基于异构多核SoC的LT码编码硬件化技术研究*
2021-01-06江仲鸣杨全胜
江仲鸣,杨全胜
(东南大学计算机科学与工程学院,江苏 南京 211189)
1 引言
喷泉码(Fountain Code)是一类无码率编码,具有抗干扰能力强、接近香农极限的优点。2002年,Luby[1]公布了首个实用的数字喷泉码——LT(Luby Transform)码。现今,LT码被广泛应用于气象水文数据广播[2]、深空通信[3]、电力线通信[4]和移动视频传输[5]等领域。这些领域存在大量嵌入式设备。在嵌入式系统中高效地实现LT码,不仅能够实现数据发送端和接收端设备的小型化、轻量化,还能提高端设备的能效。
目前学术界和工业界对于LT码的研究工作主要分为3类。第1类属于LT码的应用性研究;第2类是LT码的优化方法研究,其主要研究方向是优化LT码的度分布函数,以提高译码成功率;第3类则是LT码的硬件实现方法研究。
目前,关于LT码硬件实现的研究主要基于FPGA展开,主要优化方法有:(1)改进鲁棒孤子分布RSD(Robust Soliton Distribution),增加低度数编码包的出现概率[6,7],从而降低译码复杂性;(2)使用码本对生成矩阵进行压缩[7],降低LT码编码的存储代价和数据通信开销;(3)采用乒乓缓存机制[8,9],提高硬件编码器内部的数据交换速率。方法(1)的副作用是降低了译码成功率;方法(2)等同于直接记录每次编码产生的原始数据分组号;方法(3)则是通用的硬件设计优化方法。这些方法仅针对LT码编码的某个环节进行优化,并未从整体上优化LT码编码器的设计。
此外,LT码通常只是应用系统的一个环节,完全采用FPGA实现LT码编码器,将消耗较多的逻辑资源,降低硬件平台的实用性,增加系统设计成本。因此,有研究在XILINX ZYNQ的异构平台上实现LT码的编码器[10],但该研究没有为异构平台制定计算任务到各处理核心之间的任务映射策略。
本文将对异构多核SoC进行建模分析,将LT码编码在异构多核SoC上的实现问题转换为LT码编码算法在异构多核SoC上的任务映射问题,并基于遗传算法给出了该问题的求解方法。最终基于异构多核SoC上的LT码编码子任务映射问题求解结果,在XILINX ZYNQ-7000异构多核平台上实现LT码编码器。实验结果表明,本文所设计的LT码编码器能够满足不同的性能和资源需求,增加了硬件平台的实用性和应用系统设计的灵活性。
2 LT码编码技术简介
LT码将原始数据分割成若干分组,利用这些分组产生编码包,并向外源源不断地发送这些包;数据接收端接收一定数量的编码包,并恢复原始数据。
2.1 LT码度分布
假设待编码的原始数据分组个数为k,从中任意选取d个分组,并将这些分组按字节异或,即可得到一个编码包,则称d为该编码包的度数。
LT码的核心是度数的概率分布函数,简称度分布函数。若待编码的原始数据分组个数为k,则鲁棒孤子分布RSD的表达式为:

(1)
其中,μ(i)表示度数取i的概率,其表达式为:
(2)
其中,ρ(·)为理想孤子分布,其表达式为:
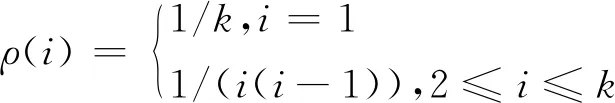
(3)
其中,τ(·)的设置是为了提高低度数编码包的出现概率,从而提高译码成功率,其表达式为:

(4)
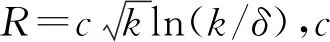
2.2 LT码编码算法
假设有被分割成k个分组的原始数据S,即:
S={s1,s2,…,sk}
则LT码的编码算法如算法1所示。
算法1LT码编码算法
输入:原始数据S。
输出:LT码编码包。
步骤1通过Monte-Carlo实验,基于式(1)生成一个度数d。
步骤2从S中随机选择d个不重复的数据分组。
步骤3记录步骤2选择的数据分组号,形成编码包的数据包头部h。
步骤4将步骤2选择的数据分组进行异或,形成编码包的数据载荷l。
步骤5将数据包头部h和数据载荷l打包形成编码包e。
步骤6发送步骤5生成的编码包e。
步骤7若接收端已成功译码,则结束;否则转到步骤1。
3 面向特定应用的异构多核SoC模型
本节首先为异构多核SoC建立模型,然后基于所建立的模型,将LT码在异构多核SoC上的实现问题转变为异构多核SoC上的任务映射问题,随后基于遗传算法给出该映射问题的解决方法。
定义1(异构多核SoC) 异构多核SoC是指将不同架构的处理核心集成到同一块数字集成电路元DICE(Digital Integrated Circuit Element)的嵌入式单机异构多核系统。
由于处理核心被集成到同一块DICE,各处理核心之间的通信线路长度大大缩小,因此异构多核SoC理论上比具有相同功能的嵌入式系统具有更低的核间通信延时、更强的抗干扰能力、更低的功耗和更小的体积。
3.1 异构多核SoC模型建立
虽然异构多核SoC具有一定的通用性和可编程性,但在实际的应用场景中,异构多核SoC通常只运行有限种类、有限个数的应用。由此可认为异构多核SoC是面向特定应用的,所以本文在对其建模时,将异构多核SoC所面向的应用也包含在模型内部。
3.1.1 应用表示模型
若要对面向特定应用的异构多核SoC进行建模,首先需要对其应用进行描述。本文使用带权有向图WDG=(V,E)描述异构多核SoC所针对的特定应用。
首先将异构多核SoC所针对的特定应用划分成n个子任务。子任务划分的原则是:
(1)完整性和等效性。尽管应用被划分成若干子任务,但这些子任务应当能够通过重组还原出原始应用。
(2)同构性。在不存在数据相关性的前提下,相同种类的运算应当被划分到同一个子任务。
按照以上原则,将异构多核SoC所针对的特定应用划分成n个子任务,每个子任务对应顶点集V中的一个顶点;子任务之间的执行顺序关系对应边集E中的有向边;子任务之间的通信数据量对应边集E中有向边的权值,由此得到异构多核SoC的应用表示模型。
3.1.2 异构多核SoC 4元组模型
以下给出异构多核SoC 4元组模型的定义。
定义2面向特定应用的异构多核SoC模型HSoC可定义为4元组HSoC= (P,V,E,F),其中:P为处理核心集合,P={p1,p2,…,pm}是异构多核SoC中的所有m个处理核心构成的集合。V为任务集合,V={v1,v2,…,vn}表示HSoC所针对特定应用的n个子任务,对应于WDG中的顶点集。E为通信集合,E={(eij,wij)|1≤i,j≤n∧vi,vj∈V},其中,eij表示子任务vi与vj之间的执行顺序关系,对应于WDG中的有向边;wij表示子任务vi与vj之间的数据通信量,对应于WDG中有向边的权值。F为映射,F⊆V×P表示任务集合V到处理核心集合P之间的映射关系。
3.1.3 HSoC加速比模型
首先引入执行时间矩阵为:Tn×m和带宽集合B。
(1)执行时间矩阵为:
其中,tij表示子任务vi在处理核心pj上的执行时间。
(2)带宽集合B={bij|1≤i,j≤m∧pi,pj∈P},表示HSoC的任意2个处理核心之间的通信带宽。当i=j时,令bij=∞,即处理核心内部的通信时间忽略不计。
在描述HSoC所针对特定应用的WDG中,存在串行和并行2种基本子结构,分别如图1和图2所示。
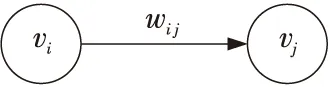
Figure 1 Serial sub-structure图1 串行子结构

