基于多特征值的源代码相似性检测技术
2021-01-19展佳俊赵逢禹
展佳俊,赵逢禹,艾 均
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
随着计算机技术以及互联网技术的迅速发展,软件系统已经应用于各行各业,软件的规模也越来越大。在软件系统开发的过程中,为了满足敏捷开发的快速迭代需求,大多数软件开发工程师通过直接复制粘贴或者在复制的基础上进行若干修改后来重用代码,这是一种十分常见的现象。因此,相似代码在软件系统中是十分常见的,开发人员直接拷贝粘贴或者在此基础上进行若干修改实质上是一种简单的代码复用机制。这种复用机制是非正式和不可控的,并且会带来一系列负面影响[1]。随着开源软件的迅速发展,一些开源项目和商业软件项目中存在大量复用的开源代码,这样可以帮助软件开发工程师加快项目的开发进度,但是也带来了一些风险,可能会出现严重的安全漏洞。如今代码抄袭现象也是经常发生的[2-3],而源代码相似性检测是代码抄袭检测的核心,源代码相似性检测技术的研究具有重要意义。
目前的源代码相似性检测技术主要有基于token的代码相似检测技术、基于抽象语法树的代码相似检测技术、基于程序依赖图的代码相似检测技术和基于深度学习的代码相似检测技术等。
Wang等人提出了一种基于token的代码相似性检测技术[4],在源代码预处理之后,他们利用一个滑动窗口扫描源代码,将窗口中的源代码进行哈希,最后进行多重对比从而检测代码相似。国内学者王春辉也提出了一种基于串匹配的程序代码相似检测方法[5],该技术将源代码转化成token,使用高效的RKR-GST串匹配算法找出每对token的所有最长公共子串,然后计算相似度。基于token的技术没有考虑到代码行的顺序,如果代码行顺序被改变了,相似代码将不会被检测到。并且该技术没有充分利用源代码信息,比如它会忽略掉源代码语法结构信息。
Jiang等人提出了一种基于抽象语法树的相似性检测技术[6],并使用欧氏距离来计算代码相似度。该方法首先将源代码生成语法树,然后再将语法树生成一个向量集用于承载语法树的结构信息,接着使用局部敏感哈希算法对这些向量进行聚类,通过寻找一个向量的近邻检测代码相似。国内学者朱波等人也提出了一种AST的代码相似检测技术[7],该技术通过预处理去除生成AST时的冗余信息,再进行词法语法分析,得到相应的AST;然后通过自适应阈值的选取方式,利用AST遍历得到的程序属性、方法序列,对AST进行相似度计算,最终判定代码是否相似。
GPLAG[8]是一种基于程序依赖图的源代码相似性检测技术,它将代码表示为程序依赖图,并使用程序依赖图子图对比算法来进行源代码相似检测。国内学者吕利也提出了一种基于PDG的相似检测算法[9],该算法主要包括构造代码段的PDG,检测PDG的最大同构子图,和判断同构子图对应的代码是否为克隆代码三步。
