基于滚动预测平均的监控视频干扰识别方法
2021-01-20杨亚虎陈天华邢素霞
杨亚虎,陈天华,邢素霞,王 瑜
(北京工商大学 计算机与信息工程学院,北京 100048)
0 引 言
作为智能视频监控系统最前端的监控摄像头,对其镜头的遮挡、模糊和旋转等异常进行准确而高效的识别是十分必要的。计算机视觉的发展为异常干扰识别提供了新思路[1]。传统的摄像头异常干扰识别大多仅针对一种异常干扰进行识别[2-5],且通过人工提取特征,最后使用支持向量机(support vector machine,SVM)等分类器实现对摄像头异常干扰的分类与识别。但随着摄像头数目的日益剧增,视频监控系统产生的图像数据也在成指数增加。传统通过人工提取特征再使用SVM等分类器进行摄像头干扰的分类与识别,不仅资源耗费大而且难以达到视频监控对准确率和可靠性的要求。
近年来,深度学习技术在分类、检测和识别[6]等领域表现优越[7]。基于卷积神经网络而衍生的分类网络中,最具代表的是VGG16、VGG19、SqueezeNet、InceptionV4、DenseNet121、ResNet18和ResNet50等端到端的图像分类网络。
将深度学习技术引入摄像头异常干扰识别当中,结合云计算和图像处理器的加速计算性能,为提高识别准确性、可靠性和实时性提供了新方法。文献[2-5,8-10]提出的几种算法,大多将特征提取和分类分步实现,与传统方法相比,这种分步实现异常干扰识别的方法取得了一定的提升,但与端到端的图像分类网络相比,以上方法不仅识别的干扰种类少,而且效率和准确率低,实时性也差。
为此,本文充分借鉴ResNet50优秀的图像分类性能,使用自建的图像数据集微调ImageNet预训练的ResNet50以训练出用于摄像头异常干扰的图像分类与识别模型,最后在训练的模型之上,创造性地运用滚动预测平均算法实现监控摄像头异常干扰视频的分类与识别。
1 ResNet网络
1.1 ResNet网络原理
针对网络层数加深时,训练集和测试集准确率下降的现象,微软研究院的Kaiming He等提出了ResNet(residual neural network,ResNet)网络[11],并通过使用残差单元(ResNet Unit)成功训练出了152层的ResNet网络,在top5上的错误率仅为3.57%,拿下了当年ImageNet比赛中分类任务的第一名。
网络越深,获取的信息越多,而且特征也越丰富。但是根据实验结果表明[11],随着网络的加深,优化效果反而越差,测试集和训练集的准确率反而降低了。这是由于网络加深时,会出现梯度爆炸和梯度消失的问题,以致深层网络无法训练。为此,ResNet通过绕道的方式,既保护了信息的完整性,又简化了学习的目标和难度,如图1为ResNet网络的残差学习模块。

图1 ResNet的残差学习模块
ResNet中有两种映射,一种是恒等映射(identity mapping),就是图1中的X。 另一种是残差映射(residual mapping),也就是图1中的F(X)。 要求解的目标映射为H(X), 由图1可知
H(X)=F(X)+X
(1)
F(X)=H(X)-X
(2)
因此,问题转换为求解网络的残差映射函数F(X), 简化了学习的目标和难度。因F(X) 和X和通道数(channel)不全一样,故式(1)还有另一种表达形式,如式(3)所示
H(X)=F(X)+WX
(3)
其中,W是卷积操作,主要用来调整X的通道维度,常用的方法有全0填充或采用1x1卷积。ResNet网络中主要有两种残差模块,一种是将2个3x3的卷积串接作为一个残差模块,另外一种是将1x1、3x3、1x1的3个卷积串接作为一个残差模块,如图2所示。

图2 两层及三层的ResNet残差学习模块
图2(a)的结构主要针对ResNet34网络,图2(b)的结构主要针对ResNet50、ResNet101和ResNet152网络。因此,ResNet50主要是由图2(b)所示的三层残差学习模块经过堆叠和全连接层构成的具有50层卷积和全连接的深层神经网络。
1.2 ResNet50网络结构
经过三层残差学习模块的堆叠和全连接层构成的ResNet50网络的结构见表1。进行图像分类任务时,输入到ResNet50网络输入层的是224×224像素的RGB图像。

