基于自注意力和自编码器的少样本学习
2021-01-08柴星亮
冀 中,柴星亮
(天津大学电气自动化与信息工程学院,天津 300072)
近年来,深度学习的发展推动了大量计算机视觉任务的突破[1].数据多、数据平衡、标注准确、模型大是深度学习的基本特征.虽然在ImageNet[2]这种大型数据集上机器的识别准确率已经超过人类,但收集并标注如此大规模的数据集成本极高[3-4].在某些应用场景下,例如用于药物研发的医学图像,人们甚至无法收集到如此多的样本图像[5].
与机器学习形成对比的是,人类可以从极少数的示例样本中学习到新概念,如儿童可以从书本上学习到某类新事物.赋予机器相似的能力,即从少数的示例样本中学习到新的概念,既是学术界的追求,也是工业界的目标.研究者将模型从少数样本中学习的能力称作少样本学习[6].
根据计算学习理论,机器学习旨在利用先验知识,提高某一度量指标在某一任务上的性能.准确地说,对于分类任务,机器学习旨在通过训练样本从模型的假设空间H 中筛选出某一适合训练集的假设H′,该假设能最小化训练集上的经验误差.但笔者更加关注的是模型的泛化能力,根据概率近似正确(probably approximately correct,PAC)学习理论[7],深度学习需要的样本复杂度是很高的,显然有限的样本无法满足这一条件.
一种可行的办法是借助易获取的大量样本排除假设空间中的不合理假设,缩小可行假设范围.基于度量学习的算法从原始假设空间H 中的初始化点出发,通过随机梯度下降等优化算法使模型收敛到结束点,该结束点属于H′.H′空间的点满足某一度量标准,使得同类样本之间的距离小而不同类别样本之间距离大,从而使训练样本的经验损失最小.缩小后的空间规模利用少数样本便可支撑.特别地,原型网络[8]使用同类样本特征向量的均值作为类别原型来代表该类别,通过比较测试样本和类别原型间的欧式距离实现分类.
虽然原型网络[8]在少样本学习任务上取得了良好的效果,但与大多数度量学习方法类似,其过多关注嵌入空间的类型,忽略了如何高效提取更具区分性的样本特征.度量学习的方法仅关注H′内的点满足某一度量标准,而很少关注如何为样本提取有效特征从而使H′变得更小,也更加精确.对于本就不充足的样本,提取有效特征,缩小H′空间的规模有重要意义.
针对上述不足,本文借助通道自注意力和自编码器的思想,设计了两种独立且兼容的方法来提高样本特征的有效性和类别原型的准确性.在利用卷积神经网络(convolutional neural network,CNN)逐层提取样本特征的过程中,更深层的特征更加稀疏,也更能反映该类别的抽象、特异的特征.基于此,本文合理假设,在CNN 提取特征的不同通道中,越稀疏的通道越能反映该类的本质特征.本文设计一种无参数的通道自注意力方法使得模型关注更加稀疏的特征通道,提取表达性更强的特征.另外,在样本的特征空间中,某一具体类别的特征向量相对于空间某一点的位置是固定的.本文假设对于所有类别的特征向量,其相对于所有样本特征向量均值这一点的位置是不变的,该点被称为“空间原型”.据此,本文借助自编码器的思想,寻找类别特征在该空间中的潜在信息来增强校正原始类别原型.
以原型网络为基础,本文设计实验在两个少样本学习的标准数据集验证所提方法的有效性,结果显示,所提方法能提升原有网络的准确性,尤其是在领域跨度较大时,所提方法取得 10.23%的性能提升.此外,将本文所提通道自注意力方法用于其他少样本学习方法可有效提高原有方法的性能.
1 相关工作
少样本学习自提出以来便吸引了众多研究者的兴趣.经过前期的发展,目前少样本学习方法大致可以从数据扩充、参数预测、度量学习等方面进行归类,本节对此做简单介绍.
1.1 基于数据扩充的方法
一种直接的思路是为缺少样本的类别生成新的样本以扩充数据集,扩充数据后便可使用一般的深度学习分类方法训练模型.Hariharan 等[9]将具有丰富样本的某一类别的姿态变换映射到仅有少量样本的类别,通过姿态转换为少样本类别扩充样本.区别于生成具体的样本,Wang 等[10]关注为少样本类别直接生成有利于分类的特征,从特征空间直接扩充样本.
1.2 基于参数预测的方法
此类方法的思路在于从具有大量样本的类中学习深度网络中某部分参数的生成规则,从而为具有少量样本的类直接生成参数.
Qiao 等[11]根据样本特征向量和分类器参数间的关系,设计网络为具体类别映射生成分类器参数;Wang 等[12]设计残差网络通过渐进式的方式为仅有少数样本的类别更新分类器参数.
1.3 基于度量学习的方法
此类方法致力于将原始图像映射到合适的度量空间,在该空间内,通过比较测试样本与类别样本的距离便可实现目标的分类.
匹配网络[13]利用长短时记忆(long-short term memory,LSTM)网络发现样本之间的关联,使用余弦距离完成进行样本分类,同时提出在任务上优化的方法来训练网络;原型网络[8]使用同类样本的均值作为类别原型,通过比较测试样本与类别原型之间的欧式距离完成分类;关系网络[14]不采用某一固定的度量空间,通过测试样本与类别样本的拼接,利用深度网络比较样本之间的相似性.
本文所提方法也使用距离度量完成最终的分类,与以往方法不同的是,本文更加关注提高样本特征的可辨别性而不是寻找合适的度量空间.
2 自注意力编码网络
本节先从数学的角度介绍少样本学习的定义,然后介绍本文的基准原型网络,最后介绍本文工作中所提出的通道自注意力方法以及自编码器方法.
2.1 问题定义
如前所述,少量的K 个样本不足以支撑整个假设空间.如何合理利用拥有大量标注数据的 Dbase成为少样本学习的关键.元学习(meta-learning)的提出为解决这一问题提供了新思路.在度量学习领域,元学习表现为基于Episode[8,13-14]的训练方法.
基于Episode 的训练方法旨在对少样本学习任务进行逐个优化,通过使用训练集模拟测试过程中的支持集和目标集来实现.具体地,在训练过程中,对于C-way K-shot 任务,模型首先从中随机抽取C 个类别,每个类别随机抽取K 个样本(称为“示例样本”)来模拟支持集,此处将其定义为,随后模型在每个所选类别中除去K 个样本再随机抽取L 个样本(称为“查询样本”)模拟,此处将其定义为.上述 过程 可定 义 为,其中 M =K × C, N =L ×C ,x 为样本图像,y 为其对应的标签.每次的损失在一个Episode 上进行计算,从而实现对任务的优化,即

