A new model for predicting the total tree height for stems cut-to-length by harvesters in Pinus radiata plantations
2021-01-11ChenxiShanHuiquanBiDuncanWattYunLiMartinStrandgardMohammadRezaGhaffariyan
Chenxi Shan · Huiquan Bi · Duncan Watt · Yun Li ·Martin Strandgard · Mohammad Reza Ghaffariyan
Abstract A new model for predicting the total tree height for harvested stems from cut-to-length (CTL) harvester data was constructed for Pinus radiata (D.Don) following a conceptual analysis of relative stem prof iles, comparisons of candidate models forms and extensive selections of predictor variables. Stem prof iles of more than 3000 trees in a taper data set were each processed 6 times through simulated log cutting to generate the data required for this purpose. The CTL simulations not only mimicked but also covered the full range of cutting patterns of nearly 0.45 × 10 6 stems harvested during both thinning and harvesting operations. The single-equation model was estimated through the multipleequation generalized method of moments estimator to obtain efficient and consistent parameter estimates in the presence of error correlation and heteroscedasticity that were inherent to the systematic structure of the data. The predictive performances of our new model in its linear and nonlinear form were evaluated through a leave-one-tree-out cross validation process and compared against that of the only such existing model. The evaluations and comparisons were made through benchmarking statistics both globally over the entire data space and locally within specific subdivisions of the data space. These statistics indicated that the nonlinear form of our model was the best and its linear form ranked second.The prediction accuracy of our nonlinear model improved when the total log length represented more than 20% of the total tree height. The poorer performance of the existing model was partly attributed to the high degree of multicollinearity among its predictor variables, which led to highly variable and unstable parameter estimates. Our new model will facilitate and widen the utilization of harvester data far beyond the current limited use for monitoring and reporting log productions in P. radiata plantations. It will also facilitate the estimation of bark thickness and help make harvester data a potential source of taper data to reduce the intensity and cost of the conventional destructive taper sampling in the field. Although developed for P. radiata, the mathematical form of our new model will be applicable to other tree species for which CTL harvester data are routinely captured during thinning and harvesting operations.
Keywords Stem prof iles · Cut-to-length simulations ·Harvester data · Model construction · Nonlinear multipleequation GMM estimation · Benchmarking prediction accuracy
Introduction
Over the last 40 years, cut-to-length (CTL) harvesters have been increasingly adopted and widely utilised to improve log-harvesting productivity in natural and plantation forests worldwide (e.g., Huyler and LeDoux 1999; Murphy 2003; Gerasimov et al. 2012, 2013; Strandgard et al. 2013;Olivera et al. 2016; Williams and Ackerman 2016; Lu et al. 2018). The widespread utilization has been largely driven by great technological advances in the mechanical design of harvesters and in the harvester head measurement and optimization systems over the same period(Heinimann 2007; Nordセ ell et al. 2010; Uusitalo 2010;Malinen et al. 2016). Now modern harvesters equipped with a GPS receiver and a computerized harvester head have become a major source of “big data” for forest management as they constantly capture, accrue and provide a daily flow of spatially explicit and time-stamped data on log production and assortment as well as detailed diameter measurements of harvested stems of individual trees over large operational areas (Sellén 2016; Uusitalo 2017; Lu et al. 2018; Müller et al. 2019; Rossit et al. 2019). Harvester data can provide the total log length but not the total height of individual trees because the top crown section beyond the last cut does not pass through the harvester head and therefore its length cannot be measured. The lack of tree height data represents a stumbling block in the full integration of spatially explicit harvester data with conventional inventory data, remote sensing imagery and LiDAR data for the development of harvester-based inventory systems (e.g., Stendahl and Dahlin 2002; Murphy et al. 2006; Holopainen et al. 2010), for predicting attributes of individual trees, stands and forests (e.g., Rasinmäki and Melkas 2005; Holmgren et al. 2012; Söderberg 2015;Saukkola et al. 2019) and for estimating product recovery (e.g., Peuhkurinen et al. 2008; Barth and Holmgren 2013; Barth et al. 2015; Caccamo et al. 2018; Hauglin et al. 2018). Full integration will provide forest managers with a more detailed view of standing trees over an entire forest area and also allow them to predict spatially the volume and value of a certain product or a product mix that the forest can yield for optimising value recovery in management planning (Hauglin et al. 2018; Lu et al. 2018).Without full data integration, maximum value extraction from harvester data cannot be attained, preventing the transformation of big data into valuable data for forest management (see Müller et al. 2019).
For the most effective use of harvester data, a necessary first step is to estimate the total height of each harvested tree that was bucked, measured and recorded by the harvester head. This necessity has been well recognised, and several attempts to do so have been made in the estimation oflogging residue biomass and in the integration of harvester data with remote sensing data in forest inventory for predicting tree and stand attributes and estimating product recoveries (Varjo 1995; Kiljunen 2002; Maltamo et al.2010; Möller et al. 2011; Söderberg 2015; Siipilehto et al.2016; Hauglin et al. 2018; Lu et al. 2018). So far, total tree height has been calculated by estimating the length of the unprocessed top section of individual trees using the only such existing model, that of Varjo (1995), or through an iterative search algorithm using a taper equation as demonstrated well by Lu et al. (2018) and also briefly alluded to by Hauglin et al. (2018). Another ad hoc method was described by Kiljunen (2002), but it cannot be readily applied because of its requirement for diameter measurements at specific heights that are not routinely captured and stored in a harvester database.
Although proved useful in reconstructing individual trees from harvester data (e.g., Palander et al. 2009; Vesa and Palander 2010; Siipilehto et al. 2016), the only such existing model has a rather restricted range of application, only to stems with the small end diameter underbark of the top log between 5 and 10 cm and over a minimum log length of 1.5 m as outlined by Varjo (1995) for the 3 coniferous and broadleaf species in his study. The iterative search algorithm demonstrated by Lu et al. (2018)requires a taper equation and 2 extreme quantile curves that def ine the search range of total tree height at any given diameter at breast height overbark (DBH) for the species at interest. In comparison to a single predictive equation,it requires a large amount of auxiliary height and diameter data, is somewhat cumbersome to implement in a computer program and also takes longer to reach the optimal estimate. Even after the optimum is reached, it may still be less accurate than the prediction from a single equation as shown by Lu et al. (2018). This approach also relies on extensive bucking simulation through a large taper data set for accuracy testing. Without doing so, the accuracy of tree height estimation cannot be ascertained as in the case of Hauglin et al. (2018).
The weaknesses of these 2 methods highlight the need for an improved and more efficient approach to predict total tree height of individual stems cut-to-length by harvesters.The recent work of Lu et al. (2018) with Pinus radiata represented an essential first step towards satisfying this need.Building upon this work, this paper presents a new model that overcomes the weaknesses of the 2 methods that are currently in use, also using plantation trees of P. radiata as an example.
Materials and methods
Notation

A schematic diagram of the notation was drawn to aid understanding by readers (Fig. 1).