表1 ResNet50网络结构
2 基于滚动预测平均的监控摄像头干扰识别
2.1 微调ImageNet预训练的ResNet50网络
ImageNet数据集是按照WordNet架构组织的大规模带标签图像数据集,由斯坦福大学李飞飞教授领导创建[12],是目前世界上图像识别最大的数据库。ImageNet中共有14 197 122幅图像,分为21 841个类别,带有边界框注释的图像数为1 034 908,主要用于图像分类、目标定位、目标检测、视频目标检测和场景分类等比赛项目。
在实际中,因为数据量小的缘故,很少有人会从零开始去训练一个CNN模型。相反,普遍的做法都是在大的数据集(例如ImageNet)上训练出一个CNN模型,然后提取最后一层卷积层或者倒数第二层全连接层的输出作为CNN的特征,直接使用SVM、贝叶斯或softmax等分类器进行分类,也就是将预训练的CNN视为一个特征提取器,这被称为通过特征提取的迁移学习。
事实证明,相比于通过特征提取的迁移学习,迁移学习的另一种类型-微调可以带来更高的准确性。具体来说,微调就是将在大数据集上训练得到的权重作为特定任务(小数据集)的初始化权重,重新训练该网络(根据需要修改全连接层的输出)。至于训练的方式可以是微调所有层或者固定网络的前面几层权重,只微调网络的后面几层,这样做主要有两个原因,第一是避免因数据量小造成过拟合现象,第二是CNN前几层的特征中包含更多的一般特征(比如边缘信息、色彩信息等),这对许多任务来说是非常有用的,但是CNN后面几层的特征学习注重高层特征,也就是语义特征,这是针对于数据集而言的,不同的数据集后面几层学习的语义特征也是完全不同的。
本文主要使用自建的数据集微调在ImageNet上预训练的ResNet50网络,以训练出摄像头干扰图像分类与识别模型,可视化过程如图3所示,具体步骤如下:
(1)删除预训练的ResNet50网络末端的全连接层(fully connected,FC)与softmax层,如图3(a)所示;
(2)用一组新的随机初始化的FC层和softmax层替换原来的FC层和softmax层,如图3(b)所示;
(3)冻结预训练的ResNet50网络FC层和softmax层以下的所有CONV层,以确保不会破坏预训练的ResNet50掌握的任何先前的强大功能,如图3(c)所示;

图3 微调预训练的ResNet50过程
(4)以很小的学习率(0.0001)来训练ResNet50,但仅训练FC层和softmax层,如图3(c)所示;
(5)解冻预训练的ResNet50网络中的全部CONV层,然后进行第二次训练,如图3(d)所示。
2.2 滚动预测平均实现监控摄像头干扰视频识别
在进行图像分类时,将图像送入CNN,从CNN获得预测,最后选择具有最大对应概率的标签。由于视频是一系列的帧,因此朴素的视频分类方法是,循环播放视频文件中的所有帧,对于每一帧,将其通过CNN,分别对每帧彼此独立地进行分类,选择具有最大对应概率的标签,最后标记帧并将输出帧写入磁盘。但是,这种方法存在问题,它并没有考虑视频的上下文信息也即时序特征,而仅考虑了视频的表观特征。如果将简单的图像分类应用于视频分类,则可能会遇到一种“预测闪烁”,即对于同一个视频类,预测值在正确预测值和错误预测值之间频繁闪烁,对于视频监控,这是绝不允许的。针对这一问题,本文在已经训练好的监控摄像头干扰图像分类与识别模型的基础之上,创造性地提出利用滚动预测平均算法实现监控摄像头异常干扰的视频分类与识别算法,算法具体如下:
Algorithm: Realization of surveillance camera abnormal interference video classification and recognition by rolling prediction average.
input: Surveillance camera interference video file
output: Surveillance camera interference video and its corresponding label
(1)foriinrange(n):
(2) For each frame, pass the frame through ResNet50 fine-tuned on our self-built dataset;
(3) Obtain the predictions from ResNet50 fine-tuned on our self-built dataset;
(4) Maintain a list of the last K predictions;
(5) Compute the average of the last K predictions and choose the label with the largest corresponding probability;
(6) Label the frame and write the output frame to disk;
(7) Show the output image;
(8) i+=1;
(9)end
(10) Release the file pointers.
通过在训练的监控摄像头异常干扰图像分类与识别模型之上运用上述算法,不仅可以对不同类别的干扰视频进行分类与识别,而且可以对同一干扰视频中的不同干扰进行分类识别并快速准确地在不同标签之间切换,实现了监控摄像头干扰视频的准确和高效的分类与识别。
3 实验结果与分析
为验证本文方法的有效性,先构建了监控摄像头异常干扰图像数据集,然后结合迁移学习中的微调方法,采用合适的训练准则对ImageNet预训练的ResNet50进行训练。在训练好的模型之上采用滚动预测平均算法对4类监控摄像头视频(正常视频、监控摄像头遮挡、模糊和旋转视频)进行分类识别,测试监控摄像头干扰识别效果,并与传统和分步的方法进行对比实验。实验硬件平台:Intel(R) Xeon(R) E5-2603v3@1.60 GHz CPU, 8 GB内存, 256 G RAM;NVIDIA Titan XP GPU(12 G显存);操作系统为Ubuntu16.04 LTS;深度学习框架为Keras2.2.4。
3.1 建立监控摄像头干扰图像数据集
监控摄像头异常干扰识别研究中,目前还没有公开的用于监控摄像头异常干扰分类与识别模型训练的数据集。本文通过物联网摄像头、监控摄像头、半球摄像头、移动摄像头和彩色摄像机等设备从真实监控场景采集干扰视频,随后进行切片化处理以创建监控摄像头干扰识别图像数据集,视频采样频率为30 Hz。监控摄像头干扰视频采集过程如图4所示。