随着机器学习和自然语言处理工具的发展,学者开始将机器学习、自然语言处理等技术应用于代码相似检测研究中。Wei等人[10]提出了基于深度学习的相似性技术来检测代码相似。他们将相似性检测问题转化为学习源代码的哈希特征的有监督学习问题,首先将源代码用抽象语法树表征之后用一定的编码规则进行编码,然后将编码后的数据输入一个修改过的卷积神经网络当中进行训练,最后用训练到的特征进行代码相似检测。阿卡什等人提出了基于源代码注释的源代码相似性检测技术[11],他们的方法是基于LDA来检测相似代码,该方法仅使用了源代码注释来进行源代码相似性检测。
以上研究分别从代码token、代码的抽象语法树、代码的程序依赖图以及代码注释等维度来进行源代码相似性检测研究,他们的方法分别从不同的维度对特定类型的代码进行相似性分析。
由于代码的结构与语义的复杂性,使得这些相似性检测技术效果并不令人满意,而如果将多维度信息综合考虑在一起,对于相似代码检测的准确度应该还有较大提升空间。为了提高源代码相似性度量的准确性,该文以方法级别的源代码相似为研究对象提出了一种基于多特征值的源代码相似性度量技术,该技术主要从代码注释、方法型构、代码文本语句与结构等方面来进行分析并研究,从这些方面来提取特征进行方法级别源代码相似性检测。
1 相关概念
1.1 代码相似定义
目前对于源代码相似并没有一个权威的定义,早期研究者认为:“如果一份代码能够通过少量的常规变换手段得到,这两份代码就是相似的”[12],少量的意思是付出的代价较少,常规手段是指普通的文本置换。然而,随着计算机技术的不断发展,人们可以使用更高级的代码抄袭方式来对代码进行大规模的修改。该文采用文献[8]所定义的相似:“源代码之间满足一些抄袭变化方式,就可以认为是相似的”。目前对于代码抄袭手段还没有精确的分类。Jones总结了常见的10种抄袭手段[13],这10种常见的抄袭手段为:完整拷贝、修改注释、重新排版、标识符重命名、更改代码块顺序、调整代码块里语句的顺序、更改表达式中操作符和操作数的顺序、更改数据类型、添加冗余代码、控制结构的等价变换。因此,笔者认为只要两段代码之间满足以上一种抄袭变化方式,就可以认为这两段代码是相似的。
Yamamoto等[14]给出了两个软件系统的相似度定义。对于两个软件P和X,软件P是由元素P1,P2,…,Pm组成,P的集合构成表示为{P1,P2,…,Pm},软件X是由元素X1,X2,…,Xn组成,X的集合构成表示为{X1,X2,…,Xn}。P、X中的元素表示为软件P、X中的文件或者代码。P和X的相似性定义为:
S(P,X)=
(1)
