基于多种聚类算法和多元线性回归的多分类主动学习算法
2020-12-31武禹伯
汪 敏,武禹伯,闵 帆
(1.西南石油大学电气信息学院,成都 610500;2.西南石油大学计算机科学学院,成都 610500)
(∗通信作者电子邮箱minfanphd@163.com)
0 引言
在油气测井中,储层岩性复杂多样,基于测井资料开展岩性识别在储层评价过程中具有重要意义[1]。在测井资料中携带着大量地层岩性、物性的地质信息,准确的地质信息对于无论是岩性识别还是储层评价都有着至关重要的影响。随着石油行业的快速发展,海量的测井数据处理对于测井人员来说费时费力,而且极大地影响了如岩性识别等石油相关领域的工作效率。近些年来,随着机器学习领域的不断发展,许多学者和石油领域工作者把目光放到了这两者的结合上。现阶段,有许多机器学习方法都被应用到了岩性识别领域,包括多元统计方法[2]、主成分分析方法[3]、模糊数学[4]、支持向量机[5]和人工神经网络[6]等。
主成分分析方法是一种统计方法,通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,并将这组变量称为主成分。陈伏兵等[7]提出了分块二维主成分分析法,在与传统二维主成分分析法的对比中,通过使用低维的鉴别特征矩阵,使得识别精度得到了进一步提高。周非等[8]提出了一种基于主成分分析和卡方距离的信号强度差指纹定位算法,通过使用主成分分析算法进行信号强度差数据降维和相关性冗余消除,使得定位误差得到了明显的减小。目前主成分分析方法已被广泛应用于石油相关等许多领域。
支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。张进等[9]提出了一种改进的支持向量机算法,通过使用粒子群优化和特征选择与参数联合优化,使得算法在分类精度上得到了明显提高。章少平等[10]针对不平衡数据集提出了一种优化的支持向量机集成分类模型,通过预处理不平衡数据并优化参数使得其算法相较于传统支持向量机算法具有更高的分类精度。目前支持向量机已被广泛应用于图像分类等许多领域。
人工神经网络是从信息处理角度对人脑神经网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。史兴宇等[11]提出了一种对汽车车牌进行智能数字识别的人工神经网络方法,通过引入离散型神经网络的联想记忆功能,使得该模型相较于传统人工神经网络具有更快的收敛速度和更高的识别精度。程宇等[12]提出了一种基于卷积神经网络的弱光照图像增强算法,通过将处理弱光照图像得到的派生图输入到卷积神经网络中,使得输出的图像拥有更好的视觉效果和图像质量。目前人工神经网络已被广泛应用于人工智能等许多领域。
主动学习方法[13-14]通过选择具有代表性的样本交由专家进行标记,将专家经验与机器学习进行结合。目前比较常见的主动学习方法有不确定性抽样法、基于聚类方法和基于委员会投票采样法。其中基于聚类主动学习致力于将聚类算法应用到样本选择策略中,利用数据的结构来选择代表性样本。Wang等[15]提出了基于密度峰值聚类算法的主动学习算法,通过将密度峰值聚类算法应用到样本选择策略中,在相同训练样本基础上使得算法的分类精度得到提升。贾俊芳[16]提出了基于层次聚类的主动学习算法,通过采用分层细化、逐步求精的方法提高了学习器的学习效率,获得满意的泛化能力。目前主动学习方法已被广泛应用于数据分类等许多领域。
应用到岩性识别领域中的机器学习算法虽将测井资料和机器学习算法进行了结合,但是想要获得良好的识别效果需要大量的标记样本。实际工程中,具有标记的样本是稀有且昂贵的。如何通过引入专家经验获取少量的标记样本,达到良好的识别效果,是本文首先考虑的问题。机器学习领域中的主动学习方法能够很好地解决这一问题,所以本文引入基于聚类算法的主动学习思想,但是基于单一聚类主动学习方法对于不同分布数据集的识别效果是不同的,因此,本文提出了基于多种聚类算法和多元线性回归的多分类主动学习算法(multi-category Active Learning algorithm based on multiple Clustering algorithms and multivariate Linear regression algorithm,ALCL),来解决上述提到的问题。首先,应用四种异构聚类算法对数据进行聚类,通过比较每种算法的聚类结果对数据进行初始标记与分类。然后,选取关键实例并求解目标函数得到每种聚类算法的权重系数。最后,引入权重系数进行决策分类的综合计算,将计算结果高于分类阈值的样本进行分类。分类阈值一般设置较高,如在所有迭代终止后仍存在无法分类的样本,则将截至目前所有的已分类样本作为训练集,采用K 最近邻(K Nearest Neighbor,KNN)分类方法[17]进行投票分类。
在大庆油田油井的6 个已公开测井岩性数据集上进行实验。在不同的查询比例下,实验对比了3 种经典监督学习算法和3种较新主动学习算法,通过Friedman和Nemenyi事后检验[18]验证了所提ALCL 与其他算法之间的显著性差异,在查询比例相同的情况下,ALCL有效提高了岩性识别精度。
1 相关工作
本文的数据实例模型是决策信息系统,决策信息系统定义成一个三元组:

式中:X代表一个数据集向量;X=Xtrain∪Xtest,Xtrain是训练集,Xtest是测试集;A代表一个条件属性向量;Y代表一个真实标签向量。
本文根据主成分分析方法、支持向量机和人工神经网络三种方法在岩性识别领域中的应用做了如下调研。
针对东营凹陷董集洼陷浊积岩岩性复杂的问题,周游等[19]提出基于粒子群算法以及核函数理论的主成分分析方法,通过建立新的主成分计算方法构建五个主成分变量代替原有多维测井信息来对该区岩性进行识别。实验结果表明该方法有效提升了该地区岩性识别的精度。杨兆栓等[20]针对塔中地区奥陶系碳酸盐岩岩性复杂的问题,根据该地区测井信息利用主成分分析方法构建了五个综合变量应用到识别模型中,有效提升了该地区岩性识别精度。传统主成分分析方法在岩性识别问题中并未考虑所用测井信息的可靠性,这导致新主成分变量在岩性识别中效果减弱,从而使岩性识别精度降低。若能引入专家地质经验则能更好地对测井信息进行优选,进而帮助到新主成分变量的构建中,进一步提高岩性识别精度。
张昭杰等[21]结合乌夏地区岩芯资料和测井数据,采用支持向量机法对该地区的岩性进行识别。应用遗传算法挑选出最佳的支持向量机核函数参数和惩罚因子,建立支持向量机岩性识别模型。实验结果表明该模型实际数据预测符合率达到81.6%。苏赋等[22]针对测井曲线间存在大量信息冗余的问题,通过合成少数过采样技术对数据集进行预处理,并提出模糊隶属度函数改进模糊孪生支持向量机算法。在北美Hugoton 油气田实际测井数据基础上应用该算法对其进行岩性识别,并取得了良好的识别效果。上述方法在实际建模过程中需要用到大量带有标签的训练样本。实际过程中很难获取大量的训练样本,所以基于支持向量机的岩性识别方法在实际应用中存在难以获取大量训练样本的问题。
单敬福等[23]针对苏里格气田岩性复杂的问题,提出利用优选输入向量的人工神经网络法对其进行识别。实验结果表明该方法相较传统人工神经网络法具有更快的收敛速度和更高的识别精度。陈钢花等[24]应用卷积神经网络法将岩性识别从高度非线性问题转换成多层非线性计算问题,通过构建双层卷积神经网络模型对储层岩性进行判别。实验结果表明该方法较其他岩性识别方法具有更高的识别精度和更快的速度。人工神经网络法自设计以来一直存在着无法解释输入与输出之间关系的问题。较其他传统机器学习算法来说,传统人工神经网络法需要更多的带标记样本作支撑才能达到良好的识别效果。在岩性识别应用中,若仅用有限的带标记样本进行识别,则会导致识别精度不高。
传统基于聚类算法的主动学习都仅在一种聚类算法上进行应用和优化改进,而每种不同的聚类算法都有其适合的数据分布形式,如K均值(K-Means)聚类算法[25]对于球形数据分布的数据集具有良好的聚类效果,而像密度峰值聚类算法(Density Peak Clustering Algorithm,DPCA)[26]则对非球形数据分布的数据集具有良好的聚类效果。对于基于单一聚类算法的主动学习来说,分类效果的优劣取决于单一聚类算法的质量和是否适用于这一聚类算法的数据集。这导致在实际应用中面对各种各样不同分布的数据集时,算法的泛化能力较差。
2 本文算法
通过主动融合专家经验,选取少量关键样本作为训练样本,结合过程清晰的聚类算法,并针对基于单一聚类主动学习算法适用数据集有限、泛化能力差的问题,提出了本文的ALCL,其执行步骤如下:
1)对岩性识别数据集进行预分类;
2)根据预分类结果对未分类样本进行关键实例选取;
3)以所选关键实例为基础建立多元线性回归模型,并求解目标函数获得聚类算法的权重系数;
4)根据决策分类方法将符合分类标准的样本进行分类。
图1给出了ALCL的整体流程。
2.1 聚类算法的预分类方法
岩性识别问题中,不同地层所对应的岩性是不同的,且岩性种类较多,聚类算法对岩性识别数据集进行聚类的同时无法对聚成的每簇进行类别的划分。本节采用结合K-Means、DPCA、模糊C 均值聚类算法(Fuzzy C Means clustering algorithm,FCM)[27]和层次聚类算法(Hierarchical Clustering Algorithm,HCA)[28]这四种聚类算法聚类,并查询公共点的方法解决上述问题。预分类方法也为后面关键实例的选取以及目标函数的建立与求解打好基础。预分类方法的具体流程如下:
1)应用四种异构的聚类算法,对同一数据集进行无类别划分的聚类操作。每种聚类算法根据自身的聚类原则,将数据集划分成预先设定好的簇数。
2)以其中一种聚类算法为基础,将这个聚类算法聚成的簇数同其余几种聚类算法的簇数进行一一的查询比较。根据交集个数最多被分为一类的原则,依次对每种聚类算法的簇数进行划分,从而得到所需要的类数。
3)查找每类中的交集部分,将其前几个样本点与专家进行交互获得其真实类别。将这几个样本点中,类别相同个数最多的类别定义为这一类中所有点的伪标签。同时,为保证所有类别都能被标记成伪标签,在之后的类别交互过程中,已被标记了伪标签的类别不再计算其类别个数。

