一种分布式异构带宽环境下的高效数据分区方法
2021-01-05马卿云季航旭赵宇海毛克明王国仁
马卿云 季航旭 赵宇海 毛克明 王国仁
1(东北大学计算机科学与工程学院 沈阳 110169)
2(东北大学软件学院 沈阳 110169)
3(北京理工大学计算机学院 北京 100081)
随着物联网、移动互联网、产业互联网和社交媒体等技术的飞速发展,每天都会产生大量的数据,人们已经身处大数据时代[1].根据国际数据公司(International Data Corporation, IDC)的预测,到2025年,全球的数据量将是现在的10倍,达到175 ZB.
大数据中有着丰富的信息,并且蕴含着巨大的价值[2].谷歌通过用户搜索词频的变化成功对冬季流感进行了预测,沃尔玛通过分析消费者购物行为对纸尿裤和啤酒进行共同销售,这些耳熟能详的案例都印证了这一点.但随着数据产生速度的加快,数据量的急剧增长,如何对庞大的数据进行处理成为了新的难题.传统的单机处理已经无法满足大数据的需求,分布式的大数据处理框架应运而生.谷歌首先提出了用于大规模数据并行计算的编程模型MapReduce[3],引起了极大的反响,也因此促使了Hadoop[4]的诞生.之后为了改进传统MapReduce中运行效率低下的问题,基于内存计算的Spark[5]被提出.时至今日,为了追求更快的处理速度、更低的时延,Flink[6]开始崭露头角,并得到了飞速的发展.
与此同时,随着云计算[7]的兴起,包括谷歌、微软、阿里巴巴等在内的互联网公司都提供了大数据存储与分析的相关服务,众多企业开始选择将自己的业务上“云”.这些提供云服务的公司需要存储和处理的数据同样是海量的,为了更好地为客户提供服务,提供云服务的公司通常都会在各地建立数据中心[8],例如微软和谷歌在世界各地就分布着超过十个的数据中心.各数据中心之间经常需要联合进行数据分析,此时分布式大数据处理框架依然是不二之选.跨数据中心的大数据分析业务许多都是数据密集型作业,作业运行过程中,通常需要使用数据分区方法将相同键的数据发送到同一数据中心进行处理,而各个数据中心之间通常相隔较远,这样会产生大量的网络传输开销,导致数据在网络中的传输时间成为大数据分析作业的瓶颈.由于网络提供商硬件设备的不同,各数据中心之间的带宽通常差异较大,这样便会形成异构带宽的分布式环境[9].当然,即使在同构的集群中,也可能因为某些节点上的作业抢占了带宽而导致集群环境中各节点带宽异构.综上所述,在异构带宽环境下,如何高效地进行数据分区是一个急需解决的问题.
数据分区是大数据框架的一个基本功能,通过数据分区可以将各分区数据交给不同的节点进行处理.常用的数据分区方式有随机分区、Hash分区和Range分区[10].其中Hash分区和Range分区都能保证具有相同键的数据分发到同一节点,这也为许多需要这种保证的算子提供了保障.现有的研究很少在数据分区时对节点的带宽进行考虑,在节点间异构带宽的情况下,传统的数据分区方法效率低下,完成数据分区的时间开销较大.针对该问题,本文提出了一种基于带宽的数据分区方法,在带宽异构的集群环境下可以有效减少数据分区完成的时间.
本文的主要贡献有3个方面:
1) 提出了一种基于带宽的数据分区方法,该方法在异构带宽的集群下能有效减少数据分区所需的时间;
2) 在新一代大数据计算框架Flink中,对基于带宽的数据分区方法进行了实现;
3) 通过实验对基于带宽的数据分区方法进行了验证,实验结果显示该方法可以有效地减少完成数据分区所需的时间.
1 相关工作
针对异构集群环境下的大数据框架优化的研究已有不少,主要的研究方向是针对节点间计算能力的不同,为各节点分配不同的数据量或者不同的计算任务.如在异构Hadoop集群中,文献[11]针对集群中节点计算性能不同的特点,以数据本地性策略为基础,通过在计算能力更强的节点放置更多的数据块,使得计算能力强的节点处理更多的数据,从而提升系统的性能;文献[12-13]则针对异构的Hadoop集群,考虑提交至集群的作业运行时需要的资源大小和集群中可用资源的数量,提出了一种新的调度系统COSHH,该调度系统可以结合Hadoop中原始的调度策略进行使用,进一步减少异构Hadoop集群中作业的平均完成时间,使得MapReduce模型在异构集群中的运行效率更高.
在异构Spark集群中同样有着相应的研究,如文献[14]提出了一种在异构Spark集群下的自适应任务调度策略,其主要考虑的是集群中各节点的计算能力不同,通过对各节点的负载和资源利用率进行监测来动态地调整节点任务的分配;文献[15]则采用了一种主动式的数据放置策略,通过对任务所需的计算时间进行预测,在初始数据加载过程中将数据放置在适当的节点上,并在作业执行的过程中进一步对数据的放置进行调整,缩短作业的整体运行时间.
对于数据在节点之间的传输,主要的研究方向是针对同构集群中的数据倾斜问题,比如文献[16]提出了一种用于MapReduce的采样算法,在Hadoop集群中不需要对输入数据运行额外的预采样程序,就能比较精确地估计出中间结果的分布,从而均衡各节点的数据量;同样是针对MapReduce框架中出现的数据倾斜问题,文献[17]基于对Map端中间结果的采样,提出了一种基于动态划分的负载均衡方法,可以保证每个Reduce任务处理的数据量尽量均衡;文献[18]则针对Spark提出了一种基于键重分配和分区切分的算法,该算法作用于中间结果的产生和shuffle过程中,同样用于解决数据倾斜问题;针对数据传输过程的优化通常都需要使用采样算法来获取数据的信息,文献[19]针对大规模数据流,提出了一种改进的水塘抽样方法,Flink中使用该抽样方法实现了Range分区.
