基于边缘节点的深度神经网络任务分配方法
2021-01-20陈明浩陈庆奎
陈明浩,陈庆奎
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
近几年物联网的发展,数以百千万个边缘节点通过无数网络节点链接在一起进行数据交互、分析,同时越来越多的节点设备也在通过物联网方式不断加入,边缘设备的智能化已经大势所趋[1]。由于边缘节点自身硬件资源限制,往往需要通过远程的云计算资源为用户提供相关服务,云端服务器仍承担着巨大的计算负载[2]。因此在边缘节点上搭载神经网络成为新的趋势。但由于节点设备自身硬件性能与网络通信环境的限制,目前难以全部实现[3]。
为了解决低性能边缘节点难以搭载神经网络的问题,本文提出通过改进Roofline模型对通信环境、边缘设备与神经网络参数三者进行动态评估,并根据评估指标对不同的神经网络计算任务进行动态适应性划分方法,使得边缘节点与服务器节点能够共同完成神经网络计算任务。实验结果表明,对计算任务的适应性分配,能够避免边缘节点计算资源的浪费,降低服务器节点的通信与计算开销。该方法克服了边缘节点的硬件条件限制,将边缘设备与神经网络进行有效结合,表现出优良效果。
1 相关工作
目前将神经网络计算与边缘设备节点相结合主要分为两种方式:①运用客户端/服务器架构模式(C/S模式);②对网络模型进行优化。
传统的C/S架构模式,是指通过边缘节点获取数据信息,将采集的信息传输至中心服务器,服务器结合神经网络进行数据处理分析。该模式保证了计算结果的高精度性,并避免了边缘设备终端的自身硬件性能的限制。但C/S架构模式面临着的巨大通信开销,以及服务器资源分配调度等问题。文献[4]提出通过对于通信数据进行压缩,优化传输功耗实现了通信时间延迟以及边缘节点的物理损耗。文献[5]结合了边缘设备任务优先级,设备运算性能,任务完成时间等条件,自适应调用Max-Min与Min-min算法进行任务分配。但边缘设备节点不断增多,中心服务器仍面临着巨大的负载压力。
优化网络模型,则主要分两种情况。第一种情况,若边缘设备硬件条件良好,则对传统神经网络模型进行参数压缩从而达到模型优化。文献[6]通过在保证网络结构的前提下进行网络修剪,去除不重要的网络连接,减少模型冗余,达到降低模型复杂度的目的。文献[7]基于迁移卷积滤波器的方式设计新型结构卷积滤波器,缩小计算规模。文献[8]指出借助复杂的神经网络训练结果训练新型网络,从而减少计算开销,优化网络模型。第二种情况,若边缘设备自身硬件性能较为低下,难以支撑传统的神经网络模型,则选择搭载轻量化网络模型。轻量化模型主要通过改变自身网络结构,减少参数量,从而减少存储空间的占用,降低计算开销。轻量化模型主要包括:①基于流线型架构,使用分离卷积核,深度可分离卷积的MobileNet[9];②借鉴ResNet[10]分组卷积,采用各点卷积的ShuffleNet;③采用个点卷积,并利用Squeeze layer限制通道数的SqueezeNet[11]等。神经网络模型的轻量化,让越来越多节点设备能够成功搭载神经网络,使之得到充分的利用。但模型的压缩与轻量化难以保证运算结果精度的准确性,目前生活中仍有大部分边缘节点设备无法支持轻量化模型的计算。
为了使边缘计算节点进行神经网络计算,同时避免上述两种方式的现有问题。本文提出了一种创新性地解决方案,在确保计算结果准确性的同时减轻服务器原计算负载与传输延迟,即对深度神经网络模型进行可分离式拆分。根据不同节点设备的网络环境与硬件性能瓶颈,动态分配计算任务,其它部分计算任务则通过网络传输由中心服务器进行完成。从而充分利用大批移动设备的空闲计算力,使边缘设备得到利用,同时降低传输延迟,减轻服务器的负载压力。
2 模型分析
本文对Roofline模型进行改进,选取神经网络模型作为分析对象。结合节点设备自身性能以及网络环境,分析设备在网络计算过程中产生的计算与通信开销,进行动态计算任务分配。
2.1 节点设备与网络模型的性能评估
