基于量子计算的医疗数据敏感度度量
2021-01-19李晓峰焦洪双王妍玮
李晓峰,焦洪双,王妍玮
(1.黑龙江外国语学院 信息工程系,黑龙江 哈尔滨 150025;2.普度大学 机械工程系,印第安纳州 西拉法叶市 IN47906)
0 引 言
利用大数据分析和处理方法对医疗信息进行管控、建立医疗大数据的融合调度和敏感度表征模型,有利于提高对医疗大数据的信息检测和统计分析能力。通常来说,对医疗大数据进行处理的方法是建立在对医疗数据的统计分析和大数据融合采样基础上的[1],建立医疗数据的量化分析模型,结合模糊信息调度方法,有利于提高医疗信息的表征能力[2]。由于很多医疗应用程序都包含敏感信息的输入过程,为确保敏感信息的安全性,使患者的个人权益不受侵害,研究敏感信息的安全保护机制尤为重要,而这一过程,需建立在对医疗数据敏感度进行度量的基础上。因此,相关的医疗数据敏感度度量和特征分析方法研究,在医疗数据的信息诊断和检索等领域中具有很好的应用价值。
目前,已有很多专家学者在该领域进行了研究,所得到的医疗数据的敏感度度量方法主要有统计特征分析方法、三维特征重构方法、C均值重构度量方法等。总的来说,对医疗数据敏感度进行度量的方法是建立在医疗数据的谱特征分析和特征提取结果的基础上的,从中提取医疗数据的敏感度特征分量,再结合高阶统计信息融合方法对医疗数据进行三维重构。在此基础上,根据医疗数据的融合聚类分析结果结合医疗数据的表面重建,实现医疗数据的三维重构和特征分析,完成对敏感度的度量[3]。文献[4]中提出了一种基于改进全卷积神经网络的大数据表面重建和敏感度度量方法,在该方法中,采用无线射频识别技术进行大数据采样和敏感度特征分析,结合卷积神经网络分析方法,实现对数据的敏感度度量。但该方法进行医疗数据敏感度度量的自适应性不好,统计分析能力不强。文献[5]中提出了一种基于关联规则特征检测的医疗数据敏感度度量方法,在该方法中,首先对医疗信息管理系统中的医疗数据的存储结构进行分析,采用支持向量机算法区分医疗数据的属性类别,再在同类属性数据中筛选出敏感度数据并对其敏感度进行计算。然而在利用该方法进行医疗数据敏感度度量的时间开销较大,度量过程过于繁琐。文献[6]中提出了一种基于秩约束密度敏感距离的自适应聚类方法,该方法首先引入密度敏感距离相似度度量方法扩大不同类数据间的距离,并将秩约束施加于拉普拉斯矩阵,使相似矩阵的连通区域数量等于聚类数量,将数据划分至相应的类别中,在聚类的基础上实现对数据敏感度的度量。然而该方法对敏感数据的查准率较低,对敏感数据的采集和获取结果不理想。
