基于多级表示网络的无参考立体图像质量评价
2021-01-08沈丽丽
沈丽丽,王 丹,徐 珂
(天津大学电气自动化与信息工程学院,天津 300072)
随着3D 成像技术和多媒体应用的飞速发展,越来越多的立体内容出现在日常生活中,如3D 电影、3D 游戏和3D 广告等.与平面图像相比,立体图像可以呈现出立体感和真实感,因此,如何客观准确地预测立体图像的感知质量比预测平面图像质量更具有挑战性.
早期的立体图像质量评价(SIQA)研究直接将成熟的2D 图像质量评估算法如SSIM[1]、MS-SSIM[2]应用于立体图像的单个视图,对其取平均值来表示立体图像的质量分数.这些方法没有考虑立体图像的感知特性,无法提供满意的评价效果.为了更好地模拟双目视觉特性,如双目融合、双目竞争和视差原理等,文献[3]将双眼质量预测简化为单眼特征编码和合并,预测立体图像的质量分数.文献[4]使用感知组合算法从失真立体图像中生成两种融合图用于质量分数预测.文献[5]从合成图和视差图中提取对比度、边缘和结构等信息预测立体图像质量分数.文献[6]引入双目特征和双目能量的概念,提出一种无参考立体图像质量评估方案.基于人类视觉系统,文献[7]使用AdaBoost 机器学习算法设计立体图像质量评估指标.以上方法都是将手工提取的特征输入到回归模型中预测立体图像的感知质量,然而,由于人类视觉系统的复杂性,设计特征需要大量的经验和知识,设计过程非常复杂.
近年来,卷积神经网络(CNN)在计算机视觉领域中得到广泛的应用.CNN 将原始图像用作输入,自动学习并完成分类、识别和预测等任务.然而,由于缺乏足够的具有主观质量分数的训练数据,CNN在图像质量评价领域的应用较为困难.为了解决这个问题,一些方法通过将图像的主观平均意见得分(DMOS)分配给图像中的所有小图像块来处理.例如,Kang 等[8]提出一个浅层框架,通过测试图像块的平均客观得分计算得到整张图像质量得分,在将CNN 用于图像质量评价的性能方面做了开创性的工作.随后,CNN 逐渐被应用在立体图像质量评价方面.文献[9]通过将多个卷积层和最大池化层堆叠在一起,学习了对人类感知较为敏感的局部结构.文献[10]通过两步回归对立体图像进行局部和全局特征聚合的监督训练.文献[11]设计一个Siamese 网络来提取左、右视图的高级语义特征.文献[12]通过在LIVE 2D 数据库中微调Caffenet[13]和GoogLeNet[14]提取反映图像质量的高质量特征.
人类视觉皮层具有复杂的层次结构.在立体视觉刺激过程中,双眼融合和视差响应最初在V1 皮质区域(即低级视觉区域)形成,经由V2 到V5 的高级皮质区域增强[15-17].基于以上观察,笔者在CNN 中加入表示立体图像深度信息的视差图,提出一种通用的多级表示网络用于SIQA.参考视觉系统的层次结构,将网络分为初级子网和高级子网两部分.在初级子网部分,将视差图的低级特征融合到右视图中形成视差交互通路;之后三通路的卷积神经网络合并为二通路,得到具有立体图像失真信息和双目信息的高级融合特征;最后高级子网提取融合特征图的深层信息,进一步模拟视觉系统中的立体成像过程.
1 图像预处理
视差图像不仅考虑了立体图像的视差/深度信息,还增加训练数据的特征数量,因此,将视差图加入到网络中,并采用小图像块的预处理方法.