神经网络模型与节点设备需要相互“配合”,才能发挥各自的性能优势。因此不仅需要对节点设备进行分析,还需要对网络模型进行性能评估。伯克利大学并行计算实验室的Williams和Patterson提出了Roofline模型,该模型可将复杂的性能问题进行可视化描述从而进行相关的性能评估[12]。Roofline模型指出计算设备的性能指标主要有两点:①每秒浮点运算最大次数π(单位FLOP/s),指的是系统每秒内所执行的最大浮点运算次数。②内存带宽上限M(单位 Byte/s),指的是系统每秒可进行内存交换的字节数最大值[13]。模型同时提供了评估网络模型性能的指标:①计算量O(单位FLOAPS)指模型进行一次完整的输入计算所产生浮点计算总数。②内存访问量T(单位 Bytes) 指模型进行一次完整的输入计算能够达到最高的内存交换量,亦称作空间复杂度。③计算密度I(单位 FLOP/Byte):指模型的计算量与内存访问量的比值,计算方式如式(1)所示
(1)
2.1.1 Roofline模型
提出Roofline模型的目的是为了能够创建适用于共享内核系统的可视化模型。发展至今,该模型已被广泛用来评估设备系统性能[14]。它表达出设备的内存带宽与设备最佳性能之间的关系,节点设备实际可达到的最大浮点计算量F的计算方法如式(2)所示
(2)
当计算密度小于某一阈值Imax时,节点可达到的最大计算性能,受自身内存带宽上限控制。当计算密度大于阈值Imax时,可达到的计算性能取决于系统的最大浮点计算性能上限π,其关系如图1所示。

图1 Roofline模型构
2.1.2 Roofline模型的扩展
由于原始Roofline模型一般研究的对象为单机平台理论评估,并没有考虑到节点设备在实际应用中与外部机器进行数据通信占用系统性能的情况。为了评估因数据通信产生的影响,本文对传统Roofline模型进行改进,引用新的参数指标:①数据通信带宽Mc(单位BPS),指设备进行数据通信时单位时间内传输的数据量。②网络传输字节数N(单位Byte),指设备进行一次数据网络通信传输的字节数。③通信计算密度Ic(单位 FLOP/Byte)指设备在单次网络通信中设备总计算量与通信字节数的比值,其计算方式如式(3)所示
(3)
节点设备在进行数据通信时,可达到的最大计算性能F计算公式如式(4)所示
(4)
由式(4)可看出,当系统应用的通信计算密度小于特定阈值Icmax时,系统的达到的最大计算性能由通信带宽主导。当通信计算密度大于阈值Icmax时,可达到的最大计算性能受限于该系统的浮点计算性能上限π。在原始Roofline模型基础上进行改进,通过将通信计算密度与数据通信带宽替换原始模型中的平台计算密度与存储器带宽可以得到新Roofline模型如图2所示。

图2 新Roofline模型
2.2 模型相关分析
2.2.1 计算分析
本文选取卷积神经网络作为分析对象,卷积神经网络主要包括卷积层、线性整流层、池化层、损失函数层[15]。不同神经网络模型之间结构的主要区别在于计算层的数量以及排序不同。卷积层是卷积神经网络最重要的一环,并且它数据计算量占据了整个网络计算量的绝大部份,因此以卷积层为例并进行着重分析,其它层的计算方法与卷积层计算方法类似将不详细介绍。卷积层的结构如图3所示。

图3 卷积层解析
从图3中可看出,卷积层的输入参数:Hn为输入的高度,Wn为输入的宽度,常规计算中有Hn=Wn,Dn为输入的深度。卷积核的计算参数包括:Fh为卷积核的高度,Fw为卷积核的宽度,常规计算中Fh=Fw,Fd为卷积核的深度,默认卷积核深度与输入核深度相同,卷积核个数为N。单层卷积的输入参数量Tn如式(5)[16]所示
Tn=Hn*Wn*Dn
(5)
卷积核的总参数量Fn如式(6)所示
Fn=Fd*Fh*Fw*Fd*N
(6)
单层卷积总计算开销公式Cn如式(7)所示
Cn=Hn*Wn*Fh*Fw*Fd*N
(7)
单层卷积产生的内存访问开销Mn满足式(8)
(8)
卷积神经网络完成一次前向传播总计算量Ctotal,总内存访问量Mtotal满足式(9)、式(10)
(9)
(10)
2.2.2 通信分析
为了简化模型,我们不考虑内存之间,或网络波动产生的延迟。为了确定计算中的动态参数值,编写一个简易的“弹球准则”脚本来进行对网络通信带宽的测量[17]。在测试中,节点设备发送指定固定大小的通讯消息至中心服务器,服务器收到消息后回复同样大小的消息。节点设备通过计时器获取从发送消息到接收回复消息的时间T,消息字节大小为S,通信带宽为Mc,其计算方法如式(11)所示
(11)
假定第N层卷积层为任务分割层,则需要在完成卷积操作后将该层的计算结果进行数据传输。则该传输数据量大小TDn如式(12)所示
(12)
