基于深度学习的声呐图像目标识别
2021-01-19张家铭丁迎迎
张家铭,丁迎迎
(江苏自动化研究所,江苏 连云港 222061)
0 引 言
声波是唯一能够在海水介质中远距离传播的波,因此是海洋探测的主要方法,而声呐则是用声波探测海洋的主要设备。目前,声呐信号处理已经发展到了数字化阶段,获取的声呐数据都以图像的形式将目标信息显示出来,但是由于水声信道的不均匀性及其边界的不规则形,造成声呐图像斑点噪声明显、边缘模糊、亮度不均匀和分辨率低等特点,研究声呐图像处理技术具有重要意义[1]。
前视声呐不仅可以探测海中的状况,还可以对目标进行定位,判断目标的大小以及形状信息。对水下机器人来说,前视声呐不仅起到避障的作用,而且当水下机器人遇到感兴趣的目标时,可以利用前视声呐对其进行跟踪和分类识别。在水下作业的应用场合中,除了需要对目标进行探测定位之外,还需要对目标进行分类识别,所以对声呐图像目标跟踪识别的研究有现实意义。
本文研究基于深度神经网络的声呐图像目标识别技术,提出一种基于卷积神经网络的声呐图像目标识别方法。由于声呐图像含有大量的噪声,首先选择速度较快的中值滤波去噪,使用Canny 边沿检测算子[2]提取出包含白线的位置,然后使用霍夫变换[3]提取直线,随后使用自适应阈值化算法[4-5]分割目标,并使用分水岭算法连接相邻较近并且灰度相近的目标得到分割图像,最后查找分割图像中的连通区域,获得目标轮廓、方位等信息。针对提取得到的目标信息,选用卡尔曼滤波器算法[6]实现目标跟踪,最后使用卷积神经网络[7-8]对跟踪后的目标进行分类识别。
1 图像预处理
1.1 中值滤波
声呐图像处理常用的滤波去噪方法主要有非局部均值滤波、中值滤波、维纳滤波、均值滤波和高斯滤波等。这里选择处理效果较为稳定且速度较快的中值滤波对声呐图像进行降噪。
中值滤波是一种常用的非线性滤波方法,采用3×3的掩模能够有效地避免滤波带来的模糊效应,在平滑脉冲噪声方面非常有效,同时可以保护图像尖锐的边缘,非常适合消除声呐图像中的孤立噪声点。中值滤波的基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值,主要步骤为:在图像中依次移动模板,使模板中心和图像中某个像素点重合,读取和模板对应的像素点的灰度值并升序排列,将中值赋值给模板中心对应的像素点。
中值滤波的本质是使用与区域周围像素灰度值接近的值取代与周围像素灰度值差别比较大的值,从而消除孤立的噪声点。
