基于深度神经网络的病理报告自动打标签框架
2020-12-28曹晏阁王利团
曹晏阁,王利团
(四川大学计算机学院,成都 610065)
0 Introduction
Computer-Aided Diagnosis(CAD)systems in medicine aim at assisting doctors make diagnostic decisions by emulating the way of a skilled human expert. Intelligent CAD systems use artificial intelligence approaches to analyze clinical data that often can be complex and/or massive[1]. Hence, this kind of CAD systems can offer great help in making diagnostic decisions in varies diseases. As one of the most important methods in artificial intelligence, neural networks have been widely studied for many years[2]. It discovers complex structure in large datasets by using the backpropagation algorithm to indicate how a machine should change its internal parameters that are used to compute the representation in each layer.
Recently, benefit to the ability of automatically abstract hierarchical features,CAD systems with deep neural networks have achieved great success in many kinds of medical image analysis tasks, such as described in [3]. In most of these tasks, the CAD systems are constructed by using supervised learning,which needs the manual annotations. However, there are usually some challenges in manual annotation, such as laborious, time-consuming and subjective with poor reproducibility. It is also heavily dependent on the experience of annotators.In this regard,automated labelling is urgently demanded in the constructing of CAD systems.
In clinical, the imaging techniques including X-ray,MRI, and ultrasound yield a great deal of information that the radiologist or other medical professional has to analyze and evaluate comprehensively. CAD systems process digital images to highlight conspicuous sections,such as possible diseases, in order to support a decision taken by the professional.Usually,there are four kinds of CAD systems:(1)preprocessing for improving image quality;(2)segmentation for different structures in the image;(3)structure/ROI(Region of Interest)analysis;(4)evaluation/classification. In this work, we focus on the automatic labelling for the classification tasks.
The following procedures are examples of classification algorithms,logistic regression,support vector machine(SVM),principle component analysis and DNNs.A classification algorithm is usually a supervised learning algorithm,which maps an input to an output based on example input-output pairs[4].In supervised learning,each example is a pair consisting of an input object and a desired output value. A supervised learning algorithm analyzes the training data and produces a function, which can be used for mapping new examples like determining the class labels for unseen instances. As we are using such a supervised learning algorithm for classification in CAD, input-output pairs are necessary. As for medical imaging, the input is usually the image including X-ray, MRI and ultrasound.Thus, it is easy to obtain the input by using the appropriate machine,but the challenge is how to get the output value, the corresponding label. Usually, it is the radiologists or other medical professionals that analyze the image and give the corresponding label.But in the classification task,we will build and train a large network with CNN, thousands of images are usually needed, thus manually labeling is very labor-intensive and time-consuming.The need for automated labeling method is necessary. As far as we know, there is no such a method that can automatically label the image.
Because of its convenience, speed, non-invasiveness and low cost, ultrasonography is widely used in many kinds of disease,i.e.,breast cancer,thyroid cancer.Usually, the conclusion of the pathology reports is the golden standard. The pathology report shows the biopsy result,and by which doctors can give the accurate label. Hence,the important thing is extracting the benign/malignant labels of the corresponding images from the pathology report. An example of the pathology report is shown in Figure 1.

Figure 1:An example of the pathology report of thyroid nodules(benign label).The part in the red box is the diagnosis and the part in the blue box is the Pathological image.
In this work, a framework that can automatically generate the label(benign or malignant)from the pathology report is proposed. In clinical, there are usually four main steps are included to get the label of one examination from the pathology report.Firstly,finding the location of the pathology diagnosis. Secondly, reading the diagnosis conclusion line by line and recognizes the text. Thirdly, understands the meaning of the text according to the context. At last, giving the label. Analogously, there are four main step-ins the proposed framework.(1)Use text detection technology to detect the diagnosis part from the whole pathology report.(2)recognize all text lines from the diagnosis part.(3)Encode every recognized text line into sentence vector.(4)Classify the sentence vector to generate the label. Hence, the proposed framework should have the ability of detect a certain part from a whole image, and then segment the certain part as each text line. Furthermore, it also can understand the sentence and then classify it. Considering the aforementioned ability, we propose the PRALF(pathology reports automated labeling framework)to automatically generate the benign/malignant labels from the pathology report.In this framework,CTPN is used to detect text, OCR is used to recognize text, sentence embedding is used to encode text into vector and binary classification is used to classify the vector.