其中,Hn+1为完成第N层卷积层的输出数据尺寸,Dn+1为输出数据的深度,其中4 Bytes为矩阵中单位值所占大小。
卷积神经网络模型完成一次完整的前向传播计算传输的总数据量TDtotal满足式(13)
(13)
数据通信效率更多依赖于网络带宽,若计算数据量较大时,数据通信往往更容易成为设备平台的性能瓶颈。
2.2.3 模型综合分析
为了能够综合性评估设备运行模型的性能,同时考虑节点设备的计算开销与通信开销。结合原始Roofline模型与新Roofline模型,构建全新的三维模型,如图4所示。借助新模型可以更明显观察出计算密度与通信计算密度对计算平台浮点运算瓶颈产生的影响。新模型主要参数包括浮点计算量、存储器带宽、通信带宽、计算密度、通信计算密度。

图4 Roofline三维模型
从图4中可看出在不同计算密度以及不同通信密度条件下,系统可达到的最大运算性能。X轴代表计算密度,Y轴代表通信计算密度,Z轴代表设备可达到的计算性能。系统进行一定卷积计算任务时,若通信计算密度固定不变,伴随计算密度的提升,系统的运算性能随之增加。同时,若计算密度不变,改变通信计算密度大小,系统的运算性能也将改变。如果当前应用的计算密度很大时,整个平台性能可达到的性能上限将受到通信密度的制约,此时对数据通信方面的优化对平台产生的影响远比优化计算密度产生的影响大的多。当计算密度与通信计算密度分别各自达到特定值时,计算平台才能充分发挥其最大计算性能。
结合网络模型的计算量分析、数据通信量分析以及系统自身性能参数,可适应性分配给计算设备相应的计算任务。假定设备自动分配k层计算任务,完成第n层卷积计算时可达到的浮点计算性能fn如式(14)所示,设备完成计算任务时间记为TCn。在获取每层计算峰值性能后,可预估出设备完成各层计算任务的时间以及完成一次完整模型计算所需时间TCtotal如式(15)所示,从而进行任务分配,但设备信息或设备环境发生变化时将自动重新评估分析
fn=Min(π,M*I,Mc*Ic)
(14)
(15)
相比于传统模式服务器运行全部计算任务,利用设备节点计算大大减少了服务器的运行负载,内存访问以及运行时间。服务器减少的计算负载量CS如式(16)所示
(16)
服务器减少的内存访问量MS如式(17)所示
(17)
网络数据通信减少的传输量TD如式(18)所示
(18)
2.2.4 系统运行分析
当边缘设备接收到计算指令,结合自身硬件资源与当前网络状态,借助Roofline三维模型进行性能评估,若当前性能足以支持完成对应层计算任务,则进行下一层,否则返回上一层,并以该层数作为任务划分层。若网络环境发生较大波动时则将重新进行性能评估与任务分配,以确保已分配任务的可执行性。任务完成后,将分层信息与参数传输至服务器。
服务器接收到信息后进行下一步处理,若服务器为单节点模式架构,其余任务将直接由该节点进行完成。
若服务器为多节点分布式架构,则需先根据Roofline模型评估各个从节点的实际计算力并进行排序。每当主控制节点接收到计算指令后,将扫描各个从节点的工作状态,若从节点存在空闲节点则按照先前顺序进行任务分配,若不存空闲节点则借助AP哈希算法进行任务调度分配,尽量使各个从节点均衡负载,避免某个服务器压力过大情况的发生。
2.3 算法分析
每当系统设备接收到计算指令,进行计算前,首先获取系统相关参数,测试网络状态,并将设备闲置时间作为分配任务的时间上限Free_T,结合分析深度网络模型,进行任务分层划分[18]。具体的分配步骤如下:
(1)获取当前状态设备系统,模型信息,并分析相关参数,模型层数以及每层计算层的计算量与内存访问量;
(2)系统与服务器之间进行数据通信,获取当前网络实时带宽;
(3)根据相关公式计算出系统计算以及通信计算密度,并确认当前状态下系统在各层所计算时所能达到的最佳浮点性能(步骤(1)~步骤(3)参考算法1);
(4)根据每层的参数以及系统可达到的计算性能可得出每层消耗时间Ti;
(5)将每层的耗时累计,若到达N层时,耗时累计超过Free_T,则返回N-1层;
(6)将第N-1层作为界限进行任务划分(步骤(4)~步骤(6)参考算法2);
(7)若下一次计算时,则返回步骤(1)重新进行任务划分。
算法1: 计算与数据通信分析伪代码:
Data calculation and communication analysis of equipment
Get the System.info.