1.2 白线检测
边缘检测的目的是在保留图像特征的前提下,减少数据规模,边缘检测的算法有很多种,但是Canny边缘检测是边缘检测算法中的标准算法。它使用变分法实现最大化标识出图像中的实际边缘且最小化漏检、误检概率,同时极小化检测到的边缘点与实际边缘点之间的距离。Canny 边缘检测算法的主要过程为:首先使用高斯滤波平滑图像,然后提取图像的强度梯度,使用非最大抑制技术和双阈值方法来降低漏检、误检概率,最后使用滞后技术跟踪边界。Canny边缘检测效果示意图如图1 所示。
使用边缘检测算法提取出包含白线的位置后,使用霍夫变换提取直线。霍夫变换追踪图像中每个点对应曲线间的交点,若交于一点的曲线数量超过了阈值,则此交点所代表的参数对在原图像中为一条直线。霍夫变换采用极坐标表示直线,所以对于霍夫变换,通过点 ( x0,y0)的直线簇的表达式为:
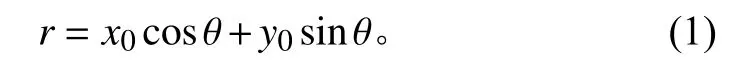
对图像中的所有点,分别在极径-极角平面绘出所有通过它的直线来得到一条正弦曲线,对于图像中2 个不同的点,如果正弦曲线在平面相交,则可以认为这2 个点通过同一条直线。
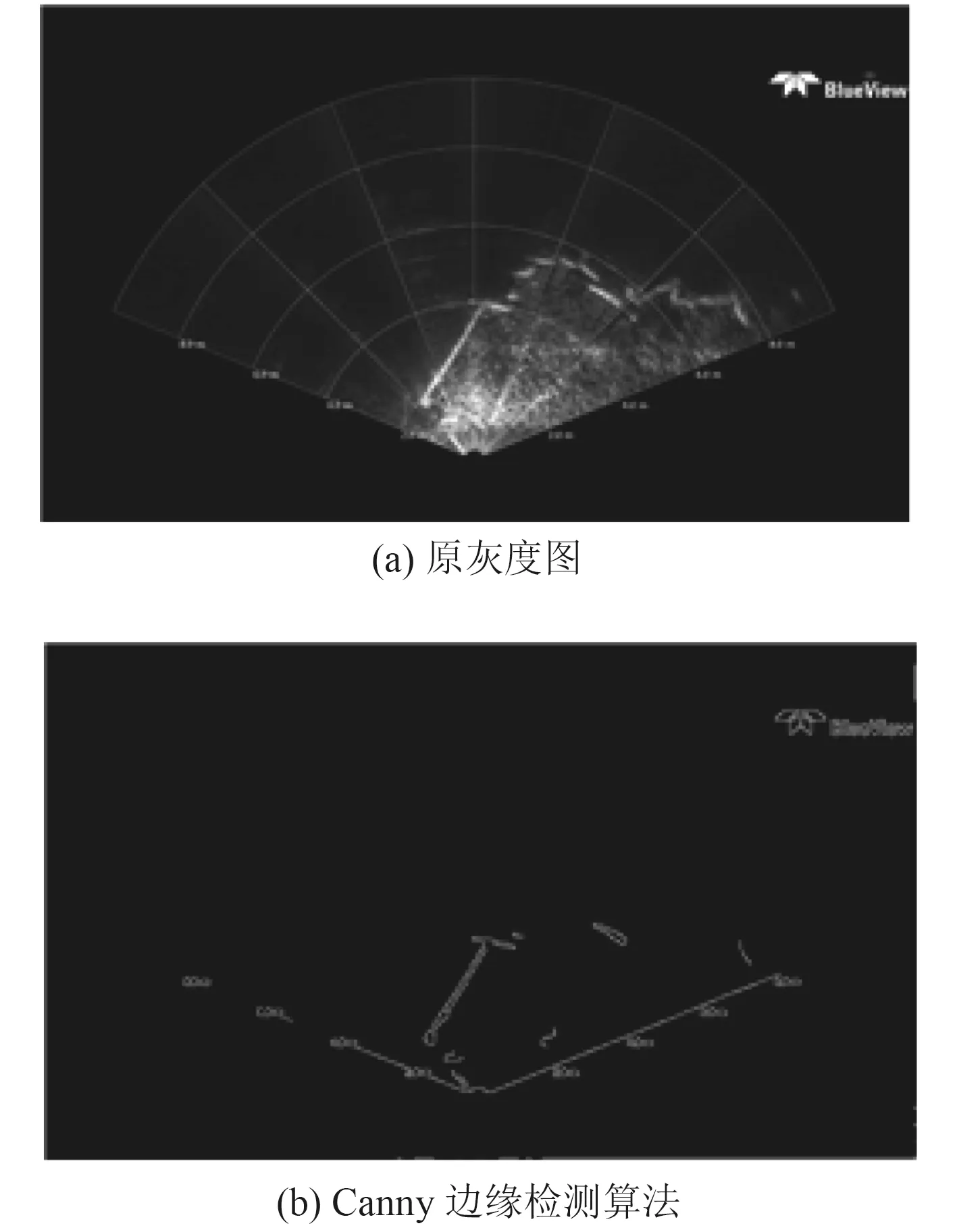
图 1 Canny 边缘检测效果示意图Fig. 1Schematic diagram of Canny edge detection effect
2 图像分割
在声呐图像处理领域,通常关心的只是目标或者目标附近领域而不是整幅图像,其他目标无关部分会对图像处理产生干扰。为了更好地检测和分析目标,为后续的目标跟踪和识别提供充足的目标信息,需要将目标或者目标区域同背景干扰分离开。目前被广泛应用的图像分割算法主要有OTSU 阈值化法、均值聚类算法、自适应阈值化算法、分水岭算法和区域生长算法等。均值聚类算法不容易区分噪声和目标,分水岭算法对噪声的抑制能力较差而不能很好的保留目标的整体性,区域生长算法需要多次迭代,运算时间较长且对噪声敏感,考虑到算法的执行速度,因此选择自适应阈值化法进行图像分割。
自适应阈值根据像素的邻域块的像素值分布来确定该像素位置上的二值化阈值,使每个像素位置处的二值化阈值根据其周围邻域像素的分布来不断变化而不是固定不变的。亮度较高区域的二值化阈值通常较高,而相应的亮度较低的区域二值化阈值会变小。不同亮度、对比度、纹理的局部图像区域对应不同的局部二值化阈值。常用的局部自适应阈值有局部邻域块的均值和局部邻域块的高斯加权和。
