基于多层次聚类的文本知识挖掘
2021-01-20席永轲钱茛南顾丽红
刘 昕,席永轲,何 杰,钱茛南,顾丽红
(1.中国石油大学(华东) 计算机与科学技术学院,山东 青岛 266580;2.中电科大数据研究院有限公司,贵州 贵阳 550022;3.中国电子科技集团公司信息科学研究院 提升政府治理能力大数据应用技术国家工程实验室,贵州 贵阳 550022;4.中国电子科技集团公司信息科学研究院,北京 100081)
0 引 言
随着各行各业数字化进程的发展,各类文本信息不断积聚,如何在大量的文本中提取用户感兴趣的、潜在有用的信息并且能够针对不同层次、不同类别的信息进行分类处理对于用户决策有重要的参考价值[1]。
文本挖掘[2](text mining,TM),又称为文本知识发现(knowledge discovery in texts,KDT),是指从大数据文本中挖掘出隐含位置的潜在有用模式的过程,文本知识挖掘是涉及多个学科的研究领域,其中包括数据挖掘、机器学习、数据统计、自然语言理解、信息检索、信息提取、可视化和数据库技术等。随着文本知识挖掘技术的不断进步,相关算法已经不仅仅局限于分类、文本特征提取等简单模式的文本知识挖掘,也可以探索更丰富的文本知识挖掘,如主题发现、情感分析、语义规则发现、趋势分析等。
但目前大多数机器学习与数据分析方法,都无法从多层次对同一语料数据进行不同粒度的快速高效知识挖掘,随着网络的不断发展,互联网上的信息越来越丰富,更多的文本数据已经不单单仅限于一个层次,对单个层次的文本数据进行知识挖掘已不能满足人们对知识的需要。因此,为了更加精确发现不同层次语料数据所表征的不同层次的文本知识,我们提出了一种基于多层次聚类的文本知识挖掘方法。
1 相关工作
文本知识挖掘处理的并非是少量文本,而是大规模文本集合,可以发现隐藏在大量文本中的隐藏知识,通常是以前未知的模式或关系。这些模式和关系对于解答某个特定问题很有价值,或者是某用户特别感兴趣的知识。同时由于文本数据噪声大及结构不规则,要求文本知识挖掘算法具有较强的算法鲁棒性[3]。聚类算法是数据分析与挖掘中的一个比较常见的手段,将其用于文本知识挖掘,进行文本知识聚类,可以将文档数据集聚为不同簇,并且需要同一簇中的文本特征尽可能相似,不同簇中的文本特征尽可能差异大。因为中文文本数据大部分为非结构化或半结构化数据,这使得基于结构化数据的聚类算法不适用于文本聚类。