Get the Layer.info.
Time_begin = sys_gettime();
While{
length = Recv(Client_socket, buffer, Data 0);
Send_num++;
Time_end = sys_gettime ();
Time[send_num] = (Time_end - Time_begin)/2;
Mc[send_num] = Data /Time[send_num];
If(send_num == 20):
Break;
Send(Client_socket, buffer, Data, 0);
}
I ← O_Pre/T; /* Operational intensity*/
Ic ← O_Pre/N; /*Communication arithmetic intensity*/
If (M*I>π) & (Mc*Ic>π):
F←π;
Else:
F←Min(M*I, Mc*Ic);
Return F
END
算法2:计算任务划分伪代码:
Data calculation and communication analysis of equipment
Get the System.info.
Get the Layer.info.
Get the equipment free time.
For N = 0→Layer:
LayerTime[n]← O_Pre/F;
If Sum(LayerTime)<=Free_T:
N++;
Else:
Break;
END
分布式服务器主控制节点收到新的计算请求,对本次任务进行分析,结合集群中可利用的计算资源,进行任务分配。具体计算步骤如下:
(1)服务器控制节点通过广播,对所有服务器进行检测,获取可用的从节点资源集合List。每个从节点属性涵括其GPU算力,最大带宽,节点状态等。如果List为空,则继续步骤(1),否则进入下一步;
(2)为了能够确定最优分配方案,需先对List内各个节点借助Roofline模型计算出实际计算能力,并依照结果进行排序(步骤(1)~步骤(2)参考算法3);
(3)接下来分情况讨论,若存在多个空闲服务器节点,则依照排序将任务分配给算力最高的节点。若只存在一个空闲服务器节点,则直接进行分配。若无处于空闲状态的节点,则借助APHASH算法进行分配(参考算法4);