图1 ALCL流程Fig.1 ALCL flowchart
图2 通过四个部分展示了在簇数取2 时,对假设的10 个初始样本进行预分类的具体过程。图中用黑色方框和灰色方框来区分每种聚类算法聚类获得的簇分布。在第三和第四部分中,灰色样本表示当前类中的交集部分,通过将这些灰色样本与专家进行交互以获得其真实类别。图中以正类和负类作为真实类别来区分10个初始样本的类别。
2.2 关键实例选取方法
传统的岩性识别方法难以和地质经验进行有效的结合,本文根据样本的代表性和信息量设计了关键实例的两种选取策略。通过将选取到的关键实例交予专家进行标记,实现专家经验与数据间的交互。经过人机交互后,专家的地质知识也为后面建立训练模型提供了可靠的帮助,进而优化识别模型,提高岩性识别精度。
2.2.1 优先级最大搜寻策略
在主动学习中,主动地找到对算法影响效果最好的查询样本是整个学习过程中非常重要的一环。找到优先级最大的样本就是为了找到对算法影响效果最好的样本。对优先级定义的步骤如下:
1)定义局部密度。
样本x的局部密度ρ定义为:

式中:dc表示截止距离;dist表示两个样本之间的欧氏距离;χ()为一个判断函数。若括号内的值小于0,则χ=1;若括号内的值大于等于0,则χ=0。
2)定义与高密度点之间的最小距离。
样本x与局部密度更高的样本点的最小距离定义为:

3)定义优先级。
样本x的优先级定义为:

根据式(4)计算测试集Xtest中每一个样本的优先级,找到优先级最大点xmax,根据式(5)循环计算k次,得到离xmax最近的k个样本xnearest。将xnearest和xmax作为关键实例,并加入到训练集Xtrain中。
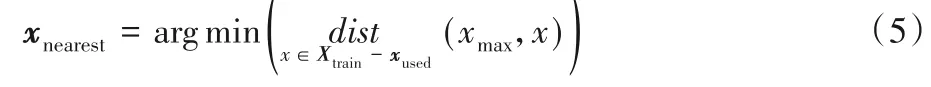
式中:xused为当前已被得到的离xmax最近的样本点。
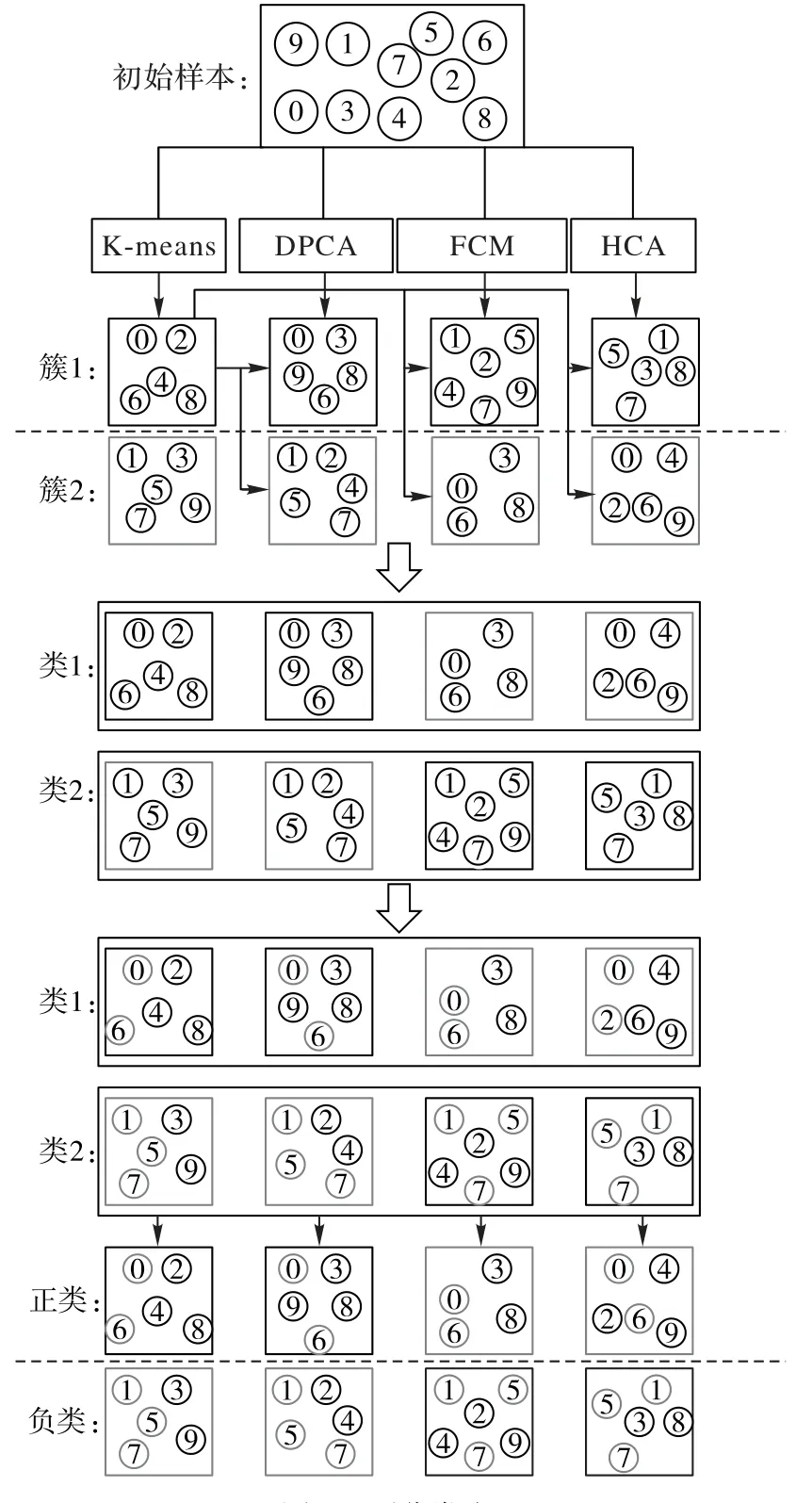
图2 预分类流程Fig.2 Pre-classification flowchart
2.2.2 最混乱查询策略
预分类过后,测试集Xtest中每一个样本点都被4种聚类算法标上了各自的伪标签。首先,定义最混乱:ALCL 共用到4种聚类算法,在进行了预分类处理之后每种聚类算法都对每一个x∈Xtest标记了各自的伪标签。若每种聚类算法对应同一个样本点的伪标签基本都不相同,那么则称这个样本点当前处于最混乱情况,应被交互查询真实标签并作为关键实例加入到训练集Xtrain中。然后,图3 具体地展示了样本点x的最混乱查询策略的过程。最后,如图3 所示,ALCL 所用聚类算法个数为4,因此在伪标签个数一栏中所能出现的最大值为4,当且仅当伪标签个数最大值小于等于2 时,当前样本点被认为处于最混乱状态,可以被选取为关键实例。
2.3 聚类集成方法
本节设计了一种基于多元线性回归[29]的聚类算法集成模型。在进行了预分类和关键实例的选取后,将选取得到的关键实例同多元线性回归模型相结合,构建预测标签值的计算函数,进而构建用于求解每种聚类算法权重系数的目标求解函数。通过最小化目标求解函数得到每种聚类算法的权重系数。每种聚类算法的权重系数代表着在当前迭代中该聚类算法在样本预测中所占的比重。权重系数越高,那么该聚类算法在样本预测中的决定程度就越高;相反,则决定程度就越低。
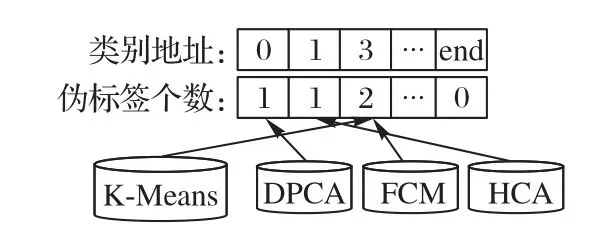
图3 最混乱查询策略Fig.3 Most confusing query strategy
首先,根据选取的关键实例结合多元线性回归模型建立样本标签值的计算函数,即