其中,集合Rs表示所有匹配对(Pi,Xj)的集合。根据式(1)可看出,相似性S为一个比值,由Rs中的元素个数比上P、X中元素个数之和。
目前对于代码相似度没有一个统一的定义,代码相似度与上述软件系统相似度类似,该文将代码分为注释、型构、代码文本语句与结构这四个维度,通过加权计算这四个维度的相似度来计算源代码之间的相似度,其结果用数值表示。
1.2 代码特征
将源代码转换成中间产物或者从源代码中提取特征从而进行相似度检测是十分常见的。该文将从多个维度来度量代码的相似性,主要从代码注释、方法的型构、代码文本语句与结构这些维度来进行特征提取。
1.2.1 注 释
代码注释对于研究源代码相似性具有重要的意义。随着自然语言处理技术的不断发展,将自然语言处理技术应用到源代码相似检测中可以有效利用源代码注释中包含的语义信息,从而提高代码相似检测的准确性。
对于源代码注释,该文使用LDA模型[15]来处理。LDA模型是用来预测文档的主题概率分布的,该模型将文本的主题以概率分布的形式给出,可以用来进行文本主题聚类或者文本分类。文本使用LDA模型来提取注释的主题特征。
1.2.2 型 构
该文以方法级别的源代码为研究对象,因此提出方法型构的概念,型构主要包括:方法名称、方法返回值类型、参数类型、参数个数。由于参数类型和数量比顺序更重要,因此该文忽略参数之间的顺序。方法型构主要特征如下:
(1)方法名称;
(2)方法返回值类型;
(3)参数类型列表;
(4)参数个数。
1.2.3 代码文本语句
代码文本语句特征主要度量代码行数与各类语句的数量。代码文本语句主要特征如下:
(1)代码行数;
(2)赋值语句数量;
(3)选择语句数量;
(4)迭代语句数量;
(5)switch语句数量;
(6)case语句数量;
(7)返回语句数量;
(8)try语句数量;
(9)catch语句数量;
(10)变量声明语句数量;
(11)表达式语句数量;
(12)变量类型数量。
1.2.4 代码结构
代码结构特征主要考虑if语句与循环语句之间相互嵌套的数量以及表达式语句、变量声明语句、控制语句之间前后相继关系的数量,代码结构主要特征如下:
(1)if语句嵌套循环语句数量;
(2)循环语句嵌套if语句数量;
(3)if语句嵌套if语句数量;
(4)循环语句嵌套循环语句数量;
(5)表达式语句→控制语句数量;
(6)表达式语句→变量声明语句数量;
(7)变量声明语句→表达式语句数量;
(8)变量声明语句→控制语句数量;
(9)控制语句→表达式语句数量;
(10)控制语句→变量声明语句数量。
其中“A→B”的含义为A语句后面紧接B语句。
2 特征提取