(4)配置执行脚本开始执行。
算法3:计算服务器节点实际计算力并排序:
Calculate computing power of the server node and sort
Get the Server.info.
Get the Layer.info.
I_Server←O_Other/T;
For(i=0;i M_Server ←List[i].[BandWith] If (M_ Server *I_ Server > π): List[i].[Computer]←π Else: List[i].[Computer]←M_ Server *I_ Server; QuickSort(List,left,right) Return List END 算法4:服务器节点任务分配: Task assignment of Server Node Get the Server.info. List_State = False If (List.length == 1): UseNode = List[0] Else: For(i=0;i If (List[i].state == Free): UseNode = List[i] List[i].[Computer]←π If (List_state == False): UseNode←APHash(List) Return UseNode END 本次实验设备由中心服务器与边缘节点设备构成,因由实际条件限制,服务器采用的是单节点模式架构。实验设备信息如下:中心服务器GPU为GTX1080,8 G显存;边缘节点设备采用的是树莓派3B型,其CPU采用的是四核1.2 GHz Broadcom BCM2837 64位处理器 1 G 内存。实验环境,树莓派编译环境采用的是Tensorflow 1.7,服务器采用的是Tensorflow 1.3,IDE工具为Anaconda-Navigator,本文采用LeNet-5以及OpenPose神经网络模型,通过改变任务计算量、网络环境进行对比实验分析。 为了防止模型计算任务过大从而导致系统宕机,首先对结构简单、计算量较少的LeNet-5进行分析,LeNet-5网络具体参数见表1[19]。 