从1995年Feldman正式引入文本挖掘的概念之后,尽管只有20年左右,但国内外有关文本知识挖掘的相关研究已经得到了迅速发展。国内外的各相关研究主要围绕文本挖掘模型、文本特征抽取与文本中间表示、文本挖掘算法[4]等,目前在文本知识挖掘领域国内外已经形成了较为成熟的理论体系与技术手段,并已应用于多个应用领域。如在微博文本知识挖掘中,张茜等[5]提出一种用于评论集褒贬态度和方面观点挖掘的新模型,该模型加入了表情符号层与文本情感层,实现评论集方面和褒贬态度的同步检测。黄贤英等[6]根据词形相同与词义相近寻找微博短文本中的公共块,提出一种基于多视角的微博短文本相似度算法。钟文良[7]提出了一个基于Pitman-Yor过程模型的文本聚类算法用于文本知识挖掘。秦永彬等[8]结合用户兴趣与微博信息的特点,提出了一种文本聚类与兴趣衰减的微博用户兴趣挖掘(TCID-MUIM)方法,具有更好的主题区分度,且更贴合用户的真实兴趣偏好。
随着相关研究的不断深入,文本聚类成为文本知识挖掘的一项关键技术。Hang等[9]提出了一种局部同步聚类算法(G-Sync算法),该方法基于重力学中的中心力优化方法,将其用于文本知识挖掘并取得了良好效果。Zheng等[10]提出了一种基于语料库的短文本聚类方法,主要在短文本文档中给可能未出现的新单词添加虚拟词频,该虚拟频率是从给定该文档中所有单词的新单词的后验概率中获得。Mohammad等[11]提出了一种目标函数和混合KH算法(称为MHKHA)相结合的方法来解决文本文档聚类问题。Ghai等[12]提出了一种有效的方法,即使在复杂背景下,也可以使用DWT和k-means聚类以及投票决策过程来提取文本区域。Soares等[13]提出了频率Google Tri-gram测度,以根据比较文档中术语的频率以及作为附加语义相似性来源的Google n-gram语料库来评估文档之间的相似性,以此来改善文档聚类的质量。Mozhgan等[14]采用基于最小生成树的聚类算法来发现文档的各种子主题。Song等[15]提出了一种模糊控制遗传算法(GA),并结合一种新颖的混合语义相似度度量进行文档聚类用于知识挖掘。Alguliyev等[16]提出了一种基于聚类和优化技术的两阶段句子选择模型COSUM用于文本知识挖掘,取得良好效果。