一种基于蚁群算法的智能水上机器人的简单仿真实现
2020-12-28李光辉郭锐田瑶瑶
李光辉,郭锐,田瑶瑶
(中南民族大学计算机科学学院,武汉430074)
0 引言
如今各种垃圾长期在水面堆积,严重影响水环境。于是如何进行水质监控和垃圾清理便是一个不得不解决的问题。
目前国内的水面垃圾处理措施大多为人工打捞,此种方式效率低成本高危险大,为解决以上问题,目前不少学者提出了各种水面垃圾清理系统[1-5]。综合起来看,前人在船体构造、框架设计等方面已有较好解决方案,在一定程度上解决了小型水域的垃圾打捞问题。但是也存在着需要人工操控、巡航方式过于耗能等尚未解决的问题。
因此,在前人的研究基础上,我们对智能水上机器人的巡航方式进行优化。通过历史数据选取遍历点,再使用蚁群算法[6-7]规划机器人航行的最优路径,在保证清洁能力的前提下减少了航行里程数,使其更加智能化。在很大程度上减少了的航行里程,使机器人更高效节能,在一定程度上解决了前人学者在此机器人研发上未解决的问题。
1 模型建立与效率计算
首先设置水上机器人的航行环境为二维平面模型,采用栅格法建模[8](图1),避障方面由硬件实现,本文算法航行的水面为理想化的无通行障碍水面。每个单元格为水上机器人可探测垃圾的范围。每个单元格的状态分为三种:①环境检测取样点;②有垃圾点;③无垃圾点。在机器人航行过程中,垃圾产生后忽略其在水面的微小漂移。

图1 湖面建模
在本文研究中,将单元格地图划分为A×A网格单元,假定每个栅格的单位长度为a(2 倍机器人扫描半径),机器人走过一个栅格它的移动步数step加1。垃圾只会产生在栅格中,且机器人经过该栅格时会捡到垃圾,捡垃圾不增加额外步数。
假设起点在(0,0)处,则一趟全图遍历的移动步数:

我们设定在每次航行前产生垃圾数为n,垃圾产生范围当然在我们规定的地图中。我们定义一个A×A的垃圾矩阵garbage_map,通过函数garbage_input(x,n)在该矩阵中产生垃圾。有一个环境因子比较重要,那就是垃圾集中区面积与总面积之比θ1。所谓垃圾集中区,就是垃圾产生概率较大的区域。另一个重要的参数就是垃圾集中区垃圾产生数与非垃圾集中区垃圾产生数比例θ2。这两个参数对本文算法的性能具有较大的影响,后续会对其进行分析。
我们定义捡到垃圾占比garbage_picked_ratio(记为γ1)和有效比例great_ratio(记为γ2)。其中,捡到垃圾占比为算法运行结束后捡到的垃圾占投放垃圾的比例,而有效比例则等于航行中捡到垃圾的步数占总步数的比例,后续将用于衡量算法效率的指标。假设采样点为m,垃圾数为n,则一趟全图遍历的有效比例为:
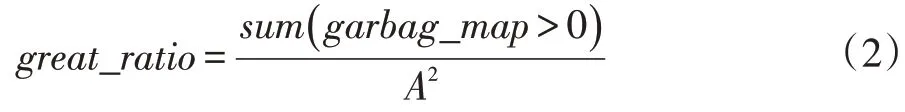
其中,sum()为Python 函数,意在统计地图中有垃圾的点数。
2 基于蚁群算法的学习遍历算法
2.1 蚁群算法
蚁群算法作为一种自组织群体智能优化算法,正反馈机理与较强的鲁棒性使其在求解组合优化问题中得到广泛地应用[9-10],相比于其他的路径规划算法[11-12],蚁群算法的启发式的概率搜索方式不容易陷入局部最优,易于寻找到全局最优解[13]。其他传统的非进化型算法如模拟退火算法[14],会出现结果属于局部最优解而非全局最优解的情况,相比之下蚁群算法就不会出现此类情况,也就避免了其他算法中可能出现的搜索能力变差的情况。
蚁群算法模拟自然界中真实蚂蚁的觅食行为,寻找一条从蚁巢(起始点)到食物源(终止点)的最短路径。在寻找食物的过程中,蚂蚁会在其行走路径上释放信息素,并根据信息素浓度大小决定下一步路径方向。由于蚂蚁倾向于选择信息素更强的路径,若某一路径上蚂蚁所释放的信息素越多,则蚂蚁选择该路径的可能性会越大。蚂蚁在觅食过程中根据当前节点与下一节点的距离及信息素浓度来决定下一节点的转移概率为:

上式中:τij(t)为路径ij上的信息素浓度,ηij(t)为与路径ij相关的启发式信息,α为信息素浓度启发因子,β为能见度启发因子,allowedk中包含蚂蚁k 尚未访问过的节点。

式(4)中:εij为节点i与下一节点j之间的欧氏距离,若两节点间的欧氏距离越短,则所对应能见度启发函数值越大,对应转移概率也越大。

式(5)为所有蚂蚁完成一次迭代后,信息素更新方式。式中:ρ为信息素挥发系数,其值越大信息素挥发得越快,M为蚂蚁总数,τij(t+1)为第t+1 次迭代时路径ij上的信息素浓度,为本次迭代中蚂蚁k留在路径ij的信息素。

式(6)中:Lk为蚂蚁k 完成路径搜索后行走的总长度;Q为一常数,表示蚂蚁携带的信息素浓度因子。
2.2 遍历点选取算法
使用蚁群算法对遍历点进行遍历是再好不过。本文算法的另一个重点是确定遍历点,使得用蚁群算法对这些点进行遍历时捡到的垃圾数较多,同时有效比例也较大。遍历点由三种点组成:①水质检测点;②垃圾集中点;③随机垃圾点。其中,水质检测点是用于水质取样检测的,是已知点。垃圾集中点是指该湖面区域内产生垃圾较为频繁的点,随机垃圾点则是小概率有垃圾的点。后两种点是未知的。
本文是这样来确定后两种遍历点的。初始化一个记忆矩阵Memory_map,其大小依然为A×A,初始化值为0。在一个陌生湖泊环境中进行工作时,机器人在前K次工作时会对湖面进行全图遍历,根据在某点是否捡到垃圾来更改Memory_map的权值。若该区域捡到垃圾,该点权值加μ,若没有捡到,权值减去η。则根据实际情况,前K次运行完毕后的矩阵值进行如下更改:
假设捡到垃圾的次数为l1,未捡到为l2。

前K次运行过后,若某点的记忆矩阵值大于预选阈值γ,则将其选入垃圾集中点。之后,通过对Memory_map[i,j]进行排序,选择其中前k 大的加入随机垃圾点。以上三种点通过蚁群算法规划路径后进行下一次遍历。
假设本文算法捡到垃圾的移动步数为get_num,其总的移动步数假设为step_2,则其有效比例为:

虽然无法确定其值,但我们可以知道他们与各种参数的关系:
(1)预选阈值γ与k共同决定了遍历点个数t_num,在一定范围内,get_num随着t_num增大而增大,而step_2 也会随着t_num增大而增大,且在一定范围内,step_2 增大速率大于t_num。
(2)垃圾集中区垃圾产生数与非垃圾集中区垃圾产生数比例θ2。其他参数设置合理的情况下,get_num随着θ2增大而增大,step_2 随着θ2增大而减小。
2.3 算法流程
基于本文提出的算法的机器人路径规划步骤如下:
步骤1 初始化蚁群算法中的所有参数,设置蚂蚁个数M,最大迭代次数N,起终点位置S等。
步骤2 初始化遍历算法参数:全图遍历次数K,正反馈权值μ,负反馈权值η,以及预选阈值γ等。
步骤3 进行K次全图遍历。更改Memory_map的值
步骤4 根据Memory_map的值以及遍历点数量k和环境监测点确定遍历点,使用蚁群算法进行路径规划,然后进行遍历,遍历过程中再次更新Memory_map的值。
步骤5 判断是否达到最大运行次数,若是则输出运行结果,否则转向步骤4。
2.4 算法效果展示
如图2 所示为某一次初始化的湖面,其中带斜杠的阴影部分代表以该点为内心的正方形区域内存在垃圾(包括新产生的垃圾和上次未清理干净的垃圾)。图3 为本文算法在图2 基础上规划的路径(此前算法在该湖面的运行次数已足够充分),圆点为算法产生的遍历点,连线部分为路径,在路线上的垃圾已被打捞。