Figure 2 Parallel sub-structure图2 并行子结构
在图1所示的串行子结构中,子任务vi、vj在处理核心F(vi)、F(vj)上的执行时间分别为ti,F(vi)、tj,F(vj),且vi与vj之间的通信时间为wij/bF(vi),F(vj),因此该子结构的执行时间ts为:
(5)
类似地,在图2所示的并行子结构中,其执行时间tp为:
(6)
特别地,对于循环次数为N的循环结构,其执行时间的计算方法为:将循环体划分为若干个形如图1和图2所示的子结构,利用式(5)和式(6)计算循环体的单次执行时间,并将其乘以N。
将WDG拆分为若干如图1和图2所示的子结构,根据式(5)和式(6)分别计算各子结构的执行时间,并对这些子结构的执行时间进行求和,最终得到应用在HSoC上的总执行时间THSoc。
假设HSoC所针对的特定应用在PC机上的执行时间为TPC,则加速比Sp为:
(7)
式(5)~式(7)构成了HSoC的加速比模型。
3.2 HSoC上的任务映射问题
3.2.1 HSoC上的任务映射问题定义
此处引入资源集合R={r1,r2,…,rm},表示HSoC的片上资源集合,其中ri表示处理核心pi所拥有的资源集合。
基于定义2给出的HSoC 4元组模型,以及式(5)~式(7)给出的HSoC加速比模型,给出如定义3所示的HSoC上的任务映射问题定义。
定义3(HSoC上的任务映射问题) 在面向特定应用的HSoC= (P,V,E,F)上,以资源集合R作为限制条件,通过某种映射策略,在任务集合V与处理核心集合P之间建立映射关系F,使得系统的某项指标(如加速比、能效、单位资源加速比等)达到最优。
3.2.2 任务映射问题简化
根据定义2,对于HSoC,其处理核心集合P中的m个处理核心相互之间可能同构,也可能异构。
此处引入HSoC处理核心的架构类型集合(以下简称处理核心类型集合)Φ={P1,P2,…,Pθ},表示HSoC所具有的θ(1≤θ≤m)种类架构的处理核心。其中,Pi表示P中第i类架构的处理核心所构成的集合,且有:
s≠t∧1≤s,t≤θ
(8)
基于处理核心类型集合Φ和式(8),可将定义3所述的对映射关系F⊆V×P的求解,转化为对映射关系F′⊆V×Φ的求解。
当求得映射关系F′,使得系统的某项指标(如加速比Sp、能效、单位资源加速比等)达到最优时,定义3所述的任务映射问题也得到了最优解。该结论容易通过反证法证明,限于篇幅,本文略去证明过程。
由此,对HSoC上的任务映射问题进行了简化。
3.2.3 基于遗传算法的映射方法
HSoC上的任务映射问题属于软硬件划分问题,换言之,是NP完全问题[11]。采用遗传算法在解空间中进行搜索,可以获得近似最优解。
基于遗传算法解决HSoC任务映射问题的具体方法是:
定义种群个体的染色体为一个n维向量:
a={a1,a2,…,an},1≤ai≤θ,1≤i≤n
(9)
若ai=k,则表示子任务ai被映射到HSoC的第k类处理核心集Pk。
考虑不同的优化目标,基于HSoC的加速比模型设计相应的适应度函数,并利用随机数生成初始种群。通过一定次数的迭代,最终获得目标解。
4 基于HSoC的LT码编码器设计
本节将根据第2节提出的HSoC上的任务映射问题及其解决方法,基于XILINX ZYNQ异构多核SoC,设计LT码编码器。
在本文中,LT码参数设置如表1所示。
4.1 硬件平台
本文使用的硬件平台是XILINX ZYNQ-7000系列Zybo开发板。该开发板的主芯片是基于ARM双核Cortex-A9+FPGA的异构多核SoC。因此,对于该硬件平台,处理核心类型集合Φ={P1,P2}。其中,P1={p11,p12}代表ARM双核Cortex-A9的CPU,P2={p21}代表FPGA。
4.2 数据量化
由式(1)~式(4)可知,计算RSD涉及大量浮点运算,而在FPGA实现浮点运算需要消耗大量逻辑资源。为此,本文采用了16 bit量化策略,相关实验及分析见5.1节。
4.3 编码器映射问题的求解
4.3.1 LT码编码任务划分
按照2.2节所述的LT码编码算法,基于3.1.1节所述的子任务划分原则,将LT码的编码过程划分为7个子任务,如表2所示。
表2中,子任务v1、v2、v3、v4对应RSD的计算;子任务v5对应2.2节中的步骤1;子任务v6对应2.2节中的步骤2和步骤3;子任务v7对应2.2节中的步骤4和步骤5。
进行16 bit量化后,对应的WDG如图3所示。其中,有向边上的数字代表2个子任务之间的数据通信量,单位为字节。虚线箭头表示子任务v5、v6、v7循环1 450次。
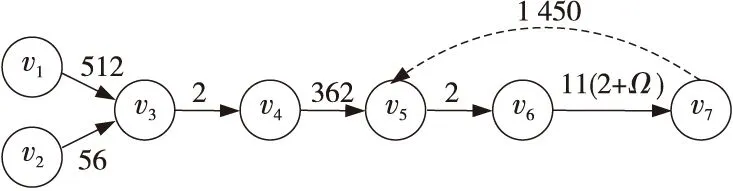
Figure 3 Task model of LT codes’ encoding图3 LT码编码任务模型
上述7个子任务分别在PC机、ARM Cortex-A9和FPGA上的执行时间如表3所示。
已知在150 MHz时钟下,ARM和FPGA通过AXI-GP接口通信的理论最大带宽为600 MB/s[12]。
基于以上设置,下面分别以加速比Sp、单位资源加速比作为适应度函数,对LT码编码在异构多核SoC上的映射问题进行求解。
4.3.2 以加速比Sp作为适应度函数
令加速比Sp为适应度函数,设种群大小为1 000,求得在迭代100次后,加速比Sp>1的部分可行解如表4所示。
根据表4所示的映射结果及其对应的加速比Sp,结合式(9)对染色体的定义,可知:(1)利用FPGA实现所有子任务时,系统获得最大加速比;(2)若选择合适的子任务(如v2、v3等)在CPU上实现,对加速比的影响可以很小,从而可以节省FPGA的硬件资源,增加系统的实用性。
4.3.3 以单位资源加速比作为适应度函数
查找表LUT(Look-Up-Table)是用于衡量FPGA资源使用情况的常用资源单位。令Rall表示LT码编码器使用的LUT资源总数,则单位资源加速比为Sp/Rall。