以上研究都没有考虑在异构带宽情况下,如何对数据分区方法进行优化.对于数据密集型作业,网络传输往往是瓶颈所在,在异构带宽条件下,传统考虑负载均衡的数据分区方法运行效率反而低下.针对该问题,本文通过建立基于传输时间的数据分发模型,提供了一种基于带宽的数据分区方法,在异构带宽的集群环境下可以有效地减少数据的传输时间.
2 相关概念介绍
2.1 Flink框架
Flink与大多数大数据框架一样也可以分为Master和Slave节点,如图1所示,其中充当Master的称为JobManager,充当Slave的称为TaskManager,除此之外,提交作业的节点通常称为Client.

Fig. 1 The architecture of Flink图1 Flink架构图
Flink中JobManager将接收Client提交的作业,对作业进行调度并选定TaskManager进行任务的执行,收集作业运行的状态,并在作业运行失败时进行容错和恢复,TaskManager上则真正运行着作业的各个子任务[20].通常Flink集群中会有一个JobManager和多个TaskManager.
Flink中作业会被抽象为数据流图,通常都是一个DAG结构[21].具体来讲,作业在Client端提交后,如果是批处理作业会通过优化器生成Optimized-Plan,如果是流处理作业则会生成StreamGraph,之后会继续在Client统一转化为JobGraph,提交给JobManager.在JobManager处接收到JobGraph之后,会将其转化为ExecutionGraph,最后调度执行.
2.2 Flink中的分区方法
大数据计算框架通常都会为用户提供数据分区的功能[22],Flink在其批处理API中也提供了3种常用的数据分区方法,包括Rebalance分区、Hash分区和Range分区.
2.2.1 Rebalance分区
Rebalance分区是Flink中最简单的数据分区方法,通过该分区方法可以很好地均衡每个节点上的数据,但其无法保证具有相同键的数据分发到同一节点上.Flink中使用Round-Robin算法实现了Rebalance分区,具体算法如算法1所示:
算法1.Rebalance分区算法.
输入:待分区的记录record、分区数量numPartitions、当前分区编号partitionToSendTo;
输出:待分区记录的分区编号partitionToSendTo.
①partitionToSendTo++;
② IFpartitionToSendTo≥numPartitions
③partitionToSendTo=0;
④ END IF
⑤ RETURNpartitionToSendTo.
2.2.2 Hash分区
Hash分区是使用最普遍的数据分区方法,该分区方法是基于Hash算法实现的[23].使用该分区方法首先会根据待分区记录的key值得到相应的Hash值,之后利用Hash值对分区数量取余,得到的结果作为该条记录所属的分区编号.因为相同的key值一定有相同的Hash值,因此Hash分区可以保证键相同的记录分发到同一节点上.具体算法如算法2所示:
算法2.Hash分区算法.
输入:待分区的记录record、分区数量numPartitions;
输出:待分区记录的分区编号partitionToSendTo.
①key=extractKey(record); /*提取记录的key*/
② IFkey==null
③partitionToSendTo=0;
④ ELSE
⑤hash=key.hashCode;
⑥partitionToSendTo=Hash%numPartitions;
⑦ END IF
⑧ RETURNpartitionToSendTo.
2.2.3 Range分区
Range分区是一种根据所有待分区记录的键的范围进行数据分区的方法[24],也就是说每个分区结果都包含互不相交的键在一定范围内的记录,也因此使用Range分区方法时需要确定每个分区的边界.为了确定每个分区的边界,通常使用的方式是对输入数据进行抽样.Flink中使用的抽样算法是改进后的蓄水池抽样算法,各分区边界的确定则是对抽样数据进行排序后按等比例获取各个分区的边界.
举例来说,假设抽样得到的数据按键排序后的结果为{(10,value1),(20,value2),(30,value3),(40,value4),(50,value5),(60,value6),(70,value7),(80,value8),(90,value9)},分区数量为3,则计算得到的边界为{30,60},也就是说key≤30的记录将会被发往第1个分区,key∈(30,60]之间的数据会发往第2个分区,key>60的数据则会发往第3个分区.Range分区方法通过抽样并等比例划分各个分区的边界,可以在保证键相同的记录发往同一节点的同时,使得各分区拥有的数据大致相等.具体算法如算法3所示:
算法3.Range分区算法.
输入:输入源的分区数量numInputPartitions、待分区的记录record、分区数量numPartitions;
输出:待分区记录的分区编号partitionToSendTo.
① 使用改进后的蓄水池抽样算法在每个输入源分区上进行抽样;
② 将各输入源分区上的抽样结果进行汇总,得到sampleData[],并排序;
③ 根据分区数量numPartitions和sampleData[],计算出分区边界rangeBoundary[];
④ 对于每条待分区的记录record,在分区边界rangeBoundary[]中查找出所属的分区编号partitionToSendTo;
⑤ RETURNpartitionToSendTo.
3 基于带宽的数据分区方法
本节我们先对最优数据分发比例的计算建立模型.之后举例说明异构带宽的集群中不同的数据分发比例对数据分区完成时间的影响,体现基于带宽的数据分区方法的重要性.最后介绍针对异构带宽的数据分区方法的算法流程以及在Flink中的实现.
3.1 最优数据分发比例建模
本节对异构带宽环境下各节点最优数据分发比例的计算建立模型,首先对所要用到的变量进行定义.
