB
对WB按行求和,然后再进行归一化处理,得到权重向量W,该权重向量的每行值对应CPU、内存、磁盘、网络带宽4个评价指标对应在该时刻的权重值
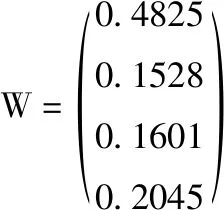
为了验证该权重向量的有效性,需要进行一致性检验。按照前面章节所描述的步骤计算拉姆达的值为4.1441。即可得C.I.的值为0.048 06。查表可知R.I.的值取为0.9,则C.R.的值为0.0534,则C.R.<0.1,即权重向量W的值满足一致性检验,每一行的值即为该时刻对应指标因素的权重值。
2.1.2 动态客观权重
熵权法通过利用指标过去一段时间的变化值,计算该指标的权重,因此被称为是一种客观赋权法。熵权法通过利用指标过去一段时间的变化值,计算该指标的权重,因此被称为是一种客观赋权法。本文数据来源于yahoo webscope数据集,选取其中4个指标为列向量,过去20分钟内的使用率作为历史数据,构建初始数据表。对初始化表进行归一化处理,之后按照公式计算归一化后的数据表中数据,即得CPU、内存、磁盘、网络带宽得信息熵,见表2。

表2 指标信息熵
按照式(6)所示,即得在该时刻4个指标得权重值,结果值见表3。

表3 指标权重
2.1.3 组合评价模型