量子算法是指利用量子计算的并行性和纠缠性等特征、将量子理论与计算机技术相结合的新型计算模式。由于量子的独特性质,使得量子算法能够适应大数据量的处理,计算成本也大大减少。为此,针对当前方法中存在的度量过程自适应性差、度量开销大、对敏感数据查准率较低的问题,该文提出一种基于量子计算的医疗数据敏感度度量方法。整体思路如下:首先采用分布式样本重构方法对医疗数据的分布式结构进行重组,然后采用量化回归分析方法对医疗数据进行模糊融合和聚类分析,根据融合分析结果建立定量递归分析模型,在此基础上,结合量子计算对度量过程进行寻优约束,并采用动态全局规划方法实现对医疗数据敏感度的度量。最后通过仿真实验结果证明了该方法在提高医疗数据敏感度度量性能方面的优越性能。
1 医疗数据的分布式结构重组及统计分析模型
1.1 医疗数据的分布式结构重组
为了实现对医疗数据敏感度的准确度量,首先构建医疗数据的分布式结构重组模型,采用高阶统计特征分析方法,进行医疗数据的分布式结构重组过程中的特征提取和分布式特征检测[7],继而建立医疗数据度量的模糊关联规则特征检测模型,采用一条NURBS曲线进行医疗数据的分布式结构重组[8-9],这一过程表述如下:
(1)
其中,N表示采集到的用于进行敏感度度量的医疗数据;P表示重组结果;Ci(i=0,1,…,n)表示医疗数据的分布式度量的控制顶点;Wi(i=0,1,…,n)表示自适应学习的权因。在此基础上,对医疗数据的分布式结构重组的权因子进行量化寻优,当分布式权值满足W0>0,Wn>0时,采用模糊加权学习方法,假设Ni,k表示第k次寻优规范的样条函数,则由递推公式计算医疗数据的分布式结构重组模型为:
(2)
其中,U=(u0,u1,…,ui+k+1)表示医疗数据敏感度度量节点矢量,u表示NURBS曲线的自变量。根据上述重组结果,结合关联规则挖掘方法进行医疗数据敏感度度量的自适应寻优,从中提取出医疗数据的关联维特征量,再采用关联特征检测方法进行医疗数据敏感度度量过程中的模糊加权学习。在这一过程中,得到的统计特征量为:
X=xi(P-Ni,k×α)
(3)
其中,xi表示医疗数据敏感度度量的状态矢量,α表示模糊加权系数。对于所得的统计特征量,结合自适应学习方法对医疗数据进行三维特征重建。设置r个不同的聚类中心中医疗数据结构重组的状态因子,得到医疗数据敏感度度量的动态增量函数h1,h2,…,hi,…,hr,每一个函数满足hi:{0,1}*→[1,m]。采用线性映射方法,建立医疗数据敏感度度量的模糊度检测模型,结合结构重组方法进行医疗数据敏感度度量和统计特征分析,所得的模糊度检测结果为:
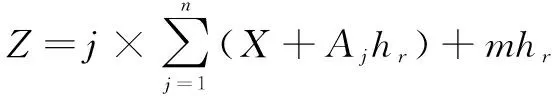
(4)
其中,m表示医疗数据三维特征动态重构的模糊度分布特征集,Aj表示不同模糊度下医疗数据敏感度度量的聚类中心,其中j(j=1,2,…,n)表示模糊度。
1.2 医疗数据度量的统计分析模型