1.1 视差图生成原理
视差图能够根据左、右图像进行三维重建,并提取立体图像的深度信息[18].本文采用基于结构相似性的立体算法(SSIM)提取视差信息[19].空间位置i的视差值计算公式为

式中:d 为左视图到右视图对应像素之间的差值;D=25,代表绝对差的最大值.函数s(·)由SSIM 指数计算,具体描述为
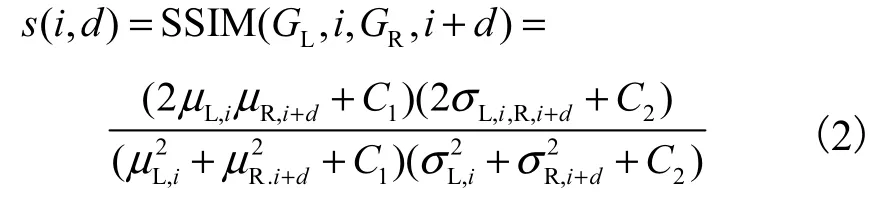
式中:GL代表左视图;GR代表右视图;C1和C2是避免被零整除的常数.假设SL,i为左视图中以i 为中心的大小为W 的邻域矩阵,则μL,i是SL,i的平均值,是SL,i的方差,σL,i,R,i+d是SL,i和SR,i+d的协方差.在本文中,SL,i的大小为7×7,即W=49.
1.2 图像分块预处理
在将失真的立体视图和视差图送入多级表示网络之前,先转换为灰度图像,并划分为多个m ×n 大小的图像块,其中m=n=32.
由于图像的失真是均匀的,因此小图像块的质量标签可设置为源图像的质量标签.为了避免出现大量具有相同质量分数的同质性图像块,笔者使用基于图像块方差的采样策略过滤部分同质图像块,立体图像的方差设计为灰度视图方差的均值,即
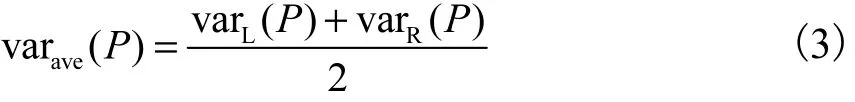
式中:P 是均值为0 的归一化图像块;vaLr ( P) 和varR( P )分别为左视图和右视图的像素方差值.设阈值为T,如果varave( P) >T ,则图像块将被送到多级表示网络进行训练.T 值根据预测性能设置.
2 立体图像质量评价模型
图1 给出多级表示网络的框架.网络中添加视差/深度信息构成三通路的初级子网,将其特征分别融合形成二通路的高级子网,从而构建立体图像质量的整体表示.在多层之间设计特征融合以模拟人类视觉系统中视觉信息的交互过程.最终,多级表示网络分别预测基于视差的交互式双目特征(disparity based interactive binocular feature,DIBF)图和基于无视差的单眼特征(no-disparity based monocular feature,NDMF)图的感知质量分数,求二者的平均值来获得立体图像的质量估计.
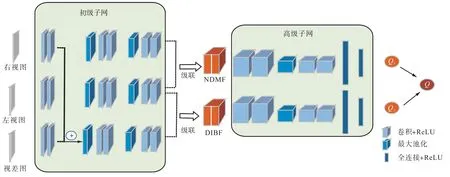
图1 多级表示网络框架Fig.1 Architecture of multi-level representation network
2.1 多级表示网络结构
多级表示网络由初级子网和高级子网两部分组成.初级子网中的3 条通道分别代表左视图通道、右视图通道和视差交互通道.高级子网中的两条通道分别代表DIBF 通道和NDMF 通道,分别对应于提取的立体图像双目特征和单眼特征.
初级子网中的每条通道都包含6 个具有相同结构的卷积层,每两个卷积层后面接最大池化层.在第2 个卷积层之后存在一个低级特征的交互融合,即将视差图特征和右视图特征相加,从而获得低级右视差补偿特征图PRD,同时保留左视图和右视图的初级特征,分别表示为PL和PR,即

式中FL、FR和FD是第2 个卷积层后的特征图.
