考生能力分布与被试量对IRT 等值的影响
2021-01-13韩晓杰
韩晓杰 任 杰
一、引言
等值是将不同测验版本的分数统一到一个量表上的过程[1]。 等值不仅有利于保证测验的公平,为分数使用者提供来自不同测验版本上具有同等意义的分数,让不同版本的测验分数具有可比性;同时,等值也是题库建设中的重要一环, 通过等值可以将不同测验版本的题目参数统一到一个量尺上, 让题目参数具有可比性,等值误差越小,越有利于科学化题库的建设。
为保证测验的安全性, 某些全国性大型测验经常以平行试卷的形式对全国考生进行施测。 在题库建设时,需对所有平行试卷进行等值处理。不同地区的考生在平行试卷上得分不同,究其原因,一方面是试卷难度不同, 另一方面是不同地区考生能力存在差异。涂冬波(2004)指出,我国教育存在地区间发展不平衡的问题, 且该问题直接造成了地区间人才培养上的差距[2],即地区教育水平差异很大程度上会影响考生能力。那么,不同地区考生能力分布不同是否会影响不同平行试卷等值到基准卷上的结果? 这一问题直接关系到题库建设的科学化程度。
一般认为, 基于项目反应理论 (item response theory,IRT)的等值的一大优点在于不依赖被试。 但是,Holland & Rubin(1982)提出,等值或多或少存在样本依赖性[3]。 罗照盛等(2007)指出,当前关于等值误差问题的研究, 基本上都是在固定被试参数总体的情况下,并未系统研究锚题设计情形下,使用不同分布形态的被试组估计项目特征曲线等值系数时可能带来的等值误差;其研究结果表明,在实际等值估计过程中,不应只考虑样本量的大小,必须重视被试样本的分布形态[4]。 吴佳儒、陈柏熹(2008)针对等值过程中不同受试者人数与能力分布形态对试题参数与能力估计精准度的影响进行了研究, 研究结果表明: 能力以均等分布时, 等值的均方根误差(Root Mean Square Error,RMSE)值最高[5]。 Sevilay&Nukhet(2012)基于IRT 理论,根据样本量与被试分布形态对分别估计下的四种等值方法进行了比较研究;研究结果表明,Stocking-Lord 法的等值误差最小,且被试样组分布形态越接近,等值误差越小[6]。 以往研究中,试卷题目参数与考生能力参数均采用模拟数据。本研究将采用实际题目参数, 考生能力参数将根据实际考生能力参数进行模拟。 本文意在探讨与基准卷能力分布一致的被试以及与基准卷能力分布差异较大的被试对等值误差的影响, 并研究这种误差是否可以通过增大被试量来解决。
本研究基于IRT 理论中的LOGISTIC 双参数模型,采用共同题非等组设计。共同题非等组设计是等值设计中最为灵活有效的设计[7]。其具体方案是将同一测验的不同版本对两组考生进行施测, 两个测验版本之间存在约20%的共同题目。 两组考生的得分受到考生能力与题目难度两方面的影响, 通过考生在共同题上的作答表现可以分离出考生能力的差别,从而得到试卷难度差异。
在进行两份试卷等值时, 本研究采用项目特征曲线法。 该方法的优点在于充分利用了题目参数与考生能力参数的信息, 增加了等值结果的可靠性。1980 年,Haebara 率先提出基于项目特征曲线法来完成量表的转换。 Raju & Arenson(2002)认为,对于具有一定能力水平的参与者, 项目特征曲线的差值为每个项目的项目特征曲线平方和[8]。 Haebara 提出了使这一差值最小的方程常数和方程曲线。 1983年,Stocking 和Lord 提出与之类似的方法[9]。 两种方法均基于以下公式:

其中,θ 为考生的能力参数,a 为题目的区分度参数,b 为题目的难度参数,α为标杆卷,β 为待等值试卷,Pij为被试j 正确作答题目i 的概率。 A 为等值方程中的斜率,B 为截距。 将测验样本的项目参数估计值带入,会存在误差ε,误差最小时的A、B 值即为理想的等值系数值。 下面将分别介绍Haebara 法与Stocking-Lord 法对A、B 值的估计原理。
Haebara 法首先对误差求平方,可得:
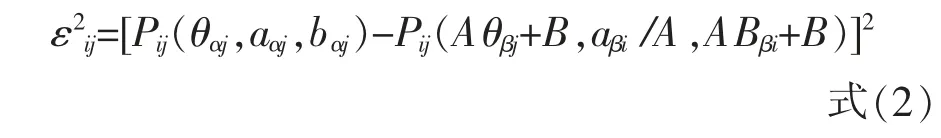
若存在n 个被试,m 个题目, 则将上式对i 与j进行求和,得到:


Stocking & Lord 法与Haeraba 的方法稍有差别。由于同一被试在同一批项目上的正确作答概率是相等的,Stocking-Lord 法首先将被试j 固定, 对题目i的正确作答概率进行累加,可得:

此时,再带入参数估计值,计算误差方差,可得:
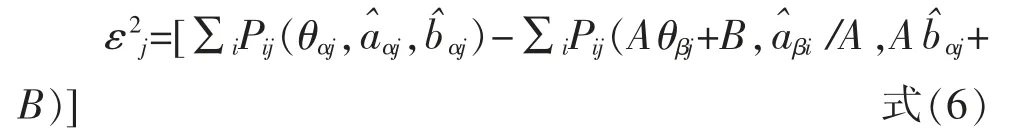
若存在m 个题目, 则需要对上式中的j 进行求和,并记为F2,可得:

当误差方差最小时,即令F1与F2最小,求出A、B 值即为理想的等值系数。 一般方法为求导并采用牛顿迭代法迭代求出最佳A、B 值。
等值方法不同会带来不同的等值误差。 误差分为随机误差和系统误差。 随机误差是由抽样造成的,增大样本量,随机误差会随之降低。 因此,本研究旨在通过对考生能力分布与被试量以及等值方法的研究,为降低等值误差提供参考。 同时,采用等值分数标准误、等值系数标准误、共同题参数稳定性三种方法对等值结果进行评价。
二、研究设计
本研究涉及某汉语考试某两个年份的试卷X 和Y。 这两份试卷为平行试卷,其中X 试卷为基准卷,Y试卷为待等值试卷。X 与Y 包含20%的共同题。作答X 试卷的考生组记为P, 作答Y 试卷的考生组记为Q。 模拟不同被试量下P 考生分布以及Q 考生分布去作答Y 试卷,再将Y 试卷与X 试卷等值,以此研究不同等值方法下考生分布及被试量对等值结果的影响。
(一)研究工具
本研究采用WINGEN3 对考生作答数据进行模拟,采用R 语言自编程序进行参数估计和试卷等值。
(二)研究设计
首先利用R 语言自编程序根据Q 组考生在Y试卷上的作答反应估计出Q 组考生的能力值, 并计算Q 组考生能力值的平均值与标准差。 经计算,平均值θQ为-0.064,标准差θQ为0.85。再根据P 与Q 两组考生在共同题上的作答反应估计出两组考生的能力差异,记为θε。 由此可得与Q 组考生在同一能力量尺上的P 组考生的能力为θP=θQ+θε。 经计算θP为-2.7。
利用WINGEN3 对考生作答进行模拟, 试卷参数使用Y 试卷的真实参数, 考生能力参数为正态分布,平均值分别采用θP和θQ,标准差采用原始能力值的标准差, 被试量分别为500、1000、5000 三个批次, 每个批次分别模拟15 次, 共90 批考生作答数据。 将90 批考生数据分别与基准卷X 进行等值,采用等值分数标准误、等值系数标准误、共同题稳定性三种方法对等值结果进行评价。
因此, 根据考生能力分布与被试量共模拟了以下6 种情况:
①被试量为500,考生能力分布服从[N(-2.7,1)]
②被试量为1000,考生能力分布服从[N(-2.7,1)]
③被试量为5000,考生能力分布服从[N(-2.7,1)]
④被试量为500,考生能力分布服从[N(-0.064,0.85)]
⑤被试量为1000,考生能力分布服从[N(-0.064,0.85)]
⑥被试量为5000,考生能力分布服从[N(-0.064,0.85)]
以下简称N(-2.7,1)为P 分布,N(-0.064,0.85)为Q 分布。
三、研究结果
学界对于等值结果的评价标准不一。张建、任杰(2018)提出,可以根据评价的对象不同,将等值结果评价标准划分为评价等值分数的标准和评价等值参数的标准[10]。 本研究拟采用以上两类评价标准中的等值分数标准误、等值系数标准误、共同题参数稳定性三种评价方法对等值结果进行评价。
(一)等值分数标准误
等值分数标准误是在评价等值分数时采取的主要评价标准, 其实质是考察样本量对等值分数的影响。一般而言,样本量越大,等值误差越小,等值结果越稳定。 Bootstrap 法和Delta 法均可计算等值误差。戴海崎(1999)认为,Bootstrap 法对等值误差的估计更接近于等值标准误差的定义[11]。 Bootstrap 法的计算步骤如下:
(1)分别在参加X 测验与Y 测验的考生中抽取样本量为nX、ny的样本;
(2)采用适当的等值方法将两个样本进行等值,可得:

由于抽样的复杂性, 一般采用特定的程序进行抽样和等值。等值后不仅会产生等值分数,也会产生等值分数标准误。等值分数标准误越小,等值结果越稳定。
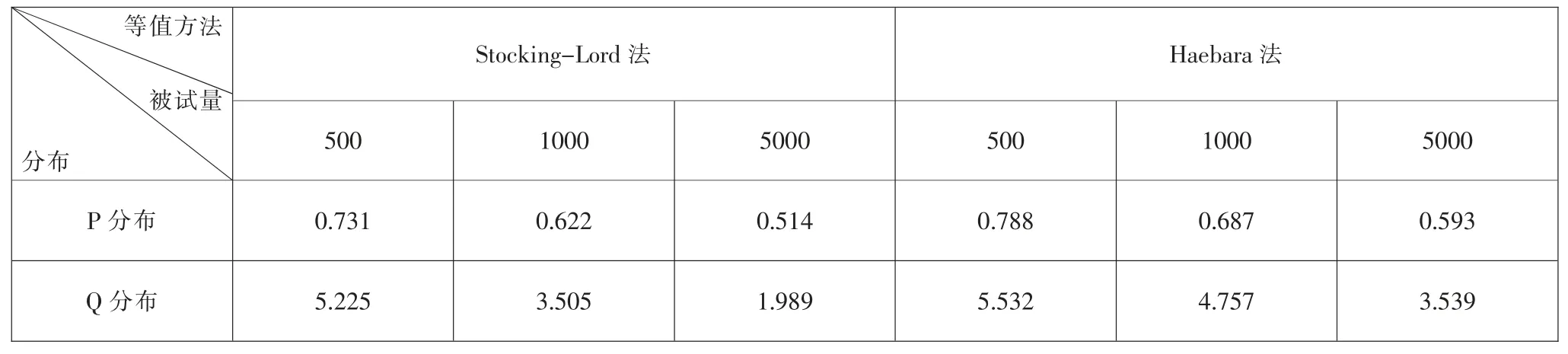
表1 等值分数标准误平均值
综合表1、图1 及图2 可知,Stocking-Lord 法与Haebara 法下等值分数标准误的趋势基本一致,Stocking-Lord 法等值结果更稳定。 当考生能力服从P 分布时,等值分数标准误较Q 分布低。 即考生能力分布越接近,等值分数的标准误越低。 两种分布下,等值分数标准误均随样本量的增加呈现出降低趋势。 P 分布中的等值分数标准误在不同批次及不同样本量中的变化均较为平稳;Q 分布中的等值分数标准误则波动较大,当样本量增至5000 时,变化趋于稳定, 但是其值仍高于P 分布中样本量为500 时的等值分数标准误。 本研究结果与罗照盛(2007)的研究结果不谋而合。在实际等值中,不能仅依靠增加样本量来降低等值误差, 还需关注两组考生的能力分布。当两组被试分布差异较大时,仅靠增加样本量并不能有效降低等值误差。

