基于AO算法的数据流频繁项集挖掘*
2021-01-06耿小海朱璐伟许萌萌
文 凯,耿小海,朱璐伟,许萌萌
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065;3.重庆信科设计有限公司,重庆 401121)
1 引言
互联网的快速发展和5G的到来,使得数据发生了爆炸性的增长,而现在绝大多数的数据都是以流的形式出现,数据流[1]的应用已经涉及到各方各面,随着时代不断进步,人工智能、模式识别中的搜索算法和建模技术也在数据流挖掘中得到了广泛应用,并且吸纳了多个领域中的优秀知识和思想[2]。大数据从批处理,再到现在的实时处理,以及混合两者的处理,经过了3次技术革新[3]。数据流频繁项集挖掘已成为当前数据挖掘中的一项重要任务,并随着大数据实时分析的发展变得越来越重要。
相较于国内,国外在数据流频繁项集挖掘方面的研究开始得比较早。在数据流处理模型中主要有3种不同的窗口模型[4]:界标窗口、衰减窗口和滑动窗口,目前使用最多的是滑动窗口模型。滑动窗口模型由Mozafari等[5]引入,并且提出了SWIM(Sliding Window Incremetal Miner)算法,它能够根据数据流调节滑动窗口的大小,因此算法具有良好的自适应性和扩展性。基于 Hadoop平台的并行化框架和固定的滑动窗口,CanTree-GTree算法[6]进行数据流频繁项集挖掘在滑动窗口满事务后,新的数据流流入,旧事务流出;文献[7]中的SysTree(Systolic Tree)算法采用2种窗口进行数据流频繁项集挖掘,该算法基于树结构,在挖掘频繁项集时分别使用了滑动窗口和界标窗口;寇香霞等[8]提出的FIUT-Stream算法,用位图压缩数据流,提高了空间效率,但采用FIUT结构挖掘频繁项集时会产生大量候选项集,构造FIU-tree也消耗大量内存。
针对高效用模式的挖掘,SHU-Growth算法[9]使用滑动窗口进行挖掘,该算法根据类FP-tree(Frequent Pattern-tree)结构来存储高效用项集,降低了候选项集的空间消耗;HAUPM(High Average Utility Pattern Mining)算法[10]只关注新近事务中的高效用模式,结合衰减窗口模型,挖掘平均高效用模式,并且采用新的衰减平均效用树结构来提高挖掘效率。
现在的应用有许多不仅仅是单数据流,学者们也在研究多数据流挖掘算法,例如王鑫等[11]提出的MCMD-Stream(Mining Collaborative frequent itemsets in Multiple Data Stream),采用多个数据流同时挖掘,效率显著增加;Guo等[12]结合目前诸多的应用提出的H-Stream(Hybrid-Stream)算法,也是对多数据流进行挖掘。
针对现有数据流频繁项集挖掘算法挖掘频繁项集时间效率不高等问题,本文提出一种高效挖掘数据流频繁项集的AO算法,提高了FIUT-Stream算法的挖掘效率。本文的AO算法在挖掘频繁项集的过程中,采用超集检测的策略,极大地过滤掉非频繁项集。实验表明,改进算法在时间效率的提升上比较明显。
2 相关概念
定义1设项目集合I={I1,I2,I3,…,Im},对于该项目集中的每一个元素,称之为项,若一个集合中所有元素均包含于I中,则该集合称为项集,包含k个元素的项集称为k-项集。
定义2数据流DS(Data Stream)是由连续不断到达的事务数据组成的有序序列DS={T1,T2,…}。其中Ti(i=1,2,3,…)称为事务,数据流中的每个事务Ti满足Ti⊆I。
定义3若minsup为用户设定的最小支持度阈值,对于任意项集X,若项集X的出现频率sup(X)≥minsup,则称项集X为频繁项集。
定义4将数据流按w大小等分成若干块,每一块对应一个基本窗口,每一个基本窗口有相同的事务数,这些事务数个数|w|即为基本窗口的大小。
性质1(超集检测) 对于任意项集X和Y,且X⊆Y,若判定X为非频繁项集,则Y也一定不会是频繁项集。
3 频繁项集挖掘
3.1 窗口更新
FIUT-Stream算法在数据流中挖掘频繁项集时,采用的是滑动窗口的方式。该算法首先将数据流压缩到FIUT结构的位表中,然后以滑动窗口的方式对位表中的数据进行更新,进而对FIUT中的数据聚类得到所有的k-项集,然后以构建FP-tree的方式构建FIU-tree,根据FIU-tree来挖掘出所有的频繁项集。
与其它数据流频繁项集挖掘算法相比,FIUT-Stream算法采用一种位表进行数据压缩,极大地降低了内存消耗,从而极大提高了空间效率;从FIUT-Stream算法的构建可以看出,该算法需要2个结构进行数据流的存储,一个是位表,一个是项表,这就导致在处理大量数据时,空间消耗极大,并且该算法采用类FP-tree算法进行频繁项集挖掘的过程中,会产生大量候选项集,必然对时间效率产生一定的影响,随着数据的增多,这个影响就更明显;而且该算法在更新数据流时,需要随着数据流的到来同步更新支持度,这进一步降低了时间效率。
本文提出的改进算法在进行数据压缩时,只采用一个位表,在一定程度上提高了空间效率,在频繁项集挖掘的时候,直接通过位表采用数学中的与运算(And Operation)就可以得到所有的频繁项集;另外,在支持度计算时,简单使用加减计算即可完成,减少了聚类操作,减少了在数据流频繁项集挖掘时的FIU-tree结构的构建,极大提高了效率。具体思路如下:如表1所示为本文所用到的数据流,分装在4个Pane中,每个Pane包含3个事务,即代表一个窗口。在FIUT-Stream算法中,新的数据到来,按表格箭头所指方向进行流动,新簇流入,旧簇流出,以此更新数据。