2.2 原型网络
原型网络[8]旨在利用同一类别样本特征向量的均值作为类别原型来表示该类别,然后通过比较测试样本与类别原型之间的欧式距离完成分类.具体地,给定支持集和目标集,第n 个类别的原型 cn可以表示为
式中:fφ表示特征提取器;φ 为网络参数;xnk表示第n 个类别的第k 个样本.对于来自的样本 xi,对其使用softmax 函数完成最终分类,即

2.3 自注意力编码网络
图1 为本文所提出的通道自注意力编码网络(self-attention auto-encoding networks,SA2EN)的整体结构.如前所述,本文关注如何提高样本特征的可鉴别性以及如何获得更准确的类别原型,因此图1 中仅展示获得增强型类别原型的过程.具体地,本文设计无参数的通道自注意力网络作为特征提取器从每个样本提取更能聚焦该类别特征的向量,然后利用编解码器的结构对类别原型在特征空间中的位置进行调整,提升类别原型的准确性.输入样本首先经过特征提取器映射为对应的特征向量,随后,取同类样本的特征向量均值得到该类别的基础原型,将此基础原型与“空间原型”通过自编码器得到其调节原型向量,最后,将此调节原型和类别基础原型乘以相应的系数并相加得到该类别的增强原型.

图1 自注意力编码网络结构Fig.1 Network structure of self-attention coder
2.3.1 通道自注意力特征提取网络
通道自注意力网络(self-attention networks,SAN)的重点在于提高样本特征向量的可辨别性.在图1 的整体结构框图中,本文使用ResNet[15]作为特征提取器的基本结构,并在其中加入通道自注意力,其具体结构如图2 所示.

