基于图像处理与深度学习方法的棉纤维梳理过程纤维检测识别技术
2021-01-05邵金鑫张宝昌曹继鹏
邵金鑫,张宝昌,2,曹继鹏
(1. 北京航空航天大学 自动化科学与电气工程学院,北京 100191; 2. 深圳航天科技创新研究院,广东 深圳 518057; 3. 辽东学院 辽宁省功能纺织材料重点实验室,辽宁 丹东 118003)
梳棉机高速梳理过程中的原理细节的研究是棉纺织领域的盲点,用可视化和图像分析技术重新审视和分析纤维在梳棉机梳理过程中的运动,对梳理盖板、纤维转移以及均匀混合、固定盖板梳理作用、棉网清洁器、针布类型等方面进行研究,可提供新的视角和方法,也为实现纤维梳理要求,减少纤维损伤和提高纤维转移率,优化梳理组件提供新的直接方式。
由于梳理速度快(刺辊速度达1 400 r/min[1]),棉纤维线密度极小[2],梳棉机的工作条件不允许破坏(梳理过程中无法在设备内架设其他装置),传统的光电检测方法不适用于在高速运转中的梳棉机内的棉纤维检测[3]。瑞士的乌斯特公司与澳大利亚的BSC电子公司都曾开发过基于光电传感和图像处理技术的纤维检测试验仪,但内部实现原理并未公开,且需要将试样在特定的检测条件下送到实验仪器中,很明显这些已有设备对于与梳棉机结合使用的场景并不适用[2]。对于这一问题无论是从梳理设备内部纤维信号的获取,还是后续的对信号进行检测算法的设计,都存在很大的挑战性。
为解决高速运转的梳棉机内部棉纤维信号无法采集这一问题,本文使用高速摄像结合图像处理算法进行棉纤维的检测与识别。首先对梳棉机漏底部分进行开口,通过架设高速摄像机进行内部纤维运动过程的拍摄,得到一系列连续的梳理过程中混合有刺辊、光斑以及微弱纤维信号的检测图像;然后使用传统的图像处理方法,以及近年来较为流行的深度学习方法对检测图像进行一系列的工业流程处理,分别使用检测流程与生成模型对棉纤维进行检测与识别。
1 基本实验数据采集及处理流程说明
1.1 基本实验数据采集
本文实验采用胶南永佳纺织机械制造有限公司生产的A186F型梳棉机进行实验,通过在梳棉机漏底开2.7 cm×2.7 cm的观察口,使用加拿大Mega Speed Corp.公司生产的75KS2C3104型高速摄像机拍摄梳棉机工作状态下梳理纤维的视频。拍摄频率为6 000帧/s,得到一系列连续运动的图像,图像分辨率为502像素×504像素,示例图片如图 1 所示。

图1 样本集示例图片Fig.1 Sample image of dataset. (a) Sample 1; (b) Sample 2
由图1可以看出,拍摄图像底色全黑并带有强烈的干扰模式,刺辊反光形成的针点形成了明显的网状结构,在这些针点之间存在着模式较为明显的刺辊反射的光斑,构成了整个图像的主要背景信息。在强烈的干扰模式下,依稀可在无干扰的空白部分看出稀疏的不太明显的纤维信息。很明显,在这种强干扰模式下,如果不经过处理,即使是人眼也很难对图像中的纱线进行有效地识别。
1.2 流程说明
整体检测流程如图2所示。
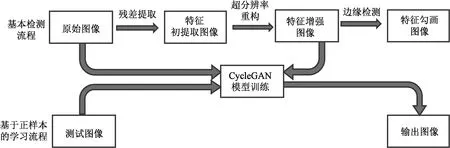
图2 检测流程图Fig.2 Detection process