表1 LeNet-5网络具体参数 从表1可得出完成一次LeNet-5网络前向传播计算开销约为13.88 MFLOPS,内存访问量约为13.45 MB,因此可计算出该网络模型的计算密度约为1.03 FLOP/Byte,根据官方文档所示,树莓派3B型的内存带宽M为1 GB/s。π为24 GFLOPS从表2可得出系统进行数据传输速率基本不变,相对稳定,限定传输速率平均在8 MB/S,系统数据通信密度约为38 FLOP/Byte,由此可见在本次LeNet-5计算过程中,系统性能受到双条件约束:①计算任务的内存限制;②系统通信带宽限制,因此可提升计算任务工作量与复杂度,并对网络通信环境进行改善。 实验以200张图片作为一个测试单位,计算完成后并以二进制文件进行数据传输。由于实验网络中采用的每一层计算输入输出矩阵尺寸基本不变,其数据量在输入图片尺寸相同的情况下相对固定,因此本次计算数据量的大小取决于设备本身采集图片的清晰度大小。实验完成相应分层任务后进行数据通信的结果见表2。 表2 数据通信结果 通过实验发现,边缘节点设备可以完成对于简单网络模型计算分层处理,于是我们通过在系统上运行OpenPose网络进行分析[20,21]。因OpenPose网络过于复杂,本实验仅对模型前26层进行分析研究,OpenPose网络具体参数见表3。 表3 OpenPose网络具体参数 从表2可得出完成一次OpenPose网络前向传播计算开销约为31 GFLOPS,内存访问量约为191.4 MB,因此可计算出该网络模型的计算密度约为163 FLOP/Byte。π为24 GFLOPS从表2可得出系统进行数据传输速率基本不变,相对稳定,由于网络环境限制,传输带宽最高保持在速率25.5 MB/S,系统数据通信密度约为166 FLOP/Byte,由此可见在本次OpenPose计算过程中,系统的计算性能受通信带宽限制,提高网络带宽是当前提高系统性能的有效办法。以单张图像为例,不同分割层完成计算后进行数据通信传输时间如图5所示。 从图5中可看出,伴随划分层数的深入,节点设备的通信传输时间不断减少,最多甚至可减少90%以上。对于设备系统来说减少了系统通信开销,释放了更多的系统资源。单个节点通信时间减少产生的影响并不显著,但若应用到大规模节点设备中并采用分布式服务器架构,则将大幅度降低网络通信负载。 图5 通信时间 通过将系统置于不同网络环境下并搭载不同神经网络模型进行实验,可分析出网络环境质量的好坏以及任务计算量的大小对于系统性能造成的影响。 