在本文提出的方法中,使用自适应阈值化法时,对图像中亮度较高的区域进行补偿以免遗漏。对阈值化后得到的结果进行腐蚀与膨胀操作以滤除噪声,同时删除面积较小的连通域。对剩余的连通域使用分水岭方法连接以免图像破碎,最后计算连通域的面积、几何中心坐标等作为目标信息。
3 目标跟踪
针对声呐目标跟踪问题,常用的方法为利用一些先验信息,获取目标的特征点,之后根据特征点采用基于特征的跟踪方法跟踪目标。
将图像分割为不同区域,通过隶属度判断分割出的区域类别,然后在相邻图像中使用目标的模板进行区域匹配实现目标跟踪的基于区域的跟踪,将目标跟踪问题等效为贝叶斯概率最优估计问题的基于贝叶斯的跟踪。由于基于特征点法不适用于噪声多、分辨率低的声呐图像,基于区域法匹配效果较差,所以选用卡尔曼滤波器方法实现目标跟踪。
卡尔曼滤波器是一个最优化自回归数据处理算法,在系统中引入线性随机微分方程来描述离散控制过程的系统:
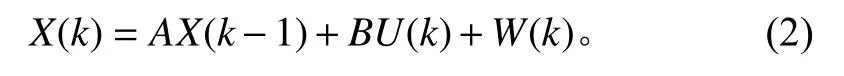
式中:X(k)为 k时刻的系统状态; U (k) 为k时刻对系统的控制量; W (k)为系统过程;A 和B 为系统参数。
首先预测下一状态的系统,假定目前的状态为 k ,则上一状态的系统可以表示为:
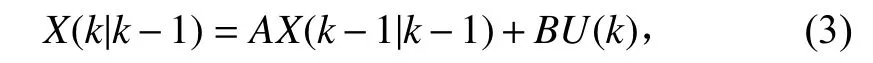
其中,X(k|k-1)是根据上一状态的预测结果,X(k-1|k-1)是上一状态的最优结果, U (k)为目前状态的状态控制量。根据式(3),系统状态已经更新,然而预测结果的协方差矩阵还没有更新:
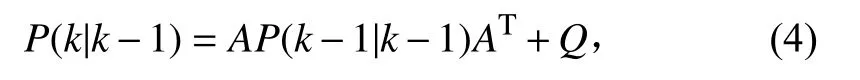
式中:P(k|k-1)为与系统X(k|k-1)对应的协方差;P(k-1|k-1)为与上一状态系统X(k-1|k-1)对应的协方差; Q为对应系统状态的协方差。
系统的测量值可以表示为:
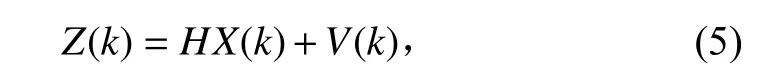
式中: H 为测量系统的参数; V (k)为高斯白噪声。根据获得的预测值和测量值,可以得到目前系统状态X(k)的最优化估计值X(k|k):
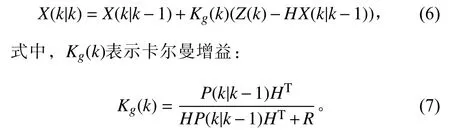
根据X(k|k)估计其对应的协方差P(k|k):
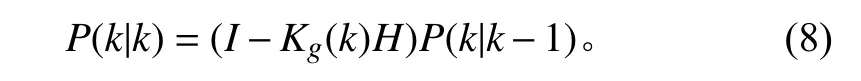