Xu等[17]提出了一种用于短文本聚类的灵活的自学卷积神经网络框架(称为STC2),成功地合并更多有用的语义特征。Sangaiah等[18]提出了3种方法:在无监督、半监督技术和降维半监督下,为阿拉伯文本文档构建基于聚类的分类器。Qiang等[19]提出了一种基于Pitman-Yor过程的新型模型来捕获集群分布的幂律现象。Alanko等[20]设计并实现了一种节省空间的聚类算法框架解决无监督元基因组聚类中的许多核心原语。Kushwaha等[21]提出了一种无监督文本聚类的特征选择方法,称为基于链接的粒子群优化算法(LBPSO)。
目前的中文文本知识挖掘只是在某些方面(如特征抽取)和某些应用领域(如分类与聚类)展开,是零散的、孤立的。没有同时从微观和宏观层次进行知识挖掘,不能多层次展示特定领域语料的特征。
2 基于多层次聚类的文本知识挖掘方法
2.1 数据预处理
数据分词是把连续的汉字序列划分成一系列单独的词语,之后将词语作为文本数据的基本单位。例如“中印洞朗的对峙事件持续了两个月”被分割为“中印/洞朗/的/对峙/事件/持续/了/两个/月”的形式。本文使用的分词原理是基于前缀字典实现高效的词图扫描,获得所有可能的词,由这些词生成有向无环图(DAG),然后再使用动态规划算法以寻找最大概率路径,最终找到基于词频的最大拆分组合。本文使用Jieba分词,并将分词结果用于后续分析。
分词之后仍然存在大量的停用词诸如“的”、“了”、“呢”等,和无意义词、错误用法词汇等,本文使用自定义词表,包含超过4000个不同的停用词、无意义词、错误用法词、特殊符号,基于词表对分词结果进行匹配,去除词表中存在的词汇,从而进一步得到文本具有实际意义的词集。将文本进行预处理后得到高质量的词集,有助于提高后续文本知识挖掘效率和准确率。
2.2 词向量训练
本文所采用的词向量训练模型建立在分布假说的基础上,假设词的语义由其上下文决定,上下文相似的词,其语义也相似。本文中利用人工神经网络对词向量进行训练与二维空间映射。
本文的词向量训练过程为:首先将某一层次所有文本数据作为一个文档集合,并对文档集进行数据预处理操作;然后使用word2vec词向量训练方法,为每个词语构建词嵌入矩阵并将其所有词语转换成one_hot独热码编码;将词嵌入矩阵送进word2vec中的CBOW神经网络模型中进行训练,同时将输出的预测值与标签计算loss值,并计算预测值与标签之间的损失偏差用以优化网络[22];最终将训练后的词嵌入矩阵采用TSNE算法进行降维,将其映射到二维空间。
