面向微博文本流的负面情感突发话题检测
2020-12-31李艳红赵宏伟王素格李德玉
李艳红,赵宏伟,王素格,李德玉
(1.山西大学计算机与信息技术学院,太原 030006;2.计算智能与中文信息处理教育部重点实验室(山西大学),太原 030006)
(∗通信作者电子邮箱liyh@sxu.edu.cn)
0 引言
近年来,社交媒体如Twitter和新浪微博,已经是人们了解信息资讯、探讨社会问题的主要平台,根据Twitter 发布的2019 年第四季度财报显示,Twitter 日活跃用户增加了700 万人,达到1.52 亿人;根据新浪微博发布的用户发展报告显示,2019 年第四季度微博月活跃用户为5.16 亿,同比增长11.7%。微博受到了越来越多民众的欢迎,大家可以享受即时信息,分享自己的看法,此外信息在微博中迅速广泛地传播,使其成为各类突发话题的第一发布现场。由于微博信息的高度动态性、交互性、海量性,使民众在享受服务便利的同时,也会面临新的挑战:微博中非负面情感突发话题(如明星庆生、体育赛况等)会吸引大量的网民关注,而负面情感突发话题(如地震灾害、疫情传播等)同样也会引发社会热议。传统的突发话题检测方法并没有考虑两者的区别,导致检测出的突发话题还需进一步判定是否为负面情感突发话题,这样既浪费了资源,也不能达到及时有效的舆论监控。
目前,微博突发话题检测方法主要分为两类:以微博文本为中心的方法和以突发特征为中心的方法。以微博文本为中心的方法首先对滑动窗口中的微博文本聚类,然后评估聚类结果的突发性从而发现突发类,最后从突发类中提取主题词以表示突发话题,如:Li 等[1]提出了一种增量时间主题模型,通过微博文本流的时间信息进行建模,若当前时间窗口中微博数量相较于历史均值显著增加时,则认为存在突发话题。Diao 等[2]通过改进隐狄利克雷分布(Latent Dirichlet Allocations,LDA)主题模型,综合考虑了时间因素和用户因素来发现微博文本流中的突发话题。Huang 等[3]首先利用局部加权线性回归方法估计单词的新颖度和衰减度,然后使用主题模型获取微博话题,最后将二者相结合确定主题的突发度和衰减度,并实现对话题的追踪。Wang 等[4]提出了一种主题级别的突发话题检测模型,通过单词的突发性以及与其他单词的共现性来确定突发话题。
以突发特征为中心的方法通过分析微博流的突发特征(如主题词的词频、加速度、动量、情感特征)的变化来判断突发,然后对具有突发特征的微博文本进行聚类从而获取突发话题结构。Fung等[5]首次提出了以特征为中心的突发话题检测方法,通过分析时间信息和单词的分布情况来发现特征词,突发话题由若干特征词组成。Zhu 等[6]利用主题词频的变化率以及对其变化趋势的预测发现突发话题,由于在主题的提取过程中加入了时间和地理位置信息,得以更好地确定突发内容。Xie等[7]提出了TopicSketch 突发话题检测框架,将单词对和三元单词组的加速度作为突发特征,然后利用草图模型和张量分解技术确定突发话题的主题。Zhang等[8]在文献[7]的基础上,提出了一种改进的张量分解模型,将聚类和模糊集理论加入到模型当中,使其过滤掉普通主题,从而检测出突发话题。Zou 等[9]首先通过离线构建情感共现图对微博文本进行情感分类,然后利用Kleinberg 等[10]提出的自动机模型判断每种情感中的微博文本数量是否存在突发,最后将具有突发状态的微博主题标签作为突发话题的关键词,选择与其相关的单词共同描述突发话题。Paltoglou 等[11]将与关键词相关微博的情感极性相较于历史情感平均值的变化作为突发特征发现突发话题。张鲁民等[12]利用情感符号模型监测微博流中情感符号的变化,发现情感符号的突发期,然后通过启发式近邻传播(Affiliation Propagation,AP)聚类算法得到话题的主题结构。文献[5-8]在检测突发话题时没有考虑微博的情感特征,文献[9,11-12]中虽然考虑了微博的情感特征,但在检测时没有区分突发话题的情感极性。
以微博文本为中心的检测方法需先将微博流划分为多个滑动窗口,并对窗口中的微博进行聚类,这种检测方式不适合实时检测任务。以突发特征为中心的方法重点在于检测微博文本流中突发特征随时间的变化,但是以往的工作还存在以下问题需要深入研究:1)由于在舆情监控中更加关注负面情感突发话题,因此如何有效地区分负面情感突发话题与非负面情感突发话题是当前需要解决的问题。2)已有的检测方法通常采用定长滑动窗口技术,滑动窗口的大小难以确定,因此势必对突发话题的检测带来影响。所以,如何确定突发话题的范围也是研究难点之一。
针对以上问题,本文提出了面向微博文本流的负面情感突发话题检测(Negative Emotion Burst Topic Detection,NEBTD)算法。该算法同时考虑主题词对的加速度和负面情感强度的变化率进行负面情感突发话题检测,并根据突发词对的速度确定负面情感突发话题的持续范围,然后使用一种基于吉布斯采样的狄利克雷多项式混合模型(Gibbs Sampling Dirichlet Multinomial Mixture model,GSDMM)聚类算法[13]获取突发话题的主题结构。最后通过与一种已有的基于情感方法的话题检测(Emotion-Based Method of Topic Detection,EBM-TD)算法进行对比,结果表明本文所提算法的准确率和召回率均有明显提高,而且可以减少负面情感突发话题检测的时间延迟。
1 问题的形式化定义