Fig. 1 Diagram illustrating a stem prof ile cut into 4 logs. Log end diameters (red dots) were derived from the prof ile that was interpolated from overbark taper measurements (black dots) using piecewise cubic Hermite interpolating polynomials (PCHIP). See the “ Notation” section for symbols in the diagram
Data
For the purpose of this study, it would be ideal if the total tree height and stump height of a large enough sample of harvested trees were measured and recorded in addition to log lengths and diameters in the field during harvesting as Lang et al. (2010) did for a small number of sample trees.However, measuring a large number of sample trees across different stand types, site, and age classes is costly and timeconsuming, particularly when working with harvesters in field operations amid safety concerns. To overcome the lack of such ideal data, this study followed the intuitive approach of Lu et al. (2018) in combining taper and harvester data through simulated log-cutting to generate a data set that not only included stump height and total tree height, but also mimicked the cutting patterns of harvesters in operational thinning and harvesting.
Taper data
The taper data set contained 3251 trees sampled from P. radiata stands across the State of New South Wales(NSW) in Australia over 30 years. These taper trees were sampled from both thinned and unthinned stands over wide ranges of age, site quality, and stand conditions. The lowest measurements of both overbark and underbark diameter were taken at between 0.1 and 0.3 m above ground, then another measurement was usually taken at 0.7 m before reaching the def ined breast height of 1.3 m. Measurement intervals above breast height varied between 1.5 and 3 m depending on the height of the sample trees. This data set was previously used by Bi and Long (2001), Bi et al.(2012) and Zhang et al. (2015) for developing taper equations, height-diameter functions and conversion factors for DBH measured at different breast height. It was also used by Lu et al. (2018) in combination with harvester data in log-cutting simulations. These publications provided a detailed textual and graphical description of this data set,so it was not repeated here. For the log-cutting simulation in this study, 152 trees were excluded, including 66 small trees with DBH less than 10 cm that fell below the minimum size for log-cutting and 86 trees that had underbark but not overbark taper measurements. The remaining 3099 trees in the taper data set had a range of 10-79.1 cm for DBH and 6.4-44.5 m for total tree height. For each tree,a complete stem prof ile from ground to the tip was constructed numerically by interpolating through its observed values of DOB using piecewise cubic Hermite interpolating polynomials (PCHIP) with an even interval of 0.1 m.
Harvester data
The harvester data came from the Tumut Management Area of the Snowy Region, Forestry Corporation of NSW(FCNSW). Covering the foothills of the Snowy Mountains,this management area has about 90,000 ha of P. radiata plantations, representing approximately 46% of FCNSW’s total P. radiata estate, and produces over 1 × 10 6 cubic meters of sawlogs and more than 0.6 × 10 6 cubic meters of pulp wood annually. These plantations were established with an initial stocking of 1000-1100 trees ha −1 across all site classes under the stand density management regime adopted for P. radiata in NSW since the 1980s (Horne and Robinson 1988). At the present regime, either one or two thinnings are prescribed for more productive sites. The first thinning aims to bring the stocking down to 450-550 trees ha −1 at around 14 years of age, and the second thinning further reduces the stocking down to 200-300 trees ha −1 at around 23 years of age. For poorer sites, no thinning is carried out before the final harvest generally at the age of 30-35 years.
The harvester data contained a total of 0.502 × 10 6 stems/trees that were harvested and processed by 20 CTL harvesters in routine thinning and clear-felling operations at 54 sites over a period of 3 years from 2012 to 2014. Each stem was cut into one or more logs that were numbered sequentially from the butt log to the top log, making up a total of 1.808 × 10 6 logs including approximately 0.240 × 10 6 waste sections in the data set. For each stem, stump height and stump diameter, i.e. LED of the butt log, were not available.For each log, the length, overbark volume and SED were recorded together with a product description that contained customer identification and product type. For logs without a specific customer and product type, production description was recorded as “random”. The cutting patterns were driven by the sawlog and pulpwood specifications of the local softwood industry consisting of one large 0.7 million tonne pulp and paper mill producing high quality kraft paper for both domestic and international markets and six large and small timber and wood products companies near the town of Tumut in southern NSW.
Data screening and interactive exploratory data analysis
With the aid of the statistical software R 3.5.1 (R Foundation for Statistical Computing, Vienna, Austria) and GGobi 2.1.10, an open source visualization program for exploring high-dimensional data (see Swayne et al. 2006; Cook et al.2007), multiple rounds of data screening and interactive exploratory data analysis were carried out through a systematic set of procedures to detect inconsistencies in data recording, erroneous or illogical records in the harvester data. Some obvious errors were corrected wherever possible,others errors or anomalies that could not be corrected were removed from the data set. To facilitate this process, DBH was calculated for each stem from the length and SED of its butt log using a system of conversion equations together with linear interpolation as in Lu et al. (2018). In addition,the merchantable height up to 5 cm DOB of trees in the taper data set was analysed in relation to their DBH to obtain an extreme nonlinear conditional quantile curve in the form of the 3-parameter Chapman-Richards function, one of the most commonly used functions for tree height and diameter models (see Huang et al. 1992; Huang 1999; Bi et al. 2000,2012):
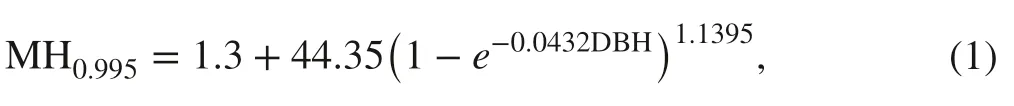
where MH0.995represents the 0.995th nonlinear conditional quantile of merchantable height in meters for a given DBH. The 3 parameters in Eq. 1 were estimated using the R package for quantile regression, quantreg (Koenker 2017,2018). This extreme quantile curve depicted the relationship between the maximum attainable merchantable height and DBH for P. radiata in NSW (Fig. 2). Through this equation,a maximum attainable total log length (Lmax) for any given DBH was def ined as MHq=0.995minus 0.15 m, the average stump height. This relationship between Lmax and DBH was then used as an upper frontier in the detection of anomalous stems.
After the completion of data screening and filtering, there were 0.448 × 10 6 stems and 1.581 × 10 6 logs remaining in the final data set. The DBH of these stems ranged from 10 to 82 cm with an average of 33 cm and their total log length L varied within the range of 2.2-40.8 m with an average of 16.6 m (Fig. 2). The minimum L of 2.2 m represented cases where only one short log was cut from a stem. The SED of the 1.581 × 10 6 logs varied from 3 to 80 cm, where values larger than 60 cm were found only in 0.3% of the logs. The individual log length ranged from 2.2 to 26.4 m, but lengths longer than 6.4 and 12 m represented less than 0.50% and less than 0.01% of the logs, respectively (Fig. 3). Because the logs were numbered sequentially from the butt log up,the number oflogs decreased as log number (i.e., the relative position oflogs) increased. Concomitantly, the SED and length oflogs varied both within and across log numbers,with the distribution oflog length peaking around a number of specified log lengths (Fig. 4). This final data set was used for deriving cutting patterns for the simulated bucking of the stem prof iles of taper trees.
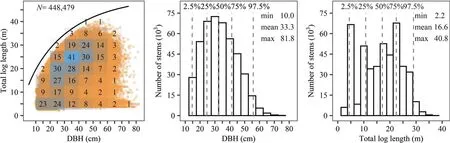
Fig. 2 Total log length (L) in relation to DBH under the curve of the maximum attainable merchantable height def ined by Eq. 1 for the 0.448 × 10 6 stems drawn on the left as clustered heatmaps using the R package Pheatmap (pretty heatmaps). The numbers in the grid cells indicate the number of stems in thousands. The corresponding frequency distributions of DBH (center) and L (right) are shown with percentiles and descriptive statistics