图2 初始化的湖面
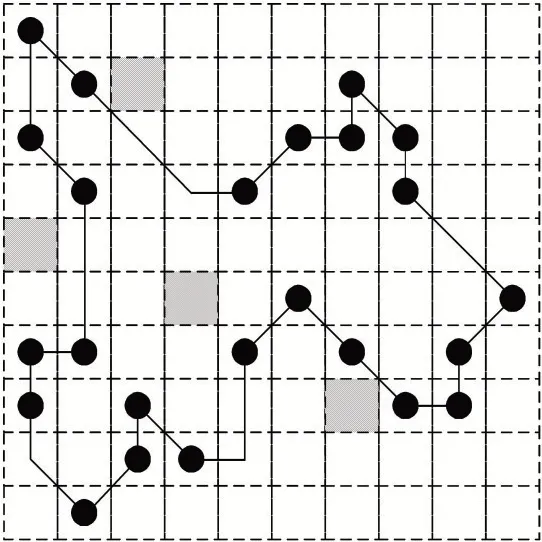
图3 某一次垃圾打捞路线
3 实验结果与分析
为了验证学习遍历算法的可行性与有效性,本文设定的垃圾分布在全局静态10×10 的单元格中。在参数与环境完全相同的情况下,利用Python 分别对全图遍历方法,本文算法进行仿真对比分析。
由于本文算法受垃圾集中区面积与总面积之比θ1,垃圾集中区垃圾产生数与非垃圾集中区垃圾产生数比例θ2影响,故先得到该算法在不同环境因子下的效率后再选择不同因子下的各个效率与全图遍历效率相对比。
其中,蚁群算法的参数为:蚂蚁规模M=50;最大迭代次数N=150;信息素启发因子α=1;期望启发因子β=5;信息素增加强度系数Q=2000;信息素蒸发系数ρ=0.1 ;本文算法中全图遍历趟数K=0.9×travel_time,阈值γ=c_num+5,正反馈权值μ=4,负反馈权值η=2。其他参数通过控制变量法来观察其对本文算法各个效率的影响。
根据算法在不同参数环境中运行的结果,我们选取了较为稳定和具有代表性的数据,捡到垃圾比例γ1、垃圾集中区占比θ1与垃圾产生比例θ2关系,有效比例γ2与垃圾集中区占比θ1和垃圾产生比例θ2关系分别如表1、表2 所示。

表1 捡到垃圾比例、垃圾集中区占比θ1 与垃圾产生比例θ2关系

表2 有效比例与垃圾集中区占比θ1 和垃圾产生比例θ2 关系
同参数下各效率变化趋势如图4、图5 所示。

图4 θ1=0.15时各效率随θ2 变化情况

图5 θ2=7/3时各效率随 θ1 变化图
从实验结果中可以看出,θ1不变,捡到垃圾比例和有效比例都随着θ2减小而减小,但总体而言θ2对有效比例影响不大。θ2不变,随着θ1增大,捡到垃圾比例减小,少走路径比例急剧减小,而有效比例则急剧增大。可以看出,在一定范围内,垃圾集中区占总面积比例θ1和垃圾产生比例θ2越大,本文算法有效比例越大。
我们选取遍历次数为200 时,垃圾产生比例θ2=9/1,垃圾集中区占比θ1=0.15,以及垃圾产生比例θ27/3,垃圾集中区占比θ1=0.0 5 两种情况与全图遍历的效率对比,结果如表3-表4 所示。

表3 θ1=0.05,θ2=7:3 情况下本文算法与全图遍历各项数据比较

表4 θ1=0.15,θ2=9:1情况下本文算法与全图遍历各项数据比较
表3-表4 中本文算法在不同环境下与全图遍历相比较,有效比例都比全图遍历要高许多,少走的路径也意味着更低的能耗,但同时也能看到,全图遍历能捡到水面上几乎所有的垃圾,而本文算法只能捡到80%-90%的垃圾,精度上还有待提高。
4 结语
本文提出的学习遍历算法具有一定的学习能力,能够根据历史数据减少遍历点的个数从而大大增加水上机器人工作的效率,相比于传统的全图遍历的方法,本文的改进从垃圾集中点入手,在遍历过程中逐渐找到垃圾集中的地区,主要遍历这些地区,适当频率遍历垃圾较少出现的区域,从而较大改善了水上机器人的遍历路径,航行时间明显得到减少,有效步数大幅度增加,具有更好的实用性。但是本文算法还需进一步改善,算法体现出对垃圾集中点外产生的垃圾清理效率不高,虽可通过增加遍历点个数来提高垃圾清理效率,但如此一来有效比例却会因此下降。改善算法之后,下一步将考虑具体实物实现。