2.3 基于局部密度的快速聚类算法
为满足多层次文本知识挖掘的任务需要,本文采用基于局部密度的快速聚类算法对数据文件进行聚类,将语义相近的文本数据聚为一类作为一个分类主题。
本文所采用的基于局部密度的快速聚类算法,通过计算数据节点的局部密度与相对距离来确定聚类中心与孤立点,然后对剩余数据节点进行聚类,其具体过程如下:
(1)针对基于word2vec词向量训练后的文本数据集合Dc,将原始文档集Ds中每条文本数据的关键词抽取结果与Dc中的词向量结合,将Ds中每条文本数据的关键词对应的Dc中词向量坐标累加求和,得到每一条文本数据的二维坐标作为一个数据节点的坐标,将所有的数据节点作为数据节点集Dd;
(2)计算Dd中每个数据节点的局部密度,式(1)如下
ρi=∑jx(dij-dc)
(1)
其中,ρi为第i个数据节点的局部密度,dij为第i个数据节点与第j个数据节点间的欧氏距离,dc为截断距离。
局部密度描述了一个数据节点周围数据的聚集程度,局部密度越大说明该节点周围的其它数据节点数量越多,分布越密集;反之则分布越稀疏。
(3)计算每个节点的相对距离,式(2)如下
(2)
其中,ρi是第i个数据节点的局部密度,ρj是第j个数据节点的局部密度,dij为第i个数据节点与第j个数据节点间的欧氏距离。
相对距离描述了一个数据节点与其它具有较大局部密度的数据节点的距离,当一个节点是局部密度最大的节点时,它的相对距离就是与该点距离最远的节点的距离;当一个节点不是局部密度最大的节点时,相对距离便是大于该点局部密度的数据节点与该节点的距离。
(4)设定中心局部密度阈值Ld与中心相对距离阈值Rd, 统计Dd数据节点中局部密度大于Ld且相对距离大于Rd的数据节点作为聚类中心;若一个节点的局部密度值较小,但相对距离较大,则认为其是一个远离群体的孤立点,在聚类过程中不对孤立点进行聚类操作。
(5)根据步骤(4)确定的聚类中心,将数据节点集合Dd中剩余点进行分配,分配原则为按照节点间距离将其分配给与其具有较高密度的最近节点相同的类簇。
2.4 各层次文本定义
针对不同规模的数据,根据其数据分布,使用不同的方式对数据进行划分,进行不同粒度的聚类,实现各个层次知识的挖掘。共有以下几种形式:
(1)将所有数据归为一个层次,即将所有数据进行最广义文本知识挖掘。
(2)根据规范化后数据所属的不同类别,可以根据不同类别层次将数据划分为不同类别,并根据不同类别进行文本知识挖掘。
(3)若想获取自定义类别数据,首先自定义类别标签关键词,然后对所获取规范化数据进行遍历,并通过类别关键词对每一条数据进行类别相似度赋值权重,最终通过权重大小获取到自定义类别数据。
2.5 多层次文本知识挖掘算法描述
算法流程如图1所示。
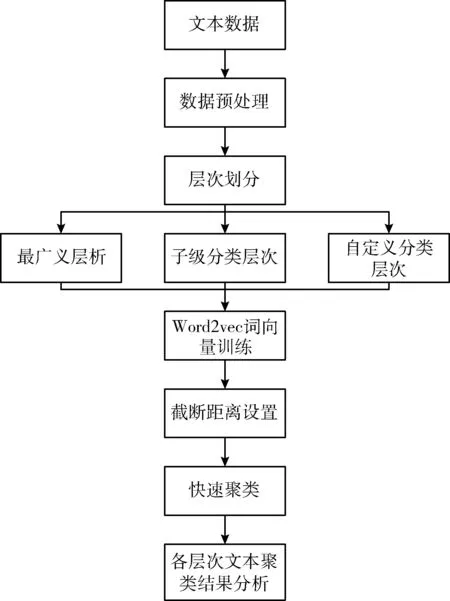
图1 算法流程
(1)基于所获取的原始文本数据进行数据预处理操作,主要包括基于前缀词典的数据分词、去停用词及无意义词、清除空值数据、数据规范化等操作。
(2)根据规范化数据的不同特征以及在数据表中所属的不同类别,将所有规范化数据作为最广义层次,根据规范化数据所属类别将数据分为多类,每一类作为子级分类层次,根据规范数据的关键词标签将其归为自定义分类层次。
(3)基于不同层次的文本数据,采用word2vec算法进行文本词向量训练,将文本数据处理为二维并在空间标识。
(4)基于词向量训练结果,将每条文本数据的关键词抽取结果与词向量结合,将关键词对应的词向量坐标求和,作为一个数据节点的坐标。
(5)计算所有数据节点的相对距离,并不断动态更新截断距离。通过计算每个数据节点的局部密度与相对距离确定各个聚类中心,并根据各个聚类中心,将不同数据聚为一类,保存聚类结果。
(6)针对不同层次的文本聚类结果进行各层次文本知识挖掘。针对最广义层次的文本知识挖掘可在已获取全体数据的基础上对其划分为多个主题,实现其各主题事务的划分;针对子级分类数据的文本知识挖掘可发现下一层次主题分类;针对自定义层次的文本知识挖掘,可针对某一个具体事件进行知识分类,发现该事件中存在的具体细节。
3 实 验
3.1 实验数据
本文采用诉求数据进行测试,其中涉及一级到五级分类,共约30万诉求工单数据。首先将文本数据进行预处理,然后采用word2vec进行文本词向量的训练,将所得数据分词结果简化为K维向量空间中的向量运算,并最终映射到二维空间;通过所得文本词向量,使用多层次文本聚类方法,针对各不同层次数据,通过局部密度与相对距离的计算,自动挑选聚类中心,基于聚类中心将剩余数据按照空间距离进行聚类,实现不同层次的文本知识挖掘。