Table 1 Parameters setting of LT codes表1 LT码参数设置

Table 2 Sub-task partitioning of LT codes’ encoding表2 LT码编码子任务划分
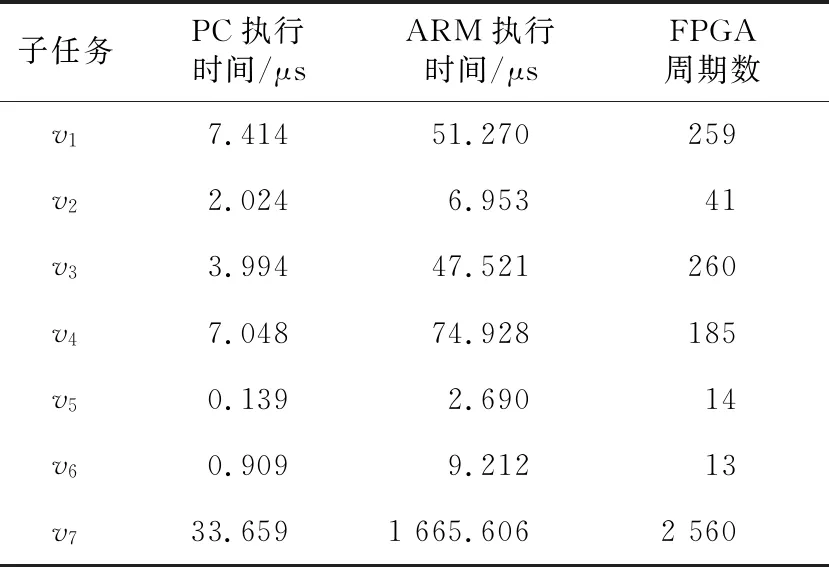
Table 3 Execution time of sub-task of LT codes’ encoding on various cores表3 LT码编码子任务在不同处理核心上的执行时间