然后,根据样本标签值计算函数构建用于求解权重系数向量θ的目标函数,即

式中:Hi是每个关键实例的预测标签值;yi是真实标签值。
对式(7)进行最小二乘变形得到:

对式(8)进行展开得到:

对式(9)进行求导并令导数为0,得到:

最后,通过对式(10)求解,得到最终的求解函数为:

通过对式(11)进行求解后,得到权重系数向量θ=(θ1,θ2,θ3,θ4)。该向量中各系数存在着较大的范围差异,且系数可能出现为负的情况。这使得在决策分类过程中每种聚类算法的优先级不能够很好地展现。为解决上述问题,需对权重系数向量θ进行归一化处理。

式中:w是归一化权重系数值。通过式(12)对权重系数向量θ进行归一化处理后,得到归一化权重系数向量,记为W=(w1,w2,w3,w4)。
2.4 决策分类方法
在获得归一化权重系数向量W后,需要根据每种聚类算法的权重系数进行决策分类的综合计算,将计算结果超过阈值的样本点进行分类,计算式如下:
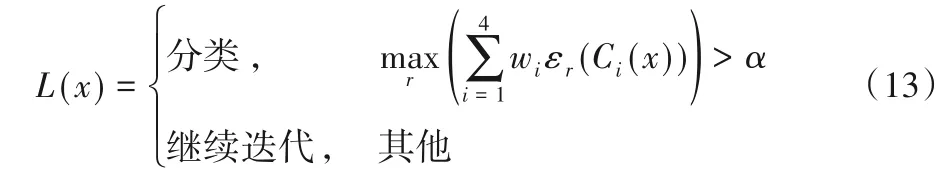
式中:εr()是一个判断函数,若括号内的值等于r则εr=1,否则εr=0;C是每个样本对应每种聚类算法的伪标签值;r是数据集的真实类别数;α是决策阈值。
进行决策分类后,可能会出现仍未被分类的样本点。剩余样本的分类策略为:通过KNN 分类方法对剩余样本点进行分类。ALCL 中KNN 分类方法使用的训练集包含通过决策分类方法得到的分类样本。这些样本点的类别标签并不一定是这些样本点的真实标签。但是通过对α大小的设置,可以增加这些分类样本的可信度。通过这种处理方式,可以尽可能增加KNN分类过程中训练集的大小,进而提高KNN分类方法的准确率,同时可以减少与专家进行交互时所花费的代价。
2.5 伪代码及复杂度分析
基于多种聚类算法和多元线性回归的多分类主动学习算法(ALCL)的框架如算法1 所示。第1)行为数据预处理过程,第4)~6)行为预分类过程,第7)~10)行为选取关键实例过程,第13)行为获取权重系数过程,第14)~21)行为决策分类过程。