对于原始图像,首先通过图像去噪算法得到去除纤维信息而只保留针点与光斑的平滑图像,然后通过图像做差得到残差图像,即为棉纤维特征初提取图像;针对特征初提取图像纤维边界模糊的特点,使用超分辨率重构算法增加图像的梯度,便于人眼的进一步观察以及计算机边缘识别;最后使用合理的纤维边缘勾画算法对纤维边缘进行勾画,得到最终的处理结果。
之后尝试使用生成模型进行棉纤维特征信息提取工作。通过500张原始图像以及500张经过特征增强的处理图像作为CycleGAN模型训练的输入与输出,使用新的测试集图像测试生成模型的生成效果。
2 基本检测流程
2.1 特征初步提取
根据图1所示图像数据特点,可发现刺辊的光斑和针点信息较强并具有明显的分布规律,而纤维的信息较弱,并较为稀疏。可将光斑和针点的信息作为图像本身要提取的模式特征,将纤维作为噪声信息,把勾画纤维特征的问题转化为一个提取去噪残差的图像去噪问题,则要提取的特征为
If=Ip-Ic
(1)
式(1)可理解为通过原始图像(Ip)减去平滑后的图像(Ic)得到残差图像,即为要提取的纤维特征图像(If)。简单来说,对于一个往干净图像中加噪声的过程,是一个有定解的稳定问题,但对于去噪这个逆问题,则是一个非存在唯一稳定解的问题[4],类似于超定方程的求解过程,没有严格的限定条件就不能得到稳定的解。因此,一般来说,去噪的效果更多的取决于对噪声性质的假设程度和对图像本身性质结构的估计。对于每种去噪方法,都有各自的估计特点,而对于这样的实际工业问题来说,去噪残差提取效果无法用真值(正样本)来进行比对,只能通过人眼的观察进行判断。对于这一问题,在测试了主要的去噪算法之后,最终选定多级小波卷积神经网络(MWCNN)方法进行去噪残差的提取[5],其网络结构如图 3 所示。
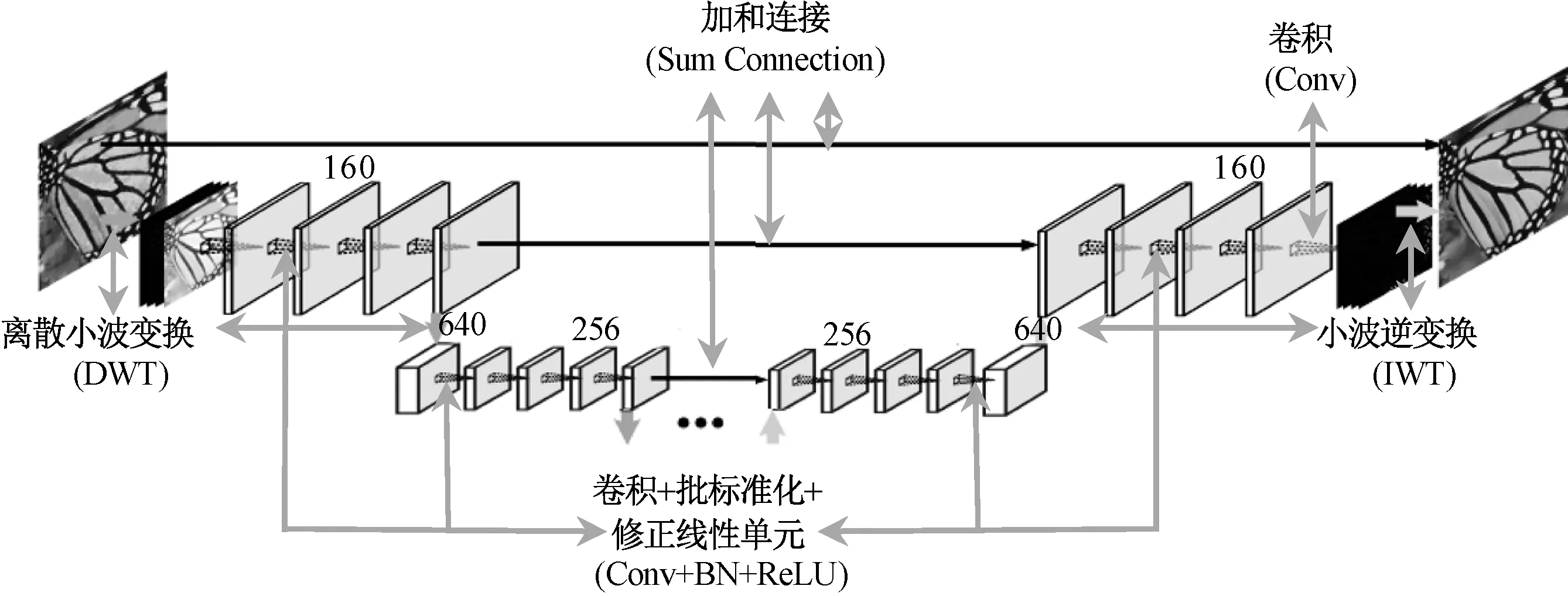
图3 多级小波卷积神经网络的网络结构示意图Fig.3 Network structure of MWCNN
该结构的主要特点为在语义分割网络U-Net训练框架上,引入了小波变换及逆变换代替原有的卷积与反卷积操作进行图像尺度的变换,属于传统图像处理方法与深度学习方法的融合,可减少连接形成的子网络的特征图大小,以便在计算效率以及感受野(receptive field)大小间得到更好的权衡结果。
使用前期实验预训练模型,即使用200张伯克利分割数据集(BSD)、800张DIV2K数据集、4 744张滑铁卢探索数据集(WED)在高斯噪声标准差水平为15、25、50的条件下预训练图像去噪重构模型。最终经过不断测试,认为预估计噪声标准差水平为15时去噪残差提取肉眼评价效果最好。当估计噪声标准差水平为15时,所得到的残差提取结果如图4所示。

图4 示例1和2初步提取特征的提取效果Fig.4 Effect of preliminary feature extraction of sample 1 (a) and sample 2 (b)
从图4可看出:残差中针点和光斑信息基本都得到了去除,而纤维信息保留较为完好,且有轻微的平滑效果;另外还有一些图像本身带有的模糊效果影响观察。总体而言,纤维的特征已基本得到了提取,但由于平滑效果和模糊块的影响,还达不到能进行边界勾画的效果。