卡尔曼滤波流程如图2 所示。
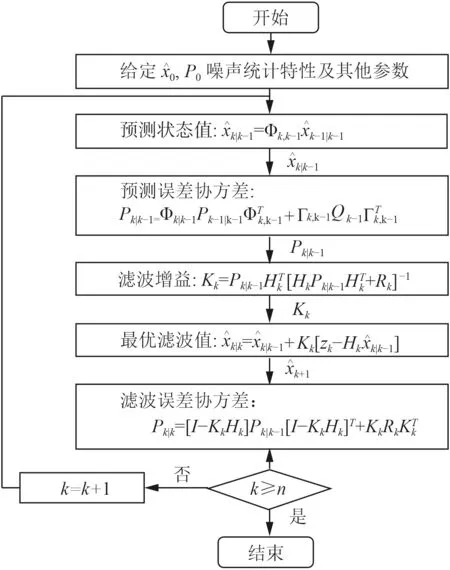
图 2 卡尔曼滤波流程图Fig. 2Kalman filter flow chart
根据前后2 帧图像,可以得到通过卡尔曼滤波器预测得到的目标信息和根据当前帧图像分割出的目标信息,接下来要做的就是提取测量目标和预测目标之间的对应关系。如果上一帧与当前帧相比在与当前帧目标附近位置处存在一个大小相似的目标,则这2 个目标为同一个目标。反之则目标在当前帧消失。附近位置通过距离描述,大小相似性则通过交并比描述。使用上一帧卡尔曼滤波器的预测值与当前帧目标做匹配得到当前帧的测量值,根据测量值更新卡尔曼滤波器。将卡尔曼滤波器估计出的速度作为目标的运动速度,实现目标跟踪。
4 目标识别
分割出目标并完成跟踪之后,需要对目标进行识别以确定目标身份信息。使用支持向量机(SVM)训练根据声呐图像提取的不变矩和灰度梯度共生矩阵特征都不能很好地实现目标识别。因此,选择在图像分类识别任务中表现优异的卷积神经网络(CNN)进行目标识别。
MobileNet 是谷歌于2017 年提出的用于嵌入式设备和移动端的轻量级卷积神经网络。MobileNet 利用深度可分离卷积思想,将传统卷积过程分解为深度卷积Depthwise 和点卷积Pointwise 两个步骤,突破传统3D 卷积的通道数量,通过滤波和组合的方式计算卷积,极大减少了卷积核的冗余,减少了网络层数和参数规模,提高了计算速度。同时引入宽度因子和分辨率因子2 个全局超参数对网络延迟和准确度进行有效权衡。
早期版本MobileNet_V1 网络中,当激活空间的维度较低时,激活空间中的兴趣流形经过ReLU 非线性变换会出现空间坍塌,造成特征信息丢失,而使神经元的输出为0,出现神经元死亡的现象。针对这个问题,MobileNet_V2 在保留MobileNet_V1 深度可分离卷积的基础上引入了残差倒置模块Inverted Residuals 和线性瓶颈模块Linear Bottleneck。
MobileNet_V2 的Inverted Residuals 模块聚焦于残差网络各层的层数,采用“扩张-深度卷积-压缩”的思想,首先经过1×1卷积核对输入数据进行特征维数放大,然后经过3×3深度卷积进行特征提取,最后经过1×1的点卷积将放大的特征维数压缩回去,解决了特征提取受限于输入通道数的问题。Linear Bottleneck 模块将全连接层之后的激活函数由ReLU 替换为线性激活函数,而其他层的激活函数依然是ReLU 函数,通过将非线性激活变换为线性激活来捕获兴趣流形,解决低维激活空间的信息损失问题。2 个模块结合构成了MobileNet_V2 网络的基本架构,如图3 所示。