在初级子网之后,三通道卷积合并为二通道卷积形成两个高级交互式特征图,分别为 DIBF 和NDMF,其中DIBF 代表立体图像的高级双目融合特征,而NDMF 代表立体图像的高级单眼融合特征.级联过程描述为

式中:HL、HR和HRD分别是左视图通道、右视图通道和视差交互通道的高级特征图.两组高级融合特征进一步送到高级子网络中.高级子网中的每个路径都由4 个卷积层、1 个最大池化层和2 个全连接层组成,以预测立体图像单眼特征和融合双目特征的分数.两组高级融合特征彼此互补,对其取平均值得到立体图像的感知质量为
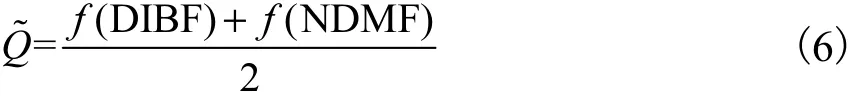
式中f(·)为高级子网的回归函数.
卷积层的卷积核大小为3 ×3 ,在其中应用填充以保持图像块大小恒定.通过3 次最大池化对图像块2 次采样,因此,多级表示网络的输出特征图大小为原始输入图像块的1/8.表1 给出了多级表示网络的详细配置.
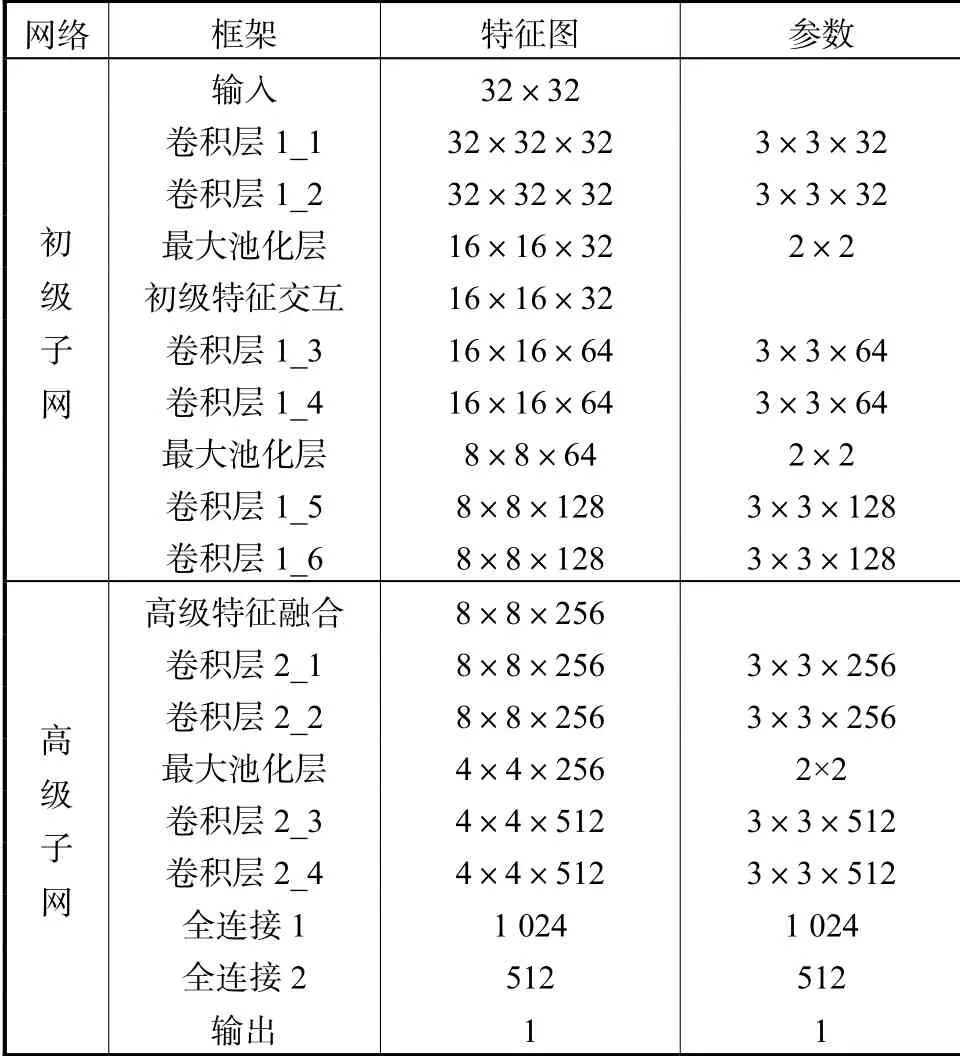
表1 多级表示网络配置Tab.1 Configuration of multi-level representation network
2.2 训 练
网络的损失函数定义为平方差损失与L2 正则化之和.最终损失函数为
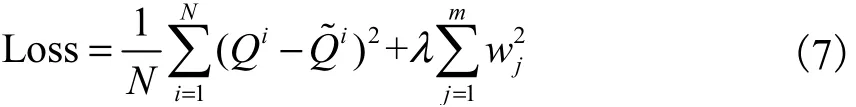
使用Adam[20]训练网络,学习率设置为10-4,衰减因子为0.8,即随着迭代次数的增加,学习速率因指数衰减而降低,从而使网络模型收敛得更快.每个卷积层和全连接层之后接ReLU[21],ReLU 是一种通过采用输入阈值来简化反向传播并增强优化的非线性激活函数.为了有效减少过度拟合,还对每个全连接层应用dropout,在实验中将神经元的输出以0.5的概率随机设置为零.
3 实验结果和分析
3.1 数据集和评价指标