Di:节点i上的初始数据量大小;

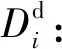
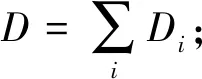
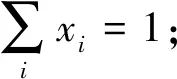
ui:节点i的上行带宽;
di:节点i的下行带宽;
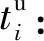
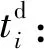
cost:数据分发所要花费的总时间.
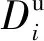
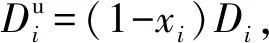
(1)
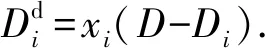
(2)


(3)

(4)
数据分发所要花费的总时间cost则是各节点传输数据所需时间的最大值.我们的目标是最小化数据分发所需的时间,则形式化地针对数据传输时间的优化模型表示为
mincost
s.t. ∀i:xi≥0,
该模型是一个典型的线性规划问题,使用计算机可以比较方便地求解.
3.2 示 例
考虑集群中参与数据分区的2个节点Slave1和Slave2,它们初始的节点信息如表1所示:

Table 1 Information of Nodes表1 节点信息表
其中Slave1节点上的初始数据量D1=320 MB,上行带宽u1=2 Mbps,下行带宽d1=10 Mbps.Slave2节点上的初始数据量D2=160 MB,上行带宽u2=10 Mbps,下行带宽d2=10 Mbps.
当Slave1和Slave2以50%和50%的比例进行数据分发时,可以分别计算出Slave1和Slave2传输的数据量大小和所需时间,具体如表2所示:

Table 2 Transmission Information on Proportional 50%∶50%表2 50%∶50%比例分配数据传输信息表
其中Slave1需要传出50%的数据,即160 MB,接收来自Slave2的80 MB数据.Slave2则需传出80 MB数据,接收来自Slave1的160 MB数据.根据Slave1和Slave2的上下行带宽可以计算得出相应的传输时间,而最终数据分区完成需要取决于传输最慢的节点,也就是说以50%和50%的比例进行数据分区,最终需要花费640 s来完成.
考虑以90%和10%的比例进行数据分发,也就是说数据分发结束后Slave1保留90%的数据,Slave2保留10%的数据.同样可以计算出各节点所需传输数据量大小和相应的时间,如表3所示:

Table 3 Transmission Information on Proportional 90%∶10%表3 90%∶10%比例分配数据传输信息表
其中Slave1需要传出10%的数据,即32 MB,接收来自Slave2的144 MB的数据.Slave2则需传出144 MB数据,接收来自Slave1的32 MB数据.同理计算出传输时间后,可以得到最终传输结束所需时间为128 s,与分配比例为50%时相比速度提高了4倍.
3.3 算法设计
以建立的最优数据分发比例模型为基础,可以设计出基于带宽的数据分区算法,如算法4所示:
算法4.基于带宽的数据分区算法.
输入:输入源的分区数量numInputPartitions、待分区的记录record、分区数量numPartitions、参与分区的节点信息instanceInfo;
输出:待分区记录的分区编号partitionToSendTo.
① 使用改进后的蓄水池抽样算法在每个输入源分区上进行抽样;
② 将各输入源分区上的抽样结果进行汇总,得到sampleData[],并排序;
③ 根据参与分区的节点信息instanceInfo计算出最优数据分发比例ratio[];
④ 根据最优数据分发比例ratio[]和得到的抽样结果sampleData[],计算出分区边界rangeBoundary[];
⑤ 对于每条待分区的记录record,在分区边界rangeBoundary[]中查找出所属的分区编号partitionToSendTo;
⑥ RETURNpartitionToSendTo.
3.4 算法实现
鉴于新一代大数据计算框架Flink的出色性能,选用Flink对基于带宽的数据分区算法进行了实现.
实现基于带宽的数据分区方法,需要完成最优数据分发比例的计算和作业图逻辑的修改.3.4节已经提到过,计算节点的最优数据分发比例需要节点的带宽信息和数据量.原始的Flink无法获取集群中各节点的带宽信息,考虑实现简便性,我们在Flink的配置文件中添加了各节点上下行带宽的配置项,在Flink集群启动时,各TaskManager会将自身的带宽信息汇总到JobManager处.各节点的数据量则根据作业JobGraph中的Source算子,获取相应的数据源分布情况后推算得出.作业图逻辑的修改包括采样算法的加入和分区方法的重写,这部分将在生成OptimizedPlan时完成,这样可以减少JobManager处的负载.
图2对一个基于带宽的数据分区作业的整体流程进行了详细描述.如图2中Step1~3所示,作业在Client端提交后,首先会通过优化器优化生成OptimizedPlan,之后将以生成的OptimizedPlan为基础,生成作业图JobGraph.在作业图生成的过程中我们添加了采样的逻辑和用于计算分区边界的算子,并重写了数据分区的方法.其中计算分区边界的算子会根据最优数据分发比例得到数据分区的界,该结果将会通过广播的方式发送到每个分区算子.需要注意的是,此时还在Client端,计算分区边界的算子还没有实际获取到最优数据分发比例,最优数据分发比例的获取需要在JobManager处完成.完成作业逻辑的修改后, 通过Step3生成的JobGraph将被提交到JobManager.
如图2中Step4~7所示,JobManager收到作业的JobGraph后,首先会遍历JobGraph中的算子并找到Source算子,通过Source算子中存储的数据源信息去获取待处理数据在集群中的分布情况,并结合作业的并行度选择运行该作业的节点.考虑网络传输是作业运行的瓶颈,节点的选择策略是尽可能选择拥有数据的节点来运行作业,这样根据数据本地性策略,可以减少Source算子读取数据源时的网络传输.确定作业运行的节点后,通过节点的带宽信息和初始数据量大小,使用数据分发比例计算模块就可以计算出各节点的最优数据比例,该比例将会被写回JobGraph中用于计算分界的算子.至此,包含最终作业执行逻辑的作业图JobGraph才真正构建完成.最后根据JobGraph中各算子的并行度,会生成对应的执行图ExecutionGraph,执行图中的每个任务通过Step7将部署至对应的节点,进行调度执行.