随着时间的推移,用户不同时刻会用不同的请求,导致云平台的资源消耗处于一个动态变化的状态,4个指标的权重是基于当前时刻各自的使用情况来确定,为了使得到的指标权重符合当前平台的负载情况,则每当资源发生变化时都需要重新计算当前指标的权重值。考虑云平台负载的变化情况,本文采用层次分析法和熵权法计算出各个时刻评价指标的权重值后,将得出的主客观权重值带入拉格朗日乘子,得出各个时刻对应的CPU、内存、磁盘、网络带宽的实时权重。各指标的实时权重与对应的利用率的乘积即是当前时刻云平台的负载值。按照以上步骤,即可得到某实验对象云平台的负载时间序列值,部分结果见表4,该负载值结合了各硬件资源的主客观因素,能够较好反映云平台的实时负载情况。

表4 云平台负载值
2.1.4 结果分析
本文将熵权层次法分别同单纯使用熵权法、层次分析法和固定权重计算得出的负载值对比。采用固定权重的方法虽然考虑了不用资源对负载的影响情况,但其实质是将4种因素的指标和缩小至1/4,不能反映系统资源的真实使用情况。层次分析法反映了CPU是系统关键指标的主观经验,未充分体现其它3种指标的影响。熵权法计算得出的云平台负载值较高,是由于云平台的内存利用率一直处于较高状态,但从计算机系统的角度来看,内存的使用情况并不能代表系统整体的负载。熵权层次分析法则考虑了CPU在系统运行过程中的关键地位的主管经验,同时也客观评估了4种指标的影响程度,计算得出的负载值能够更好反映系统的整体运行状态,较另外3种方法更加科学合理。4种负载评估方法对比如图5所示。