2.2 特征增强
很明显,对于上述初步提取得到的信息图像,需要进行图像增强以便进行特征的边缘勾画操作。如果图像的梯度变化较为平滑,则图像较为模糊;而如果图像的梯度变化较为剧烈,则图像较为清晰[6]。从某种程度上来说,超分辨率重构算法是一种增加图像梯度使图像边缘更清晰的操作,其公认的定义为利用图像特征的先验知识,在不改变拍摄条件的情况下,利用低分辨率图像合成出细节信息更丰富的图像的过程[7],从而更好地作出轮廓的提取。在这一思路下,使用深度卷积超分辨率重构网络(SRCNN)的超分辨率重构方法[8]进行效果重构,该网络结构如图5所示。
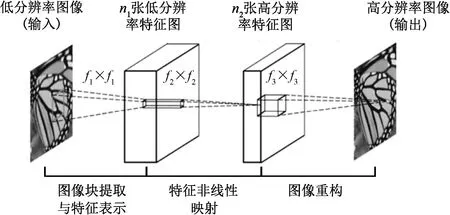
图5 深度卷积超分辨率重构网络结构示意图Fig.5 Network structure of image super-resolution using deep convolutional networks
深度卷积超分辨率重构网络是深度学习方法在图像超分辨率重构领域应用的开创性方法,通过3层卷积层的方法模拟了超分辨率重构中的稀疏编码方法[9]:通过第1层c×f1×f1×n1大小的卷积核提取输入图像的图像块,映射到n1张低分辨率特征中,相当于稀疏编码方法中将图像块映射到低分辨率字典中;再通过第2层n1×f2×f2×n2大小的卷积核将n1张低分辨率特征图映射到n2张高分辨率特征图,相当于通过稀疏编码中的字典学习的方法找到图像块所对应的高分辨率字典;最后通过n2×f3×f3×c大小的卷积核将n2张高分辨率特征图卷积成高分辨率的c通道原始图像,相当于字典学习中通过高分辨率字典进行超分辨率图像重建。
使用文献[8]预训练模型,即使用从ImageNet数据集中选择的395 909张图片作为训练数据,所选取的卷积参数为n1=64、n2=32、f1=9、f2=5、f3=5,使用单通道图像(灰度)即c=1进行超分辨率模型训练。测试使用图像超分辨率缩放倍数即下采样因子(upscaling factor)x=3,对图4中初步提取特征的提取效果图进行超分辨率重构时,可得到如图6所示的结果。

图6 示例图片1和2的超分辨率重构后的 纤维检测效果Fig.6 Effect of fiber detection after super-resolution reconstruction of sample 1 (a) and sample 2 (b)
由图6可以看出,相比较于信息初步提取得到的纤维检测效果,超分辨率重构得到的纤维边缘更加清晰,更易与背景进行分离,通过这一步得到的结果更易进行下一步纤维特征的勾画。
2.3 特征勾画