Fig. 2 The process of bandwidth partitioning job图2 基于带宽的数据分区方法作业运行过程
4 实验与分析
4.1 实验环境
实验所用环境为4个节点的分布式集群,每个节点的处理器为Intel Xeon E5-2603 V4(6核6线程),内存为64 GB,节点间通过千兆以太网连接,安装的操作系统为CentOS7.集群上通过Standalone模式搭建了修改后的Flink集群,其中1台master节点作为JobManager,另外3台Slave节点作为TaskManager,使用的版本为Flink1.7.2.除此之外集群中还基于Hadoop2.7.5搭建了Hadoop集群,使用其中的HDFS作为分布式文件存储系统.集群中各节点带宽的控制则通过工具Wondershaper[25]来实现.
4.2 数据集
实验使用的数据是通过TPC-H[26]基准测试工具生成的数据集,该工具可以生成8种表,选取了其中较大的Lineitem表和Orders表作为数据源.其中Lineitem有16个字段,前3个字段Orderkey,Partkey,Suppkey,其中Suppkey是主键.Orders表有9个字段,前2个字段Orderkey和Custkey,其中Custkey是主键.
4.3 实验结果与分析
本节从算法开销和算法效果2方面进行实验结果的说明与分析.
4.3.1 算法开销
基于带宽的数据分区方法的算法开销主要包括作业图逻辑修改、最优数据分发比例的计算、数据采样3部分,本文针对这3部分所需的开销分别进行了实验.
作业图逻辑的修改发生在Flink作业图生成的过程中,主要包括采样算子的添加、计算分界算子的添加以及分区方法的重写等步骤.通过与未修改作业图逻辑进行对比,可以得到作业图逻辑修改所需的时间.经过5次实验并取平均值,得到从作业提交到作业图生成完毕所需的平均时间为185 ms,如果进行作业图逻辑的修改,所需的平均时间则为232 ms,即作业图逻辑修改平均所需时间为47 ms.
最优数据分发比例的计算是利用数学规划优化器Gurobi Optimizer[27]实现的数据分发比例计算模块完成的,实验对不同节点数量下最优比例计算所需的时间进行了测试,每个节点的带宽和数据量大小则随机生成.实验结果如图3所示,当节点数量为5时所需的计算时间为32 ms,节点数量扩大至1 000时计算时间仍在100 ms以内,当节点数量达到6 000时所需的计算时间也仅为293 ms.
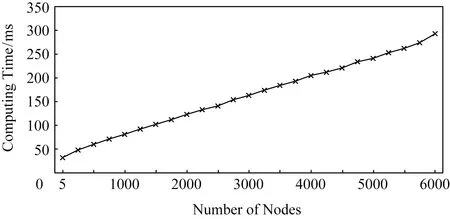
Fig. 3 The time of optimal ratio calculation图3 最优比例计算时间
为了测试数据采样所需的开销,我们分别运行了添加了采样过程的作业和未添加采样过程的作业,使用作业运行的时间差作为采样所需的开销.实验中使用了不同数据量大小的Lineitem表作为输入,具体实验结果如图4所示,在数据量大小分别为3.6 GB,7.2 GB,14.6 GB,29.4 GB时,所需的采样时间分别为21 s,44 s,86 s,167 s,平均每GB数据所需的采样时间约为5.8 s.