代码文本本身的相似性度量,可以通过AST或者PDG技术分析代码的结构相似性。以往的研究在对源代码进行预处理时都去除了源代码注释,而重点关注代码本身,然而注释对于研究源代码相似具有重要意义,特别是在对源代码语义相似检测时更是如此。
文中特征主要从代码注释、方法的型构、代码文本语句与结构等方面进行特征提取,基于多特征值来进行代码相似性度量,这样可以提高准确度。图1给出了代码特征提取的流程。
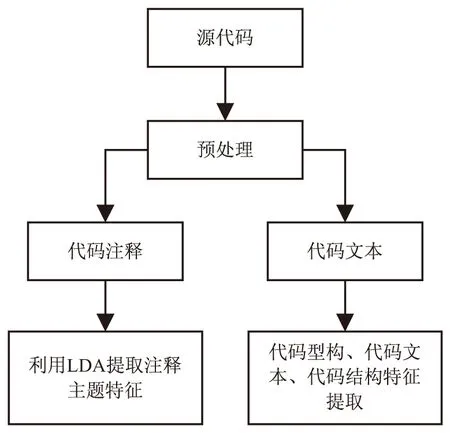
图1 代码特征提取流程
流程主要包括以下步骤:
第1步:对源代码进行预处理,提取注释将源代码分为注释文本和代码文本两部分。
第2步:对注释进行预处理后,使用gensim库的LDA模型来提取注释文本的主题特征。
第3步:对于代码分别从型构、代码文本语句、代码结构三方面,构建算法对代码文本语句以及代码的抽象语法树进行处理从而提取特征。
2.1 预处理
优雅的程序设计语言源代码会有规范的注释,特别是对于方法级别的源代码而言,注释能够反映代码的功能,能够直接体现出源代码的语义信息。然而,在早期的源代码相似性检测的研究中,学者往往把重点放在代码文本本身,而忽略了注释,在预处理的时候会去除所有的注释,这样做往往是因为自然语言语法语义的复杂性,但是这样会丢失大量的语义信息,特别是对于代码方法级别的注释而言。
随着自然语言处理技术的进一步发展,可以将自然语言处理技术应用到源代码相似性检测的研究中,从注释中获取所蕴含的重要的源代码语义信息。因此该文在进行预处理的时候需要将注释提取出来而不是删除。以Java源代码为研究对象,预处理步骤如下:
(1)提取所有在符号“//”之后、“/* */”和“/* * */”之间的程序注释内容,将注释与代码文本分离,将提取注释文本内容存储在commentText中;
(2)删除“import”开头的引包代码;
(3)删除源代码中的空行;
(4)删除每一行代码中的第一个非空字符之前的所有空格和“Tab”键;
(5)将代码存储在codeText中。
2.2 注释特征提取
使用python自然语言处理库gensim的LDA(latent Dirichlet allocation)模型来提取注释文本的主题特征。主要步骤如下:
算法1:注释文本主题特征向量生成算法。
输入:注释文本commentText。
输出:注释文本对应的主题特征向量。
①根据所有注释文本commentText创建文本数组documents;
②去除停用词“a, for, of, the, and, to, in”,将分词后的结果存储在texts数组中;
③去除texts数组中词频为1的词;
④调用corpora.Dictionary(texts)函数创建字典对象dictionary;