Fig. 3 Boxplots of SED (left) and log length (right) across the sequential log numbers for the 1.58 × 10 6 logs (including waste sections) cut-to-length from the 0.448 × 10 6 stems contained in the screened harvester data set. The numbers in the middle vertical stripe indicate the number oflogs across the sequence. The boxplots in the top horizontal stripe are for all the logs combined
Cut-to-length(CTL) simulations and data generation
Because of its larger volume, the harvester data showed an extremely wide spread in the value of SEDTL at any given DBH, which meant that there could be multiple alternative cutting patterns for a single stem, resulting in many SEDTL values and corresponding total log lengths. To have a more comprehensive representation of such variation in the cutting simulations, SEDTL was plotted against DBH for the 0.448 × 10 6 stems, and the data cloud was visually inspectedthrough the interactive and dynamic graphical display of GGobi. Then 6 nonparametric conditional quantile curves at τ = 0.01, 0.25, 0.50, 0.75, 0.90 and 0.99 were drawn through the data cloud using the QUANTREG procedure in SAS 9.4(SAS Institute, Cary, NC, USA) to help discern the patterns of conditional variation in SEDTL as DBH increased. Based on the patterns of the 6 nonparametric quantile curves, a parametric model was specified to derive the corresponding parametric conditional quantile curves:

Fig. 4 Scatter plots oflog length and SED as an extension of Fig. 3. The sequential log number is shown in the top stripe of each panel. Blue points represent logs tagged with a product code; brown points are either waste sections or random logs that were not tagged with any product type. The number oflogs in each of the 2 log categories is indicated in each panel by the string colored in the same scheme starting with P for product or W for waste

where SEDTLτis the τ th conditional quantile for a given DBH, aτ, bτand cτare the corresponding quantile-dependent parameters. Necessary constraints were placed upon parameter aτduring quantile regression to prevent the fitted quantile curves from crossing each other in the close neighbourhood of the minimum DBH of 10 cm. In addition, parameter cτwas set to 1 for the 90th and 99th quantiles as the relationship between SEDTLτand DBH became linear nearing the boundary of the data cloud (Fig. 5). For a taper tree with a given DBH in the log cutting simulations, these 6 parametric quantile curves provided 6 consecutive and increasingly large initial SEDTL values that not only well covered the range of SEDTL variations contained in the harvester data,but also led to 6 systematic and interrelated cutting patterns with 6 different total log lengths ranging from the longest to the shortest that the tree could possibly yield.
The log cutting simulation for each of the 3099 taper trees looped through 6 values of SEDTLτstarting from τ=0.01 and ending at τ=0.99 . Within each loop, the simulation went through the following steps: (1) obtaining a value of SEDTLτfrom its DBH and the τ th conditional quantile curve as shown in Fig. 5; (2) deriving the corresponding total log length L by searching through its stem prof ile from an average stump height of 0.15 m upwards to the height where the DOB was equal to SEDTLτ; (3) from among the 0.448 × 10 6 stems contained in the harvester data set selecting the stem that was most similar to the taper tree by using a similarity index SI as described below; (4) using the cutting pattern of the most similar stem to locate the sequential cross-cut points on the taper tree’s stem prof ile with some adjustment if necessary; (5) taking the DOB and height at each cutting point on the numerically interpolated stem prof ile; (6) exporting the values of stump height, log number,log length, LED and SED values, and Ltop, the length of the tree top section from the last cutting point to the tip to a storage data set. The computer program previously written by Lu et al. (2018) in C# was modified to carry out all steps of the CTL simulations. The final data set contained 6 different but correlated values of SEDTL , L and Ltopfor each taper tree with the same DBH, total tree height H and stump height Hs.