图4 监控摄像头干扰视频采集
每个设备都可以采集摄像头干扰视频,然后接入硬盘录像机的视频接口将录像保存在硬盘录像机的特定位置,以便使用U盘和移动硬盘进行复制和后续切片操作。常见的摄像头干扰包括摄像头镜头遮挡、摄像头镜头被喷漆、摄像头镜头旋转或位置移动,因此,人为干预各种监控设备以拍摄出本文预期的摄像头干扰视频,包括使用卡片、手掌或树叶遮挡摄像头、向摄像头喷洒粉尘、左右或上下旋转摄像头。需要注意的是,所有监控设备的视频采样频率都已被事先设置成30 Hz。本文分别在早晨、中午、下午3个时间段进行了摄像头干扰视频的采集任务,目的是使训练数据包含更丰富、更全面的信息,从而使得训练的模型更具有泛化性和鲁棒性,更好地适应监控场景的复杂性,如图5所示。

图5 不同时间段的小区监控摄像头遮挡图像
将监控摄像头干扰视频录像逐个切片化处理后,人工筛选出摄像头遮挡、摄像头被喷漆和摄像头被旋转的图像。为了让视频监控系统对正常情况(除了摄像头遮挡、摄像头被喷漆和摄像头旋转)也有所区分,在所构建的数据集中加入了正常类。为了丰富训练集,更好提取特征,泛化模型,本文主要采用了旋转图像、改变图像色差和改变图像尺寸的数据增强方式来扩大数据集、丰富图像特征,如图6所示。