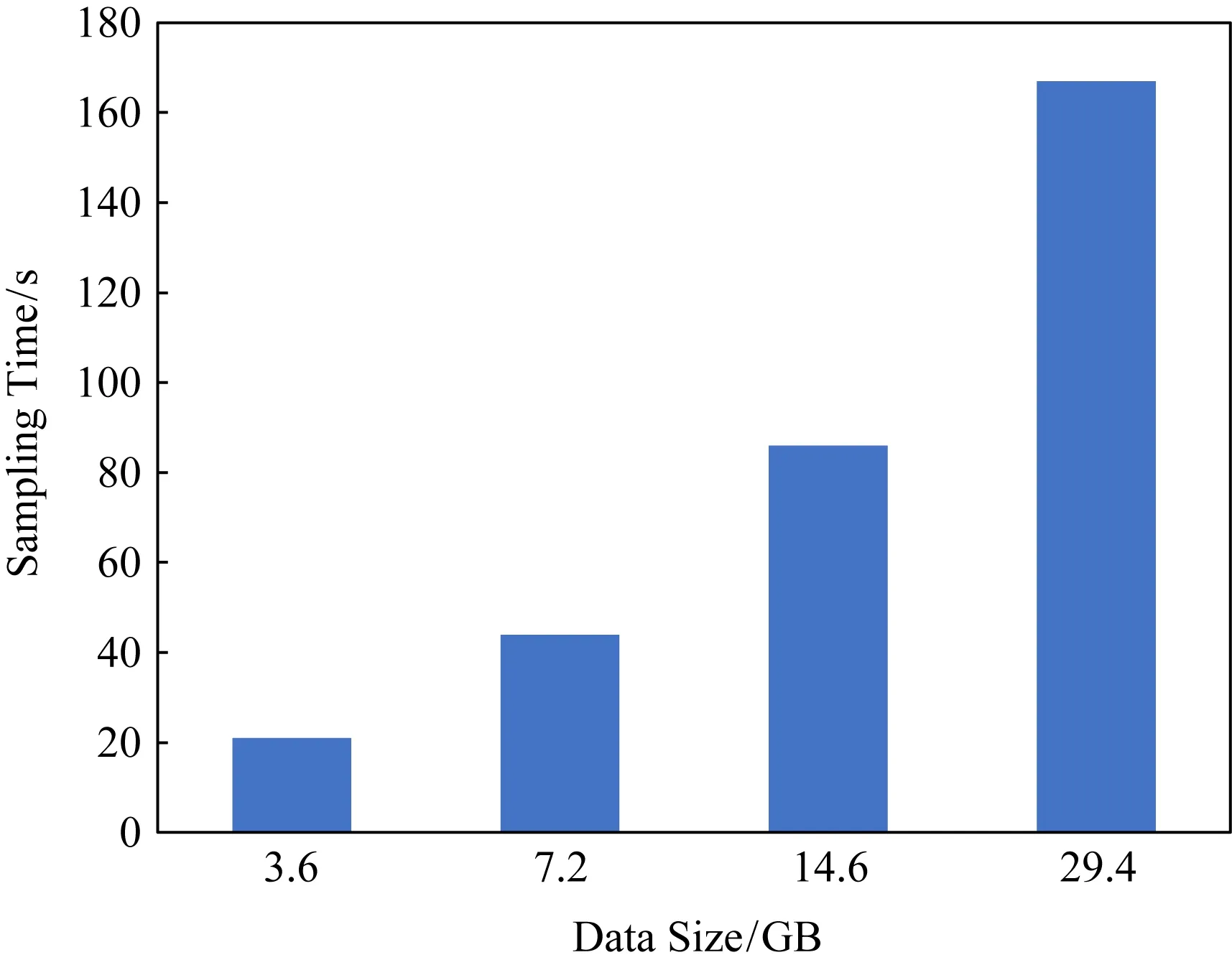
Fig. 4 The time of sampling图4 采样时间
总体来说,基于带宽的数据分区方法在作业图逻辑修改和最优数据分发比例的计算过程中所需的时间开销都较小,为毫秒级别.数据采样则相对时间开销较大,且与数据量大小相关,但在计算资源更为充足的情况下,采样所需时间可以进一步减少.
4.3.2 算法效果
为了探究本文提出的算法在不同的异构带宽条件下的效果,我们设置了带宽异构程度不同的4个实验.同时为了实验的方便,主要针对Slave1节点设置了不同的下行带宽,这样已经可以涵盖不同的数据分发比例,其他情形的异构带宽集群则与此类似.实验中各节点的具体带宽如表4所示,表4中上行带宽在前、下行带宽在后.
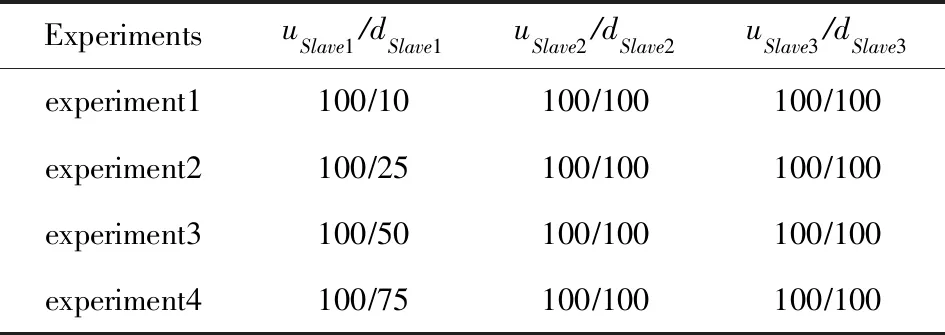
Table 4 Bandwidth Information表4 带宽信息表 Mbps
实验中使用的数据为3.6 GB的Lineitem表和1.63 GB的Orders表.实验程序会先对数据集进行分区操作,数据分区结束之后将在每个分区中进行一次聚合,统计各分区最终的记录数量,以便计算出最终各分区数据的比例.程序的执行模式设置为Batch模式,分区方法使用Hash分区、Range分区与基于带宽的Bandwidth分区进行比较,验证基于带宽的Bandwidth分区效果.
因为实验主要针对的是节点带宽的影响,而实验所使用的集群TaskManager的数量是3,因此作业运行的并行度同样设置为3.使用的数据源则被上传到HDFS中,3个节点上的数据量几乎是相等的,因此可以认为Source算子的每个并行度读入的数据量都是相同的.对数据集进行介绍时有过说明,Lineitem表中有3个字段是主键,Orders表中有2个字段是主键,在实验过程中我们发现这2个表中并没有明显的数据倾斜,通过主键中的任一字段做数据分区,实验结果都是相似的.后续的实验结果都是以各个表的第1个字段作为键来进行数据分区,也就是说数据源Lineitem和Orders都使用Orderkey作为键进行数据分区.
如图5所示,在实验1条件下,使用Bandwidth分区的作业时间在Lineitem上所需时间为198 s,在Orders上所需时间为92 s,明显小于Hash分区和Range分区所需时间,作业运行完成整体速度提升了为2.5~3倍.

Fig. 5 Running time in different partition modes in experiment 1图5 实验1中不同分区模式下的执行时间
在实验1的条件下,可以计算出3个节点数据的最优分配比例为4∶48∶48,通过表5和表6可以看出,使用Bandwidth分区很好地契合了最优数据分配比例,特别是在Lineitem上实际数据分区比例与最优比例几乎完全相同.