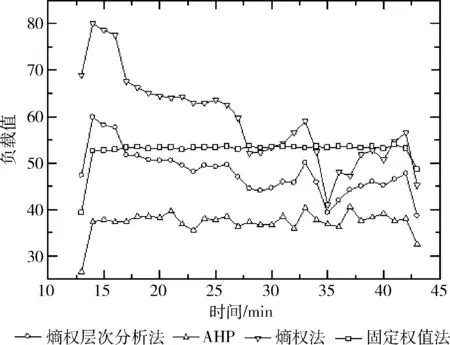
图5 4种负载评估方法对比
2.2 基于ARIMA-BP模型的云平台负载预测
2.2.1 构建ARIMA模型
对云平台负载进行平稳性处理和白噪声检验,得到稳定的非白噪声数据。根据平稳时间序列模型特征系数判断ARIMA模型的参数,模型参数的确定主要通过观察自相关函数图和偏自相关函数图。
如图6所示,是负载数据的自相关(ACF)和偏自相关(PACF)函数图,从图中可以看出,随着滞后期数的增加,时间序列的自相关系数从高值降为低值,逐渐趋向零,符合ACF拖尾的特点。同时,偏自相关系数也从高值降为低值,逐渐趋向0,符合PACF拖尾的特点;自相关(ACF)图和偏自相关(PACF)图都呈现出拖尾现象,可以初步判断该时间序列可以使用ARMA(p,q) 模型。
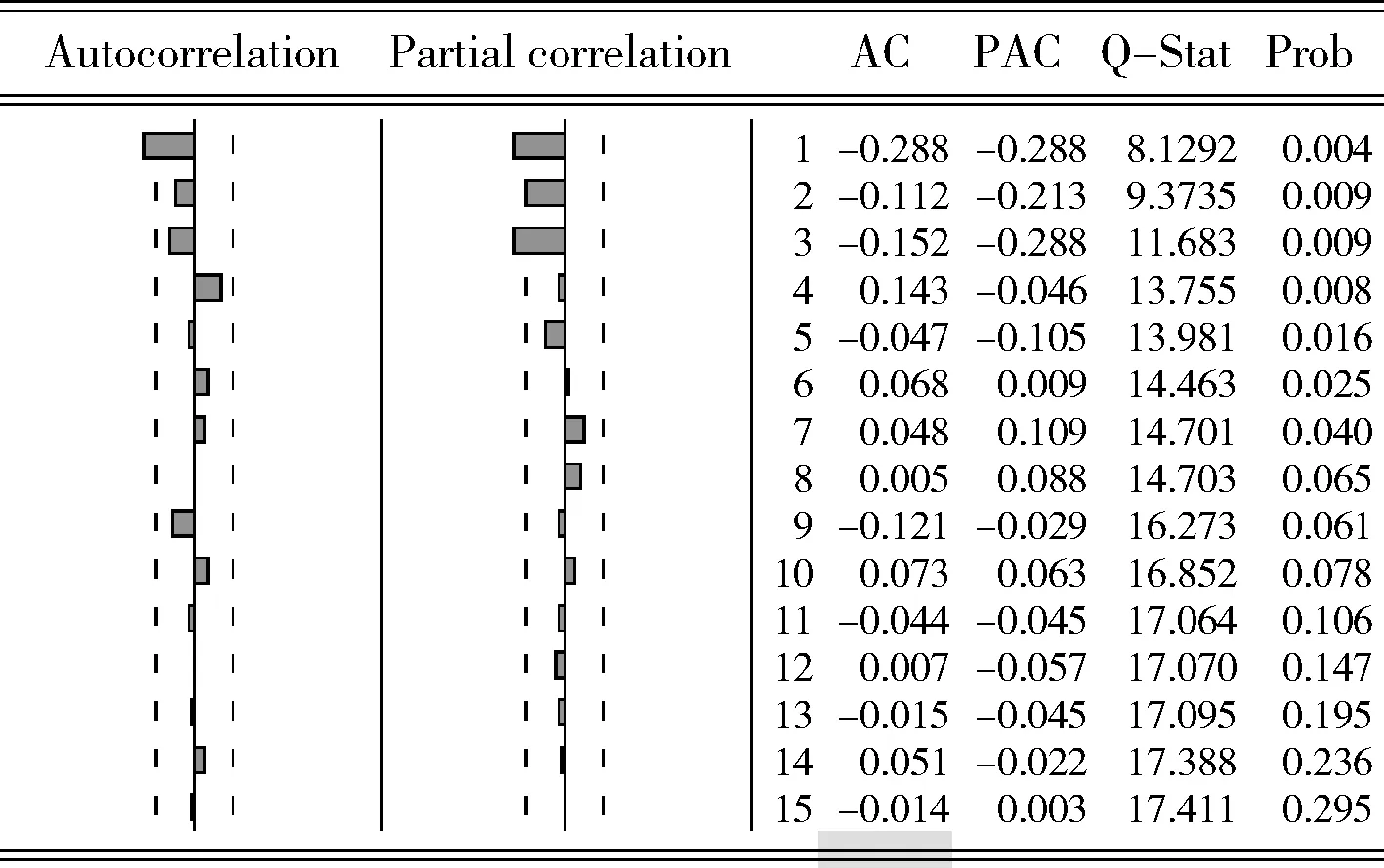
图6 自相关和偏自相关函数
在对序列进行差分处理,结果表明ARIMA(1,1,1) 模型的AIC、SC、HQ值为最小,此时可以选取p=1,q=1,d=1作为模型的参数值,即ARIMA(1,1,1)。 差分结果见表5。
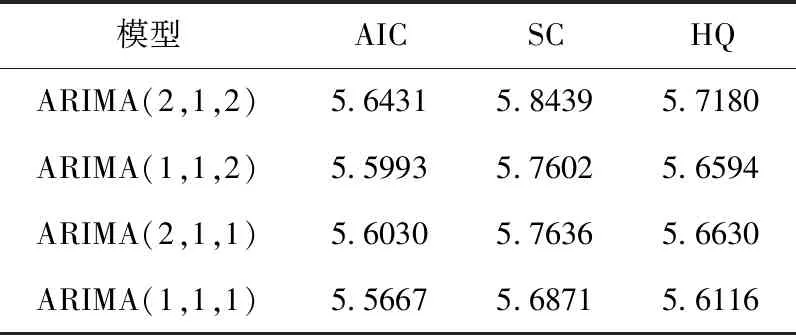
表5 ARIMA模型对比