Fig. 5 Small end diameter of the top log (SEDTL) plotted against DBH for the 0.448 × 10 6 stems in clustered heatmaps using the R package Pheatmap. The numbers in the grid cells indicate the number of stems in thousands. Overlaid on top of the heatmaps are 6 conditional quantile curves, each with a number on its right end to indicate the value of the τ th quantile. The curves are def ined by Eq. 2 and by the parameters for the 6 quantiles shown in the top left corner of the graph
The similarity index (SI) in step 3 was calculated as the distance between the candidate stem and the subject taper tree in a 3-dimentional space as follows:
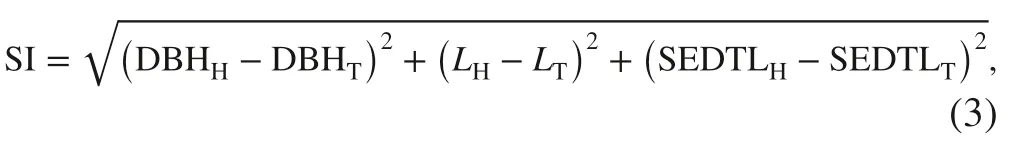
where variables with the subscript H and T denote the attributes of candidate stem from the harvester data and that of the subject taper tree, respectively. The value of SI is zero when the candidate stem and the subject taper tree are identical in the 3 dimensions. The SI values for the 3099 × 6 most similar stems selected in the log cutting simulations had an L-shaped distribution over a range from 0 to 7.9, with a median of 0.25, a mean of 0.40 and an upper quartile of 0.47.About 91% of the SI values were between 0 and 1 (Fig. 6).

Fig. 6 Frequency distribution of similarity index (SI) for the most similar trees selected from among the 0.448 × 10 6 trees for the 3099 × 6 CTL simulations. The colored bar segments for the τ th conditional quantiles represented the cutting patterns derived from the 6 corresponding curves in Fig. 5. Characteristic percentiles are shown together with summary statistics of the distribution where the number of trees with SI greater or equal to 2 was 100 only
Model derivation
In deriving a model specification for predicting total tree height H , L was considered as a fraction of H as shown in the “ Notation” section. In doing so, any given height along a tree stem above breast height was converted to relative height h and thus h varied from 0 at 1.3 m to 1 at the tip of the tree. At the same time, the DOB at a relative height h was converted to relative diameter d , which varied from 1 at 1.3 m to 0 at the tip of the tree. Considering the relative stem prof ile of the part of the stem above breast height and taking reference of the idea and approach of Bi (2000) in the construction of the trigonometric variable-form taper model,h was expressed as a power function of d and other variables:

where the base B is a monotonic function of relative diameter d, varying from 0 to 1 as d changes from 1 to 0, and K is a variable exponent. Nine candidate base functions were constructed, including both linear and trigonometric functions, to approximate the geometrical shape of the relative stem prof ile through Eq. 4. Because there was no clear geometrical form, biological reason or statistical theory to specify a particular equation form for the variable exponent,K , an empirical function for K had to be derived through exploratory model building. Variables including DBH, L, d,average stem taper T , and their various transformations and combinations were taken as candidate predictors for K in a linear function. For each of the 9 candidate base functions,Eq. 4 was linearized by taking logarithmic transformation of both sides and then ln h was regressed against all candidate predictors, each multiplied by ln B, but without the intercept term. The best model with either 4 or 5 predictors for K was determined through stepwise regression in the PROC REG procedure of SAS 9.4 with MAXR (maximum R 2 improvement) as the method of variable selection.
The selected models for all 9 candidate base functions were then further compared with each other in terms of the goodness-of-f it statistics and also subjectively evaluated in terms of their simplicity, elegance, interpretability and applicability. Following this exploratory model building process,the linear model for ln h was specified as follows:
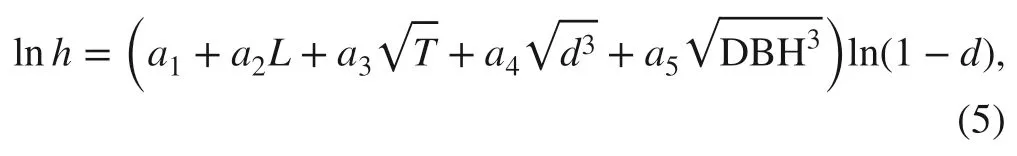
where a 1 to a 5 are parameters. This linear model was backtransformed from natural logarithm to derive the nonlinear model form for h:


Although the deterministic structures of Eqs. 5- 7 are mathematically equivalent, as statistical models for predicting total tree height, they differ. The differences in their dependent variables and error structures (either multiplicative or additive) could potentially have some impact on the prediction accuracy for H.
Parameter estimation oflinear and nonlinear models
Equations 5 and 7 could be estimated through linear and nonlinear least squares regression with the implicit assumption that the error term was an independent and identically distributed random variable. However, this assumption was unrealistic as revealed by the diagnostic analyses of residuals from the regressions. First, the CTL simulations processed each taper tree 6 times using 6 values of SEDTLτobtained from the 6 conditional quantile curves at τ=0.01 ,0.25, 0.50, 0.75, 0.90 and 0.99 (Eq. 2, Fig. 5) and generated 6 sets of values of all variables appearing in Eqs. 5 and 7.Consequently, there was an inherent correlation among the residuals from the same tree. Second, the 6 values of L for each taper tree represented different proportions of its total tree height H . As L decreased and SEDTLτincreased with τ, the magnitude of residual variation became increasingly larger, providing a clear indication of the presence of residual heteroskedasticity, particularly for the nonlinear model.
Although the least squares estimators remain unbiased in the presence of residual correlation and heteroskedasticity,they are no longer efficient and their estimates of parameter variances are biased (Gujarati and Porter 2010; Greene 2012).To take both residual correlation and heteroskedasticity into consideration, Eqs. 5 and 7 were not estimated as single equations, but each as a system of 6 equations. For the sake of parsimony, the model specification for estimating Eq. 7 only was given below:

where H1toH6represent the same H as in Eq. 7, but corresponding to data generated from the 6 cutting patterns that were based on the 6 conditional quantile curves at τ=0.01 ,0.25, 0.50, 0.75, 0.90 and 0.99 (Fig. 5), f(X,θ) stands for the nonlinear function in Eq. 7 with X representing a vector of its predictor variables and θ a vector of its 5 parameters,ε1to ε6are the corresponding error terms. The 6 error terms can be expressed in the matrix algebra notation as follows:

The properties of ε are

where E(ε) and Cov(ε) denote the expectation and covariance of ε , σiirepresents the variance of εi(i = 1,…, 6), σijrepresents the covariance between the error term of theith and the j th equation, (j=1,…,6),⊗ denotes the Kronecker product, N=3099, denotes the number of observations and INis an identity matrix of order N . The system of Eq. 8 was fitted to the data generated from the CTL simulations using the generalised method of moments (GMM) through the MODEL procedure of SAS/ETS with the Marquart method of minimization. The multiple-equation GMM estimator produces efficient parameter estimates under heteroscedastic conditions without any specification of the nature of the heteroscedasticity (Hayashi 2000; Greene 2012). This approach turned the residual correlation in the single-equation regression (7) into the cross-equation error correlation in the system of Eq. 8, which was then characterized by the variance and covariance matrix ∑ in Eq. 11 and taken into account in parameter estimation. At the same time, it also avoided the difficulty and complexity in deriving an accurate residual skedastic function conditional upon DBH, L , SEDTL across the 6 log cutting patterns to serve as a weighting function within the frame work of generalized least squares estimation of a single equation. As the same parameter vector θ was shared across the 6 system equations, this approach effectively estimated a single equation model in Eq. 7.
Evaluating and comparing prediction accuracy
To evaluate and compare their predictive performances of Eqs. 5 and 7, a leave-one-tree-out cross-validation approach was adopted to obtain prediction errors from and for trees that were independent of the model building process. In doing so, the system of 6 equations specified for each single equation model was fitted 3099 times. Each time, 6 observations from a single tree were left out from the fitting process.Then the parameter estimates based on data from the remaining 3098 trees were used to compute the corresponding 6 prediction errors for the left-out tree as follows:

The linear and nonlinear models in Eqs. 5 and 7 were further compared with the model of Varjo (1995) in its original linear form:and also in its nonlinear form after back-transformation from log scale:


Parameters of these 2 single-equation models were also estimated through the system of equations approach as described above. Then prediction errors for each model were generated through the repeated model fitting and testing process following the leave-one-tree-out cross validation approach as previously described.
The prediction accuracy of our model was evaluated and compared with that of Varjo’s in both their linear and nonlinear forms graphically and through benchmarking statistics. Scatter plots of the observed values of H against their predicted values with a line of unity slope passing through the origin were evaluated together with prediction error distributions. The benchmarking statistics included the mean error of prediction(MEP), the relative mean error of prediction (RMEP), the mean absolute error of prediction (MAEP), the mean squared error of prediction (MSEP), and the prediction coefficient of determinationThese statistics have been commonly used in evaluating the predictive performance of forest models as they assess the size, direction and dispersion of the prediction error as reviewed by Huang et al. (2003). In particular, the MSEP is the measure of prediction accuracy commonly used in the statistical literature since it incorporates both the variance of prediction error and the bias of prediction (Wackerly et al. 1996). In addition to these statistics, skewness and kurtosis (calculated as the excess kurtosis, which is 3 less than the standardized fourth central moment) were also obtained for prediction error distributions.
These benchmarking statistics were calculated both globally over the entire data space and locally over specific subspaces of data. A natural example of such subspace division lay in the data generated by the 6 cutting patterns and represented by the 6 system equations. For theith system equation, the 4 benchmarking statistics were calculated as follows:
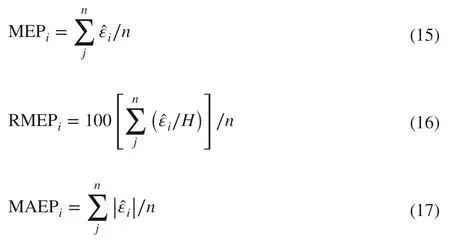

where i=1,…,6 , n=3099, i.e., the total number of taper trees, j indicates the j th tree, Hjis its total tree height andis the average height of all n trees. As the 6 cutting patterns represented by the 6 system equations did not have an equal frequency of occurrence, an overall weighted average mean squared error of prediction (WMSEP) was calculated as follows:

where wi= 0.130, 0.245, 0.250, 0.200, 0.120, 0.055 for i=1,…,6 . These weights were the approximate proportions that the 6 quantiles, τ=0.01 , 0.25, 0.50, 0.75, 0.90 and 0.99, represented over the range from 0 to 1, which were determined by evenly partitioning the distance between any 2 adjacent quantiles and allocating one-half to each quantile.Although analogous to the coefficient of determination R 2 ,which ranges from 0 to 1,can range from − ∞ to 1 (Nash and Sutcliffe 1970). Whenthe observed mean is a better predictor than the model as the variance of prediction error is larger than the variance of the observed data.
The 6 cutting patterns in the log cutting simulations also generated, as intended, a wide range of d values from 0.07 to 0.97, covering 90% of its theoretically def ined interval between 0 and 1. The range of d was therefore divided into 10 even intervals with a width of 0.1, except for the first and last interval, for a further local evaluation and comparison of prediction accuracy. In addition, 3 other subdivisions of data were assessed for the same purpose. First, the height and diameter data of 3099 trees were divided into 6 size classes according to their DBH and H . The 0.50th nonlinear height-diameter quantile curve in the form of the Chapman-Richards equation was obtained by using the R package, quantreg. This median curve divided the 3099 trees into 2 halves, i.e., relative taller and shorter trees for a given DBH (Fig. 7). Then the trees in each half were further divided into 3 DBH classes using 30 and 50 cm as points of division, resulting in 6 size classes in total. Second, a ratio of total log length ratio (Rl) was calculated by dividing L with H for each tree through the 3099 × 6 cutting simulations. Then the entire range of Rlwas divided into 9 even intervals with a width of 0.1. Third, the data were divided into 9 groups according to the total number oflogs cut from each stem which ranged from 1 to 9 or more.