⑤对texts中的每一个text调用dictionary.doc2bow(text)构建词库对象corpus;
⑥根据字典对象dictionary和词库对象corpus调用models.ldamodel.LdaModel构建注释文本的LDA(latent Dirichlet allocation)模型lda;
⑦根据注释文本输出对应的注释主题特征向量。
2.3 型构特征提取
型构特征主要包含方法名称、方法返回值类型、参数类型、参数个数。自定义CodeSignature类,创建CodeSignature对象来存储代码型构的特征。
型构特征提取算法如下:
算法2:型构特征提取算法。
输入:源代码。
输出:型构特征对象codeSignature。
①创建codeSignature=(methodName, returnType, paramType)对象用于存储型构特征值;
②逐行扫描代码提取第一个“(”之前的代码存储在methodSignature字符串中,将第一个“(”和“)”之间的代码存储在methodParam字符串中;
③过滤methodSignature字符串,去除“public”、“private”、“static”、“synchronized”等方法修饰符;
④将返回值类型和拆分后的方法名分别存储在codeSignature对象的字符串数组属性methodName和字符串属性returnType中;
⑤从methodParam提取出一个或多个参数类型并存储在codeSignature对象的字符串数组属性paramType中;
⑥输出codeSignature对象。
2.4 代码文本结构特征提取
对于代码结构特征,该文使用Eclipse JDT AST生成源代码对应的抽象语法树,获得方法对应的节点MethodDeclaration类,通过解析MethodDeclaration类的属性来提取特征。
创建特征统计数组CodeStructure来存储代码结构特征。代码结构特征提取算法如下:
算法3:代码结构特征提取算法。
输入:源代码code。
输出:代码结构特征统计数组codeStructure。
①创建代码文本与结构特征统计数组codeStructure[1..10],初始值均为0;
②创建ASTParser对象parser,再通过调用parser.createASTs(code)方法创建抽象语法树;
③遍历ASTNode获得methodDeclaration对象节点;
④通过methodDeclaration对象的方法体对象body,获得IfStatement、ForStatement、ExpressionStatement等节点以及它们之间嵌套或者前后关系从而提取代码结构的特征值;
⑤将特征值赋值给代码结构特征统计数组codeStructure;