图6 数据增强操作
由于监控设备的像素值存在差异,本文将切片后的图像都统一成了500pixel×281pixel。经过图像增强后,数据集中共有5400幅图像可用于摄像头干扰识别模型的建立,所有类别的百分比都为25%,说明该数据集在学习不同类别的分类模型方面具有很好的平衡性,最终将75%作为训练集,25%作为验证集。表2给出了该数据集的具体信息。
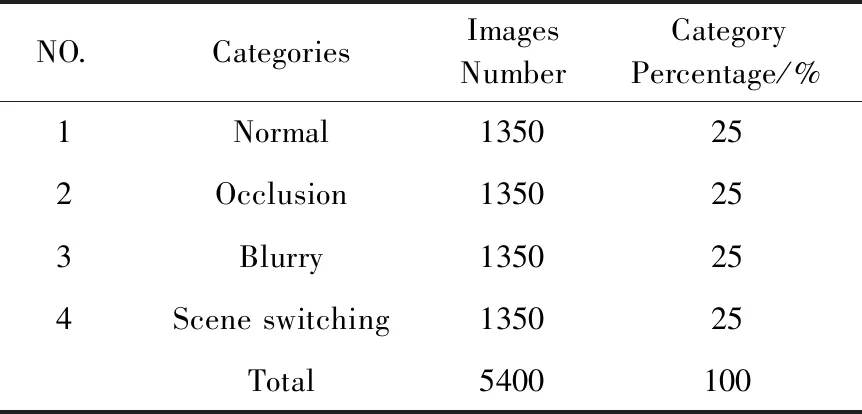
表2 所构建数据集的具体信息
3.2 监控摄像头干扰识别模型训练与评价
将数据集分为75%训练,25%验证,即训练集4050幅图像,验证集1350幅图像。在预训练的ResNet50网络上进行训练和验证,最后在80个未知的监控摄像头干扰视频上利用训练的模型进行测试。模型基于深度学习框架Keras2.2.4,在一个具有显存为12 G的NVIDIA Titan XP GPU和256G RAM的Intel(R) Xeon(R) E5-2603 v3处理器上进行了训练、验证和测试。训练时,训练批次大小为64,对ImageNet预训练的ResNet50网络进行微调,使用初始学习率为0.0001,动量为0.9,每50次迭代学习率下降0.0001的SGD(stochastic gradient descent)优化器。训练集和验证集的图像尺寸都为500pixel×281pixel。
损失函数用于估计模型的预测值与真实值之间的不一致程度,它是一个非负实值函数,通常由L1或L2正则化项表示。本文网络使用的损失函数是交叉熵损失函数,损失函数的公式为
(4)
其中,M表示类别数,yc表示类别c的真实值,pc表示类别c的预测值。损失函数越小,两个概率的分布越接近,模型的鲁棒性越好。图7显示了训练和验证过程的准确率和损失函数图。
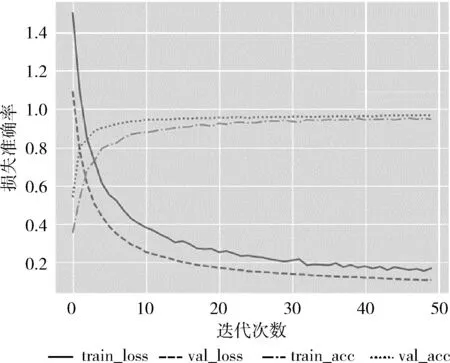
图7 训练和验证过程的损失函数
由训练和验证过程的准确率和损失函数图可知,经过本文数据集微调之后的ResNet50可以对该数据集进行准确的分类,最终在验证集上可达97%的分类准确率,且损失函数的变化平稳,最终在第50个epoch时达到0.1612,说明预测值已非常接近真实值。
除了训练和验证过程的准确率和损失函数图,本文还采用查准率(precision)、查全率(recall)、f1分数(f1-score)、微平均(microavg)、宏平均(macroavg)和加权平均(weightedavg)对分类结果进行全方位评价。
如果真实类别为正例,预测类别也为正例,则为真正例(TP),如果真实类别为负例,预测类别为正例,则为假正例(FP),如果真实类别为正例,预测类别为负例,则为假负例(FN),如果真实类别为负例,预测类别也为负例,则为真负例(TN)。查准率主要度量分类器对某一类别预测结果的准确性,对所有类别的查准率求和取均值后可以得到整体精确率,其计算如式(5)所示。查全率主要度量分类器对某一类别预测结果的覆盖面,对所有类别的查全率求和取均值后可以得到整体覆盖面,其计算如式(6)所示。综合考虑查准率和查全率两个指标,就得到了f1分数,主要度量分类器对某一个类别预测结果的精确性和覆盖面,它是查准率和查全率的调和平均值,其计算如式(7)所示。在评价多类别分类器的效果时,把所有类的f1分数取算数平均后就得到了宏平均,主要度量常见类效果。微平均主要度量稀有类的效果,其计算公式如式(8)所示,但在实际中,宏平均比微平均更合理
(5)
(6)
(7)
(8)
根据以上公式,训练好的模型在本文数据集上的各种评价结果见表3。