Fig. 7 Total tree height (H)plotted against DBH for the 3099 trees in the taper data set. For local evaluations of prediction accuracy, the entire data space was divided into 6 subspaces marked with Roman numerals. The division was achieved by the median height and diameter curve, for which the equation was plotted on the graph with the 2 vertical lines at DBH equal to 30 and 50 cm.The number next to each Roman numeral indicates the number of trees within that subspace
Results
The variance and covariance matrix ∑ as exemplified in Eq. 11 and used in the multiple-equation GMM parameter estimation was

for our model in its linear and nonlinear form respectively,and

for Varjo’s model in its linear and nonlinear form. The diagonal and off-diagonal elements of these matrices showed that error heteroskedasticity and correlation across the 6 cutting patterns were stronger for the nonlinear than the linear models. The values of all elements of ∑ for our nonlinear model in Eq. 7 were smaller than that for Varjo’s nonlinear model in Eq. 14, except for σ66. As expected, all elements of the matrices for the 2 linear models were much smaller than the corresponding elements of the matrices for the 2 nonlinear models due to logarithmic transformation. Although the dependent variable of our new model in its linear form in Eq. 5 was lnh (log-transformed relative height), some degree of heteroskedasticity was still evident as shown by the trend along the diagonal elements of the matrix. The parameters of our new model estimated in its nonlinear form in Eq. 7 differed slightly from that estimated in its linear form in Eq. 5. In comparison, such comparative differences were much larger for Varjo’s model (Table 1). The linear and nonlinear estimates of 3 parameters, a2, a3and a5in Eqs. 13 and 14 even had opposite signs. For both models,the parameters estimated through their nonlinear forms had appreciably smaller standard errors. The R2values, calculated according to Eq. 19 but using the observed and estimated values of H of all trees involved in model fitting, were slightly higher for our model in both linear and nonlinear forms than for Varjo’s.
The scatter plots of observed and predicted values of H and the corresponding distributions of prediction error generated from the leave-one-tree-out cross validation process showed little overall bias in the prediction of H for the 2 models in their linear as well as nonlinear forms(Fig. 8). The smallest MEP of 0.06 m was observed for our model in its nonlinear form, as compared with the MEP of 0.08 m for Varjo’s model also in its nonlinear form. The MEP of our model in its linear form was also smaller than that of Varjo’s model in its linear form. Our model in its nonlinear form also had the smallest value of MSEP of 6.47, as compared with its linear form and also with Varjo’s model in both forms. For both models, the nonlinear form had smaller values of MEP and MSEP than the linear form. The prediction error distributions had little skewness but pronounced kurtosis for the 2 models in both forms,but they were more leptokurtic for our model than Varjo’s(Fig. 8). These results were based on prediction errors for all 6 cutting patterns derived from using the 6 quantile curves that related SEDTL to DBH (Fig. 5). It was apparent from Fig. 8 that prediction errors for the cutting pattern derived from the 6th quantile curve at τ = 0.99 had a much wider spread than all other cutting patterns. When thepractically rare cases represented by this cutting pattern were excluded, MSEP became much smaller andhigher for the 2 models in both forms (Fig. 8). Our model in its nonlinear form still had the smallest MEP and MSEP among the 2 models and their different forms.

Fig. 8 Observed total tree height plotted against predicted values with a line of unity on the left for the linear and nonlinear forms of our new model (Eqs. 5, 7) and Varjo’s model (Eqs. 13, 14) that are labelled as NML, NMN, VML and VMN respectively in the shaded area on the far right. The corresponding distributions of prediction error are displayed on the right with characteristic percentiles and values of skewness and kurtosis. The color key is the same as in Fig. 6. The benchmarking statistics in the bottom right corner of the scatter plots were based on all 6 cutting patterns; those in the top left corner were for the first 5 cutting patterns only
When prediction accuracy was evaluated across the 6 cutting patterns individually, our model in its nonlinear form had smaller values of MSEP than its linear form with the exception of the 6th cutting pattern. However, the differences were small, representing a reduction mostly less than 2.6%. The weighted average of the 6 MSEP values showed even a smaller reduction of 1.2% (Table 2). Varjo’s model in its nonlinear form also had smaller values of MSEP than its linear form except for the first cutting pattern as its MSEP became twice as larger, pointing to a marked deterioration in predictive performance. No matter in what form our model was estimated, it had smaller MSEP values than Varjo’s model in both forms across the first 4 cutting patterns, with the first cutting pattern having the largest reduction of more than 50%. For the last 2 cutting patterns, the MSEP values of our model were either similar to or slightly larger than that of Varjo’s. The weighted average MSEP of our model represented about 20% reduction of that of Varjo’s model in its linear form and about 10-11% reduction in its nonlinear form(Table 2). For each model, the values of MSEP1−MSEP6in Table 2 corresponded almost exactly to the error variances σ11−σ66, i.e., the diagonal elements of its variance and covariance matrix. In addition to MSEP, the other 4 benchmarking statistics also indicated that our model outperformed Varjo’s in both linear and nonlinear forms. In the nonlinear form in particular, our model had smaller values of MEP, RMEP and MAEP higher values ofacross the 6 cutting patterns except for the last (Table 3).