表1 列出了ALCL 的时间复杂度,得出算法1 的时间复杂度为:

式中:m为条件属性的个数;n为样本的总个数;n′为当前未被分类的样本个数,且n′总是小于n。

表1 ALCL的时间复杂度Tab.1 Time complexity of ALCL
3 实验与结果分析
本章将展示所用测井岩性数据集上的实验结果,并进行分析。实验使用Java软件并结合Weka,在具有16 GB RAM 和Intel Core i5-9400F CPU @ 2.90 GHz 处理器的Windows 10 64位操作系统上执行了运算,并应用大庆油田油井的6 个公开测井岩性数据集,将ALCL 在岩性识别上的效果与KNN、决策树分类算法(Decision Tree Classification Algorithm,DTCA)[30]和朴素贝叶斯(Naïve Bayes,NB)[31]三种传统监督学习算法,基于委员会投票的主动学习算法(active learning algorithm with Query By Committee,QBC)[32]、基于两阶段聚类的主动学习(Active Learning through Two-stage Clustering,ALTC)算法[33]和基于密度峰值聚类的主动学习(Active Learning through Density Clustering,ALDC)算法三种较新主动学习算法进行比较。实验代码将公布在GitHub 上,提供下载和证明。
实验以自然伽马(Natural Gamma,NG)、声波时差(Sonic Jet,SJ)、补偿密度(Compensation Density,CD)、微梯度电阻率(Micro Gradient Resistivity,MGR)、浅横向电阻率(Shallow Lateral Resistivity,SLR)、深侧向电阻率(Deep Lateral Resistivity,DLR)等对岩性变化反映比较敏感的测井参数作为输入参数。每个样本代表不同储层深度的位置,样本个数为611~733。每个数据集的类别个数均为4,分别是页岩(SHale,SH)、粉砂岩(SIltstone,SI)、砂岩(SAndstone,SA)和钙质砂岩(Calcareous Sandstone,CS)。实验所用数据集如表2所示。

表2 数据集描述Tab.2 Dataset description
实验采用分类精度accuracy作为评估指标。

式中:|Xtrain|为训练样本数;|Xtest|为测试样本数;error为误分类数;|X|为总的样本数。
首先进行了ALCL 同三种主动学习算法的参数调节实验,得到实验效果最好的查询比例。接着,取实验效果最好的查询比例,将本文的ALCL 具体地同三种监督学习和三种主动学习算法作比较。
3.1 参数调节实验
实验通过不断增加查询比例,以期望找到每种算法的最佳查询比例。每个数据集上共进行5组实验,每组实验重复5次,得出分类精度后取平均值,以减小实验误差。对于每个数据集,第一组实验取数据集的1%作为查询比例,以后每组实验查询规模递增数据集的2%。
通过图4 得到每种算法在对应同一个数据集上的分类精度变化情况。图4 分别表示在6 个测井岩性数据集上的实验结果,纵轴表示对应不同查询比例时每种算法的分类精度结果。
根据图4 可以看出,四种算法的分类精度在随着查询比例增加时基本呈整体上升趋势,但ALEC 的增长趋势并不明显,基本处于稳定状态。在图4(a)、(b)、(d)、(e)中,本文ALCL 在对应不同查询比例时的分类精度基本都比其他算法高;但在图4(c)、(f)中,ALCL 的分类精度基本均低于ALTC。在图4(a)、(c)、(d)中,均有三种算法在查询比例为5%时取得分类精度最大值。图4(b)中,更是四种算法全部在查询比例为5%时取得分类精度最大值。图4(f)中,也同样有两种算法在查询比例为5%时取得分类精度最大值。因此,可以认为在查询比例取5%时对应每种算法的分类效果最好。
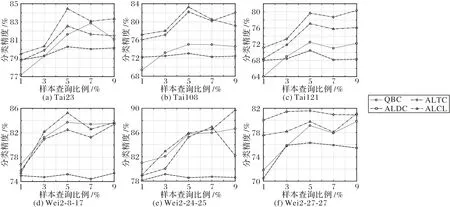
图4 递增查询比例时每种算法的分类精度结果Fig.4 Classification accuracy results of algorithms with query ratio increasing
3.2 与监督学习算法对比
3.1 节中,通过将ALCL 同三种主动学习算法对比得到最佳查询比例为5%。本节在查询比例取5%时将ALCL 同KNN、DTCA、NB 三种经典监督学习算法进行对比,以期望得到更好的岩性识别效果。表3 展示了ALCL 与三种监督学习算法在查询比例为5%时的分类精度结果。