表3 验证集评价结果
由表3可知,训练好的模型对监控摄像头干扰图像数据集具有良好的分类性能。对1350幅验证集图像进行验证,包括正常图像(normal)338幅、模糊图像(blurry)337幅、遮挡图像(occlusion)337幅和摄像头旋转图像(scene_switching)338幅。每一类的precision、recall、f1-score都非常接近1,说明模型的分类性能良好。microavg、macroavg和weightedavg都为0.97,达到了97%的验证集分类准确率,充分说明训练的模型在不同类别之间具有优秀的分类准确性和平衡性,可用于监控摄像头干扰视频的分类识别任务。
3.3 监控摄像头干扰视频识别结果与分析
在验证集上详细评价了训练的分类模型的性能之后,最后结合滚动预测平均算法对80个测试集视频进行测试,并采用准确率、漏检率和误识率进行客观评价,以观察本文所提出的算法和所训练的模型在监控摄像头干扰视频上的识别表现,部分测试视频识别结果如图8所示,总的测试集识别结果见表4。
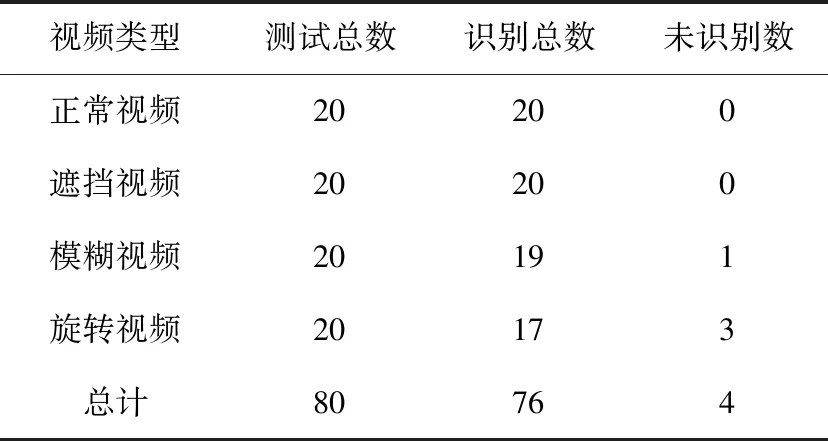
表4 测试集视频识别结果

图8 部分测试视频识别结果
如图8所示,包括正常的监控视频在内,不仅各类监控摄像头干扰视频都被打上了各自对应的标签(视频画面左上角),而且对于同一个干扰视频中的不同干扰类别,也可以进行快速分类与识别,完全可以满足以计算机视觉和模式别为核心的第三代智能视频监控的需求。
结合表3和表4可知,对正常图像和遮挡图像的分类效果并没有对模糊图像和旋转图像的分类效果好,但在视频识别时,对正常视频和遮挡视频的识别效果要比对模糊视频和旋转视频的识别效果好,这也充分验证了视频识别不仅要考虑表观特征(静态特征)还要考虑时序特征(动态特征)的结论,而图像分类识别仅需考虑表观特征,所示视频分类识别要远比图像分类识别复杂。
为了客观评价监控摄像头异常干扰视频的分类与识别结果,本文采用了文献[2]的准确率、漏检率和误识率评价准则,计算得到的各类视频及总体的准确率、漏检率和误识率见表5。
由表5可知,本文方法达到了95%的监控摄像头异常干扰视频识别准确率,漏检率和误识率都相对很低,分别为5%和6.7%,其中对正常视频和遮挡视频的识别效果最好,模糊视频次之,旋转视频最差,这也源于旋转视频图像难以获得、视频内容包含场景切换的过程等原因。

表5 准确率、漏检率和误识率客观评价
为了进一步验证本文方法的有效性,本文与传统和分步的摄像头干扰识别方法在本文数据集上进行了比较,比较结果见表6。

表6 不同算法的实验结果对比
根据实验对比结果可以看出,与传统和分步的监控摄像头异常干扰识别方法相比,本文方法的准确率、漏检率和误识率都有很大的提高,这源于:①通过在ImageNet数据集预训练ResNet50网络,合理地运用了ImageNet强大的先验知识。②受视频动作识别[13]的启发,本文创造性地将滚动预测平均算法应用于监控摄像头异常干扰识别,实现了监控摄像头干扰识别的新突破。综合以上分析,本文方法对监控摄像头异常干扰识别整体识别性能更好,从而验证了本文所提监控摄像头干扰识别方法的有效性。
4 结束语
本文提出了一种基于滚动预测平均的监控摄像头异常干扰识别方法,首先利用构建的数据集采用迁移学习中的微调方法对ImageNet预训练的ResNet50网络微调,以训练出监控摄像头干扰图像分类与识别模型,然后在训练的模型之上结合滚动预测平均算法实现了监控摄像头异常干扰视频的分类与识别,识别准确率达到了95%。与传统和分步的监控摄像头异常干扰识别方法相比,本文方法在准确率、漏检率和误识率方面都有很大提高,综合性能更好,验证了本文所提方法的有效性。在下一步研究中,将进一步降低漏检率和误识率,提高准确率。