Table 4 Feasible solutions of mapping problem with speedup as fitness function表4 以加速比为适应度函数的映射问题可行解

Table 5 LUT usage of sub-task of LT codes’ encoding表5 LT码编码子任务LUT使用情况

Table 6 Feasible solutions of mapping problem with speedup per resource unit as fitness function表6 以单位资源加速比为适应度函数的映射问题可行解

Table 7 Comparison of encoding time表7 编码时间对比 ms

Table 8 Comparison of resource consumption表8 资源消耗对比
利用Vivado综合工具估算LT码编码子任务的LUT使用量,如表5所示。
令单位资源加速比为适应度函数,设种群大小为1 000,求得在迭代100次后的种群当中,加速比Sp>1的所有可行解如表6所示。
根据表6所示的映射结果及其对应的单位资源加速比,结合式(9)对染色体的定义,可知仅在FPGA上实现子任务时,LT码编码器获得最大的单位资源加速比。
4.4 编码器架构设计
为充分利用XILINX ZYNQ异构平台中ARM和FPGA的通信带宽,本文基于CDMA(Central DMA)和共享存储架构设计ARM与FPGA的互连结构,如图4所示。

Figure 4 High performance interconnect between ARM and FPGA图4 ARM与FPGA高速互连结构
在图4中,CPU通过AXI-Lite接口实现对LT码编码器的控制,并通过2个共享的Block RAM存储器实现与LT码编码器的数据交互。
对于染色体(2,2,2,2,2,2,2)对应的映射方案(即在FPGA上实现全部子任务),设计其对应的LT码编码器架构,如图5所示。其中,模块左上角的编号代表子任务序号,虚线框内的模块属于同一子任务。LT码编码器基于线性反馈移位寄存器LFSR(Linear Feedback Shift Register),为度生成器和不重复随机数发生器提供伪随机数。

Figure 5 LT codes’ encoder architecture corresponding to chromosome (2,2,2,2,2,2,2)图5 染色体(2,2,2,2,2,2,2)对应的LT码编码器架构
对于部分子任务在FPGA上实现的映射方案,增加Block RAM读写控制逻辑,以实现软硬件数据交互。以染色体(1,1,1,2,1,1,2)为例,设计其对应的LT码编码器架构如图6所示。

