基于GFCC与CFC的低信噪比说话人识别
2021-01-15冯月春陈惠娟
◆冯月春 陈惠娟
基于GFCC与CFC的低信噪比说话人识别
◆冯月春1陈惠娟2
(1.宁夏理工学院 宁夏 753000;2.西安工程大学 陕西 710048)
在全特征矢量集模型CFC和互信息识别的基础上,对不同的语音特征参数提取方式及不同特征在不同信噪比下的识别率做了比较,实验结果表明基于人耳听觉特性的稳健特征提取方式在高信噪比时识别率最高;本文针对低信噪比情况下说话人识别系统的识别率较低的问题,提出了基于多窗谱估计普减法的能熵比法用于语音的前端降噪处理,结果表明通过改进的端点检测法在低信噪比下明显提高说话人识别的识别率。
端点检测;CFC;识别率
说话人模型是说话人识别系统的核心,目前常见的说话人模型包括:隐马尔科夫模型、高斯混合模型、矢量量化、人工神经网络等。这些方法的运用只考虑了语音信号的时变分布特征,并没有考虑语音信号的统计分布特征,同时计算量比较大。上海大学的俞教授提出了全特征矢量集模型CFC[1],该模型基于互信息理论和语音信号分析,对随机变量或随机信号之间所携带对方信息进行定量描述,由于该模型同时考虑了语音信号的时变分布特征和统计分布特征,能有效地提高类间耦合度和类内凝聚度,是目前常用的说话人模型匹配方式。该模型对语音参数特征敏感,尤其是低信噪比的情况下。因此,语音特征的提取方式是CFC精度的主要影响因素。本文在全特征矢量集模型CFC和互信息识别的基础上,对不同的语音特征参数提取方式识别率做了比较,结果表明基于人耳听觉特性的稳健特征提取方法在高信噪比时识别率最高,在低信噪比下识别率较低,本文采用多窗谱估计普减法[2]和能熵比相结合的端点检测,对语音信号进行预处理,使说话人识别在低信噪比下识别效果明显改善。
1 互信息匹配识别模型及原理
1.1 说话人全特征矢量模型
全特征矢量集模型CFC的基本思想是通过对一组包含说话人各种语音发音个性特征的数据进行分析处理,提取相应的代表性特征矢量表示说话人语音模型,其训练过程如下。
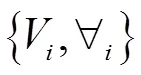
(2)计算各原始特征矢量与CFC中各特征矢量之间的距离,并将原始特征矢量赋予与其距离最小的CFC特征矢量所在子集,即:

(3)对每个CFC特征矢量子集中的原始特征矢量在特征空间计算其均值,并将其作为新的CFC特征矢量,即
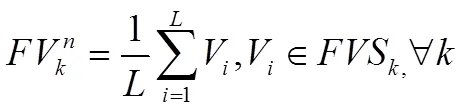
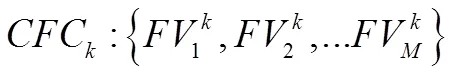
1.2 基于互信息评估的说话人识别原理