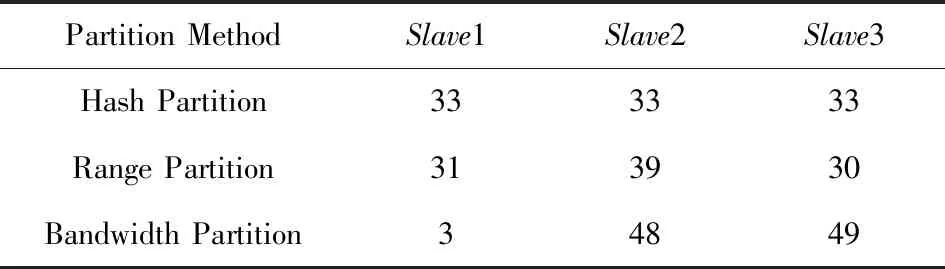
Table 5 Proportion of Lineitem After Partition in Experiment 1表5 实验1中Lineitem分区后各节点数据比例 %
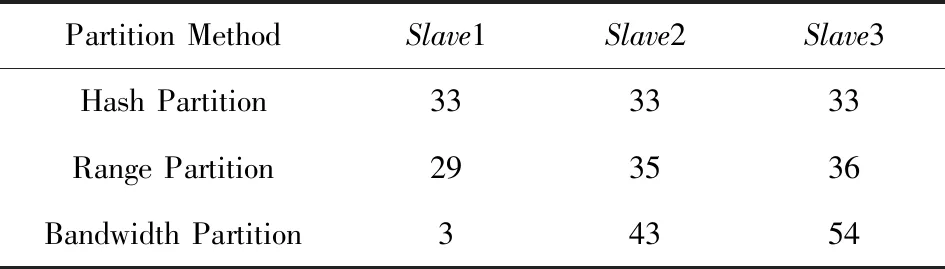
Table 6 Proportion of Orders After Partition in Experiment 1表6 实验1中Orders分区后各节点数据比例 %
如图6所示,在实验2条件下,使用Bandwidth分区的作业时间在Lineitem上所需时间为209 s,在Orders上所需时间为99 s,相较于Hash分区和Range分区,效果同样不错,提升为0.6~0.7倍.

Fig. 6 Running time in different partition modes in experiment 2图6 实验2中不同分区模式下的执行时间
在实验2的条件下,计算出的各节点数据的最优分配比例为11∶44∶44,通过表7和表8可以看出,使用Bandwidth分区后的数据分布也与最优数据分配比例比较契合.
如图7所示,在实验3条件下,使用Bandwidth分区的作业时间在Lineitem上所需时间为184 s,在Orders上Bandwidth分区所需时间为68 s,相较Hash分区所需时间194 s和88 s已经没有太大的优势,但仍然能节省一些时间.
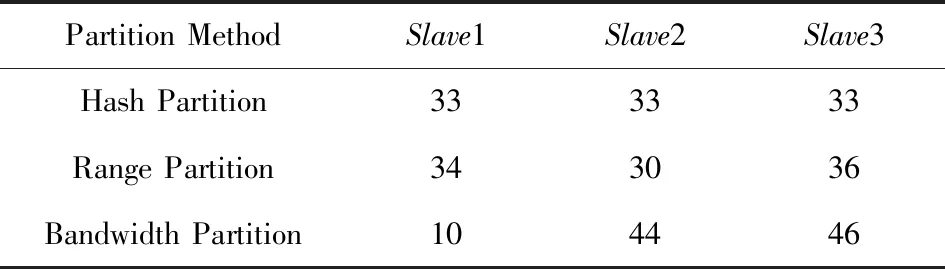
Table 7 Proportion of Lineitem After Partition in Experiment 2表7 实验2中Lineitem分区后各节点数据比例 %
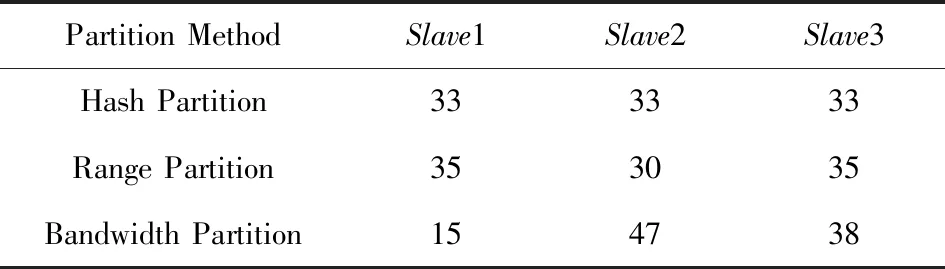