在上述研究的基础上,根据模糊度检测结果建立医疗数据敏感度度量的统计分析模型,采用量化回归分析方法进行医疗数据敏感度度量的模糊融合和聚类分析[10]。首先,采用样本回归分析方法进行医疗数据度量的统计特征分析,得到的统计特征量表示如下:
(5)
其中,di,j(i,j=0,1,…,n)表示医疗数据敏感度度量的控制顶点。采用插补算法进行医疗数据敏感度度量过程中的二维插值运算,以等弧长为度量尺度,进行医疗数据敏感度度量曲线分割[11-12]。使用f表示医疗数据敏感度度量的样条曲线,根据时间t的变化,利用一阶泰勒级数展开上述统计特征量,得到医疗数据统计特征量的时间尺度分解式为:
(6)
其中,H.O.T表示高阶微量。对于式(6)中的ti,采用i次插补方法,进行医疗数据敏感度度量的量化回归分析,建立统计分析模型,对应的插补时刻,得到医疗数据的敏感度度量的量子计算微量[13],可定义为:
(7)
忽略医疗数据量子计算的高阶微量H.O.T,根据量子计算方法[14]可得到医疗数据统计分析的参数增量ΔV如下:
ΔV=Ts×(V(t)-V')
(8)
其中,Ts为曲线插补周期。在此基础上,采用支持向量机模型,进行医疗数据敏感度度量的动态增量控制,得到控制误差性能曲线为:
l=ΔV(M+c)e
(9)
其中,M表示医疗数据敏感度特征分布的正定值;e表示医疗数据统计分析的模糊度函数;c表示为聚类误差。则根据误差控制结果对医疗数据进行统计分析,结果如下:
G=l(ΔV×M-c×Z)
(10)
通过得到的医疗数据的统计分析模型,建立医疗数据敏感度度量的定量递归分析模型,采用量子计算方法进行医疗数据敏感度度量过程中的自适应寻优控制。
2 医疗数据敏感度度量设计
2.1 量子计算过程
在上述采用分布式样本重构方法进行医疗数据的分布式结构重组,并建立医疗数据敏感度度量的统计分析模型的基础上,进行医疗数据敏感度度量模型的设计。该文提出了基于量子计算的医疗数据敏感度度量方法。采用量子计算方法进行医疗数据敏感度度量过程中的自适应寻优控制,采用模网格分区域聚类分析方法,建立医疗数据敏感度度量的关联规则特征分布集,结合分簇融合方法进行医疗数据的敏感度度量。分布集的簇模型描述为:
(11)
其中,ρ1,…,ρn为一组医疗数据敏感度特征分布的关联特征量。根据量子隐形传态原理可得到共享的量子纠缠特征值O。对医疗数据的敏感度的关联进行映射,根据映射结果,得到在邻域空间q内,医疗数据敏感度度量的量子计算统计分布集为:
F=O×(G×q+E)
(12)
采用量子计算方法,得到医疗数据敏感度度量的模糊关联度,输出为s,得到量子寻优进化模型为:

(13)
2.2 医疗数据敏感度度量实现
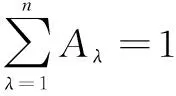
(14)