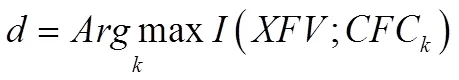
从理论上分析,由于不可能得到严格的语音信号特征矢量的概率分布密度函数以及语音模式的条件概率,语音模式之间的互信息计算只能通过合理的估计进行,即引入了熵的计算。公式如下:
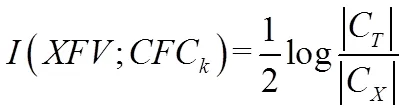
2 语音特征提取实验对比
2.1 实验环境
本文涉及的说话人识别实验中训练语音数据均在实验室环境下用进行录制,采样率11025Hz,量化精度16 位,每个人录制了7 段12 秒的语音,其中,前4 段用于训练,后3 段用于识别。为了比较各种特征提取方式的鲁棒性,分别在原语音数据中叠加上固定比例的噪声。实验所使用8种噪声类型,信噪比分别为0dB,10dB,20dB,30dB。实验结果如图1(a)、(b)所示。横轴代表不同的信噪比,纵轴代表说话人的识别率;图中矩形的线条表示为LPCC特征在不同信噪比下的识别率,圆形的线条为MFCC特征在不同信噪比下的识别率,三角形的线条为GFCC特征在不同信噪比下的识别率,星形为组合特征MFCC+GFCC在不同信噪比下识别率[4]。
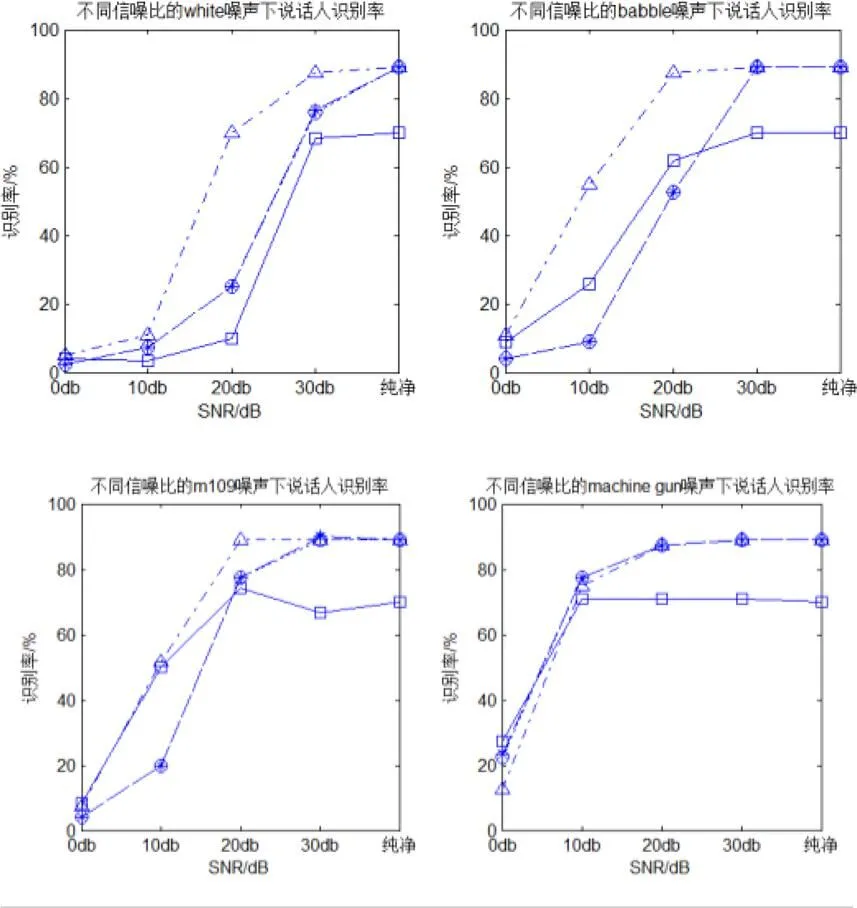
图1(a) 不同信噪比下说话人识别率
图1(b) 不同信噪比下说话人识别率
2.2 实验结果与分析
(1)在纯净语音环境下,MFCC,GFCC和MFCC+GFCC的识别率一致,最高可达到90%,而LPCC的识别率相对较低,在70%左右。
(2)在低信噪比下GFCC特征参数和组合特征MFCC+GFCC的识别率优于MFCC和LPCC的识别率,说明GFCC具有一定抗噪性能。
3 改进的语音端点检测
从实验结果发现,普通的端点检测只对有话段检测和处理,一般用短时平均能量和短时平均过零率就可以检测出语音的端点,但实际处理中语音往往处于复杂的噪声环境中,判别语音段的起始点和终止点的问题主要归结为区别语音和噪声的问题。因此,采用基于多窗谱估计普减法的能熵比法用于端点检测,来提高说话人识别的正确性。改进后说话人识别工作原理如图2所示:
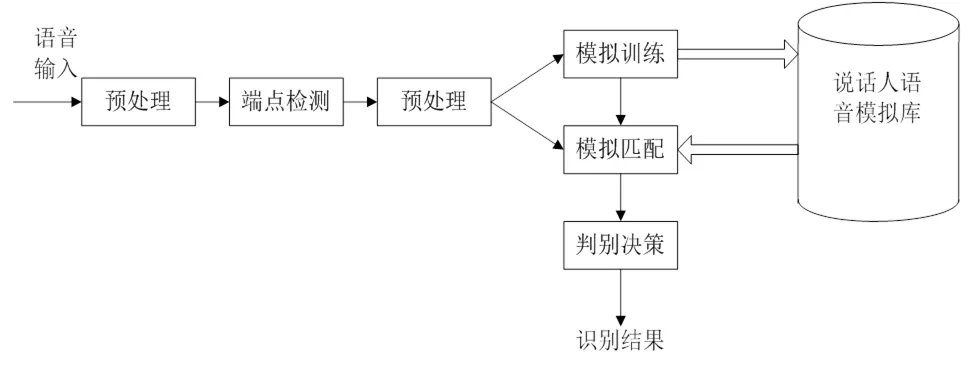
图2 说话人识别系统
4 实验结果
实验结果如图3(a)、(b)所示。其中,圆形表示普通的端点检测下特征GFCC的识别率,星形表示改进的端点检测下特征GFCC的识别率[5]。
从图3(a)、(b)中可以看出:(1)在8种不同的噪声环境下,采用两种端点检测法说话人识别的识别率均随着信噪比的增大越来越大。(2)从图中可以看到,在低信噪比下对含噪的语音法进行预处理后,对多数噪声识别率都有所提高。(3)八种噪音下在SNR低于5dB时,我们的抗噪声说话人识别系统的识别率提高明显。

图3(a) 不同信噪比下说话人识别率
图3(b) 不同信噪比下说话人识别率
5 结论
在全特征矢量集模型CFC和互信息识别的基础上,通过实验验证,结果表明低信噪比下的识别率较差;然后,针对此问题,提出了基于多窗谱估计普减法的能熵比法用于语音的前端降噪处理,通过改进的端点检测法算法使说话人识别在不同程度上得到了提高。
[1]俞一彪.基于互信息理论的说话人识别研究[D].上海:上海大学,2004.
[2]武鹏鹏,赵刚,邹明.基于多窗谱估计的改进普减法[J].现代电子技术,2008(12):151-152.
[3]杜晓青,于风芹.基于发声机理与人耳感知特性的说话人识别[J],计算机工程,2013,39(11),197-199.
[4]郭武.复杂信道下的说话人识别[D].合肥:中国科学技术大学,2007.
[5]余建潮,张瑞林.基于MFCC和LPCC的说话人识别[J].计算机工程与设计,2009(5):1189-1191.
宁夏高等学校科学研究项目(编号:NGY2018-166)