本文在两个公开的立体图像数据库LIVE 3D Phase Ⅰ[19]和 Phase Ⅱ[22]上分析提出网络的性能.LIVE 3D PhaseⅠ数据库由20 幅参考立体图像和365 对失真立体图像组成.LIVE 3D PhaseⅡ数据库包含8 幅参考立体图像和360 对具有5 种不同类型失真的立体图像.涉及 5 种常见的失真类型:JPEG2000 压缩(JP2K)、JPEG 压缩(JPEG)、加性高斯白噪声(WN)、快速衰落(FF)和高斯模糊(BLUR).值得注意的是,LIVE 3D PhaseⅡ数据库中有6 对非对称失真和3 对对称失真.因此,在LIVE 3D PhaseⅡ数据库中评估立体图像的质量更具挑战性.
使用3 个指标评估SIQA 模型的性能:皮尔逊线性相关系数(PLCC)、斯皮尔曼等级相关系数(SROCC)和均方根误差(RMSE).其中,SROCC 测量两个量的单调性,PLCC 测量预测的质量得分和DMOS 之间的线性相关性,RMSE 衡量预测准确性,表示主观得分与预测得分之间的差距.
在实验中,根据参考图像的类型随机选择80%的失真图像作为训练集,其余20%作为测试集.对于每个数据库,重复随机选择10 组不同的训练集和测试集,报告其中值性能.
3.2 算法性能分析
通过非失真特定的方式训练提出的多级表示网络.对比现有的6 种算法,包括2 种全参考和4 种无参考方法.表2 给出LIVE 3D 图像数据库上的性能结果.每列的最佳结果以粗体显示.由于代码不公开,对比的方法结果取自文献[1-2,6-7,10-11].

表2 LIVE 3D图像数据库实验结果Tab.2 Experimental results on the LIVE 3D image databases
对比的全参考方法中,SSIM[1]用于2D 图像质量 评估,其分数为单个视图预测分数的平均值.MSSSIM[2]用于立体图像质量评估.如表2 所示,2D 图像质量评估算法的直接应用没有考虑立体图像特性,无法准确预测立体图像的感知质量,基于双目竞争的MS-SSIM 改善了立体图像质量评估性能.