The main contributions of this work are summarized as follows:
· A novel highly integrated and effective automated labeling framework for
pathology reports are proposed which is the first method as far as we know.
·A manually labeled ultrasound dataset.
The rest of this paper is organized as follows: section 2 presents some backgrounds and preliminary knowledge about text detection, object detection, text recognition and sentence embeddings. Section 3 shows our 4-steps framework and explains every component in detail.Section 4 introduces our dataset and presents the results of a series of experiments, including: training the text detection model,constructing the CNN-based OCR system, training sentence vector, and performing 2-classes prediction with binary classification model.Section 5 gives the conclusion.
1 Related Works
Text detection. The traditional text detection methods have been dominated by bottom-up approaches which are generally built on stroke or character detection[5].They can be roughly grouped into two categories, sliding-window based methods and Connected-Components(CCs)based methods. The CCs based approaches discriminate text and non-text pixels by using a fast filter, and then text pixels are grouped into stroke or character candidates, by using low-level properties, e.g., color, intensity, gradient, etc.The sliding-windows based methods detect character candidates by densely moving a multi-scale windows through an image. The character or non-character window is discriminated by a pre-trained classifier,by using manuallydesigned features,or recent CNN features.
Object detection. Convolutional Neural Networks(CNN)have recently advanced object detection. The RCNN series all generate a number of object proposal by employing low-level features,and then a CNN classifier is applied to classify and refine the generated proposals.However, the object detection methods cannot be directly used in text detection task because text is significant different from general objects and has its own characters.
Text recognition. Approaches to printed text recognition can be broadly divided into segmented and unsegmented approaches. Segmentation-based methods firstly segment text line image into characters or character candidates, then recognize characters using a static character classifier designed according to the geometric characters of characters. Segmentation-based OCR systems require carefully designed character segmentation methods, since segmentation errors usually lead to errors in the output.The CNN is a segmentation-free technique and can extract hidden features of text line images thanks to its powerful ability of feature extracting. CNN-based methods do not require segmenting all characters in a text line image,the text line image is fed into CNN and the hidden features of the whole sentence can be extracted.
Sentence Embedding. Word and sentence embeddings have become an essential part of any Deep-Learning-based natural language processing systems. Word embeddings can represent words by vectors. A wealth of possible ways to embed words have been proposed over the past few years. The most commonly used models are Word2Vec[8]and GloVe[9]which are both unsupervised approaches based on the distributional hypothesis. Similarly,sentence embeddings can represent sentences by vectors.The naïve method to generate sentence vectors is simply adding all word vectors in a sentence and calculate the average, but that method treats every word equally and ignores the word order.
2 Method
Automatically labeling pathology reports includes four parts,text detection,text recognition,sentence embedding and binary classification. Based on that, we propose the automated labeling framework, as shown in Figure2.There are four steps to get the label with our framework.(1)Using Connectionist Text Proposal Network(CTPN)which is a text detection technology to detect and extract all text lines in the pathology report.(2)Using OCR based on DenseNet with CTC loss function to recognize text lines.(3)Encoding every recognized text line into Skip-Thoughts vectors.(4)Putting the sentence vector to a binary classifier to get the label.

Figure 2:The full automated labeling framework.Four steps are included,they are text detection using ctpn,ocr using DenseNet with CTC loss,encoding into skip-thoughts vectors and binary classification.
2.1 Text Detection
For a given image containing text, the task of text detection is to detect lines of text in the image. Text detection can be regarded as special object detection, but it is more challenging. The challenge of text detection is that the shape of the text is mostly a rectangle or a long strip with a large aspect ratio. Most of the traditional detection networks are for rectangular frames with a moderate ratio.Therefore, the design of the perception field and anchor must be different from the traditional detection network.
We use the CTPN[5]model to detect text lines in the pathology report. Different from the general object detection method like R-CNN series and YOLO series, CTPN does not directly treat the entire text line as an object, instead it firstly detects every single small part of the text line and then merge them all into the whole text line,which overcomes the challenge of directly detecting rectangles with large aspect ratio. The architecture of CTPN is shown in Figure3.
The specific implementation process of CTPN consists of three stages:(1)detecting small-scale text boxes,(2)circularly connecting text boxes,(3)text line edge refinement. The specific implementation steps are as follows.