3.2 聚类算法截断距离设置
本文对基于局部密度的快速聚类算法中的截断距离阈值进行设置,通过计算全部数据节点间的欧式距离,取其平均距离作为截断距离。若截断距离阈值设置较大,则所有数据就会聚为一类。若截断距离阈值设置较小,则聚出类别过多,无参考价值。
3.3 实验结果及分析
3.3.1 最广义层次知识挖掘
对全部实验数据分词并进行词向量训练之后,使用基于局部密度的快速聚类算法对表达上下文关系的词向量进行聚类,通过计算数据节点的局部密度与相对距离来确定聚类中心与孤立点,并对剩余数据节点进行基于局部密度的快速聚类,将语义相近的数据聚在一起,可以将包含全部数据的语料基于语义分为多类,从而实现多主题文本知识挖掘。
采用多层次聚类知识挖掘方法,在已知所有数据的基础上对其一步划分为多个主题,实现其各业务科室管理事物的划分。针对文本聚类结果,通过分析不同类别间的核心特征词从而确定不同类别所代表的不同问题及其问题所属部门,并将分析结果经由专业业务人员进行测评准确性。
最广义层次所采用的数据为所获取全部语料数据,约24万条,对其进行数据聚类分析,得到数据聚类结果如图2 所示。每一类别包括多条诉求数据。

图2 最广义层次聚类
聚类结果见表1,这些分类可以为每个部门办理哪些类型的诉求提供建议。

表1 最广义层次聚类结果分析
3.3.2 子级分类层次知识挖掘
子级分类层次所采用的数据为所获取数据中拆迁安置类诉求数据,约10万条,对其进行数据聚类分析,得到数据聚类结果如图3所示。每一类别包括多条诉求数据。
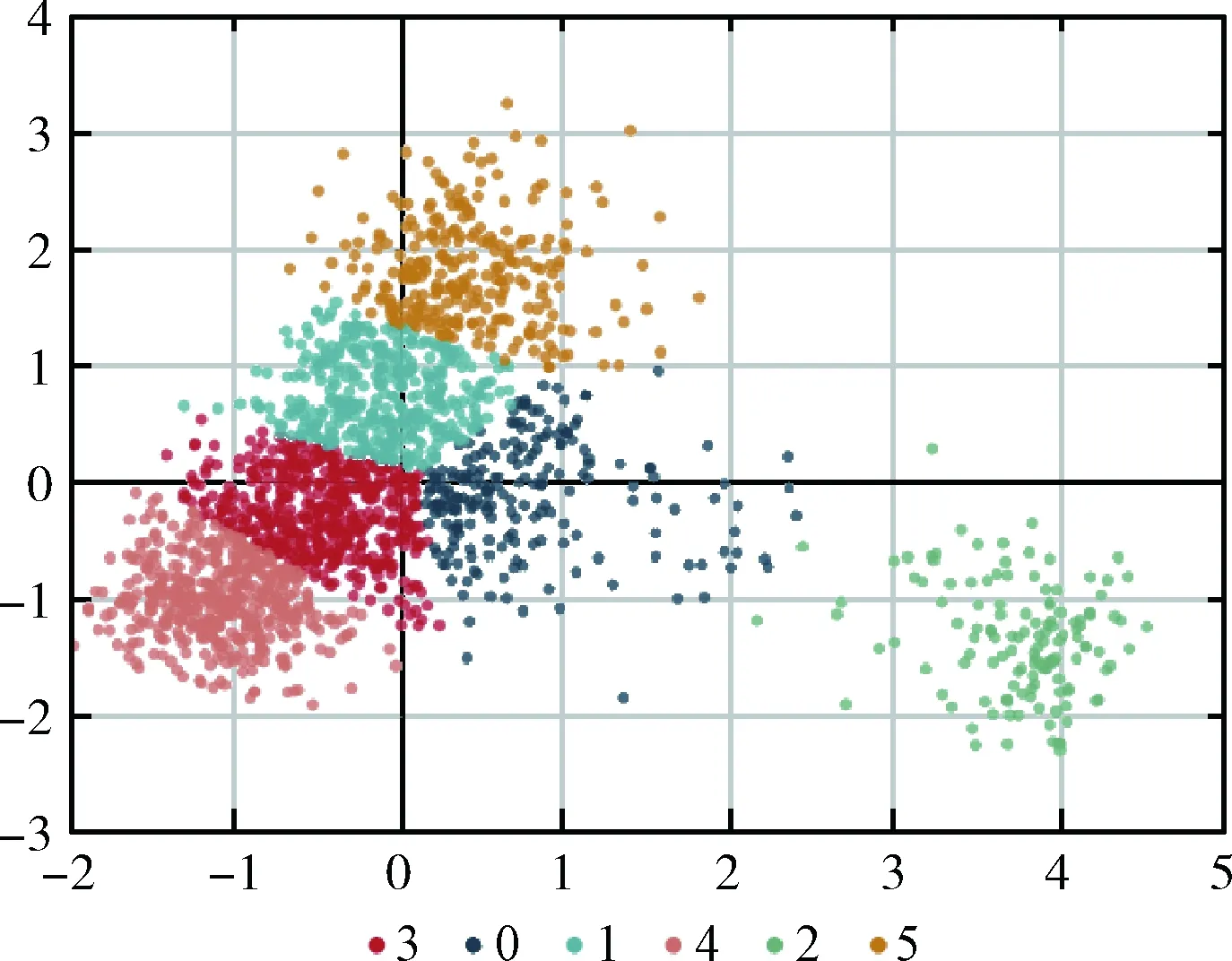
图3 拆迁安置聚类
聚类结果见表2,通过所得各不同类别可对诉求数据进一步发现下一层次主题分类。

表2 拆迁安置类聚类结果分析
子级分类层次所采用的数据为所获取数据中农村工作类诉求数据,约10万条,对其进行数据聚类分析,得到数据聚类结果如图4所示。每一类别包括多条诉求数据。
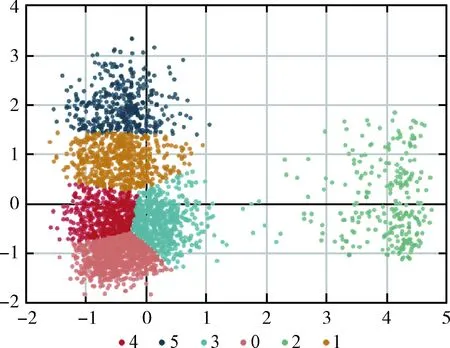
图4 农村工作聚类
聚类结果见表3,通过所得各不同类别可对诉求数据进一步发现下一层次主题分类。

表3 农村工作类聚类结果分析
3.3.3 自定义分类知识挖掘
自定义层次知识挖掘主要以当前实验数据的各末级分类数据进行聚类,其目的在于挖掘当前类别之下更加细致的问题分类,针对某一个事件相关数据聚类,可发现该事件中存在的具体细节问题。