表3 ALCL与3种监督学习算法的分类精度比较结果(均值±标准差)Tab.3 Comparison results of classification accuracy among ALCL algorithm and 3 supervised learning algorithms(mean±standard deviation)
表3 中,本文提出的ALCL 在Tai23、Tai108 和Wei2-8-17三个数据集上的分类精度达到最高,在其余三个数据集上也是达到了第二高的分类精度。使用Friedman 和Nemenyi 事后检验分析算法的性能。由Friedman 检验得出的排名中,ALCL的排名均值为1.500 0,位于所有算法的第一位。
表4给出了通过Nemenyi检验获得的t值。在显著性水平因子β取0.1 时,ALCL 对比KNN 算法和DTCA 的t值均小于0.1。因此,ALCL明显优于KNN和DTCA。ALCL对比NB算法的t值虽大于0.1,但在排名均值上ALCL 小于NB 算法,且t值为0.117 525,仅超出0.017 525。因此,ALCL略优于NB算法。

表4 假设检验(Ⅰ)Tab.4 Hypothetical test(Ⅰ)
3.3 与主动学习算法对比
在查询比例为5%时,每种算法对应每个数据集的分类精度结果如表5 所示。表5 中,本文提出的ALCL 在Tai23、Tai108、Wei2-8-17 和Wei2-24-25 四个数据集上的分类精度达到最高,在Tai121 和Wei2-27-27 两个数据集上也是达到了第二高的分类精度。使用Friedman 和Nemenyi 事后检验分析算法的性能。由Friedman检验得出的排名中,ALCL的排名均值为1.333 3,位于所有算法的第一位。

表5 ALCL与3种主动学习算法的分类精度比较结果(均值±标准差)Tab.5 Comparison results of classification accuracy among ALCL and 3 active learning algorithms(mean±standard deviation)
同时,使用Nemenyi 事后检验来分析是否存在显著差异。表6给出了通过Nemenyi检验获得的t值。在显著性水平因子β取0.1 时,ALCL 相较QBC 算法和ALDC 算法的t值均小于0.1。因此,ALCL 明显优于QBC 和ALDC 算法。ALCL 相较于ALTC 算法的t值虽大于0.1,但在排名均值上ALCL 小于ALTC算法。因此,ALCL算法略优于ALTC算法。

表6 假设检验(Ⅱ)Tab.6 Hypothetical test(Ⅱ)
4 结语
针对传统机器学习算法需要大量标记样本,且基于聚类主动学习算法适用于数据集有限、分类精度差的问题,本文提出了一种基于多种聚类算法和多元线性回归的多分类主动学习算法(ALCL)。基于多元线性回归模型的聚类算法集成策略能够很好地将结构完全不同的几种聚类算法进行结合,通过将求解得到的权重系数与主动学习建立联系,实现对岩性的识别分类。该算法能够很好地应用于岩性识别问题。在6个真实岩性识别数据集上的实验结果表明,该算法可以有效提高岩性识别的精度。未来的研究工作主要包括以下三个方面:1)增加或更换新的聚类算法以提高ALCL 的分类效果;2)改进几种聚类算法的初始聚类中心选择策略,从而优化聚类结果;3)研究更优的聚类集成策略。