1. In the first stage, for a given image I containing text, the feature expression is obtained through a feature extraction network using as ResNet50, the size of which isH×W×C.
F=f(I)
fis the nonlinear expression constructed by the ResNet50,F∈RH×W×Cis the characteristic expression corresponding to the imageI.
2. Use the sliding window g with the size of 3 × 3 to slide onF,obtainingF'∈RH×W×9C.These features will be used to predict category information and location information corresponding at the location.
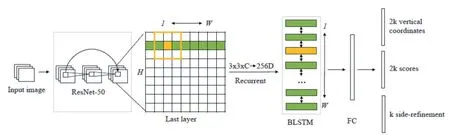
Figure 3:Architecture of the Connectionist Text Proposal Network(CTPN).H and W denotes the height and width of the last feature map of ResNet.FC is the fully-connected layer.
F'=g(F)
3. InputF'into a bidirectional LSTMs [11], with batch size isH, and maximum time lengthTmax=W, to learn sequence characteristics of each line. BLSTM outputH×W×256,and then restore the shape via Reshape.This featureF''∈R256×H×Wincludes both spatial features and sequence features learned by LSTM.
F''=s(F')
4. Then, passingF''through the FC convolution layer, the feature becomesF'''∈R512×H×W.Convis 512-dims fully-connected layer.
F'';=Conv(F'')
5. Through an RPN network similar to Faster RCNN,fine-scale text proposals are obtained.The RPN network is used to generate 2k vertical coordinates for bounding box regression and 2k scores for classifying anchors using Softmax.
6. Finally, a graph-based text line construction algorithm is used to merge the obtained text segments into text lines.
The main advantages of the CTPN model are as follows.(1)Turning the problem of text detection into localizing a sequence of fine-scale text proposals.(2)Using BLSTM to explore meaningful context information of text line. Because of the two characteristics, the CTPN can detect text lines more accurately than other methods, and therefore we use it as out text detection model.
2.2 Text Recognition
After detecting text lines in the pathology report image, we need to recognize every single text line. Encoderdecoder is the common framework in text recognition. In our framework, we use DenseNet[12]to encode input text line image and get the feature maps. Then we use connectionist temporal classification(CTC)[13]loss function to train the decoder which converts the feature maps into a character sequence. Our encoder-decoder text recognition model is shown in Figure4.
For an input text line image, we expand the last feature map of the DenseNet model along width, supposing that the width of the feature map isWand the height isH, so there are totallyWframes ofH-dimensions vectors.Each vector is passed through a softmax layer with nneurons, since there are totally n different characters. After decoding with CTC, we get the sequence of tokens.Then CTC will automatically merge repeats and drop blanks,and finally output the recognized text.
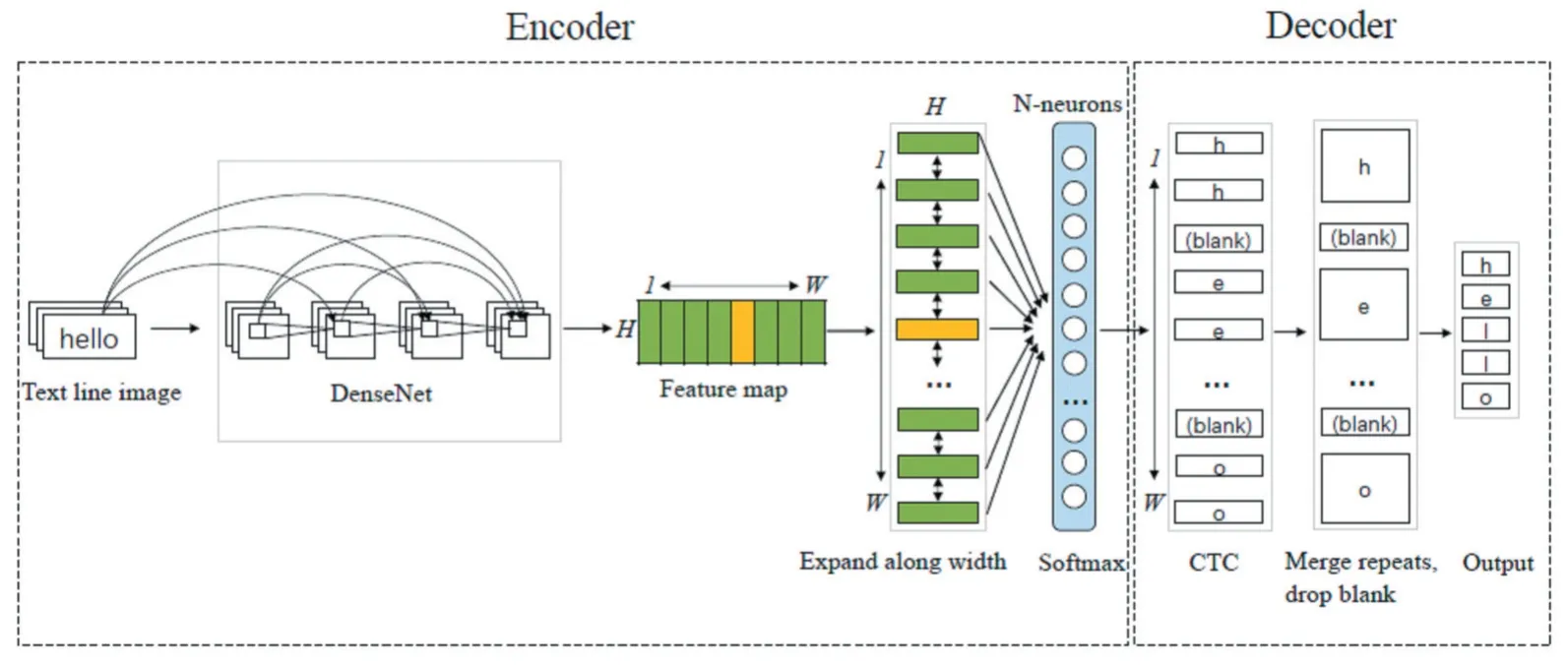