⑥输出codeStructure,
2.5 代码文本语句特征提取
代码文本语句特征提取与代码型构特征提取类似,这里不再给出算法。
2.6 相似度计算模型
文中代码相似度计算主要从代码注释、型构、代码文本语句以及结构这些方面来考量。先分别计算代码注释、型构、文本语句和结构的相似度,再进行加权计算得出源代码的最终相似度。计算公式如式(2)所示,最终源代码的相似度为代码注释、型构、文本与结构相似度的线性组合,其中的参数α、β、γ、δ均设定为0.25。
S源代码=S注释×α+S型构×β+S文本语句×γ+
S结构×δ
(2)
3 实 验
为了更好地验证基于多特征值的源代码相似性检测技术的有效性,选取了12种算法以及每个算法对应的9种相似代码作为实验数据,并通过对比实验来验证基于多特征值的源代码相似性检测技术的有效性。
3.1 实验步骤
实验主要分为三个步骤:构建源代码数据集、特征提取、相似度计算。实验流程如图2所示。
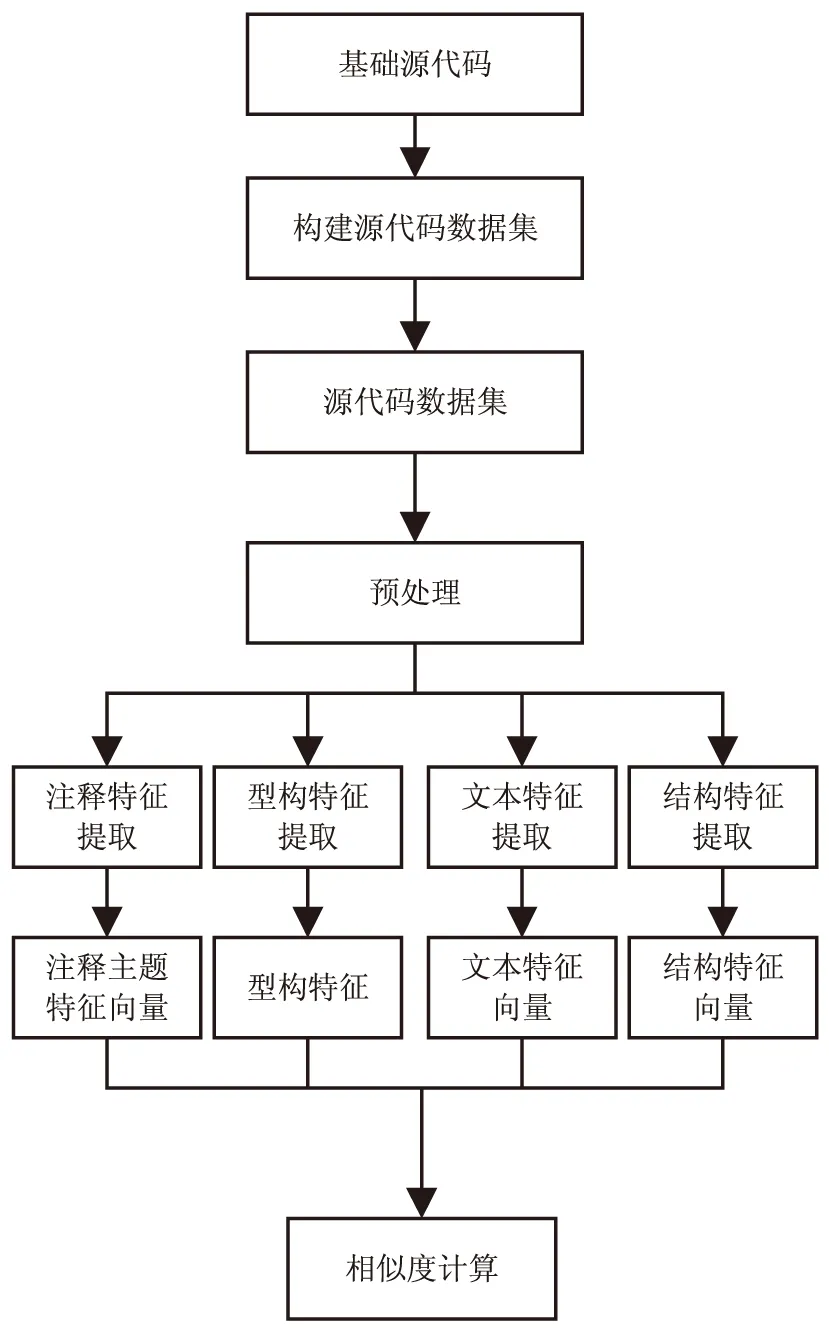
图2 实验流程
3.2 构造源代码数据集
由于没有开源的相似代码的分析数据包,该文选取带有注释的12个程序作为实验基础源代码。这些程序包括选择排序、冒泡排序、插入排序、快速排序、归并排序、堆排序、桶排序、KMP算法、最小生成树算法、最短路径算法、关键路径算法、贪心算法。为了构建足够的实验数据,对每个算法分别使用文献[11]中介绍的除去完整拷贝剩下的9种抄袭变换来手动构造相似源代码,并分为多组来进行实验。每组包含以下数据集:基础源代码T0以及9个修改后的相似代码T1,T2,…,T9。修改主要包括:
(1)修改注释;
(2)重新排版;
(3)重命名标识符;
(4)更改代码块顺序;
(5)更改代码块内语句顺序;
(6)修改表达式操作符或操作顺序;
(7)修改数据类型;
(8)增加冗余语句或者变量;
(9)替换控制结构为等价的控制结构。
9个修改后的源代码分别对应T1-T9。每一组数据集中的T0-T1、T0-T2、T0-T3、T0-T4、T0-T5、T0-T6、T0-T7、T0-T8、T0-T9源代码对均为相似源代码。
3.3 特征提取与相似度计算
该步骤分别对源代码按照代码注释、型构、代码文本语句与结构进行特征提取。然后分别计算注释、型构、代码文本语句与结构的相似度。
3.3.1 注释相似度计算
首先,将源代码的注释文本转化为与之对应的主题特征向量,然后,计算不同源代码注释的主题特征相似度。以插入排序与选择排序的注释生成的主题特征向量为例,如果取主题数为2,则二者的主题特征向量分别为(0.927 850 2,0.072 149 83)和(0.976 045 8,0.023 954 21),将这两个向量的余弦相似度作为对应的注释之间相似度S注释。