图2 特征提取模块Fig.2 Feature extractor module
图2(a)为特征提取器整体结构.网络开始为初始化层,该层对输入图像做预先处理.本文使用常见残差网络中的初始化层,包含一个卷积核大小为7、步长为2 的卷积层,一个批量归一化层,一个激活层和一个最大池化层.随后,初始化层的输出经过4个残差模块和一个平均池化层得到输入图像的特征图,将该特征图展开成特征向量得到网络的最终输出.
残差模块结构如图2(b)所示,图中CBR 分别代表卷积、批量归一化和ReLU 激活.输入模块的特征映射首先经过持续的卷积、批量归一化、激活操作得到中间的特征映射,本文所提通道自注意方法便作用在这些特征映射上.对于每个通道的特征图,模型首先计算其L2 范数的平方,随后计算该平方的倒数,将所有倒数进行softmax 归一化得到每个通道的重要性系数,即每个通道对应一个标量值,该值反映出该通道对于该样本的重要程度.随后,每个特征图与其相对应的重要性得分相乘得到带注意力的特征映射.上述过程可用公式表示为


式中: hi表示第i 个通道的特征映射;αi表示第i 个通道的重要程度系数;hi,att表示经过自注意力处理后的通道.
从上述构建通道重要性程度的过程可以看出,模型选择特征图总体更接近0 的特征图赋予更大的权值.换句话说,对于特征图来说,更为稀疏的特征图对该类别更加重要.这样设计是因为从稀疏的角度来看,更为稀疏的值更能反映样本的本质特征,即稀疏值更能反映该类的特有模式,也需要更多的关注.从另一个角度来说,不同特征图的表达能力更加均衡,从而提高了特征的整体表示能力.
2.3.2 自编码器
原型网络仅使用每个类别给定的少数支持样本的均值来表示该类别,然而,如此少量的样本所包含的信息难以反映该类别的特征.如何从给定的数据中挖掘尽可能多的信息来弥补支持集 Dbase中样本的信息不足是少样本学习的一种研究思路.在特征空间中,所有样本的特征向量的均值稳定于该空间中的某一固定点,本文称之为“空间原型”,每个类别与该原型的相对位置固定.基于此,本文设计自编码器网络(auto-encoding networks,AEN),通过寻找基础原型与该空间原型的关系来对基础原型进行修正.
训练自编码器的前提是得到空间原型.具体地,本文首先使用 Dbase在基础原型网络上进行训练,训练结束后,利用其特征提取器对 Dbase中所有的样本进行特征提取,随后将所有样本特征向量做均值得到空间原型o,用公式表示为

对于第n 个类别的基础原型向量 cn,本文将其与空间原型o 进行拼接.随后,根据Edwards 等[16]的研究,模型将拼接后的向量无监督地映射到低维的隐空间,计算该类的统计信息,隐空间低维向量 en被重参数化为具有对角协方差的条件多元高斯分布.接着使用解码器将其解码,获得与类别原型维度相同的调节原型.最后,二者乘以其相应的系数获得该类别最终的原型.