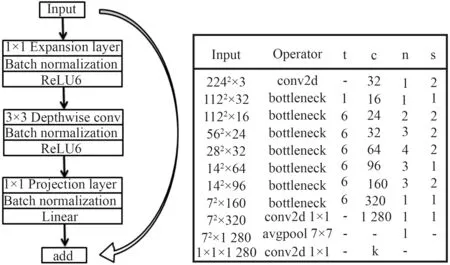
图 3 MobileNet_V2 网络微结构Fig. 3MobileNet_V2 network microstructure
5 基于卷积神经网络的声呐图像目标识别方法
本文基于声呐图像的主要特征表现及深度学习算法,对声呐图像目标识别提出如下处理方法:
1)对声呐图像使用中值滤波去除多余噪声,进行Canny 边缘检测算法识别白线提取边缘,然后使用霍夫变换提取直线,通过直线交点求解扇形所在圆心;
2)针对预处理后的声呐图像,使用自适应阈值化算法进行图像分割,同时利用分水岭算法连接灰度相近的目标,查找分割图像中的连通区域,获得目标信息;
3)根据提取得到的目标信息,通过匹配算法与卡尔曼滤波器得到的上一帧预测结果进行匹配,根据匹配得到的测量值更新卡尔曼滤波器来实现跟踪目标;
4)将跟踪得到的目标图像数据输入卷积神经网络,自动提取特征进行声呐图像目标识别。
将跟踪结果中的目标图片提取出来作为数据集,并采用随机反转、旋转、亮度变化等方法来扩充数据集,以防止由于数据量太小带来的过拟合。训练环境是在Ubuntu 系统中,基于Python3.7.2 的PyTorch 1.2,配置GPU 所使用的环境是CUDA 10.0 和Cudnn 7.6.2。采用Adam 梯度下降算法训练网络,初始学习率设置为0.000 5,网络权重衰减系数设置为0.000 5。测试集精度如表1 所示。
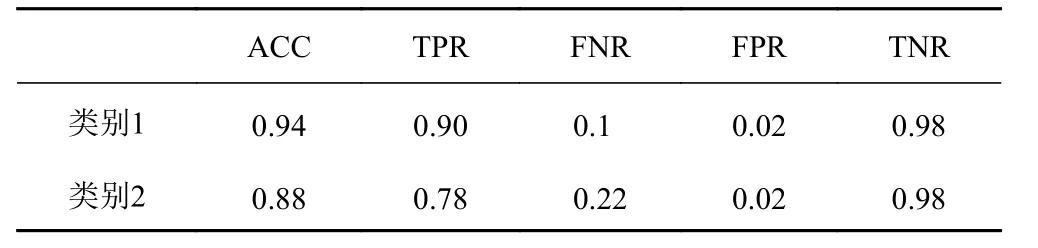
表 1 卷积神经网络测试集精度Tab. 1 Accuracy of convolutional neural network test set
从表1 可以看出,卷积神经网络对声呐图像目标的识别准确率分别为0.94 和0.88,识别准确率较高,证明了所提出方法的有效性。
6 结 语
本文基于声呐图像的主要特征表现,结合声呐图像预处理方法、图像分割方法和图像目标跟踪方法,提出一种基于卷积神经网络的声呐图像目标识别方法。以较高的准确率实现了对声呐图像目标的识别,证明了所提出方法的有效性和可行性。