3.3.2 型构相似度计算
该文用SigVector表示方法的型构,SigVector定义为SigVector=(X1,X2,X3,X4),其中X1为两个型构的方法名中相同单词数与每个型构总单词数之比;X2为返回类型是否相同,相同为1,不相同为0;X3为两个型构中参数类型相同数与每个型构总参数数量之比;X4为参数数量是否相同,相同为1,不相同为0。型构相似度计算如式(3)所示。
(3)
3.3.3 代码文本语句与结构相似度计算
对于代码文本语句与结构,以特征属性值组成的向量之间的余弦相似度作为代码文本语句与结构之间的相似度S文本语句、S结构。
以插入排序与选择排序代码为例,它们的代码文本语句特征数组、代码结构特征数组分别如表1、表2所示。

表1 代码文本语句特征数组

表2 代码结构特征数组
3.4 相似度计算
在分别得到代码注释、型构、代码文本语句与结构的相似度之后,再通过相似度计算模型S源代码=S注释×00.25+S型构×0.25+S文本语句×.25+S结构×0.25计算出源代码之间的相似度。
4 实验结果与分析
该文使用Moss[16]抄袭检测系统来进行实验对比,该系统是一个权威的代码抄袭检测系统,能够检测代码相似性,它采用串匹配算法通过将代码作为字符串放入哈希表再从表中选取一个子集进行比较,以此进行相似度度量。分别对12组代码程序进行实验,并以12组实验数据的相似度检测结果的平均值作为最终结果进行比较,表3和图3给出了平均相似度检测结果。
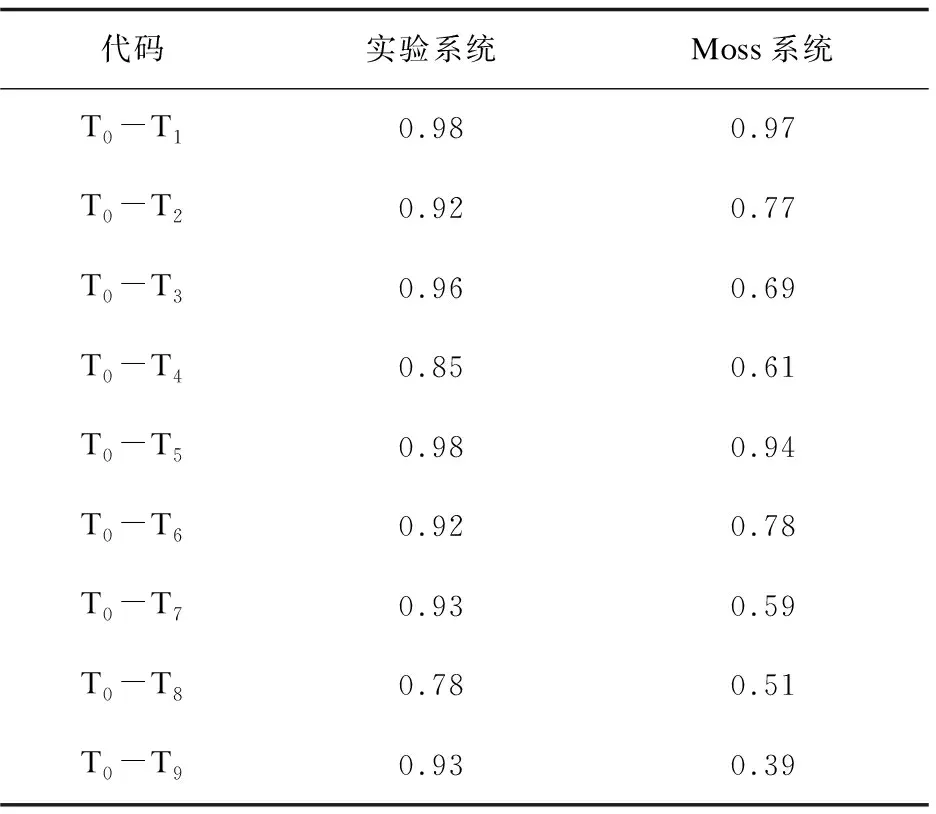
表3 平均相似度检测结果
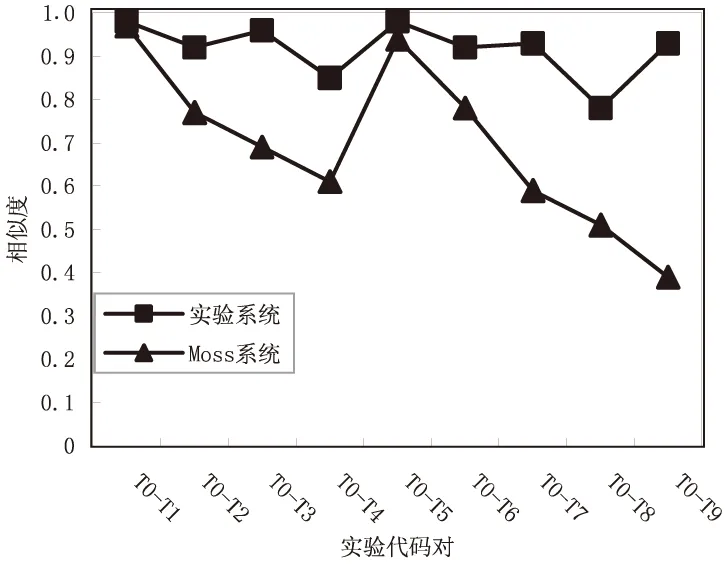
图3 平均相似度检测结果
通过实验对比可以看出,由于全面考虑了代码的多种特征,该文采用的方法能更准确地检测出多种抄袭手段修改后的相似代码。对于Moss方法检测结果较差的修改类型,如修改数据类型、替换控制结构为等价的控制结构等,都能检测到较高的相似度。
5 结束语
提出的基于多特征值的源代码相似性检测技术,将代码的相似问题转化为特征向量相似的问题,并且考虑了代码多个维度的特征,特别是考虑了源代码注释这一维度,这样能够有效地提取出代码的语义信息,从而能够提高源代码相似性检测的准确性。
然而,文中实验只是在一个很小的数据集上对基于多特征值的源代码相似性检测技术进行了验证。该源代码相似性检测技术还需要在更大的数据集上做更进一步的验证,通过扩大数据集,并使用机器学习的方法来提高实验的效率。另外,相似度计算采用了一个线性组合的方法,而且权重都取0.25,还可以进一步研究并调整各维度的权重从而优化检测结果。