综上所述,该文结合量子计算方法实现了对医疗数据敏感度度量。首先初始化医疗数据,在建立统计分析模型的基础上,采用样本重构方法重组医疗数据的分布式结构,然后采用量化回归分析方法对医疗数据进行模糊融合和聚类分析,建立其定量递归分析模型,继而采用量子计算进行医疗数据敏感度度量过程中的自适应寻优控制,通过全局动态规划方法实现对医疗数据敏感度的度量。其实现过程如图1所示。
3 实验与结果分析
为了测试所提的基于量子计算的医疗数据敏感度度量方法的实际应用性能,设计如下仿真实验进行验证。
3.1 实验环境和数据集
实验环境设置情况如下:实验所有医疗数据来自于ADNI数据库(adni.loni.usc.edu),医疗数据敏感度特征分布样本长度为1 200,对医疗数据的敏感度属性分布的维数为12,对医疗数据网格聚类的大小40*40,对医疗数据的统计特征分析的样本训练集为60,关联度特征分布系数为0.12。硬件环境为:Windows7系统,Visual Studio2010操作平台。
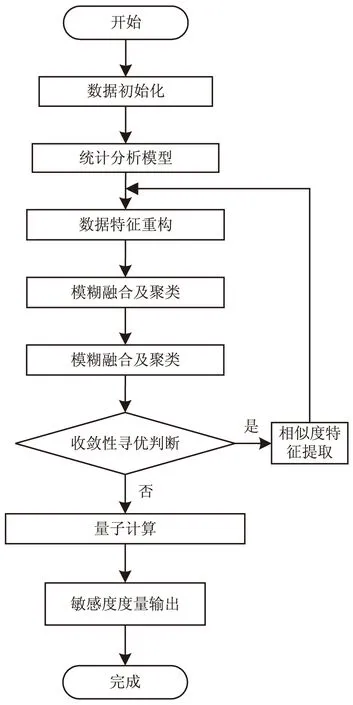
图1 基于量子计算的医疗数据敏感度度量实现
为使实验结果具有说明性,将所提的基于量子计算的医疗数据敏感度度量方法与文献[4]中的基于改进全卷积神经网络的大数据表面重建和敏感度度量方法、文献[5]中的基于关联规则特征检测的医疗数据敏感度度量方法、文献[6]中的基于秩约束密度敏感距离的自适应聚类方法作对比。
3.2 实验指标
(1)数据查准率。
查准率是一种衡量检索过程的准确度的指标,通过查准率的对比,可以判断不同方法对敏感医疗数据的检索能力,其计算过程如下:
(15)
(2)度量时间开销。
负载开销指在数据敏感度度量过程中所花费的时间,可以判断不同方法的时间消耗情况。度量开销结果由Visual Studio2010操作平台自动统计。
(3)查全率。
查全率是指由度量过程检索出的相关数据量与数据总量的比率,由数据内容、数量和运行环境的平稳性来决定,是衡量度量成功度和自适应性的一项指标,其计算过程如下:

(16)
3.3 实验结果与分析
根据上述实验条件和指标的设定情况,进行医疗数据的敏感度度量实验。首先对医疗数据进行采集,在此基础上,建立医疗数据敏感度度量的定量递归分析模型,采用量子计算方法进行医疗数据敏感度度量过程中的自适应寻优控制,实现敏感度表征。得到的医疗数据敏感度表征结果如图2所示。
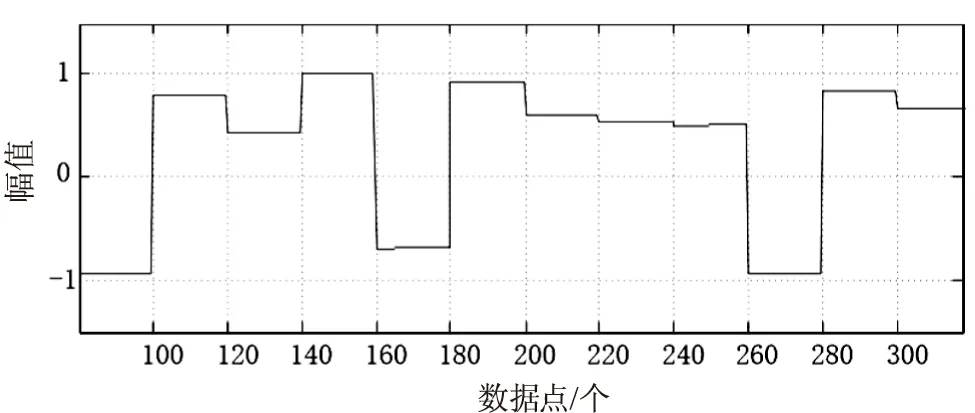
图2 医疗数据敏感度表征结果
分析图2可知,采用基于量子计算的医疗数据敏感度度量方法后,医疗数据敏感度的波动幅值始终保持在[-1,1]之间,波动情况较为稳定,证明利用基于量子计算的医疗数据敏感度度量方法进行医疗数据敏感度度量过程的敏感特征辨识能力较好,信息反馈能力较强、自适应优势明显。
