基于信息熵的粗糙集属性应急数据去重挖掘算法研究
2021-01-06曾维佳秦放李琳徐鹏
曾维佳 秦放 李琳 徐鹏


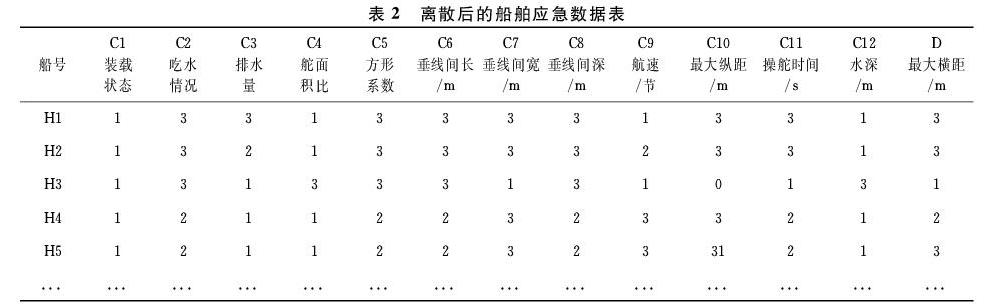


摘 要:主动学习已经被证明是一种成功的机器学习算法,最主要的缺點是它只注重样本的标签信息而忽略了样本的分布信息。因此带来的后果就是稳定性差,容易陷入局部最优解,同时对初始样本的选择非常敏感。论文将稀疏子空间聚类与主动学习相结合,首先利用稀疏子空间聚类找到原始数据的分布信息,然后利用该信息指导主动学习选取初始样本,使样本标注更加有效,提高了主动学习的效率,同时降低了主动学习对初始样本的敏感度。最后通过多组仿真实验证明,本方法可以有效的改善主动学习的性能。
关键词:主动学习;稀疏子空间;聚类
中图分类号:TP391.9 文献标识码:A
主动学习作为一种成功的机器学习,已经广泛的应用于生物、医学和材料等领域。例如研究细胞蛋白质的相互作用,通过实验验证的代价非常大,利用主动学习,可以在有限的样本基础上进行训练,然后有效的预测蛋白质间是否具有相互作用,从而大大降低了实验代价。
但是传统的主动学习对初始值比较敏感。选择不同的样本作为初始样本集,最终通过学习得到的分类模型可能会有很大的差异。有的效果非常好,有的虽然经过多次的迭代但效果仍然很差,表现很不稳定。导致这种现象的一个主要原因是,主动学习在选择样本时没有考虑数据集本身的结构分布特点。
主动学习要进行第一次迭代之前,需要建立一个初始分类模型,用于选择信息含量最大的样本。所以,传统的主动学习在迭代之前,首先要随机选取一定量无标签样本,提交给专家标注。这些标注好的样本就构成了初始有标签样本集L(0)。在实际应用中,要选择合适的L(0)非常困难,为了降低主动学习对初值的敏感性,增强主动学习的鲁棒性,许多学者提出了一些降低对初始值敏感程度的主动学习方法。2012年Swarnajyoti等人提出了一种基于预聚类的主动学习方法SPLB[1][2]。SPLB算法与传统的主动学习方法不同,它优先选取稀疏区域的样本进行标注。实验证明,该方法可以提高样本的使用效率,加快了主动学习的收敛速度。但是上述算法仍存在问题,该算法只能处理简单、线性可分的数据集,没有考虑到现实生活中大量高维非线性数据集的情况,处理复杂数据集的效果并不理想。
受上述思想的启发,结合稀疏子空间算法的优点,提出了一种改进的主动学习算法,同时结合了样本的标签信息和分布信息。首先在迭代之前,采用基于稀疏子空间聚类,找到嵌入高维空间的低维结构,并利用此结构信息来指导主动学习选择需要标注的样本,提高标记样本的利用率。同时,由于掌握了数据集的整体分布信息,降低了陷入局部最优的概率,提高了主动学习的效率。
1 稀疏子空间聚类
稀疏子空间聚类[3]是近几年来研究热点,它的主要思想是现实生活中的高维空间,由于数据间存在的内在联系,在本质上是属于多个低维子空间并集,可以用低维空间的线性组合来表达,这种线性表达还可以用来刻画不同低维子空间的相似度。然后利用拉普拉斯特征映射根据相似度矩阵进行聚类。
2 稀疏子空间聚类与主动学习的结合
本节的核心是将稀疏子空间聚类和主动学习结合在一起。为了最大限度的降低主动学习中标注样本的代价,我们需要尽量挖掘主动学习中各部分的信息。本节的核心就是挖掘无标签样本的结构信息,为主动学习的初始化提供指导,从而提高主动学习的效率和效果。
在主动学习的初始化阶段,先用稀疏子空间聚类找到原始数据集的子空间结构,然后对子空间进行聚类,再挑选到两个聚类中心距离差最小的样本来标记,作为主动学习的初始样本集。由于利用了数据集的结构信息,因此能有效的找到全局最优解。
下面以主动学习中最常用的SVM算法为例,处理二分类问题。具体的算法如下表1所示:
3 算法有效性验证
为了评估论文算法的性能,作者在不同的标准数据集上进行了对比仿真实验。论文所需的数据都是来自公开数据集LIBSVM[5]。为了测试论文算法的有效性,文中与多种学习算法进行比较:
Passive:被动学习支持向量机:该方法在每次迭代时,随机选取k个样本进行标注,并用来更新模型。
ALSVM:传统的主动学习支持向量机算法:该方法选择k个不确定性最强的样本进行标注,作为支持向量来更新模型。
SPLB:由Swarnajyoti等人提出的方法。在主动学习迭代之前,先对数据集进行预聚类处理,然后在数据稀疏的区域建立初始分类超平面。该算法与文中算法类似,因此作为文中算法的主要比较对象。
Proposed:基于稀疏子空间聚类的主动学习算法。
3.1 USPS数据集验证
为了验证基于稀疏子空间的拉普拉斯特征映射算法的有效性,将该算法应用到目前比较流行的公开数据集LIBSVM。以其中的USPS数据集为例,通过这个数据集来仿真验证论文算法的效果。
USPS是一个被广泛使用的手写字符识别数据集,里面包含七千多个数字字符(数字0-数字9)。
为了构成一个二分类的问题,本次实验随机选取一个数字6来进行验证。为了构成能使用支持向量机处理的二分类问题,将数字6的类别标签设为+1,其余的图片样本标签设为-1。这种策略经常用来处理多分类问题。
支持向量机超参数C=100,高斯核的超参数γ=0.01。