Table 1 Dataset表1 数据集
表2是对数据集3个窗口的数据压缩得到的位表,且在位表最后一行进行项支持度的计算,该方法减少了项表的构建,且支持度计算在位表最后一行完成,极大提高了效率。其中,Tid代表事务编号。
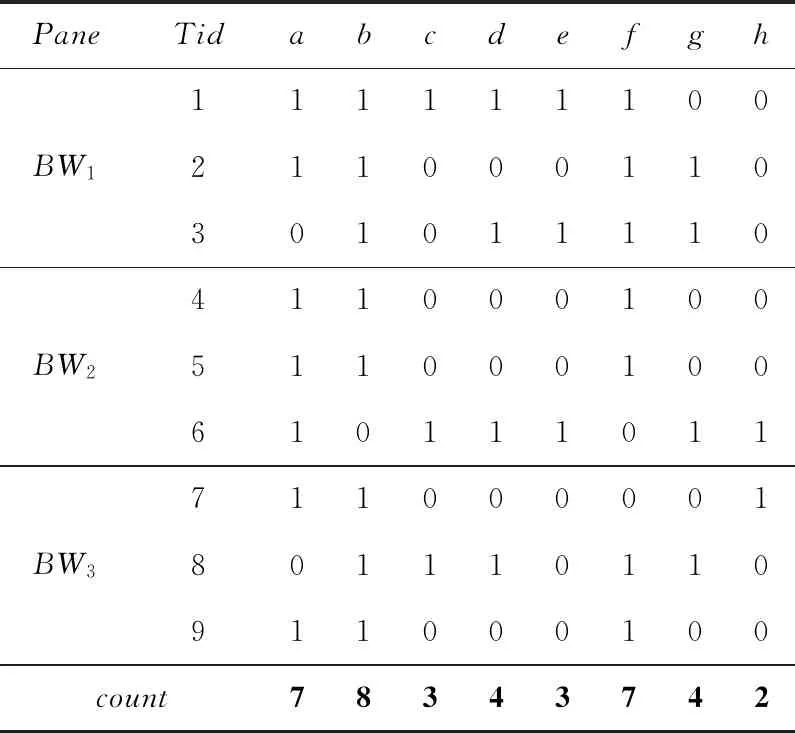
Table 2 Compressed bit table表2 压缩位表
FIUT-Stream算法是以一种滑动窗口的形式更新窗口,新簇流入,旧簇流出,数据更新需要所有的数据流动,一定程度上降低了效率。本文采用一种取余[13]的方式进行窗口更新,每次只需要对一个事务进行流动即可完成数据更新。具体方法是:当窗口中数据已满,对于新来的事务Ti,使用i%n(n为当前窗口中的所有事务数)取余将该事务插入到对应的窗口位置实现数据更新,用这种方式进行数据流更新只需要对特定事务进行操作,而不需像FIUT-Stream算法那样,对窗口中的所有数据进行操作,复杂度从O(m)降到了O(1),使得挖掘效率得到极大提高。如表3是用取余将BW4中的数据更新得到的更新表。