式中:c(⋅ ,)⋅表示拼接操作;gen,θ代表编码器,其参数为θ;gde,φ代表解码器,其参数为φ.
3 实 验
本节首先介绍所提方法在两个标准数据集miniImageNet[13]和 The Caltech-UCSD Bidrds-200-2011 Dataset(CUB)[17]的测试结果,随后介绍其在跨数据集[18]设定下的测试结果,最后就通道自注意力方法的通用性做测试.
对于所有实验,本文采用Adam[19]作为优化器并将学习率设定为10-3.对训练数据采用基本的数据增强技术例如随机裁剪、翻转等.与以往工作保持一致[8,13,18],在miniImageNet 和CUB 上,本文训练并测试了5-way 1-shot 和5-way 5-shot 的准确率,在跨数据集的场景下,与Chen 等[18]的工作一致,本文测试了5-way 5-shot 的准确率.在训练阶段,除去K 个示例样本,本文为每个类选择16 个样本作为查询样本,即L=16.
3.1 miniImageNet
miniImageNet 是 Vinyals 等[13]从大型数据集ImageNet 中随机抽取的一个子集.该数据集中不同类之间的差异比较大,是少样本学习领域挑战性较大的一个数据集.该数据集包含100 个类别,每个类别拥有600 幅图像,整个数据集拥有60 000 幅图像.现有工作[8,18]通常将该数据集中的64 个类划分为训练集,16 个类划分为验证集,20 个类划分为测试集.验证集用来筛选训练模型.
与以往工作一致[8,18],本文在测试集中随机组成600 个片段,每个片段中的每个类包含15 个待识别样本进行测试,结果为600 个片段的平均准确率.
表1 为所提方法在miniImageNet 上的实验数据,为公平比较,表1中将对比算法采用的基准网络架构列出,其中ConvNet 指较为浅层的CNN,而ResNet 代表采用ResNet[15]网络结构的方法.本文所提方法在5-way 1-shot 的任务上取得了最高的性能,在5-way 5-shot 任务上取得了第2 高的性能.无论是1-shot 还是5-shot,相较于原始基准PN,本文所提方法均使其性能得到提升,且分别提升 4.25% 和2.37%,证明了所提方法的有效性.
3.2 Caltech-UCSDBirds-200-2011
该数据集是加利福尼亚大学发布的一个鸟类数据集,其包含200 种鸟类,共11 788 幅图像,早前被用于细粒度图像分类[25]和零样本图像识别[4]. Hilliard等[26]将其引入少样本图像分类领域并对数据集进行划分,与其一致,本项工作采用100 个类作为训练集,50 个类作为验证集和50 个类作为测试集.在该数据集上的测试仍为600 个片段的平均准确率.

表1 miniImageNet数据集测试结果Tab.1 Test results on the miniImageNet dataset
如表2 所示,本文所提方法在细粒度数据集上的5-way 1-shot 和5-shot 性能达到了所有对比算法中的最优.相较于原始基准,在1-shot 任务上,所提方法取得了6.37%的性能提升,在5-shot 任务上取得了3.09%的性能提升,证明了所提方法在细粒度图像分类任务上的有效性.

表2 CUB数据集测试结果Tab.2 Test results on the CUB dataset
分析表1 和表2 中的数据不难发现,对于通道自注意力方法,无论miniImageNet 还是CUB,所提方法对1-shot 任务性能的提升大于对5-shot 任务性能的提升,且相对与原始基准,其性能相对提升幅度分别达到了8.18%和9.08%,这证明了当样本比较少时为其提取鉴别性特征的重要性,也说明了本文所提通道自注意力方法的有效性.
3.3 跨数据集少样本分类
跨数据集的分类设定由Chen 等[18]首先引入,其目的在于测试当训练任务和测试任务差异较大时不同方法的性能,是一种更加复杂同时也更符合通用少样本分类任务的设定.在该设定下,模型使用全部miniImageNet 数据作为训练集,50 个CUB 中的类别作为验证集和50 个CUB 中的类别作为测试集.在Chen 等[18]的研究中,仅仅使用ResNet18 作为特征提取器来提取特征,为与其公平对比,本文使用ResNet10 进行验证后,也进行了ResNet18 的实验.
表3 为本文所提方法在跨数据集即领域差异较大设定下的测试数据,无论使用 ResNet10 或者ResNet18,本文所提方法均取得最佳性能.相比于表1 和表2,表3 的准确率明显降低,这说明当数据集差异比较大时,单纯利用基于片段元学习方法难以获得泛化性能较好的特征,即适合训练集的特征难以适用于测试集.相对于原始方法,本文所提方法分别取得 10.23% 和 8.85% 的绝对提升,相对提升达到17.04%和14.27%,显示出当领域差异较大时所提方法的有效性,通道自注意力网络在这种设定下为原始方法带来显著的性能提升,说明在领域差异较大时,模型捕捉更具判别力特征的重要性.少样本分类任务的研究向着通用化发展,在这些设定下数据差异较大,本文的研究为解决此类问题提供了思路.