2 负面情感突发话题检测的相关定义
2.1 突发特征定义
在微博文本流中分布着大量话题,这些话题可分为突发话题和一般话题两类。直观地,突发话题区别于一般话题的特征为:1)微博涌现。突发话题出现时,在短时间内微博文本流中会涌现大量的相关微博;而一般话题没有此特征。2)情感增强。突发话题出现时,在短时间内微博文本的情感强度会明显增强,特别地,当负面情感突发话题出现时,会伴随着微博文本流负面情感强度的显著增强。
图1 是对“全国多地大雪导致交通瘫痪”这一负面情感突发话题和“吴亦凡参加快乐大本营”这一非负面情感突发话题的主题词对数量变化和负面情感强度变化的分析结果。可以发现,在两个话题发生的早期,主题词对数量在短时间内均有明显的增多。但由于图1(a)中的话题引发了民众担忧、焦虑等负面情感的爆发,所以微博文本流负面情感强度在短时间内明显增强;而图1(b)为明星参加综艺节目,民众大多为激动、喜爱的情感,话题的负面情感强度没有发生明显的变化。由此可见,将主题词对加速度和微博文本流负面情感强度变化率共同作为负面情感突发话题的突发特征是可行的。

图1 主题词对和负面情感强度分布Fig.1 Distribution of topic word pair and negative emotion intensity
为了检测微博文本流中的负面情感突发话题,本文提出将主题词对的加速度和微博文本流负面情感强度的变化率作为突发特征。这是因为当突发话题出现时,会出现“微博涌现”现象,微博中相关主题词的速度也会随之明显增高,而速度的变化快慢可以利用“加速度”来刻画。由于主题词对相较于单个主题词包含更丰富的话题信息,如:(全国,大雪)、(大雪,交通)、(交通,瘫痪),因此,可以将主题词对的加速度作为突发特征之一。此外,当负面情感突发话题出现时,会出现“负面情感增强”现象,微博中带有负面情感的情感词、表情符号会明显增多,因此可以将微博文本流负面情感强度的变化率作为另一个突发特征。
下面依次给出主题词对速度、加速度,微博情感强度,微博文本流的负面情感强度、负面情感强度变化率定义。
定义1 微博di中主题词对(wx,wy)在ti时刻的速度定义为(wx,wy)在时间片ΔT内的微博出现的平均频率[7]。表示为:
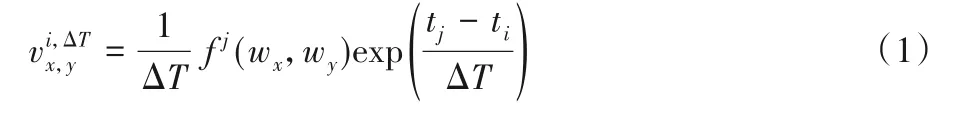
式中:ΔT是以ti为终止时间点的时间片;f j(wx,wy)为微博dj中主题词对(wx,wy)的频率。f j(wx,wy)计算式为:

定义2主题词对(wx,wy)在ti时刻的加速度通过以ti为终止时刻的两个时间片ΔT1、ΔT2所对应的主题词对速度的变化快慢来刻画[14]。定义为:

式中:ΔT1< ΔT2。
定义3微博di的情感强度ei,可基于微博中的情感词三元组(negj,vj,ej)来计算[15]。ei的计算式为:

式中:ne为微博di中情感词个数;q(ej)为情感词ej的情感强度值(-9 ≤q(ej)≤9);g(vj)为程度副词vj的程度值(-3 ≤g(vj)≤3)。其中q(ej)、g(vj)的值通过给定的情感词典和程度副词词典确定。
若ei< 0,将微博di定义为负面情感微博;否则,di定义为非负面情感微博。
定义4ti时刻微博文本流的负面情感强度定义为:
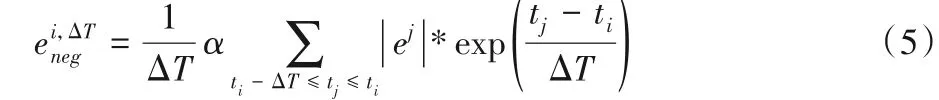
式中:α为ΔT时间内,负面情感微博数占总微博数的比值;ej为ΔT时间内所有负面微博的情感强度值。
定义5ti时刻微博文本流的负面情感强度变化率ki,可以通过以ti为终止时间点的两个时间片ΔT1和ΔT2所对应的微博文本流负面情感强度的变化来刻画,计算式为:

式中:ΔT1< ΔT2。
2.2 负面情感突发话题窗口定义
当检测到微博文本流中主题词对的加速度和负面情感强度变化率均大于特定阈值时,则认为出现了负面情感突发话题,并称该主题词对为突发词对。由于突发词对的速度在一定程度上可以反映突发话题的受关注程度,因此将突发词对的速度均不小于某个阈值的连续时间区间称为突发词对窗口。又由于负面情感突发话题的情感倾向会随着时间的推移发生变化,因此在确定负面情感突发话题窗口时没有考虑情感因素。因为一个负面情感突发话题中往往会存在多个突发词对窗口,因此可以通过合并多个交叉、重叠或相邻的突发词对窗口从而得到负面情感突发话题窗口。
下面依次给出突发词对、突发词对窗口和负面情感突发话题窗口的定义。
定义6若≥ε,则称该主题词对(wx,wy)为突发词对,记为BPx,y。其中ε为突发词对加速度的阈值。
定义7突发词对BPx,y所对应的突发词对窗口BPWx,y利用该词对的速度来确定,定义为:
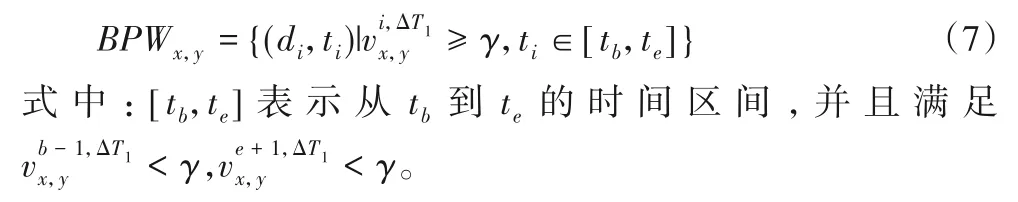
定义8突发词对BPx1,y1,BPx2,y2,…,BPxnum,ynum,若存在num个交叉、重叠或相邻的突发词对窗口BPWx1,y1,BPWx2,y2,…,BPWxnum,ynum,则对这些窗口进行合并,得到负面情感突发话题窗口W,定义为:

3 负面情感突发话题检测
3.1 负面情感突发话题检测框架
本文提出的微博文本流负面情感突发话题检测框架如图2所示。该框架主要包括以下三部分:
1)突发特征识别。将微博文本流中主题词对的加速度和负面情感强度的变化率共同作为负面情感突发话题的突发特征。当有新的微博文本出现时,进行突发特征识别,即统计微博中主题词对的频率、刷新主题词对速度表,并计算主题词对的加速度;根据微博中的情感词三元组计算微博的情感强度、更新微博情感强度表,并进一步得到微博文本流负面情感强度变化率。若主题词对加速度和负面情感强度变化率均大于给定阈值,则认为出现了负面情感突发话题,并且相应的主题词对为突发词对。
2)负面情感突发话题窗口确定。针对每个发现的突发词对,结合突发词对的速度来确定突发词对出现频繁的区间,即突发词对窗口。通过将多个交叉、重叠或相邻的突发词对窗口进行合并,得到负面情感突发话题窗口。
3)负面情感突发话题的主题结构获取。利用基于吉布斯采样的狄利克雷多项式混合模型(GSDMM)聚类算法对负面情感突发话题窗口中的微博文本进行聚类,得到负面情感突发话题的主题结构。该聚类方法能够很好地处理稀疏、高维的短文本,而且可以自动推断聚类个数,并快速地收敛。
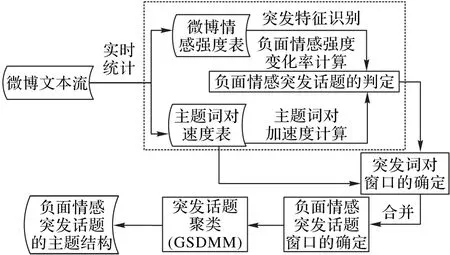
图2 负面情感突发话题检测框架Fig.2 Negative emotion burst topic detection framework
3.2 主题词对速度表与微博情感强度表
本文设计了主题词对速度表Z和微博情感强度表E,其中Z为Q*Q数组,用于保存主题词对的速度。Z[x][y]存放的是主题词对(wx,wy)的速度和,如图3所示。
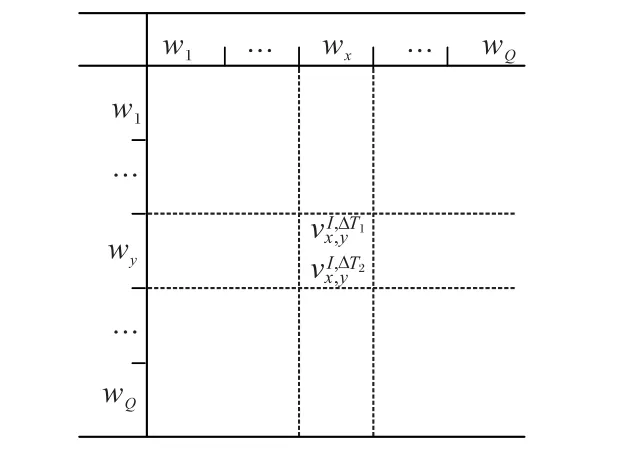
图3 主题词对速度表Fig.3 Speed table of topic word pairs
微博情感强度表E为一维动态变化数组,用于保存以ti为终止时刻的ΔT2时间内所有微博的情感强度。
当有新的微博文本到达时,更新表Z和E,并计算主题词对加速度和微博文本流负面情感强度变化率,以此来确定是否存在负面情感突发话题。
3.3 负面情感突发话题检测算法
根据图2 所示的负面情感突发话题检测框架,本文设计了一种负面情感突发话题检测(NE-BTD)算法,如算法1所示。
算法1 负面情感突发话题检测算法。
输入 微博文本流D,时间片ΔT1和ΔT2,主题词对加速度阈值ε,微博文本流负面情感强度变化率阈值δ,突发词对速度阈值γ,突发词对合并窗口个数阈值m。
输出 负面情感突发话题主题结构。
1)按照D中的时间戳ti逐条读取微博,进行突发特征计算:

2)负面情感突发话题窗口确定:根据定义7,确定突发词对窗口。若存在交叉、重叠或相邻的突发词对窗口BPWx1,y1,BPWx2,y2,…,BPWxnum,ynum,其中num≥m则合并突发词对窗口,得到负面情感突发话题窗口W;否则转到1)。
3)负面情感突发话题主题结构确定:利用GSDMM 聚类算法对负面情感突发话题窗口W内的微博文本进行聚类,得到负面情感突发话题主题结构。
4 实验与结果分析
4.1 实验环境及数据
本文实验均在PC 上完成,具体机器配置如下:CPU 为Intel Core i7-7700 3.6 GHz,内存16 GB,Windows 10 操作系统,Pycharm开发环境,Python版本3.5。
目前针对负面情感突发话题检测并没有标准的数据集,因此本文通过编写爬虫程序从新浪微博网站(www.weibo.com)爬取了从2019 年12 月23 日到2020 年1 月23 日期间32万余条微博。
针对本文的任务需要,对爬取到的微博数据进行处理,保留微博的发布时间和内容信息,形成微博文本流。在实验前对微博文本流进行预处理,首先删除微博内容中的噪声(如@×××、URL 链接),并将文本内容中词数小于3 的微博删除,然后利用哈尔滨工业大学研发的语言技术平台(Language Technology Platform,LTP)中文分词工具,对微博文本进行分词、词性标注、去除停用词操作,得到了30 余万条微博数据。经过对微博数据进行人工标注,共得到突发话题48 个,其中负面情感突发话题有28 个。在实验中将上述30 余万条微博数据划分为三部分,具体的数据描述如表1 所示。本实验所用的情感词典是在大连理工大学徐琳宏等[16]构造的情感词典的基础上,加入了人工收集的网络流行语、表情符号等,情感词典规模从原有的27 467个情感词扩充到现在的30 035个情感词。

表1 数据描述Tab.1 Data description
4.2 NE-BTD算法的准确率、召回率、F1值
本文使用准确率(P)、召回率(R)、F1 值来评价算法的性能,并在上述三个数据集上进行对比实验。P、R、F1值的计算公式为:


其中:Right_topic为算法检测正确的负面情感突发话题数量;All_topic为算法检测到的负面情感突发话题数量;lable_topic为标注的负面情感突发话题数量。
本文提出的NE-BTD 算法参数取值为:主题词对加速度阈值ε=0.15,微博文本流负面情感强度变化率阈值δ=0.20、突发词对速度阈值γ=3.0,ΔT1=15 min,ΔT2=30 min,突发词对窗口合并阈值m=4。目前针对负面情感突发话题的检测算法,如文献[17]提出的一种基于情感方法的话题检测(EBM-TD)算法,该算法使用定长滑动窗口内的主题词频增长速率,并结合负面情感对主题词频加权来筛选突发词。EBM-TD 算法的参数取值为:定长滑动窗口长度为3 h,突发词判定阈值0.3,突发词聚类阈值0.25。
图4 为本文提出的NE-BTD 算法与EBM-TD 算法在三个数据集上检测负面情感突发话题的P、R 和F1值的对比结果。由图4 可知,本文所提出的NE-BTD 算法相较于EBM-TD 算法在三个数据集上,其准确率、召回率、F1 值均有明显提高。通过对实验数据中所有话题的持续时间、情感倾向,以及两种算法检出突发话题的情况分析,结果如表2 所示,可知EBM-TD算法虽然考虑了负面情感因素,但只是将其作为主题词的权重,不能单独作为判定负面情感突发话题的依据,以至于会将部分主题词频变化率高的非负面情感突发话题误认为是负面情感突发话题(如吴亦凡参加快乐大本营),从而导致检测准确率的降低。又因为EBM-TD 算法采用定长滑动窗口的方法,窗口可能会将话题切分开,使得主题词频变化率达不到阈值而将突发话题遗漏,如“女乘客辱骂滴滴司机”,该突发话题从10:00 持续到12:00,而EBM-TD 算法中两个定长滑动窗口分别为8:00—11:00、11:00—14:00,由于话题被窗口切分,主题词频变化率没有达到阈值,所以未能检测到这一突发话题,从而导致召回率的降低。而本文所提出的NE-BTD 算法根据每一条微博信息实时计算突发特征,其中主题词对加速度能够将一般话题过滤掉,负面情感强度变化率能够有效地发现突发话题中负面情感突发话题。
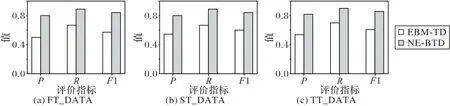
图4 两种检测算法的P、R、F1值Fig.4 P,R,F1 values of two detection algorithms