Table 3 Updated data stream compression bit table表3 更新的数据流压缩位表
3.2 支持度更新
在FIUT-Stream算法中,支持度的更新是要对整个位表中的数据进行更新,当数据流到来,滑动窗口滑动之后,位表就发生了变化,在进行支持度更新时需要对所有窗口中的数据进行计算,而本文算法只需要在进行窗口取余更新的时候计算当前事务,然后计算支持度即可。如计算项a的支持度,当窗口中新插入事务T10,根据取余更新的方式,用T10替换位表中的T1事务,此时将压缩成位表的T10与T1相减,然后将相减的结果与count相加,即可得到数据更新后所有项的支持度,如表3是按此方法更新支持度得到的更新位表,这种方法相较于FIUT-Stream算法的支持度更新有了进一步提升。
3.3 频繁项集挖掘算法
当数据流到来时,再经过一次数据扫描压缩之后得到表3,然后根据表3中的支持度计数count与最小支持度阈值minsup进行比较即可得到所有的频繁1-项集,然后根据删除非频繁1-项集后的压缩位表,结合性质1,挖掘所有的频繁k-项集(k≥2)。设定最小支持度阈值minsup=4,根据表3中的支持度计数count,与最小支持度阈值minsup比较得到所有的频繁1-项集为:a、b、d、f。删除所有的非频繁1-项集之后,得到表4。

Table 4 Frequent 1-itemset table表4 频繁1-项集位表
挖掘出所有的频繁1-项集之后,就可以根据频繁1-项集进行频繁2-项集的挖掘。本文采用数学中的And Operation进行频繁k-项集的挖掘,如要挖掘出所有的频繁2-项集,只需要对进行挖掘的2-项集的项所在的列相与,相与结果中1的个数即为该2-项集的支持度计数,再和minsup进行比较,不小于minsup即为频繁项集,按照此方法即可挖掘出所有的频繁2-项集。
根据表4,在对2-项集bd进行频繁项集判断时,对这2项所在的列进行相与,得到b、d在事务T1、T2、T3、T8中相与结果为1,所以得到2-项集bd的支持度为4,等于最小支持度计数,所以2-项集bd为一个频繁2-项集;同时,b、d项在T1、T2、T3、T8事务中均存在,也就验证了该方法的正确性。同理得到2-项集df支持度为2,所以2-项集df为非频繁项集。
在进行频繁k-项集挖掘时,本文首先会根据非频繁(k-1)-项集进行超集检测,利用非频繁项集的超集也是非频繁项集来提高挖掘效率。在本文算法中,会记录所有非频繁(k-1)-项集,然后在k-项集挖掘的时候,判断k-项集是否是非频繁(k-1)-项集的超集,如果是,则不再对其进行频繁项集的判断;如果不是,对其计算支持度,判断其是否为频繁项集。在本例中,根据上文得到df为非频繁项集,所以记录此项集,在进行3-项集adf、bdf的挖掘时,首先通过超集检测判定这2个项集均是项集df的超集,所以这2个项集不可能是频繁项集,不再对其进行下一步的判断。根据表4,得到这2个项集支持度分别为:adf:1,bdf:2,均小于minsup,所以它们都不是频繁项集,可以验证该性质的正确性。该性质在庞大数据流中挖掘频繁项集时能极大地提高效率,减少需要挖掘的候选项集数据量。