Table 3 Values of MEP,R noMnlEinP e, aM r fAoErmP ao n f doimages/BZ_38_489_2489_531_2542.pngurnf eowr the model (NMN) in Eq. 7 and that of Varjo’s model (VMN)in Eq. 14 across the 6 cutting patterns derived from the τ th conditional quantile curves in Fig. 5 τMEP RMEP MAEP R2p NMN VMN NMN(%) VMN(%) NMN VMN NMN VMN 0.01 − 0.03 0.64 − 0.13 2.30 0.48 0.76 0.99 0.99 0.25 0.05 0.24 − 0.09 0.12 0.88 1.03 0.98 0.97 0.50 0.02 − 0.19 − 0.50 − 1.78 1.17 1.40 0.96 0.95 0.75 − 0.03 − 0.36 − 1.73 − 3.49 1.91 2.14 0.91 0.89 0.90 0.06 0.12 − 2.44 − 2.66 2.79 2.81 0.82 0.82 0.99 0.25 0.04 − 0.74 − 3.83 3.13 3.16 0.77 0.78 All 0.06 0.08 − 0.94 − 1.55 1.73 1.88 0.91 0.90
As the nonlinear form outperformed the linear form for both models, the comparative performances of the 2 models in further local evaluations of prediction accuracy were only reported for their nonlinear forms for the sake of parsimony.Across the 10 intervals of d , our model had smaller values of MEP, MAEP and MSEP and highervalues than Varjo’s over the first 7 intervals where d≤0.80 (Table 4). In the interval 0.80 The ratios displayed in parentheses in the third row were that of NMN over VMN in the corresponding statistics. N is the number of observations in each relative diameter class. The median, skewness and kurtosis of prediction error distribution presented in a single column were for our new model (NMN) only Across the 9 intervals of total log length ratio Rl, our model generally outperformed Varjo’s as indicated by the benchmarking statistics also based on prediction errors for the first 5 cutting patterns (Table 5). When Rl≤0.2, i.e., the total log length was less than or equal to 20% of total tree height, the values of MEP, MAEP and MSEP were much larger than that for all other intervals for both models and theirwas negative. In this first interval, our model did not perform as well as Varjo’s. When 0.20 The ratios displayed in parentheses in the third row were that of NMN over VMN in the corresponding statistics. N is the number of observations in each relative diameter class. The median, skewness and kurtosis of prediction error distribution presented in a single column were for our new model (NMN) only To our knowledge, this study represents the first rigorous attempt at developing a model for predicting total tree height from CTL harvester data. Based on the global benchmarking statistics in Table 2, the nonlinear form of our model in Eq. 7 ranked first and its linear form in Eq. 5 second, while the nonlinear form of Varjo’s model in Eq. 14 ranked third and its linear form in Eq. 13 last.The superior performance of our nonlinear model was also reflected by the values of the diagonal elements,σ11− σ66, of the variance and covariance matrices in the results section. Our nonlinear model also proved to be far superior than the iterative search algorithm using a taper equation, an existing ad hoc approach demonstrated by Lu et al. (2018) and used by Hauglin et al. (2018).The detailed comparative results formed part of the first author’s postgraduate work but were not presented in the present paper for the sake of parsimony and because the iterative search algorithm was already found by Lu et al.(2018) to be inferior to Varjo’s model in its original linear form in Eq. 14, the worst performing among the 4 equations reported in this study. The ratios displayed in parentheses in the third row were that of NMN over VMN in the corresponding statistics. N is the number of observations in each category. The minimum, mean and maximum total log length ratio (Rl) represented by logs in each category were presented in a single column from top down Although the best performer globally, our nonlinear model in Eq. 7 did not perform as well as Varjo’s nonlinear model in Eq. 14 in certain local areas of the data space.When d>0.90 , our model had larger MSEP and lowerthan Varjo’s (Table 4). Where total log length represented less than or equal to 20% of the total tree height, Eq. 7 did not perform as well as the nonlinear form of Varjo’s model. However, the cases with total log length ratio Rl≤0.20 only accounted for about 2% of the total number of simulated log cuttings (Table 5). Among the 0.448 × 10 6 stems contained in the screened and filtered harvester data set, such cases accounted for a small proportion of 4.9%approximately. This approximation was based on the values of R1calculated for individual stems using their predicted total tree height from our nonlinear model in Eq. 7.A posterior exploratory analysis showed that stems with Rl≤0.20 were trees with DBH from 10.2 to 81.8 cm, with a mean of 41.0 cm, an upper and lower quartile of 33.8 and 47.5 cm, and a 2.5th and 97.5th percentile of 23.1 and 63.6 cm, respectively. Besides stems with Rl≤0.20 ,another subspace of data where Eq. 7 did not perform as well as the nonlinear form of Varjo’s model was the larger slenderer trees with DBH greater than 50 cm and H above the median height-diameter curve as delineated in Fig. 7.These trees had a height and diameter ratio (HDR, i.e.,H∕DBH) ranging from 0.52 to 0.83 with an average of 0.68. Among the 0.448 million stems, such slender trees represented a small proportion of 3.5% and had HDR (i.e.,calculated as predicted H over DBH) from 0.56 to 1.13,with an average of 0.70. The poorer performance of our model for Rl≤0.20 and d≥0.90 reflected a structural weakness of our model. As def ined in the “ Notation” section, d takes any value between 0 and 1. When the value of SEDTL approaches DBH, d→1 and the base function of (1−d) tends to 0. A very small positive number with a positive exponent as formulated in Eq. 7 would result in a relatively large predicted value of H .Conversely, a positive exponent would lead to a relatively small predicted value of H . As a result, the variance of prediction error became much larger as shown by the large values of MSEP in Tables 4 and 5. Based on the benchmarking statistics for the local evaluations of prediction accuracy, the applicable range of our nonlinear model for P. radiata stems processed and recorded by CTL harvesters should be where values of Rl>0.20 and d<0.95 . For stems outside of this applicable range, total tree height could still be estimated but indirectly based on model estimates for trees within the applicable range and also within a user-def ined neighborhood or local area. Using the estimated H of these trees and their spatial co-ordinates recorded in the harvester data,stem-specific and spatially varying geographically weighted linear or nonlinear height-diameter equations could be derived for more accurate total tree height estimation for such stems following the approach of Zhang et al. (2003)and Caccamo et al. (2018). The approach of estimating the parameters of a singleequation model through the multiple-equation GMM estimator was adopted in this study specifically to obtain effi-cient and consistent parameter estimates in the presence of error correlation and heteroscedasticity that were inherent to the systematic structure of data generated by the CTL simulations. This approach proved to be better than all single-equation methods that were evaluated during model derivation and parameter estimation. Although the comparative results were not reported here, these single-equation methods for the log-transformed linear models included (1)least squares regression (LSQ), (2) repeated sampling and