基于K-means算法的Co-trainning的研究
2020-12-29李恋柴豪森徐浩
李恋 柴豪森 徐浩

摘要:在Co-trainning算法中通过两个训练集互相校正来达成分类,这里两个训练集所用的特征集对结果影响很大,选取两个好的特征集也就可以使Co-trainning算法结果更优。K-means算法是一种聚类算法,在对K-means算法研究和实现时,设计并实验将K-means算法思想运用到Co-trainning算法特征集选取上,效果较好。
关键词:K-means算法;Co-trainning算法
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2020)32-0216-02
1 引言
早在1998年,Blum于“Combining labeled and unlabeled data with co-training”一文中提出了Co-training的思想。一直以来,该方法的应用领域主要集中在网页分类、双向识别系统、移动目标检测等。
Co-trainning算法是Self-training(自训练)算法的改进版,简单来说就是将一堆杂乱数据通过现有的一些数据特点和数据本身特点进行分类,这是一种半监督学习算法。K-means算法是一种聚类方法,为了优化K-means算法,人们提出了很多改进的算法,全局K均值聚类算法[1]就是一种改进方法。这里在对传统K-means算法进行研究和实现时,通过对结果的分析与思考,研究是否有可能运用到Co-trainning算法中的特征集选择上。
2 K-means算法
传统K-means算法简单来说就是以下几个步骤:1)确定要将数据聚成多少类,也就是先从数据集中随意选k个聚类中心;2)计算各个数据到k个聚类中心的距离,距离哪个中心近就分到哪个聚类中;3)计算各个聚类的平均值,使该平均值取代原来的聚类中心;4)重复二、三步,当前后两次结果差不多时,结束算法;5)传统K-means算法有着k值初始值选择和结果存在随机性等局限[2]。
3 Co-trainning算法
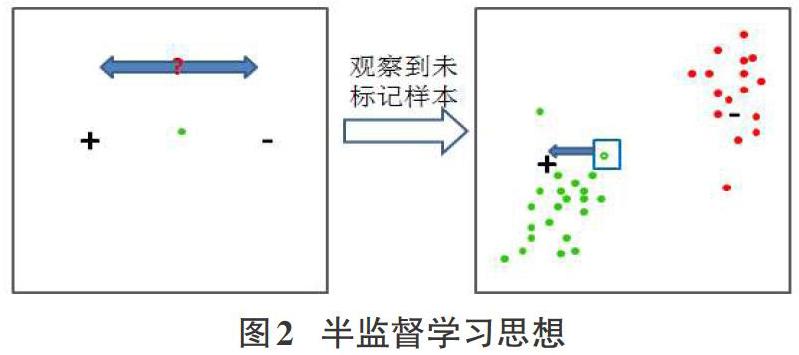
在介绍Co-trainning算法之前,需要了解一下半监督学习的一类思想。通过图2可以看出,图2左边无法判定待判别样本是“+”还是“-”,因为,待判别样本周边只有一个“+”样本和一个“-”样本。如图2右边,待判别样本周边已知众多“+”“-”样本,所以,能够根据待判别样本的相对位置判断该样本到底属于哪一个类别。
Co-trainning算法是一种典型的半监督学习方法,其本质就是一个交叉训练的过程。算法步骤如下。
1)导入有标记的数据集和无标记的数据集。
2)划分测试集和两个训练集,其中训练集中有标记的样本为少部分,大部分为无标记的数据。