表3 跨数据集测试结果Tab.3 Test results on the cross-domain setting
表1~表3 的数据从一定程度上反映出相比于自编码器的方法,通道自注意力方法在少样本学习上有更好的性能.本文认为其原因之一在于通道自注意力方法是无参数的,这能有效避免少样本学习中比较严重的模型迁移能力弱问题.除此之外,通道自注意力方法对每个样本的特征提取过程进行调节,其对特征提取的影响范围比自编码器方法更大.这两种原因导致通道自注意力方法取得了更好的性能.通道自注意力方法和自编码器方法结合能进一步带来性能提升,本文认为其原因为两种方法的关注点不同,自编码器旨在更深入挖掘训练集中的可用信息,这在通道自注意方法中并没有体现,两者具有一定的互补性,故能进一步提升性能.
3.4 通道自注意力网络的适用性验证
如前所述,作为对特征提取模型的改进,本文所提的通道自注意力模型可以被容易地结合到其他方法之中,本节选取5 种方法测试所提通道自注意力模型的普遍适用性.实验结果如表4 所示.
从表4 可以看出,将本文所提通道自注意力方法应用在其他方法上时,能进一步提升该方法的性能.表4 中所选方法既有基于度量学习的方法也有基于非度量学习的方法,证明了所提方法的适用性.

表4 通道自注意力网络的适用性测试结果Tab.4 Adaption test results of the channel self-attention method
3.5 无/有参数通道自注意方法的对比
如前所述,本文所提通道自注意方法在不引入额外参数的情况下显著提升了少样本图像分类网络的性能.无参数在增加极少量运算量的同时缓解了模型可能存在的模型迁移能力弱问题.本节选取有参数通道自注意模型SENet[27]作为对比算法,进一步研究所提方法的有效性.
与前文一致,在miniImageNet 和CUB 上,本节选取5-way 1-shot 和5-shot 对比两种方法的性能,其结果展示在表5 中.在跨数据集分类场景下,本节仍选取两种网络测试所提方法的性能,其结果展示在表6 中.从表5 和表6 可以看出,相对与基准网络,两种注意力方法都能带来性能提升,这说明为样本提取有效特征的重要性.同时,在3 种分类场景下,本文所提无参数通道自注意力方法的性能均超过SENet,这一定程度上表明当动机相同时,减少参数量对少样本图像分类的意义.参数量的减少降低了模型对训练集过拟合的可能性,使得模型更适合少样本分类的场景.
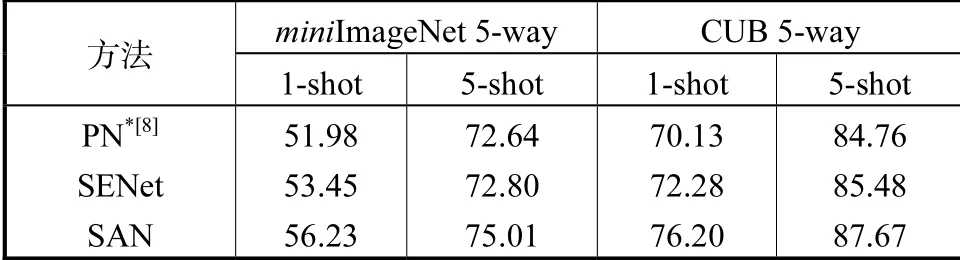
表5 miniImageNet 和CUB 上不同注意力方法的性能比较Tab.5 Performance comparation of different attention methods on miniImageNet and CUB

表6 跨数据集上不同注意力方法的性能比较Tab.6 Performance comparison of different attention methods on the cross-domain setting
4 结 语
为提高样本的特征表达能力,本文提出一种通道自注意力方法提升特征提取网络的有效性,使其提取更具有判别性的样本信息.同时,本文通过基本原型和空间原型的结合,使用自编码器结构对类别原型进行校正,合理利用了更多的样本信息.实验结果表明本文所提方法在少样本图像分类的标准数据集上取得了较好的效果,特别地,在跨数据集的少样本图像分类任务中,本文所提方法相对原始网络最高取得了10.23%的绝对性能提升和17.04%的相对性能提升,证明了所提方法的有效性.
