基于注意力模型的卷积循环神经网络城市声音识别
2020-12-29赵红东
杨 磊, 赵红东
(河北工业大学电子信息工程学院, 天津 300300)
近年来,中外研究学者在环境声音识别(environment sound recognition,ESR)领域不断取得新的突破,并将研究成果广泛应用在场景分析和音频监控系统等方面[1-3]。大量的研究工作集中在语音、音乐和生物声学等相关子领域上,对城市声学环境领域的研究则相对较少,而且具体研究工作往往局限在声学环境分类的子集上,对特征提取技术的关注也较少,以往的工作部分解决了城市声音分析的需要。
通常ESR的特征提取方式主要分为两类。一类是从音频信号中手动提取相关的短期特征,如梅尔倒谱系数(MFCC)、音高和能量等,然后将短期特征应用于一般分类器,如高斯混合模型、矩阵分解[4]和隐马尔可夫模型。文献[5]详细分析了该类方法。另一类是使用神经网络自动提取特征,如卷积神经网络(CNN)、自动编码器[6]、循环神经网络(RNN)及卷积神经网络加长短时记忆模型的组合等。文献[7-8]研究表明,这些方法在语音分类领域都能表现出良好性能。
提出一种将CNN、双向长短时记忆网络(BiLSTM)和注意力机制(attention-mechanism)三者结合起来的模型结构。首先将音频信号用梅尔频谱倒谱系数(MFCC)表示;其次利用卷积神经网络按时间顺序对频谱分片,并从每个片段中提取与城市环境声音相关的特征,同时保留提取特征中的时间信息;然后对提取出的特征矩阵实施双向长短时记忆网络以模拟与目标分类密切相关的时间信息;最后应用注意力机制对双向长短时记忆网络的输出矩阵进行加权再通过分类器得到关于城市声音的识别率。为使模型结果具备可比性,采用Urbansound8K数据集[9]。
1 实验数据集及预处理
Urbansound8K数据集的数据来源于从Freesound在线档案中截取的现场声音记录,将现场记录分割成持续时间最长为4 s的8 732个时间片段,每个片段包含10种可能的声源之一,包括:空调(AC)、汽车喇叭(CH)、儿童游戏(CP)、狗叫(DB)、钻孔(DR)、发动机空转(EI)、枪击(GS)、手提钻(JH)、警报器(SI)和街头音乐(SM)。这些城市声音分类是根据纽约市311服务热线提供的数据(2010年迄今为止的370 000多起投诉)中关于噪声投诉事件中被投诉次数最多的10种声源。由于这些是真实的现场记录,因而除依据投诉内容就可以直接标识声源外,片段中还可能存在投诉人表述时的各种背景声音。鉴于这一现实情况,数据收集者需要根据投诉内容手动标识出片段中的声源类别,并主观判断这种声音是处于片段中的前景还是背景中。实验将数据集分成训练集、验证集和测试集,具体信息如图1所示。

图1 数据集分布Fig.1 Dataset distribution
由于人耳感觉到的声音高低与声音的频率不是线性关系,听觉对低频信号比高频信号更敏感,梅尔频率刻度更符合人耳听觉特性,因而MFCC被广泛应用在语音识别系统中。在环境声音分析领域,MFCC常被用作衡量新技术优势的基准[10]。在实验中,以25 ms的窗口大小和10 ms帧长为参数从音频片段中提取特征,计算出0~22 050 Hz的40个梅尔(Mel)波段,并保留40个MFCC系数,得到特征矩阵为40×160×1,即频率×时间×通道,具体过程如图2所示。

图2 数据预处理流程图Fig.2 Data preprocessing flowchart
2 模型构建
为将数据输入模型,首先将音频信号用频谱图表示,然后按时间顺序将其切割成四等份,即将特征矩阵40 × 160 × 1切分成4个按时间顺序排列的40 × 40 × 1特征矩阵。由于城市环境声音的语义完整表达在时间轴上具备连续性的特点,因此每个特征矩阵同时含有时间和空间信息。输入的音频信号被表示成频谱图片段,它们就具有与图像序列相同的属性,因而可先使用CNN对片段提取分层影响特征;再运用BiLSTM进一步提取隐藏在这些特征矩阵中与环境音分类相关的动态时间信息;然后在最终分类前实施注意力机制以关注BiLSTM输出序列中对判断结果影响最大的那部分特征;最后将识别出来的特征输入分类器中得出判别率。图3为模型的结构示意图。
2.1 时间分布卷积神经网络
CNN是一个非常成功的模型,它在图像识别领域取得许多突破性成果。在本模型中,CNN使用三组结构,每组结构由一个卷积层和一个池化层组成。卷积层的作用是使用滤波器矩阵扫描输入的频谱图片段以生成与滤波器的数量相匹配的多个特征映射;池化层通过最大化函数来压缩前面卷积层输出的特征映射。在CNN 深层网络中可根据研究需要建立多组重叠结构的卷积层和池化层。