所有对比的无参考方法均用于立体图像的质量评估,包括2 种传统方法(Chen 等[6]和Messai 等[7])和2种深度学习方法(Oh 等[10]和Fang 等[11]).从表2 可以看出,传统方法可以在一定程度上预测立体图像的感知质量,但是在非对称失真的情况下,其性能大大降低.主要原因是这些手动设计的特征提取算法在很大程度上依赖于人类视觉系统的知识和图像质量下降的统计数据,很难设计一种通用的立体图像视觉质量评估方法来模拟人类视觉系统中复杂的层次结构.与传统方法相比,基于CNN 的立体图像视觉质量评估模型可以更好地预测立体图像的感知质量.与其他方法相比,多级表示网络可以在LIVE 3D PhaseⅠ(仅对称失真)和PhaseⅡ(对称和非对称失真)获得更高的准确性和与主观更一致的分数预测结果.在非对称失真的情况下,所提出的网络更是获得了很好的性能.主要原因是本文将视差信息添加到网络中量化立体图像中的深度信息,网络的多级交互过程模拟人类视觉系统的内部感知过程.实验结果表明,自动端到端的特征学习比传统的手工特征更有效,这进一步证明了深度特征的优越性.
3.3 阈值选择
基于方差的图像块阈值(Tvar)可以确定非均匀图像块的复杂性,是所提出的多级表示网络的关键参数.图2 显示了使用不同阈值进行图像块过滤时对质量预测性能的影响,其中Tvar在0~0.04 的范围内,步长为0.01.曲线的趋势表明,随着Tvar的增加,预测性能首先提高,然后有所降低.基于以上观察,本文选择了Tvar相应的峰值,即0.03.实验表明,基于方差的阈值指标有效地改善了训练过程.
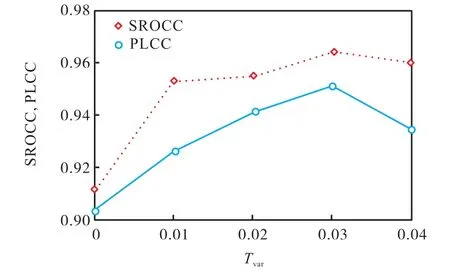
图2 Tvar 对网络性能的影响Fig.2 Effect of Tvar on performance
3.4 交叉数据集验证
为了验证所提出网络的泛化能力,本文进行交叉数据库实验.将LIVE 3D PhaseⅠ和PhaseⅡ数据库之一用作训练集,另一个作为测试集.交叉数据库验证的实验结果显示在表3 中,从实验结果中可以看出,LIVE 3D PhaseⅡ的训练性能优于LIVE 3D PhaseⅠ,原因是LIVE 3D PhaseⅡ包含对称和非对称失真的立体图像,在其进行训练可以捕获对称和非对称失真的特征.LIVE 3D PhaseⅠ仅包含对称失真,因此在LIVE 3D PhaseⅡ的测试结果略逊一筹.总体而言,提出的网络具有最佳的泛化能力,这进一步说明多级表示网络可以扩展到不同的数据库.

表3 交叉数据集验证实验结果Tab.3 Experimental results of the cross-database
3.5 消融实验
为了验证多级表示网络的有效性,进行了消融实验,实验结果如表4 所示.第1 行显示使用所有图像块的结果,可以看出,基于方差的图像块阈值过滤可以有效提高网络的性能,同时表明具有较低方差值的同质图像块会混淆网络的训练.第2 行表示未加入深度信息,即只有单眼特征(NDMF),而第3 行表示仅存在双目特征(DIBF).从实验结果可以看出,单眼特征与双目特征相互补充,提高网络的预测效果.因此,所提出的多级表示网络通过综合考虑立体图像的失真和立体视觉的特性,有效地提取了具有感知特性的立体图像特征.

表4 消融实验结果Tab.4 Experimental results of ablation experiments
4 结 语
本文提出一种用于无参考SIQA 的多级表示网络.首先,使用基于方差阈值的采样指标来过滤同质图像块.然后,考虑到立体图像的深度信息,设计了一个多层次的表示网络来集成立体视图的低级和高级语义信息,该网络通过多层深度卷积模拟人类视觉系统的立体感知过程.特征提取和回归学习被视为端到端的优化过程.实验结果表明,该网络可以获得与人类视觉感知一致的立体图像质量估计.此外,多级表示网络在非对称失真中表现良好,并具有良好的泛化能力.实验结果进一步证明了提出的多级表示网络和特征融合策略的有效性.