自定义层次所采用数据为所获取数据中末级分类农村低保类诉求数据,约5万条,对其进行数据聚类分析,得到数据聚类结果如图5所示。每一类别包括多条诉求数据。
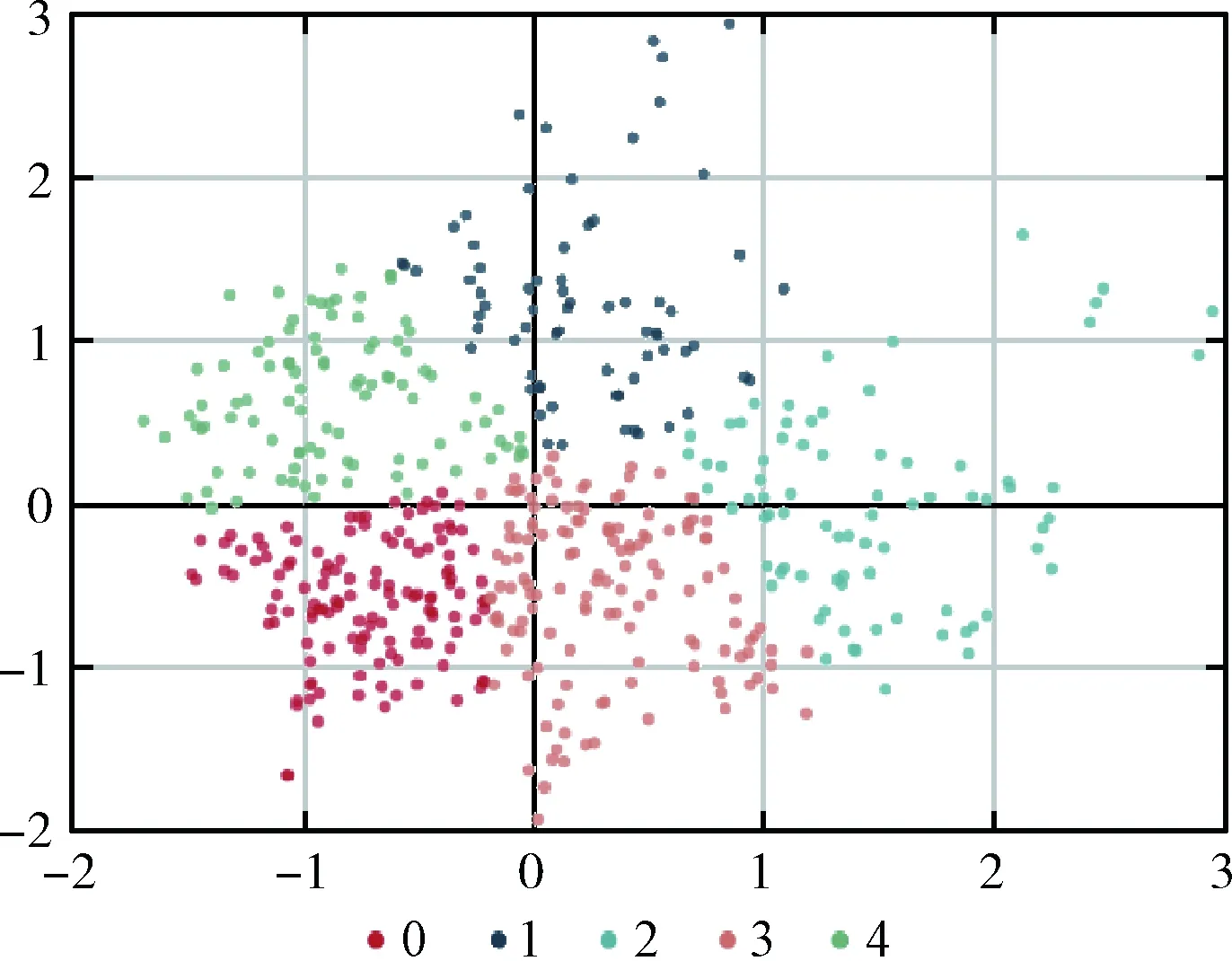
图5 农村低保数据聚类
聚类结果见表4,可发现该末级分类中存在的具体细节问题,将挖掘出来的细致分类提供给相关人员便于发现社会中存在的微问题。

表4 农村低保类聚类结果分析
自定义层次所采用数据为所获取数据中末级分类商业噪音类诉求数据,约5万条,对其进行数据聚类分析,得到数据聚类结果如图6所示。每一类别包括多条诉求数据。
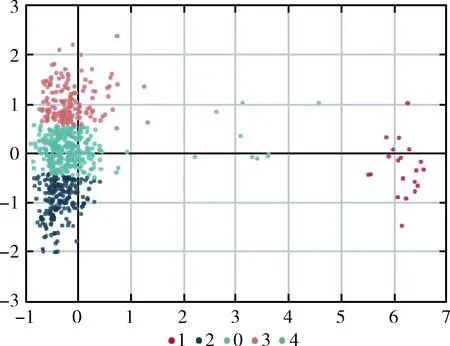
图6 商业噪音数据聚类
聚类结果见表5,可发现该末级分类中存在的具体细节问题,将挖掘出来的细致分类提供给相关人员便于发现社会中存在的微问题。

表5 商业噪音类聚类结果分析
4 结束语
本文提出了一种基于多层次聚类的文本知识挖掘。该方法主要包含5个模块,即数据预处理模块、层次划分模块、词向量训练模块、多层次聚类知识模块、结果知识分析。这5个模块构建了该文本知识挖掘方法的整体架构。其中,在层次划分模块将数据分为多个不同层次,根据规范化数据的不同特征以及在数据表中所属的不同类别,使用不同的类别判别方式对数据进行划分层次,使数据的类型更加明确。对不同层次的数据分别进行词向量训练,根据训练结果进行距离计算、聚类,从而挖掘多个层次的知识,实现对事物的多个不同层次的多角度的刻画。
实验以诉求数据进行多层次文本知识挖掘实验,获得了有价值的理论和实验效果。在最广义层次诉求数据中本文方法将已知所有数据划分为多个主题,通过文本结果分析实现其各业务科室管理事务的划分;在子级分类层次诉求数据中本文方法发现下一层次诉求的主题分类;在自定义层次的文本知识挖掘中本文方法针对某一个具体诉求事件进行知识分类,发现了该诉求事件下社会中所存在的具体细节问题,并经由专业业务人员对本文方法所挖掘出来的结果进行测评。通过本文方法所挖掘出的诉求数据办理部门分布、各子级分类及末级分类下的社会微问题与实际情况下业务进行对比评测发现,基于多层次聚类的文本知识挖掘可准确对诉求工单数据进行多层次知识挖掘,并为政府及相关部门提供精准的分析和决策支持。