图3 基于注意力机制的卷积循环神经网络Fig.3 Attention-based convolutional recurrent neural network
时间分布卷积神经网络是用固定大小和时间步长的窗口按一定顺序扫描梅尔频谱图片段,输入的特征矩阵大小为40 × 40 × 1,4个片段共享一个CNN网络,然后CNN中的每一个的输出序列将被馈送下一层BiLSTM中。CNN在从音频信号的频谱图片段中提取区分特征方面起着非常重要的作用。
2.2 双向长短时记忆网络
由于城市环境声音的语义完整表达在时间轴上具有连续性,即当前时刻的音频信息与前一时刻的音频信息相关,因此可以对CNN输出的特征矩阵实施长短时记忆网络(LSTM)。LSTM是一种特殊的循环神经网络(RNN)。随着序列长度的增加,RNN的计算量呈级数增加,因而它在训练中存在梯度消失和爆炸的问题,导致对当前位置的片段信息判断时会忽略位置较远的片段信息。LSTM的核心思想是在RNN网络中设置一类参数,选择性地保留相对位置较远的片段信息,并使其参与到对当前片段信息的判断过程中。
标准的LSTM只能在一个方向上处理序列数据,因此提出BiLSTM来克服这一限制。BiLSTM是由两个相互连接的双向LSTM构成,它对输入的音频序列同时以向前和向后的方式进行读取,产生两个隐藏状态的序列,然后将二者串联得到一个最终的BiLSTM的隐藏状态。这种方式能使对每一片段的判断结果既包含该片段的所有前项信息,又涵盖其所有后项信息,表达式为

(1)

(2)

(3)


图4 双向长短时记忆网络结构Fig.4 Bidirectional long and short time memory structure
2.3 注意力机制
为让BiLSTM网络模型能关注到与学习过程最相关的信息,注意力机制(attention-mechanism)可对输入向量x的每一部分赋予不同数值的权重,对重要信息给与较大权重,对不重要的信息赋予较小权重,然后得出综合的评分,从而使模型能做出更加准确的判断,而且不会增加模型的计算和存储负担。注意力机制已在许多领域中取得重大进展,如自然语言处理、图像分割等,其本质上是一种新的加权汇集策略,通过权重值的大小,让模型更专注于包含关键特征的帧片段部分,注意力层的输出值Z由输入序列加权求和得出,如式(4)所示:

(4)
式(4)中:权重ai由注意力模型中的输入向量x决定,其表达式为
(5)
式(5)中:xi∈x,xj∈x;f为评分函数,是由训练参数矩阵W和输入向量x共同决定的线性函数,其表达式为
f(x)=WTx
(6)
实验中,注意力机制为BiLSTM的输出序列中每个部分赋予不同的权重。
2.4 实验设置
实验模型将参数整流器线性单元(ReLU)[11]作为激活函数;在CNN层后设置全局最大池化层;最后在全连接层后应用softmax输出判断结果。在模型结构中,还使用两个密集连接层;采用最小化分类交叉熵训练模型;为防止过拟合将dropout运用在模型中[12]。在图形处理器(GPU)上运用Keras 2.0和Tensorflow 1.14技术建模,并使用LibROSA进行信号转换。实验超参数设置为:dropout参数:0.3、优化随机梯度下降(SGD)(学习率:0.015,衰减:1×10-6,动量:0.8)、训练轮数:200、批量数:64。模型训练结果如图5所示。