图1 Stocking-Lord 法下等值分数标准误

图2 Haebara 法下等值分数标准误
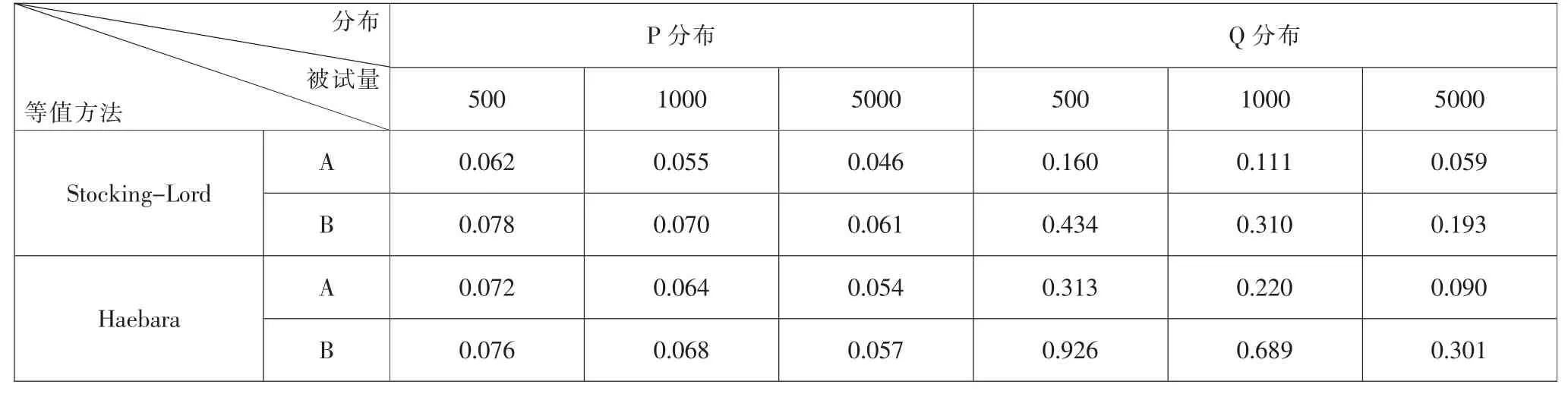
表2 等值系数标准误平均值
(二)等值系数标准误
等值系数是两份试卷之间分数转换与参数转换的关键所在,也是等值的核心环节。等值系数一般用A、B 表示。 两份试卷以及考生能力之间存在以下转换关系[12]:

采用不同的等值方法会得到不同的等值系数,同时也会产生不同的等值系数标准误。 等值系数标准误是衡量等值系数稳定性的标准,一般而言,等值系数标准误越小,等值系数越稳定,等值结果越好。
从表2 及图3-6 可知, 两种等值方法下等值系数A、B 的标准误变化趋势一致,均随样本量的增加而降低。 不同分布下标准误变化幅度不同,P 分布下的等值系数标准误较为稳定,Q 分布下的等值系数标准误随样本量变化波动较大。Stocking-Lord 法下,Q 分布中样本量为5000 时等值系数A 的标准误与P 分布中样本量为500 时的等值系数A 的标准误较为接近。 此外,Q 分布下的等值系数标准误均高于P分布下的等值系数标准误。样本量一定时,无论采用何种等值方法, 两种分布下B 值的等值系数标准误均高于A 值的等值系数标准误。
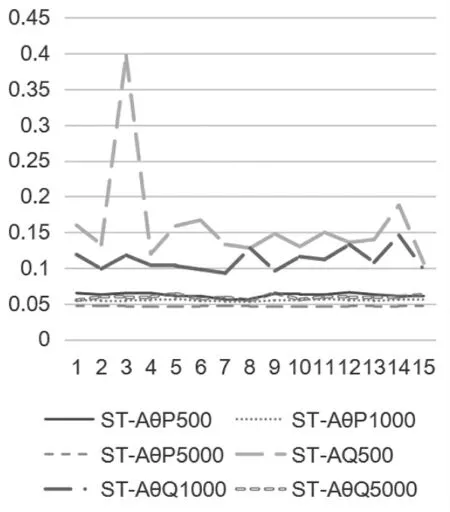
图3 Stocking-Lord 法下等值系数A 的标准误
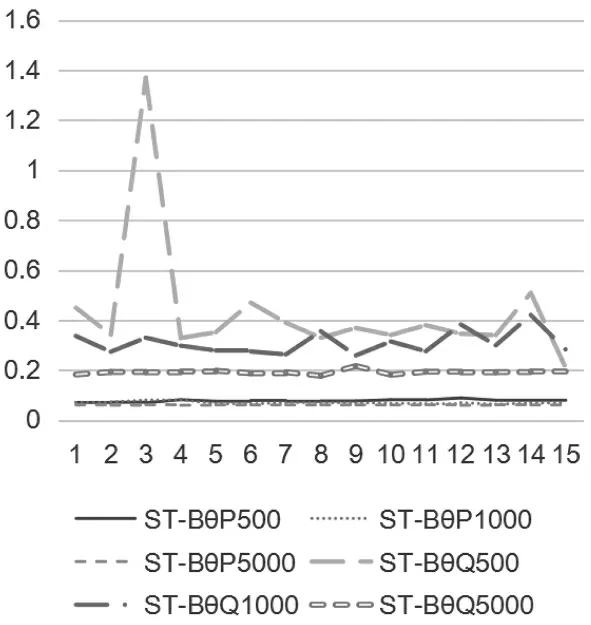
图4 Stocking-Lord 法下等值系数B 的标准误

图5 Haebara 法下等值系数A 的标准误

图6 Haebara 法下等值系数B 的标准误

图7 Stocking-Lord 法与Haebara 法的等值系数标准误差异
图7 为Stocking-Lord 法下的等值系数标准误与Haebara 法下的等值系数标准误之间的差异。图7 及表2 表明,Stocking-Lord 法下A 系数的标准误明显低于Haebara 法,但P 分布下B 系数的标准误略高于Haebara 方法; 在Q 分布下,Haebara 法中A 值与B值的标准误分别约为Stocking-Lord 法中A 值与B值标准误的1.5-2 倍。
(三)共同题稳定性
共同题参数稳定性是项目反应理论(IRT)分别估计方法下独有的等值结果判断标准。 不同组考生均作答共同题,会产生不同的作答反应,但是经过分别估计等值后, 理论上等值后的题目参数应该与基准卷上的题目参数是一致的。 但是受到等值误差的影响, 等值后的题目参数与基准卷上的题目参数往往不一致,题目参数之间会存在一定的差异。题目参数之间的差异用均方根偏差(Root Mean Square Deviation,RMSD)来计算,计算公式如下:

其中m 为共同题题目数量,xi为基准卷的共同题题目参数,xi' 为等值后的题目参数。 Sevilay Kilmen & Nukhet Demirtasli (2012) 研 究 中 采 用RMSD 值评价等值结果[13],RMSD 值越小,等值结果越好。
表3 为共同题参数稳定性的RMSD 值。 由表3可知,当分布一定、被试量确定时,Stocking-Lord 法下的共同题难度参数的RMSD 值小于Haebara 法;区分度参数的RMSD 值则稍有不同:P 分布下区分度的RMSD 值波动较小,难度的RMSD 值变化稍大;Q 分布下难度的RMSD 值变化较大, 不同样本量间RMSD 变 化 幅 度 在0.078 (1.598-1.520=0.078)到0.562(4.340-3.778=0.562)之间。当分布一定、等值方法确定时, 共同题参数的RMSD 值均随被试量的增加而降低。P 分布中的RMSD 值较Q 分布更为平稳;Q 分布中的RMSD 值变化较大,Haebara 难度平均值最大降低了2.742(4.340-1.598=2.742)。 当被试量一定、 等值方法确定时,P 分布中共同题难度参数的RMSD 值远低于Q 分布, 区分度参数的RMSD 值稍低于Q 分布。
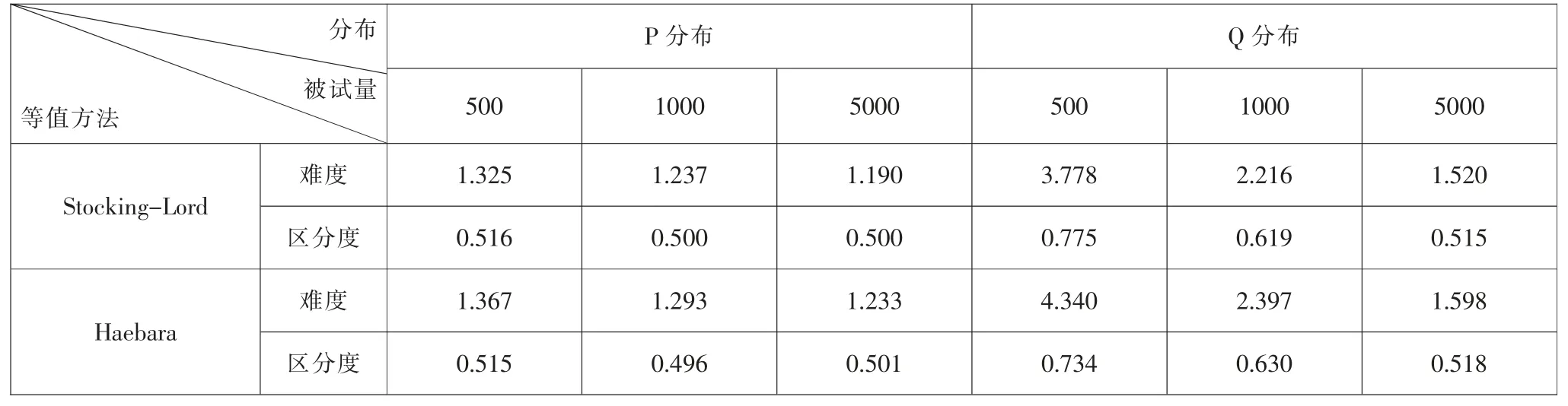
表3 共同题参数的RMSD 值
四、结论
首先,考生能力分布差异较大将显著影响等值的准确性。 待等值试卷上的考生能力分布与基准卷上的考生能力分布越接近,等值分数的标准误越小,等值系数的标准误越小,共同题参数越稳定。如果两组考生能力差别过大,会严重影响等值结果的精度。
另外,增加被试量可以降低等值误差,但是如果两组考生能力分布差异过大,此时,即使大量增加被试量也不能有效降低等值误差。 如果两组考生能力分布非常接近, 则只需较少的被试就可以得到较为准确的等值结果。
此外,不同的等值方法带来不同的等值误差。当两组考生能力分布一致时, 在等值系数B 的标准误以及区分度参数的稳定性方面,Haebara 方法表现略好。 但是,整体来看,Stocking-Lord 法较Haebara 方法更为稳定,误差更小。
因此,在实际等值操作中,不能仅关注采用增加被试量来降低等值误差的方法, 考生能力分布同样值得重视。在题库建设的等值过程中,如果发现两组考生能力差异过大, 为获得更加准确的入库题目参数, 建议在待等值试卷中抽取一个与基准卷被试分布相似的被试样本,再与基准卷进行等值,以有效降低等值误差。
五、研究中的不足
本研究仅基于正态能力分布下的两种考生能力分布情况,针对考生能力分布对等值精度的影响进行探讨,其他情况未加以讨论。 此外,在Q 分布下,Haebara 法中A 值与B 值的标准误分别约为Stocking-Lord 法中A 值与B 值标准误的近1.5-2倍, 这一结果在本研究的不同被试量下均适用,但是在其他情况下是否适用这一结论仍需要进一步讨论研究。