Figure 6 LT codes’ encoder architecture corresponding to chromosome (1,1,1,2,1,1,2)图6 染色体(1,1,1,2,1,1,2)对应的LT码编码器架构
5 实验及其结果分析
5.1 数据量化
为了避免FPGA实现浮点运算造成大量逻辑资源消耗,本文分别尝试了8 bit量化和16 bit量化2种常用的量化策略来计算RSD,并评估2种量化策略对译码率的影响。结果如图7所示。
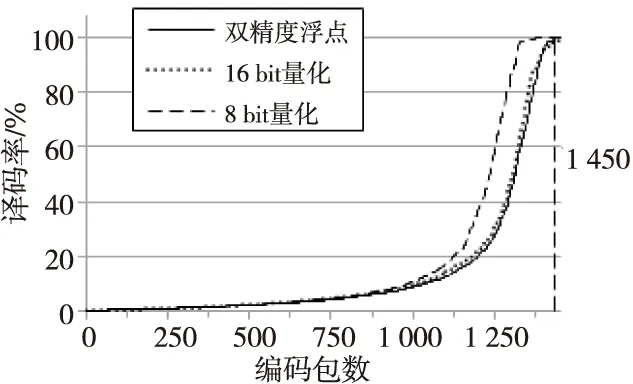
Figure 7 Influence of different quantization strategies on LT codes’ decode ratio图7 不同量化策略对译码率的影响
由图7可知,采用8 bit量化策略计算RSD,其译码率明显高于16 bit量化策略和无量化策略的。这是因为8 bit量化使得RSD损失了较多的精度,使得大量高度数编码包出现概率降为0,理论上对译码成功率影响较大。采用16 bit量化策略计算RSD,其译码率接近无量化RSD,说明16 bit量化造成的精度损失较小,对译码成功率的影响也较小。为了使LT译码的成功率得到保障,本文使用16 bit量化策略来计算RSD。
5.2 映射方案对比分析
本文4.3节基于HSoC模型进行推演,首先求得具有最高理论加速比的染色体是(2,2,2,2,2,2,2),其对应的映射方案是在FPGA上实现LT码编码的全部子任务;然后求得具有最高理论单位资源加速比的染色体是(1,1,1,1,1,1,2),其对应的映射方案是在ARM上实现子任务v1~v6,在FPGA上实现子任务v7。本节将对这2个染色体所对应的映射方案进行对比分析。
首先利用PC机(CPU 为Intel i7-4600U,内存为8 GB DDR3)实现的LT码编码器生成1 450个编码包,测量其编码时间;然后在XILINX Zybo硬件平台上实现染色体(2,2,2,2,2,2,2)和(1,1,1,1,1,1,2)所对应的LT码编码器,分别测量其生成1 450个编码包的时间,实验结果如表7所示。
由表7可知,染色体(2,2,2,2,2,2,2)和染色体(1,1,1,1,1,1,2)所对应的LT码编码器的加速比分别为1.153和1.293。
经过测试,ARM与FPGA通过CDMA进行数据交互的实际带宽在450~550 MB/s,因此,2种映射方案的实际加速比均比理论值低。其中,在FPGA上实现所有子任务时,ARM与FPGA之间存在多次数据交互,因此染色体(2,2,2,2,2,2,2)所对应编码器的实际加速比与理论值差距较大。该实验结果表明通信带宽容易成为性能瓶颈。
需要注意的是,从硬件架构设计的角度看,染色体(2,2,2,2,2,2,2)所对应的LT码编码器仍有较大优化空间。一般地,可以使用乒乓存储、流水线等技术提高LT码编码器的性能,从而获得更高的加速比,但设计复杂度和成本也会随之增加。
此外,在Vivado工具上分别实现染色体(2,2,2,2,2,2,2)和(1,1,1,1,1,1,2)所对应的LT码编码器,记录其实现后的LUT资源使用量,如表8所示。
由表8可知,使用FPGA实现所有子任务时,硬件平台只剩余23.19%的LUT资源。此时,若实际应用系统存在其他功能需要利用FPGA加速,则只能换用更高级的硬件平台,降低了硬件平台的实用性,增加了系统成本。当只使用FPGA实现数据包的异或运算时,不仅能获得一定的加速比,还能为应用系统节省大量的FPGA资源,增加了应用系统设计的灵活性,降低了应用系统的成本。
5.3 实验结论
进行子任务分配时,利用本文模型进行推演,具有一定指导意义。此外,虽然利用异构多核技术可获得一定加速比,但进行子任务分配时,不仅需要在资源使用率和加速比之间取得平衡,还要考虑带宽的影响。比如在带宽的影响下,当只使用FPGA实现异或运算时,不仅能获得一定加速比,还能为应用系统节省大量的FPGA资源,增加了应用系统设计的灵活性,降低了应用系统的成本。
在实际开发过程中,设计人员可根据实际需求,选择不同的LT码子任务映射方案,以更好地满足应用需求。
6 结束语
本文对异构多核SoC进行了建模分析,将LT码编码在异构多核SoC上的实现问题转变为异构多核SoC上的任务映射问题,并给出了基于遗传算法的解决方法。此外,本文基于异构多核SoC上的LT码编码子任务映射问题求解结果,在XILINX ZYNQ-7000异构多核平台上实现了LT码编码器。实验结果表明,本文所设计的LT码编码器能够满足不同的性能和资源需求,增加了硬件平台的实用性和应用系统设计的灵活性。
未来的研究方向有:(1)研究不同任务划分粒度,以及核间数据通信带宽对映射结果的影响;(2)研究包含多个算法的应用系统在异构多核SoC上的映射问题及其优化方法。