图5 模型训练结果Fig.5 Model training results
3 实验结果与分析
首先进行消融研究,使用CNN、LSTM、CNN+BiLSTM及本文模型对同一数据集进行细颗粒度对比分析,CNN输入的特征矩阵为40×160×1,BiLSTM为160×40,CNN+BiLSTM为4×40×40×1。实验结果如表1所示。
其次对实验结果进行细颗粒度分析,从图6、图7 可以看出,实验模型在各个分类结果上都优于其他对比模型。
最后,表2列举本文模型和外国研究学者发表的应用在Urbansound8K数据集上关于城市环境声音识别的模型分类准确率。与文献[7]提出的最先进的CNN架构相比,本文模型准确性超过了文献[13-14]的基于神经网络的实验结果。Chen等[16]将扩张型CNN引入到ESR中,其效果比采用最大池化和其他最新方法的CNN更好。Ye等[17]提出了一种组合局部和全局声学特征的聚合方案,为表征局部模式采用特征学习方法来提取依赖于类的时域光谱结构,也取得较好效果。本文模型获得80.2%分类准确度,这是使用Urbansound8K数据集且未做数据增强情况下获得的基于神经网络较高准确度。
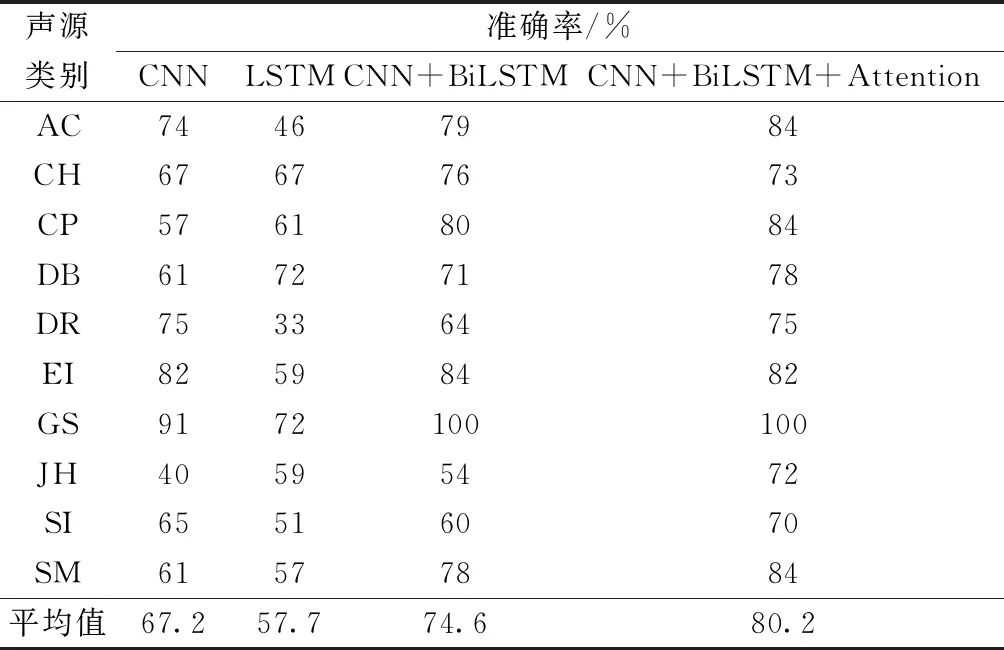
表1 四种模型的分类准确率对比

图6 CNN+BiLSTM+Attention混淆矩阵Fig.6 Confusion matrix for the CNN+BiLSTM+Attention
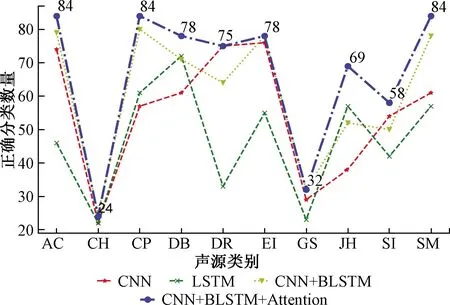
图7 四种模型细颗粒度比较Fig.7 Number of identifications among the four methods on 10 classes of environmental sound
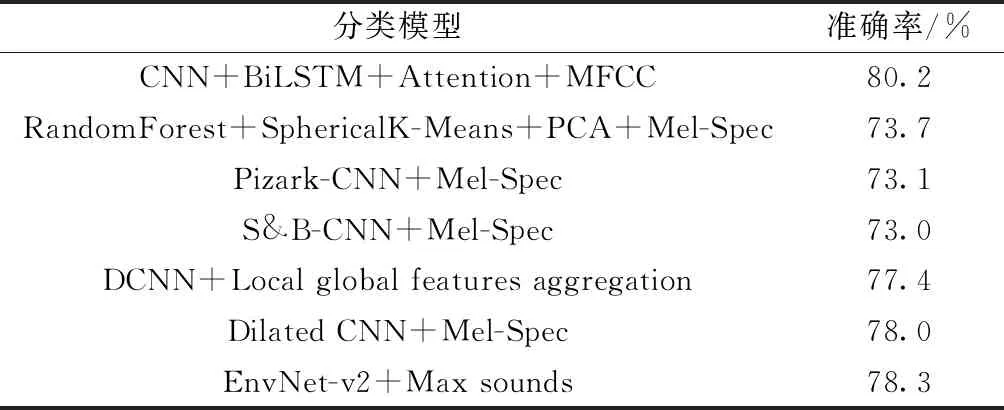
表2 Urbansound8K上7种模型的分类准确度[15-18]
4 结论
针对短音频城市环境声音分类问题,研究并提出基于注意力的时间分布式双向卷积神经网络分类模型,本文模型的分类准确性能够达到80.2%,这高于目前提出的其他卷积神经网络分类模型。从消融研究及细颗粒度分析中可以看出,本文模型在单项类别中分类稳定性较好,并具备良好的泛化能力,且在分类准确度上同样具有优势。对数据增强开展相关算法研究,将本文方法从单标签分类扩展到多标签分类,以便分类器可以识别多个并发声源,并研究其在连续录音中检测声音事件的应用。