测试不同数据敏感度度量方法的数据查准率,对比结果如表1所示。

表1 不同医疗数据敏感度度量方法的
分析表1可知,随着实验迭代次数的不断增加,不同方法的度量查准率也在不断发生变化,整体表现出上升态势。其中,文献[5]方法的度量查准率的上升幅度最大,但其度量查准率值低于文中方法、文献[4]方法和文献[6]方法。文中方法的度量查准率上升幅度虽小,但度量查准率值更高,证明采用文中方法在医疗数据敏感度度量过程中,对医疗敏感数据的捕获能力较强,检索误差较小,能够有效实现敏感医疗数据的查准。
为进一步对度量方法的有效性进行检验,测试不同数据敏感度度量方法的度量开销和查全率,结果分别如图3和图4所示。
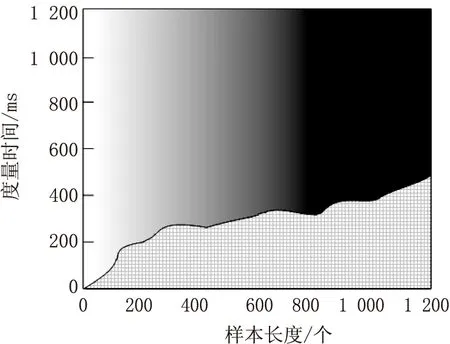
(a)文中方法
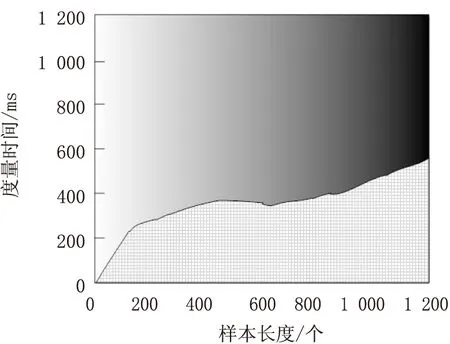
(b)文献[4]方法
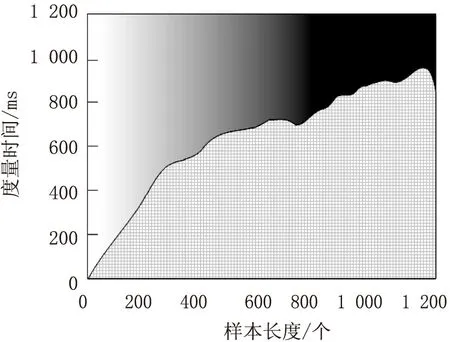
(c)文献[5]方法

(d)文献[6]方法
分析图3可知,随着数据样本数量的增加,同医疗数据敏感度度量方法度量所需的时间也在不断变化。文中方法和文献[4]、文献[5]方法的时间开销均呈现出上升态势,而文献[6]方法的时间开销先上升后下降。但四种方法中,文献[5]方法的时间开销最大,文中方法和文献[4]方法的时间开销较接近,但文中方法的时间开销更小,证明采用文中方法在医疗数据敏感度度量方法的时效性更强。
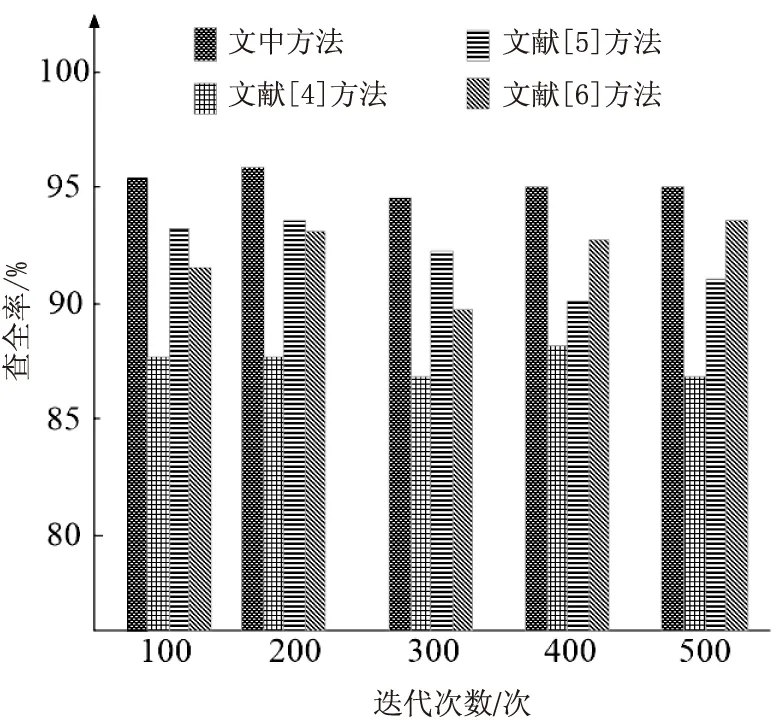
图4 不同医疗数据敏感度度量方法查全率对比
分析图4可知,随着实验迭代次数的不断增加,不同医疗数据敏感度度量方法的查全率也在不断发生变化。但文中的基于量子计算的医疗数据敏感度度量方法的查全率始终在4种方法中保持最高,维持在95%左右,证明该方法具有较强的自适应性,对数据的统计分析能力较强。
4 结束语
为对医疗数据的敏感度进行准确度量,提出基于量子计算的医疗数据敏感度度量方法。采用分布式样本重构方法进行医疗数据的分布式结构重组,对医疗数据进行统计分析,结合量化回归分析方法进行医疗数据敏感度度量的模糊融合和聚类分析,建立医疗数据敏感度度量的定量递归分析模型,采用量子计算方法建立医疗数据敏感度度量的量子寻优约束进化模型,根据动态全局规划结果完成医疗数据敏感度的度量。经实验研究得知,利用该方法进行医疗数据敏感度度量的辨识能力较好、统计分析能力较强,且自适应性能较强,为保证医疗信息的安全性奠定了基础。在今后的研究中,将进一步对该方法进行优化,以期使所提的数据敏感度度量方法在度量时效和应用范围两个方面有效突破。