系统搭载LeNet-5模型时,在进行不同计算层划分时系统实时性能如图6所示。 图6 系统运行LeNet-5性能 搭载OpenPose模型时,在不同层进行切分时系统达到的实时性能如图7所示。 图7 系统运行OpenPose性能 结合图6、图7可看出,在不同的计算任务下,节点设备性能表现截然不同,若在网络环境良好状况下,计算任务的计算量越高,则系统内存访问量越高,节点实时性能随之提升,直至达到峰值。因此,边缘节点设备则可结合当前网络通信环境,以及自身可达到的性能峰值对计算任务进行动态划分。 若在网络环境较差的情况下,任务的高数据计算量已经无法提升系统的性能瓶颈,因此节点设备将自适应地选择数据传输量相对较少的计算层进行分离。若边缘设备出现无法连接网络情况,则自动停止分配计算。 设备根据自身硬件性能与不断变化的网络环境,动态分配边缘节点计算任务,有效减轻服务器负担。以搭载OpenPose模型实验为例,设备搭模型,伴随网络模型分离的深入,服务器的负载逐渐降低,更多的时间、空间资源得到释放。系统设备分配到的计算层数越多,服务器的所需承受压力越少。实验中服务器GPU负载减少量具体情况如图8所示。 图8 服务器负载减少量 本文对传统的边缘节点计算模式进行改进,不再将全部的计算任务交付服务器进行计算,从而避免边缘设备的计算资源与网络通信的浪费。通过使用全新的方法,基于边缘设备系统性能以及设备网络环境对神经网络模型进行合理的动态分离,充分利用了设备系统的闲置性能,减轻了服务器的负载压力,提高了整个网络系统的兼容性与计算通信性能。本文以卷积神经网络为例,通过对性能评估模型的改进对设备系统、通信环境和计算任务进行定量评估。同时此模型通用适合其它情境下的计算分析,具有一定的实际通用性。 在接下来的工作中,仍需要对整个系统的运行进行监测,同时考虑系统自身物理损耗造成的性能影响并进行算法改进,以便有效改善应用系统,进行更为准确的评估分析。3 实验分析
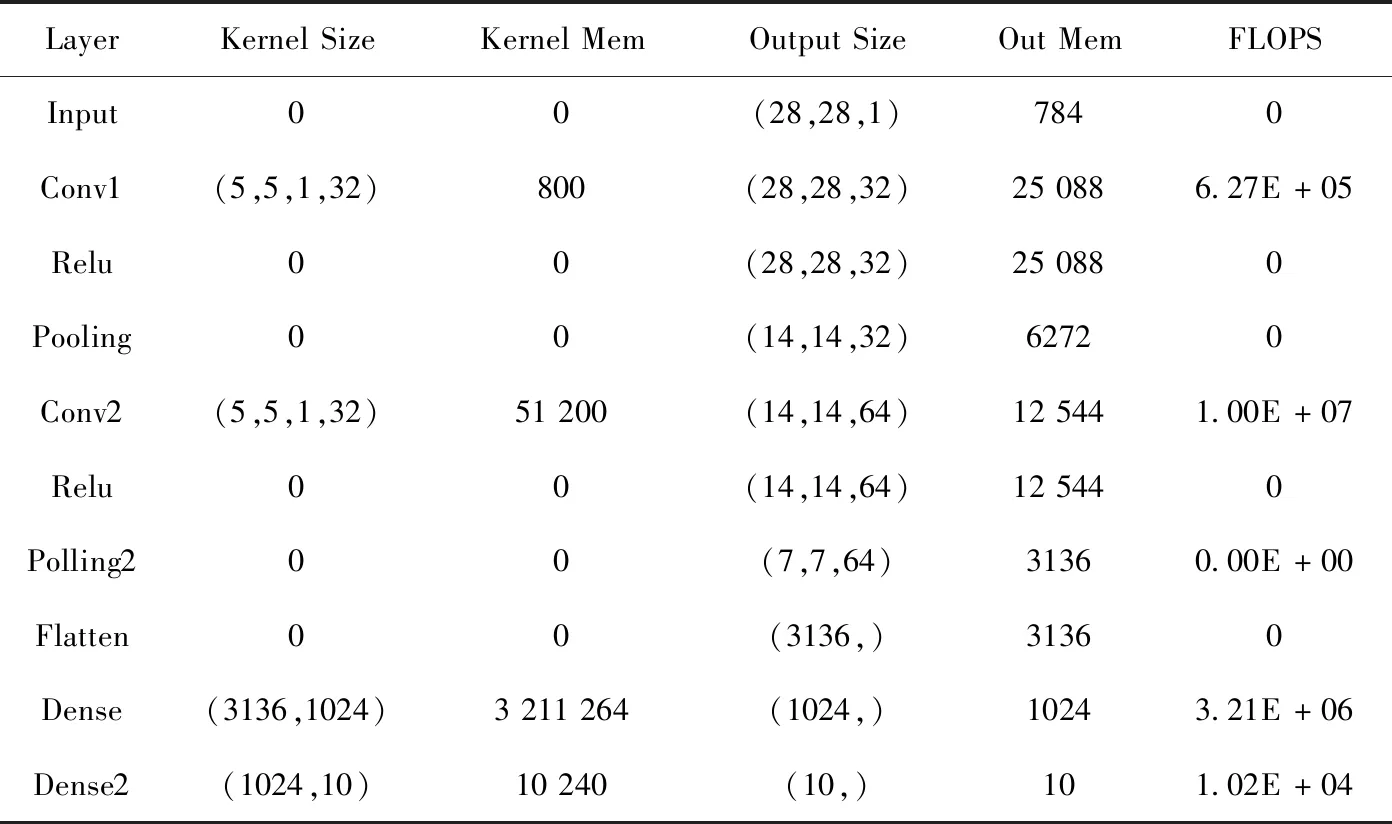
3.1 LeNet-5结果及分析

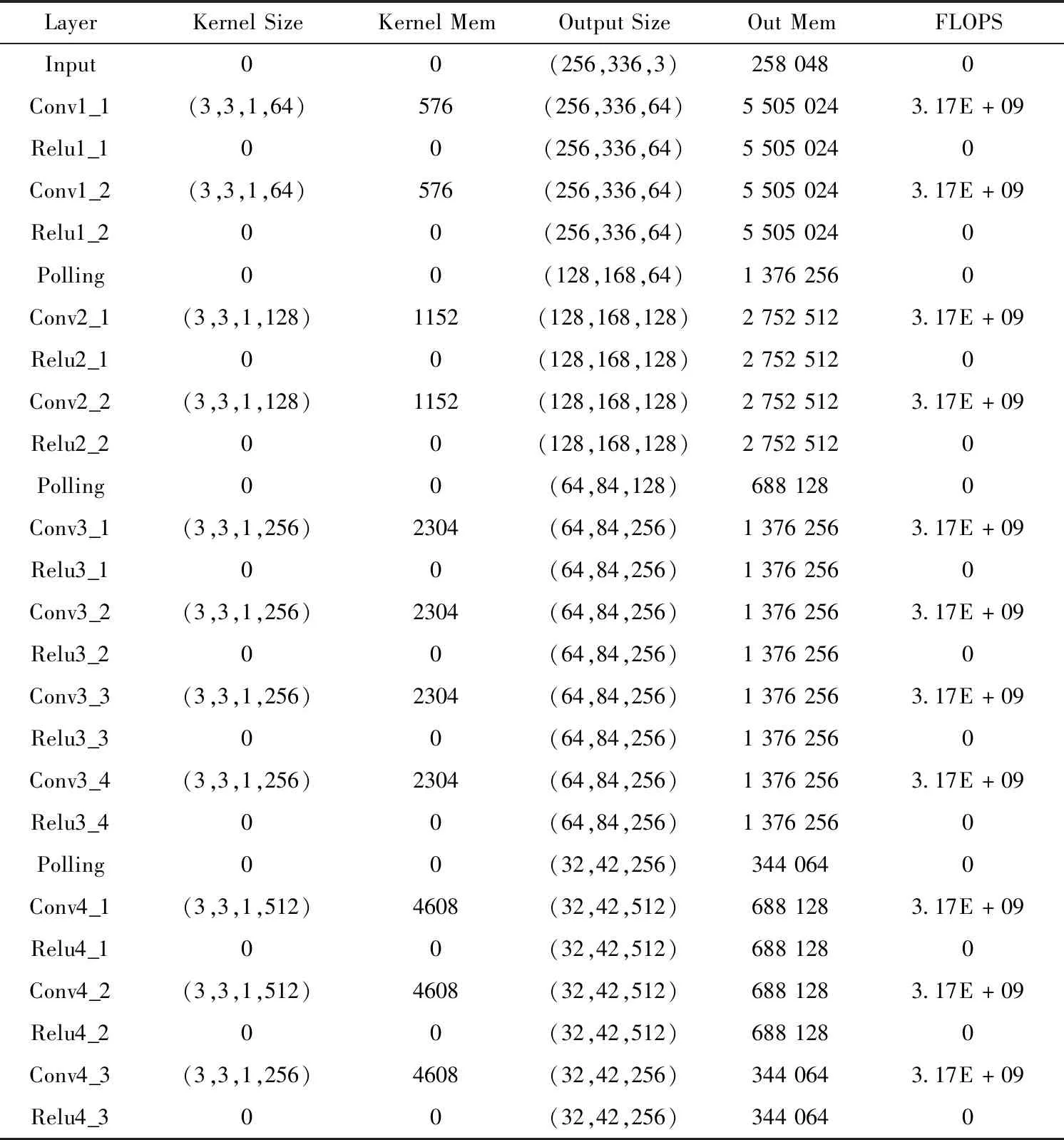
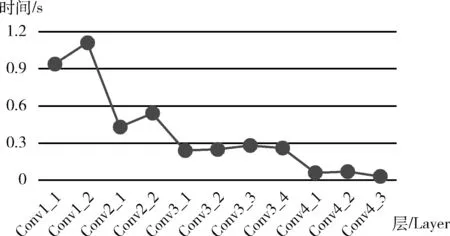
3.2 OpenPose结果及分析
3.3 综合对比研究



4 结束语