Table 8 Proportion of Orders After Partition in Experiment 2表8 实验2中Orders分区后各节点数据比例 %
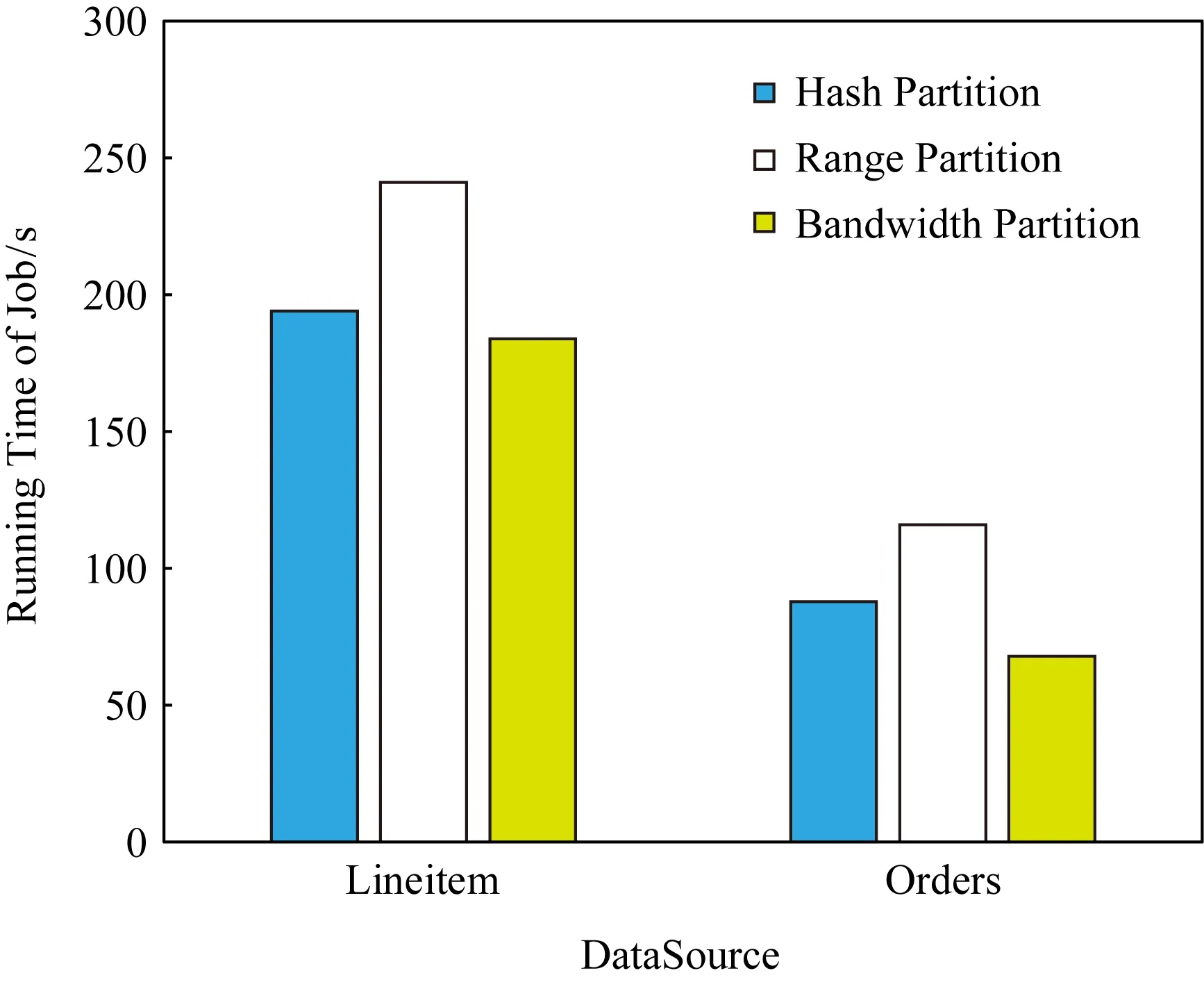
Fig. 7 Running time in different partition modes in experiment 3图7 实验3中不同分区模式下的执行时间
此时节点之间数据传输的最优比例已经是20∶40∶40,与平均分配差距已经没有那么大,同时还可以发现,此次实验条件下Range分区表现较差,分区完成所用时间与其他实验相比明显变长.分析表9和表10可以发现,Range分区在实验4中,对需要数据比例少的Slave1节点反而分配了更多的数据,导致Range分区所需时间远超了其他2种分区方法.
如图8所示,在实验4条件下,与Hash分区相比,Bandwidth分区所需时间反而变得更长.此时节点间的最优比例是27∶36∶36,与平均分配比例已经十分接近,而Range分区和Bandwidth分区需要额外的采样时间.除此之外,结合表11和表12可以发现,采样得到的结果并不是特别准确,导致并不能完全按计算得到的最优比例进行数据分发.

Table 9 Proportion of Lineitem After Partition in Experiment 3表9 实验3中Lineitem分区后各节点数据比例 %
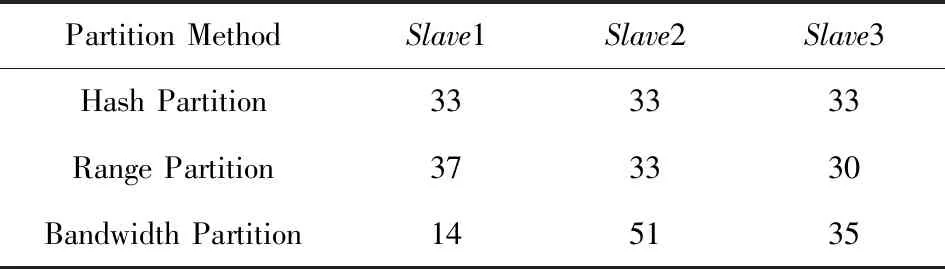
Table 10 Proportion of Orders After Partition in Experiment 3表10 实验3中Orders分区后各节点数据比例 %
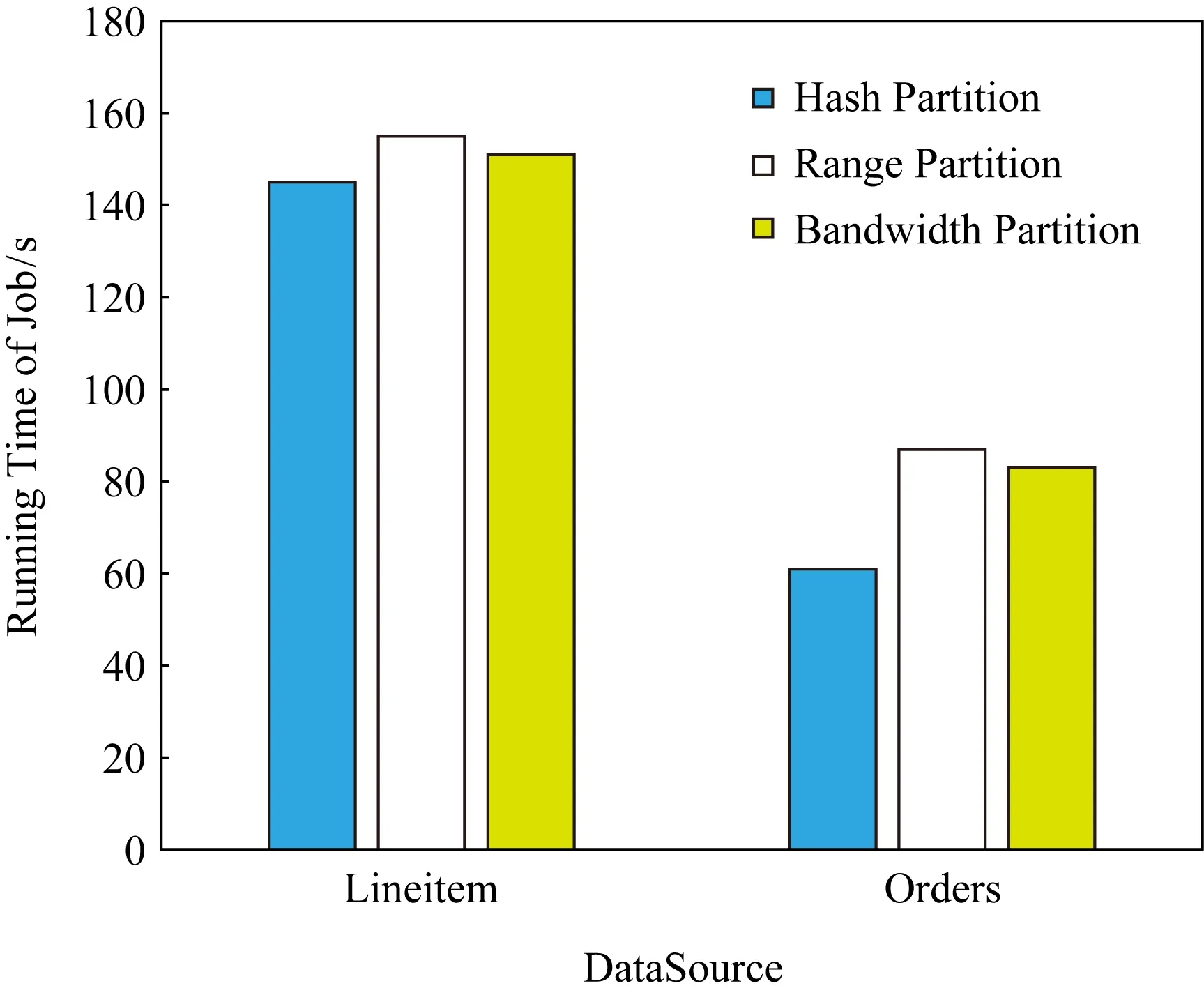
Fig. 8 Running time in different partition modes in experiment 4图8 实验4中不同分区模式下的执行时间