表2 部分话题持续时间及被检出情况Tab.2 Duration and detected status of some topics
4.3 NE-BTD算法检测的时效性
为了评价NE-BTD 算法检测负面情感突发话题的时效性,比较了NE-BTD、EBM-TD 两种算法检出同一负面情感突发话题的时间,如图5所示。
图5 为五个负面情感突发话题每分钟相关话题微博数随时间变化的情况,以及两种算法检出负面情感突发话题的时间。由图5 可知,本文提出的NE-BTD 算法相较于EBM-TD 算法至少提前40 min检出负面情感突发话题,这是因为:本文算法实时进行主题词对加速度、微博文本流负面情感强度变化率的计算,当加速度和变化率均达到阈值时则认为存在负面情感突发话题;而EBM-TD 算法由于采用定长滑动窗口的方法,要比较当前窗口和历史窗口主题词频的变化情况,所以只有当滑动窗口结束后才进行主题词频的分析,以至于其检测出负面情感突发话题的时间滞后。
4.4 负面情感突发话题的主题结构
在表3 中列举了3 个负面情感突发话题,以及EBM-TD 算法检测出的突发词和NE-BTD 算法检测出的突发词对。为获取负面情感突发话题的主题结构,本文采用GSDMM 聚类算法对负面情感突发话题窗口中的微博文本聚类。以“春运首日火车票购买困难”这一负面情感突发话题为例,NE-BTD 算法检测出了四个突发词对,将交叉、重叠或相邻的突发词对窗口合并得到负面情感突发话题窗口,通过对窗口中的微博文本聚类分析,得到该话题的两个主题结构,分别为:1)关于春运首日,民众购买火车票困难的讨论;2)民众对于12306 购票软件候补功能的讨论。
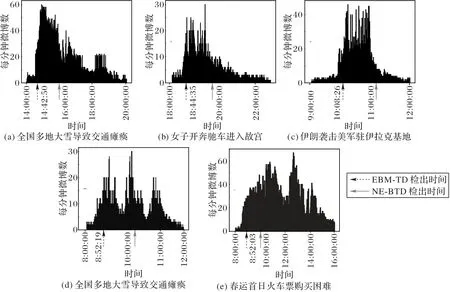
图5 两种算法检出同一负面情感突发话题的时间对比Fig.5 Time comparison of two algorithms on detecting same negative emotion burst topic

表3 负面情感突发话题主题结构Tab.3 Topic structures of negative emotion burst topics
4.5 参数ε、δ对算法P、R、F1值的影响
为分析不同的突发词对加速度阈值ε、微博文本流的负面情感强度变化率阈值δ,对本文所提出的NE-BTD 算法的准确率、召回率、F1 值的影响,在FT_DATA、ST_DATA、TT_DATA三个数据集上进行了实验。
本文设置突发词对加速度阈值ε为0.10~0.20、微博文本流的负面情感强度变化率阈值δ为0.15~0.30进行实验,实验结果如表4所示。
由表4 可知,当ε值一定时,随着δ值的增大,算法的召回率下降,这是因为随着δ值的增大,会将部分负面情感强度变化率低的负面情感突发话题过滤掉,导致算法的召回率下降。通过比较数据可知,当ε为0.15、δ为0.20 时,在三组数据中的效果最优,算法的准确率保持在80%以上,召回率保持在88%以上。

表4 ε一定,不同δ对算法P、R、F1的影响Tab.4 Under same ε,different δ influence on P,R,F1 of algorithm
5 结语
本文针对如何及时有效地检测出微博文本流中负面情感突发话题的问题,提出了一种面向微博文本流的负面情感突发话题检测算法,该算法通过检测主题词对速度、加速度来发现突发话题,通过检测微博情感强度、微博文本流的负面情感强度、负面情感强度变化率将负面情感突发话题与非负面情感突发话题区分开来。本文利用突发词对速度确定负面情感突发话题的窗口范围,有效解决了传统检测方法中滑动窗口难以确定的问题,最后采用GSDMM 聚类算法对负面情感突发话题窗口内的微博文本进行聚类,得到负面情感突发话题的主题结构,并在实验中验证了本文所提算法的有效性。在未来的工作中,我们将针对参数的取值进行深入研究使其更加精准有效,此外负面情感突发话题的演化、漂移问题,也是我们接下来研究工作的重点。