实验选择10个样本作为初始有标签样本,每次迭代20次。同时,为了进一步验证论文算法的效果,排除随机噪声干扰,作者进行了100次重复实验,最终将每次迭代的实验结果取平均值。
下图2是USPS中将数字6与其他手写数字进行分类的效果:
从上图2可以看出,利用作者提出的基于稀疏子空间的拉普拉斯特征映射算法的准确率要高于传统的主动学习算法,最终的误分率比传统算法的低了50%左右。该算法也优于SPLB算法。SPLB方法在支持向量机的输出空间中寻找稀疏区域,而在主动学习的前期,支持向量机的分类精度比较低,所以数据在输出空间的分布并不能完整反映整个数据集的分布情况。而作者的算法是根据流形假设,建立在图论中的谱图理论的基础上的,其本质是将聚类问题转化为图的最优划分问题,因此,比简单的聚类效果更好。所以该算法有效的提高了主动学习的效率,同时改善了主动学习算法的鲁棒性。
为了进一步证明论文算法的效果,表2中列出了在100次仿真实验基础上得到的最终误分率的统计指标。其中:
MAX代表100次仿真结果中的最大误差;
MIN代表100次仿真结果中的最小误差;
MEAN代表100次仿真结果的均值;
STDEV代表100次仿真结果的标准差。
这四项指标中,最主要的参考指标是MEAN和STDEV,前者反映多次仿真实验的平均精度,后者反映了与均值的偏离程度。MAX和MIN指标仅供参考,主要用于了解某算法的波动范围。
四项指标中,每一项中最低的值均用黑色粗体表示。从表2中可以看出,除了最小误差的指标MIN,论文算法在其他三个指标方面都由于其他算法,说明该算法具有很好的性能,能有效的降低样本的标注成本。同時,该算法有最低的标准差说明算法的鲁棒性很好,受初始状态的影响很小。
3.2 其他数据集验证
为了进一步验证论文算法的有效性,除了上述数据集之外,我们还使用其他数据集进行了广泛的验证,每组仿真实验均进行100次,最终的验证结果在下表3中给出。这些数据集都转化为二分类问题。在表中我们给出了每组实验的超参数,每次迭代所选择的样本数和迭代次数。在表3中,每种算法都给出两个指标,上面一个指标是多次实验后的平均误分率MEAN,下面一个指标是多次实验的标准差STDEV。
从表3中我们可以看出,论文所提出的算法在总计18组实验数据中取得了12次最好的分类成绩,并且具有最低的标准差。足以体现本算法的优势。
4 结 论
所提出算法比其他的主动学习算法体现出了更高的分类精度和更快的收敛速度。这是因为,传统的主动学习算法在开始执行时并没有考虑数据集的结构信息,只依靠样本的标签信息不断的迭代,这种逐步挖掘信息的方法效率比较低,而且对初始值比较敏感。而论文的算法除了考虑到数据样本的标签数据之外,还充分考虑了无标签样本所包含的结构信息,并利用这些信息来指导主动学习的样本选择。从而使主动学习在初始阶段的样本选取就位于全局最优解附近,再逐步选择对分类作用最大的支持向量进行迭代,因此分类的精度更高,而且效率高,节约了大量的样本标注成本。同时,因为掌握了整体的结构,使得初始样本的选择更加合理,有效的降低了主动学习陷入局部最优的概率,增加了稳定性。同时,仿真实验表明论文算法具有较低的标准差,说明算法的鲁棒性较好,受初始值的影响小。
同时,该算法也有不足之处,该算法的时间复杂度为On3级别,说明论文算法的时间消耗比较大。因此,需要在进一步提升计算效率上进行研究。
参考文献
[1] PATRA S, BRUZZONE L. A fast cluster-assumption based active-learning technique for classification of remote sensing images [J]. Geoscience and Remote Sensing, IEEE Transactions on, 2011, 49(5): 1617-1626.
[2] PATRA S, BRUZZONE L. A cluster-assumption based batch mode active learning technique [J]. Pattern Recognition Letters, 2012, 33(9): 1042-1048.
[3] ELHSMIFSR E, VIDAL R. Sparse subspace clustering: algorithm, theory and applications [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013, 35(11):2765-2781.
[4] GLOWINSKI R. ADMM and non-convex variational problems [M]. Splitting Methods in Communication, Imaging, Science, and Engineering, Springer International Publishing, 2016.
[5] CHANG Chih-chung, LIN Chih-jen. LIBSVM: a library for support vector machines[C]. ACM Transactions on Intelligent Systems and Technology, 2011, 2:1-27.