fitting through LSQ, each time using data from only 1 of the 6 cutting patterns randomly selected from each tree to avoid error autocorrelation, and (3) LSQ with discrete as well as continuous AR1 (f irst-order autoregressive) errors.For the nonlinear models, these single-equation methods included (1) nonlinear least squares regression (NLSQ), (2)weighted nonlinear least squares regression (WNLSQ) to overcome heteroscedasticity, (3) repeated sampling and fitting through WNLSQ to reduce heteroscedasticity and at the same time to avoid error autocorrelation, and (4) WNLSQ with both discrete and continuous AR1 errors. In addition,the generalized estimating equations (GEE) implemented in the SAS macro %NLMIX as described by Vonesh (2012)was also attempted, but the estimation was not successful because of difficulties in achieving convergence. All these single-equation methods were compared with the multipleequation GMM estimator and evaluated through the leave one-tree-out cross-validation process and the benchmarking statistics as described previously. The multiple-equation GMM estimator provided not only efficient and consistent parameter estimates in the presence of error correlation and heteroscedasticity in the structured data, but also the best predictive performance. The repeated sampling and fitting also exposed a structural weakness of Varjo’s model due to the high degree of multicollinearity among its predictor variables as indicated by the collinearity diagnostics during parameter estimation of its linear as well as nonlinear form. The variance inflation factor was either close to the commonly used benchmark of 10 or much greater than 10 for the predictor variables in the LSQ estimation of a single equation, while the condition index was greater than 110 and 220 in the linear and nonlinear multiple-equation GMM estimations, well above the commonly recognized threshold of 30 (Belsley 1991; Galmacci 1996; Alin 2010; Friendly and Kwan 2009). The high degree of multicollinearity led to highly variable and unstable parameter estimates. As a result, there tended to be either 1 or 2 estimated parameters that were not significantly different from zero as found during repeated sampling and fitting.A small change in the data could result in relatively large changes in parameter estimates, even to extent of switching signs. Therefore, it was not surprising to see (1) the linear and nonlinear estimates of some parameters having opposite signs as shown in Table 1 and (2) the comparatively large difference in the predictive performance between the linear and nonlinear forms of Varjo’s model (Table 2). Even for the same linear form, the model fitted by Lu et al. (2018) to data generated from a single cutting pattern based on a much smaller harvester data set had parameters of different signs to that estimated in this study. Although detailed comparative results were not reported here for the sake of parsimony,its predictive performance became much poorer when tested over the much larger data space in this study, reflecting the potential impact of multicollinearity on the predictive ability of the model beyond its original training data space where the nature and degree of multicollinearity differed. Such effects of multicollinearity in linear and nonlinear regression models have long been recognised (Belsley 1984, 1991; Galmacci 1996; Alin 2010; Erkoç et al. 2010). In comparison,our new model in both linear and nonlinear forms did not suffer from the same problem, the condition index was 28 and 23 in the linear and nonlinear multiple-equation GMM estimations, respectively, all below the benchmark value of 30. This relatively weak multicollinearity among predictor variables of our model would certainly contribute to its superior predictive performance. Interest has been growing in making a greater use of harvester data in forest management and planning among both researchers and managers over the last 10 years (Möller et al.2011; Olivera and Visser 2016; Roth 2016). Most recently,harvester data analytics has been identified to be essential for the successful transformation of big forestry data into valuable data for management and envisaged to be an integral and indispensable part in the generation of a virtual forest for subsequent digitization of the wood supply chain within the internet of trees and services in the future (Müller et al.2019). As shown by Möller et al. (2011), accurate estimation of total tree height for harvested stems represents a necessary basic step in harvester data analytics. Our new model for predicting total tree height will facilitate and widen the utilization of harvester data far beyond the current limited use in the management of radiata pine plantations, i.e., mostly for log production monitoring and reporting. It will enable the full integration of harvester data with conventional inventory data, remote sensing imagery and LiDAR data for the development of harvester-based inventory systems, for the prediction of attributes of individual trees, stands and forests, and for estimating product recovery and residue biomass in radiata pine plantations. It will also facilitate (1) the screening and exploratory analysis of harvester data, (2) calibration and estimation of bark thickness, (3) mapping of site index, (4) development site-specific height-diameter curves, and (5) post-thinning assessment of diameter and height distributions of retained versus removed stems. In addition, accurately estimated total tree height will make harvester data a potential source of taper data to supplement and possibly reduce the intensity and cost of the conventional destructive taper sampling in the field. This list is far from exhaustive. Many other applications of our model are expected to emerge as harvester data analytics become increasingly ref ined and sophisticated with further development. Although our new model was developed for radiata pine, its mathematical form will be applicable to other tree species in plantations as well as natural forests where CTL harvester data are routinely captured during thinning and harvesting operations. AcknowledgementsWe thank Mr. Mike Sutton of the Forestry Corporation of NSW for providing the data license to Beijing Forestry University for this collaborative work. We are indebted to the past and present forestry staffof the Forestry Commission of NSW, State Forests of NSW, Forests NSW, and the Forestry Corporation of NSW who collected the data in the field. Dr. Glen Murphy provided helpful comments on the manuscript. Open AccessThis article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source,provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creat iveco mmons.org/licen ses/by/4.0/.

Discussion

杂志排行

Journal of Forestry Research的其它文章
- A commentary review on the use of normalized difference vegetation index (NDVI) in the era of popular remote sensing
- Reconciliation of research on forest carbon sequestration and water conservation
- A theory to link relationships of stand volume, density, mean diameter and height in forestry data
- Comparative performances of new and existing indices of crown asymmetry: an evaluation using tall trees of Eucalyptus pilularis(Smith)
- Tree mortality and biomass loss in drought-affected forests of East Texas, USA
- A video camera recording method for measuring terminal velocity of seed dispersal by wind