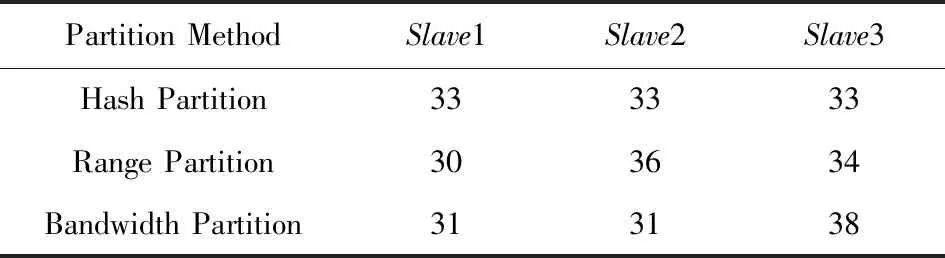
Table 11 Proportion of Lineitem After Partition in Experiment 4表11 实验4中Lineitem分区后各节点数据比例 %
结合4个实验,可以发现Hash分区十分稳定,每次实验分区结果都十分均衡,说明数据源中并没有明显的数据倾斜.Range分区和Bandwidth分区则并不能每次都保证数据按预设的比例分配,主要是因为它们都需要使用采样算法来估计数据分布,有时候采样的结果并不是十分精确.同样由于采样算法的存在,Range分区和Bandwidth分区都需要额外的开销,这也导致大多数时候Range分区都比Hash分区花费更多的时间.唯一例外的是在实验1中对Orders表进行分区,原因是Range分区恰好给瓶颈节点Slave1分配了更小的比例,而Slave1下行带宽很小,较小的数据量就会对传输时间产生较大的影响.

Table 12 Proportion of Orders After Partition in Experiment 4表12 实验4中Orders分区后各节点数据比例 %
综合来看,当带宽异构性强,各节点之间最优数据分发比例比较不均衡时,基于带宽的数据分区方法可以取得较好的效果,甚至带来数倍的速度提升.当带宽异构性较弱时,由于采样算法需要额外的开销,基于带宽的数据分区方法所需时间可能会长于Hash分区方法,这种情况下可以通过更充足的计算资源来降低采样过程所需的开销.在实际应用过程中,则可以综合考虑最优比例的计算结果和采样所需的时间,在速度提升较为明显时选择使用基于带宽的数据分区方法.
5 总 结
在异构带宽的条件下,传统的数据分区方法会因为瓶颈节点的存在,导致数据分发效率低下.通过对各节点之间数据传输模型进行分析,本文提出了一种针对异构带宽集群的数据分区方法,并在Flink中进行了实现.实验证明:在节点间带宽异构的情况下,基于带宽的数据分区方法可以极大地提升数据分区完成的速度.