在使用ARIMA预测负载并计算出负载残差后,利用BP神经网络预测残差值,其中输入层节点个数为4,隐藏
层节点个数为3,输出层节点个数为1,并设置训练网络的其它参数。最后利用ARIMA及保存的神经网络对负载值进行预测。
2.2.2 结果分析
图7是基于ARIMA模型的云平台负载预测值和基于ARIMA-BP组合模型的云平台负载预测值的对比图,可以看到后者更加接近真实值。图8是这两种预测模型的误差对比图,同样可以说明基于ARIMA-BP模型的预测值误差较小,预测精度更高。
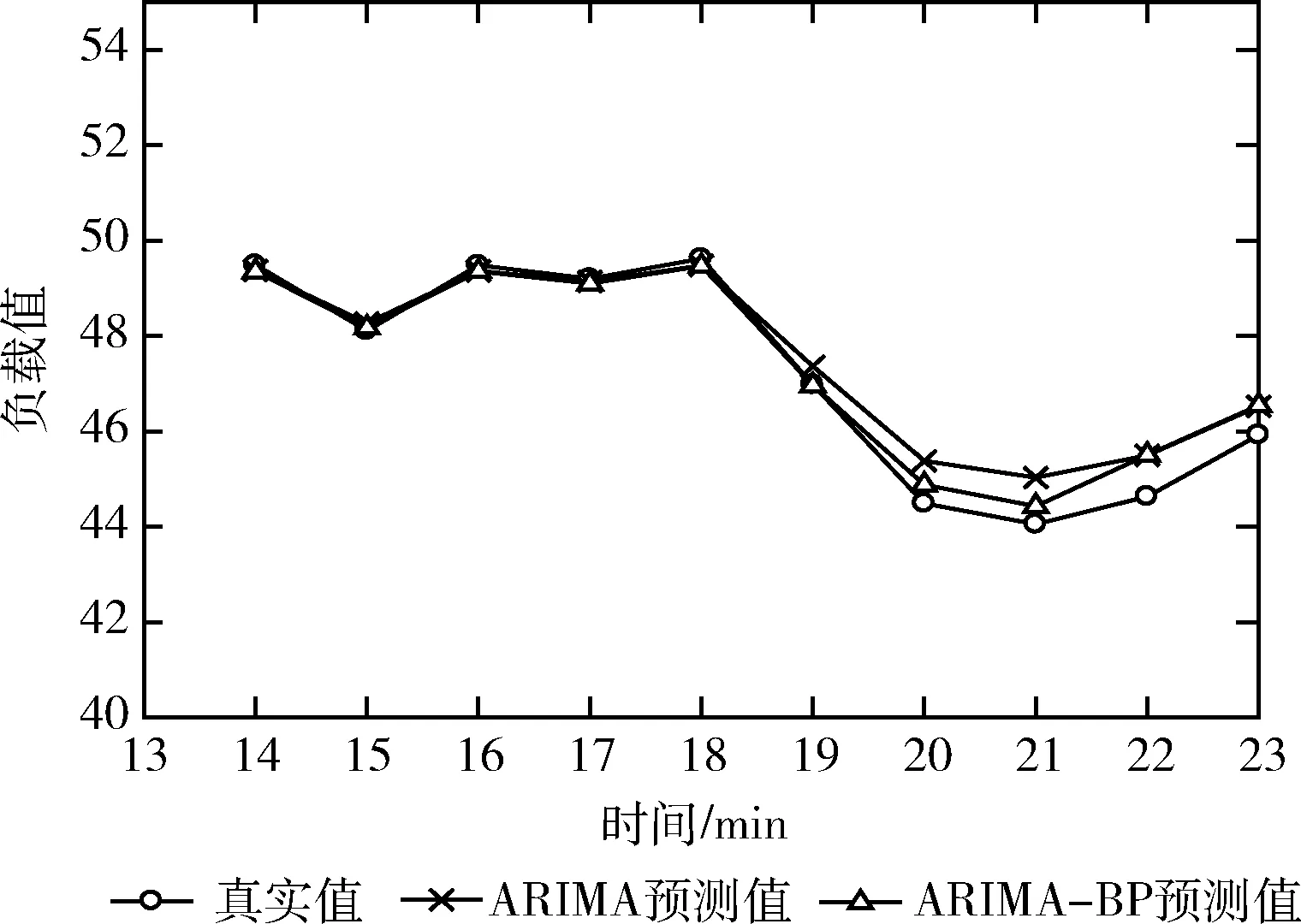
图7 平台负载预测对比
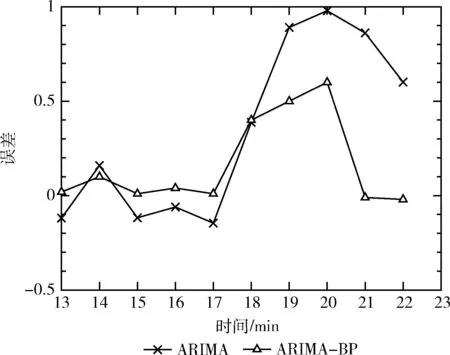
图8 预测误差对比
3 结束语
本文采用熵权法和层次分析法结合的方式建立云平台负载评价模型,该模型采用4种元素加权的方式,评估云平台的负载情况,避免了采用单一元素确定了评价云平台负载的片面性。在选择赋权法时,采用主客观赋权法结合的方式,较使用一种赋权法更加全面合理。
基于ARIMA模型预测了云平台负载数据序列的线性部分,其后采用基于BP神经网络模型预测了云平台负载值的非线性部分。最后将构建基于ARIMA-BP的组合模型,并使用该模型预测云平台负载,所得预测值与期望值相比,满足期望误差,验证了该模型在预测云平台负载值的有效性。