超分辨率重构后纤维的边界特征虽然被增强,但本身的模糊效果和噪声水平同样被增强,这是由数据集本身的特点决定的,因此,使用简单的基于图像梯度的勾画方法(如以索贝尔、坎尼算子为基础的梯度勾画方法[10],这种勾画方法往往有固定的梯度方向)很难得到有效的结果。一般的图像边缘检测算法更适合于无噪声、无扰动、边缘清晰的理想图像,对于这种强噪声状态下纤维信号的检测大都得不到理想的结果,因此,本文使用一种利用各方向梯度差值进行强噪声条件下多尺度边缘检测与纤维增强的方法[11],如果纤维尺度较大则做边缘检测,如果尺度较小则相当于纤维增强。算法流程为:首先以多个长度和方向计算方向梯度;然后使用多尺度自适应阈值检测重要响应;最后通过递归决策过程识别相干边缘。具体实现原理可简要表示为以下过程。
1)将图像分为3像素×3像素的小块,分别计算像素分布的最小标准差。统计整个图像最小标准差的分布,取主要值来估计图像的噪声水平,为N(0,σ2),即代表整个图像的噪声水平满足均值为0,标准差为σ的正态分布。
2)在上述噪声水平的估计条件下,w×l大小的面积内由噪声产生的梯度响应可估计为
(2)
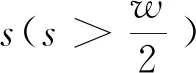
3)在一定近似条件下推导认为,在整体像素为N时,长为l、宽为w的非噪声引起的梯度响应的阈值应为
(3)
(4)
式中,F为积分。I(x,y)表示二维图像域中图像强度的连续函数,所以γ、δ都是代表长宽积分的变量。F表示为如下形式:
(5)

图8 CycleGAN的模型结构Fig.8 CycleGAN′s model structure
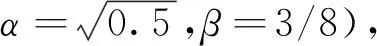
对图6采用以上算法的勾画结果如图7所示,其中深色部分为勾画后的纤维结果。可以看出,勾画结果满足了在强噪声条件和边界不清晰情况下对纤维边缘特征的提取与增强,具有很强的说服力,缺点是该方法对计算机的内存和计算能力要求较高,在Intel Core i9-9900X,NVIDIA GEFORCE RTX 2080 Ti,64 GB RAM的计算机条件下,计算1张图片需要十几分钟。

图7 示例图片1和2勾画后的效果图Fig.7 Sketched result sample 1 (a) and sample 2 (b)
3 通过生成模型进行纤维特征提取
目前有很多生成模型用作图像域之间的映射转换,或者说图像翻译,比如较为流行的生成对抗网络(GAN)[12]。很多图像到图像的问题都可归结到图像翻译的范围中来,比如分割、风格迁移等。目前为止,使用生成模型进行图像域转换得到的生成结果都好于使用深度神经网络进行监督训练得到的结果,且由于生成模型是一种半监督或者无监督的模型,使用生成模型不需要进行大量的数据标注与匹配;为此,本文使用生成模型中的循环生成对抗网络(CycleGAN)模型进行图像域之间的转换[15]。相比于普通的GAN模型,CycleGAN模型引入了自然语言处理中2种语言循环翻译以检测翻译模型效果的思想,通过建立正反向2组生成器(generator)和判别器(discriminitor)进行循环生成来训练更好的生成模型,生成器和判别器都使用类似于U-Net的卷积与转置卷积结构进行训练,从而实现2种图像域之间的转换,因此,CycleGAN的优势在于不需要严格的图像像素对应关系,即可实现图像域的转换,生成模型整体结构如图 8 所示。
优化的目标函数和传统的GAN网络类似,优化目标为生成器的目标函数应尽可能小,判别器的目标函数应尽可能大。定义数据域A、B的数据集合满足如下数据样本分布规律:
(6)
式中2个图像域A、B中的图像个体用小写字母a、b表示,图像域中分别有n、m个个体,二图像域中的数据满足pdata(a)、pdata(b)规律的分布,其中图像域转换的生成器与判别器的表示法为
GAB:图像域A→图像域B的生成器;GBA:图像域B→图像域A的生成器;DA:图像域A中图像a与生成图像GBA(b)的判别器;DB:图像域B中图像b与生成图像GAB(a)的判别器。
将循环生成对抗网络看作2个独立的生成对抗网络的组合,根据生成对抗网络的定义[12],可将单方向生成对抗网络的损失函数写成如下表达式,如只取生成器GAB,判别器DB为
LGAN(GAB,DB,A,B)=Eb~pdata(b)[ln(DB(B))]+
Ea~pdata(a)[ln(1-DB(GAB(A)))]
(7)
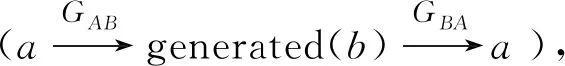
Lcyc(GAB,GBA)=Ea~pdata(a)[‖GBA(GAB(a))-a‖1]+
Eb~pdata(b)[‖GAB(GBA(b))-b‖1]
(8)
则总体的损失函数为
L(GAB,GBA,DA,DB)=LGAN(GAB,DB,A,B)+
LGAN(GBA,DA,B,A)+λLcyc(GAB,GBA)
(9)
式中,λ为控制参数。
要求解的生成器模型可表示为
(10)
使用图2中的采集数据和图6中超分辨率重构后的数据各500张分别作为图像域A和图像域B中的原始数据,进行标准的CycleGAN模型训练,训练约40 000个迭代(epoch)时模型趋于收敛。
使用新的测试数据进行训练结果的测试,测试从图像域A到图像域B的转换生成模型(GAB),为增强显示结果中纤维信息与背景信息的对比度,对生成图像进行直方图增强处理,结果如图9所示。

图9 CycleGAN模型的测试输出结果Fig.9 Test output of CycleGAN model. (a) Test data 1; (b) Test data 2; (3)Output of test data 1; (4) Output of test data 2
由图9可以看出,模型的生成结果很好地滤去了光斑的影响,但仍有部分针点信息干扰,原本模糊不清的纤维信息被提取地十分连续完好,方便人眼观察,不过纤维与背景的边界仍没有完全分离,仍有待于模型网络结构的进一步改进,以提升提取信息的对比度。
4 结 论
本文在高速摄像机拍摄得到高干扰状态下纤维梳理视频后,通过特征初步提取、特征增强以及特征勾画3个步骤实现了无正样本下的纤维检测任务;在得到特征增强的图像后,将其作为生成器的训练正样本,尝试使用生成模型进行有针对性的训练,根据数据本身的特点更好地提取要检测的纤维信息,取得了很好的人眼识别效果。未来的改进方向是通过更加有针对性的监督方法进行生成模型的训练,以期望实现更好的纤维检测识别效果,比如可尝试在生成器和判别器中加入条件变量来指导生成器进行更有针对性的生成;或者可在图像生成中尝试一些实时交互的生成方法,通过人的预勾画使生成结果更有针对性。