3)分别用两个训练集中有标记样本训练形成两个分类器,然后用这两个分类器分别对各自训练集中部分无标记样本进行分类标记,标记后的数据加入另一个训练集的标记样本中。
4)重复第三步,直到分类器不再发生变化或到达设定轮数。
5)用训练形成的最终的两个分类器对测试集进行分类,然后通过混淆矩阵计算分类准确率[3]。
4 实验
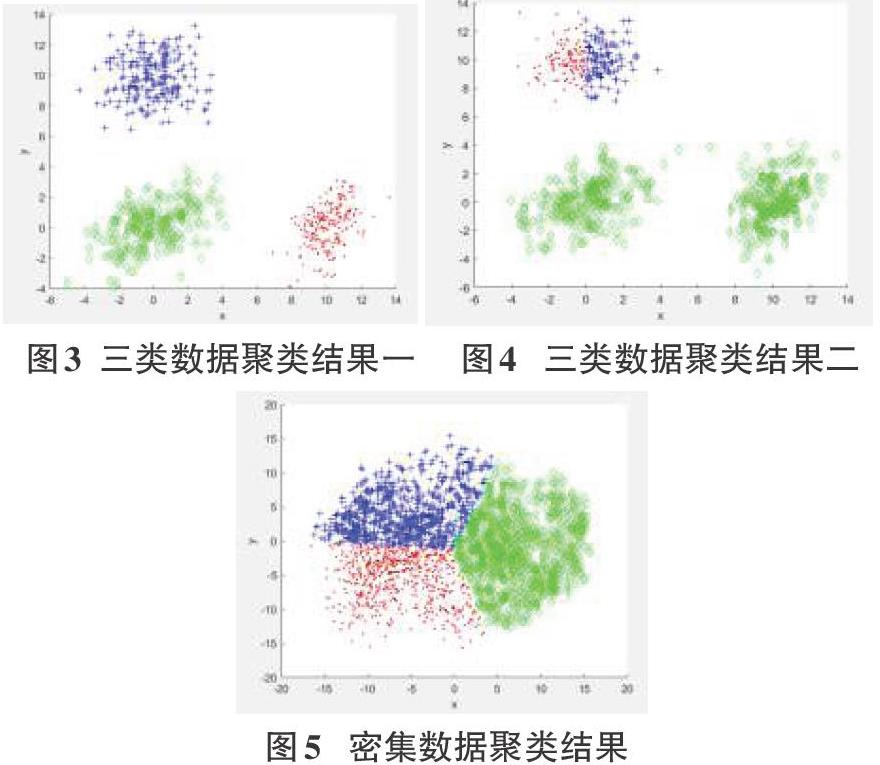
首先进行K-means算法的实现。这里取k值为3,分别对三类数据集和比较密集的数据集进行聚类算法。实验结果如图3、图4和图5所示。
由图3和图4可以看出传统K-means算法结果的随机性,而对于数据比较密集,数据距离跨度不大时,传统K-means算法结果是稳定的。
接下来进行典型Co-trainning算法的实现。这里使用的数据集合是从网上下载的mfeat-kar数据集。训练集中初始有标记样本占10%,这里有标记样本和无标记样本为随机抽取得到。实验结果如表1所示。
在进行Co-trainning算法时,选取的有标记样本对实验结果会有很大影响。在前面进行K-means聚类算法时,考虑将聚类思想运用到选取有标记样本中。于是这里将有标记样本进行一定的分配,使两个训练集的有标记样本有一定的差距。这样做主要为了使两个训练集更好地互相校正来达到形成更好的分类器。
基于上面的想法,下面对标记样本进行尽量相似地放在一边的处理后又一次进行了Co-trainning算法实验。实验结果如表2所示。
由表1和表2对比可知,明显处理后准确率降低了。在对Co-trainning算法的进一步了解后,对数据集进行多次调整以及测试后发现了降低的原因。上面对训练集的标记样本选取虽然使其独特性大了些,但是使得样本不够齐全。因为要想训练出一个好的分類器,标记样本需要尽量包含全面,而样本不齐全情况下,训练出的分类器反而比原先的要差。
5总结
本文对K-means算法和Co-trainning算法进行了实现。在将聚类思想运用到选取更有特性的标记集后,因为同时降低了能产生最优分类器的信息量,所以最终结果实验准确率反而降低了。为了提升Co-trainning算法准确率,需要学习更多知识,寻求即能保证特性又能触及更多信息的标记数据选取方法。
参考文献:
[1] 陶莹,杨锋,刘洋,等.K均值聚类算法的研究与优化[J].计算机技术与发展,2018,28(6):90-92.
[2] 王巧玲,乔非,蒋友好.基于聚合距离参数的改进K-means算法[J/OL].计算机应用:1-6[2019-08-30].http://kns.cnki.net/kcms/detail/51.1307.TP.20190520.0947.002.html.
[3] 陈善学,尹修玄,杨亚娟.基于码字匹配和引力筛选的半监督协同训练算法[J].武汉大学学报·信息科学版,2015,40(10):1386-1391,1408.
【通联编辑:李雅琪】