算法1频繁k-项集挖掘(k≥2)
输入:频繁1-项集压缩位表D。
输出:所有频繁项集。
1.For所有i维组合
2. {
3.For所有非频繁(i-1)-项集
4. {
5.If(i-项集是非频繁(i-1)-项集的超集
6. 删除该i-项集;
7.Else
8.count=D中的i-项集相与结果之和;
9.EndIf
10.Ifcount≥minsup
11. 记录该项集为频繁项集;
12.Else
13. 记录该项集为非频繁i-项集,并删除非频繁(i-1)-项集;
14.EndIf
15. }EndFor
16. 输出所有频繁项集;
17. }EndFor
经过算法1和利用超集检测性质,就可以挖掘出所有的频繁项集。本文算法相较于FIUT-Stream算法在时间和空间效率上有了很大程度的提升,本文算法只需构建FIUT中的1个位表,频繁项集的挖掘不需要通过创建FIU-tree结构来实现,直接通过位表进行数学中的简单And Operation即可得到所有项集的支持度计数,并以此挖掘出所有的频繁项集,这更能满足如今对数据流频繁项集挖掘效率要求极高的需求。
在各种监控视频遍布的今天,可以利用这种高效的数据流频繁项集挖掘方式进行恐怖分子的搜查,对在一个时间段同一个地方频繁出现的人可以给予很大的怀疑度,从而给警方缩小排查范围,在一定程度上为破案提供帮助;另外,现在电商行业的飞速发展,促使网上数据流激增,对用户网上浏览商品的数据流进行分析,可以对用户进行个性化推荐,增加用户的购买量;或者根据天气的实时变化趋势图,做出天气预报,随着信息化社会的发展,数据流频繁项集挖掘的应用会变得越来越广泛。
4 实验结果分析
本文实验采用Java语言进行实验程序的编写,实验环境为Intel(R) Core(TM) i7-6700 CPU @ 3.40 GHz,8 GB内存,Windows 10的64位操作系统。实验采用T10I4D100K数据集和真实数据集KOSARAK,T10I4D100K数据集是由IBM数据生成器生成的模拟数据集,该数据集包含了100 000个事务,总共870个项目,属于相对稀疏的数据集;真实数据集KOSARAK是一种实时的点击流数据,来自于匈牙利一家在线新闻门户网站,包含990 002个事务,共36 841个项目,属于相对稠密的数据集。采用稠密和稀疏2种数据集能更好地体现算法的优越性。
首先比较了SysTree算法、FIUT-Stream算法和本文改进算法在稀疏数据集T10I4D100K和稠密数据集KOSARAK上的时间开销。分别设定T10I4D100K数据集的支持度为(0.5,0.1,0.15,0.2,0.25),滑动窗口大小为2;KOSARAK数据集的支持度为(0.75,0.8,0.85,0.9,0.95),滑动窗口大小为4,得到如图1和图2所示的时间消耗对比图。
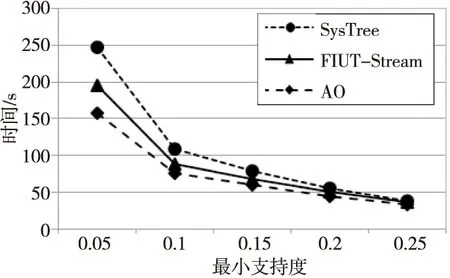
Figure 1 Comparison of time consumption on T10I4D100K dataset 图1 数据集T10I4D100K上的时间消耗对比

Figure 2 Comparison of time consumption on KOSARAK dataset 图2 数据集KOSARAK上的时间消耗对比
如图1和图2所示分别是这几种算法在数据集T10I4D100K和数据集KOSARAK上的时间消耗对比图,从图中可以看出,本文的改进算法在稀疏数据集和稠密数据集上的时间性能均优于另外2种算法的,并且随着支持度的降低,优势更为明显;另外,在稠密数据集上的优势更为明显,这是因为稠密数据集的项目数较多,本文改进算法在挖掘频繁项集时采用And Operation,能更高效地挖掘出所有的频繁项集。
接下来进行空间消耗的对比,比较3种算法的空间消耗性能。设定稀疏数据集T10I4D100K的滑动窗口大小分别为4,6,8,10,设定稠密数据集KOSARAK的滑动窗口大小分别为5,6,7,8,得到如图3和图4所示的空间消耗对比图。
从图3和图4中可以看出,本文的改进算法在稀疏数据集和稠密数据集上的表现均优于另外2种算法的,并且随着Pane大小增加,这种优势更明显。对比图3和图4发现,在稠密数据集KOSARAK上,本文改进算法的优势更为突出。这是因为本文算法采用了超集检测策略,首先通过超集检测减少了大量候选项集,这样就可以提前删除非频繁项集,提高了空间效率。

Figure 3 Comparison of space consumption on T10I4D100K dataset 图3 数据集T10I4D100K上的空间消耗对比

Figure 4 Comparison of space consumption on KOSARAK dataset 图4 数据集KOSARAK上的空间消耗对比
5 结束语
本文主要针对FIUT-Stream算法在挖掘频繁项集的时候需要构建FIU-tree结构增加了空间消耗,在频繁项集挖掘时通过类FP-tree遍历使得挖掘效率不高的问题进行改进,改进算法在一定程度上提高了时间和空间效率。本文首先在进行数据流处理时采用高效的位表进行压缩,然后用窗口的思想将数据流等块分割,在窗口中数据更新时只需对窗口中数据进行简单加减运算即可计算支持度,最后采用简单高效的And Operation即可挖掘出所有的频繁项集,同时在挖掘过程中采用超集检测减少不必要项集的挖掘,在时间和空间效率上都比原算法高,适合当前大数据环境下的海量数据流挖掘。