Figure 4:Architecture of the text recognition encoder-decoder model.DenseNet is used to encode input text line and CTC is used to decode the feature maps to text.
Encoder. DenseNet is a powerful convolutional network. In DenseNet, each layer obtains additional inputs from all preceding layers and passes on its own feature maps to all subsequent layers. Since each layer receives feature maps from all preceding layers, network can be thinner and compact.Thus,it has higher computational efficiency and memory efficiency. Because of those advantages,we use DenseNet as the encoder.The dense connectivity is shown below:
xl=Hl([x0,x1,…,xl-1])
wherexlis the output oflthlayer andHl(∙) denotes composite function of operations, [x0,x1,…,xl-1]refers to the concatenation of the feature- maps produced in layers 0,...,l-1.
Decoder. CTC is a way to solve the problem of not knowing the alignment between the input and the output,which is especially well suited to text recognition. It can be used in our framework since the text lines could be regarded as temporal sequences. In our framework, CTC is used to convert the feature maps of the text line image into a label sequence, after some processing we can get the character sequence. In traditional OCR models, before training the model, we often have to strictly align the input image with the text, thus there are two disadvantages.(1)Strict alignment takes labor and time.(2)After strict alignment, the label predicted by the model is only the result of local classification without considering the context.
CTC overcomes the two disadvantages.For a given input text line sequenceX=[x1,x2,...,xT], it gives us an output distribution over all possible output character sequencesY=[y1,y2,...,yU]where:(1)BothXandYcan vary in length.(2)The ratio of the lengths ofXandYcan vary. We can use this distribution to infer a likely output with the following formula. After merging repeats and dropping blanks in the output sequence, we can finally get the character sequence.
Y*= arg maxY p(Y|X)
2.3 Sentence Embedding
The framework cannot give the label only with the recognized text, it has to understand the context and encode the text into a vector,which can represent the semantics of the text.The most basic sentence embedding is getting word embeddings of all the words in the text and averaging them, but in this case every word is treated equally,which cannot reflect the actual situation. We can directly encode the whole text into a sentence embedding by analyzing context using Skip-Thoughts model,which is an encoder-decoder model for generating sentence vectors.
We train the Skip-Thoughts model by analyzing the context of the text. When using this model, we only need to input the text to be encoded into the model, and then a sentence vector will be generated.
2.3.1 Training Phase
In the training phase, we train an encoder to encode text to vectors. the Skip- Thoughts model is an encoderdecoder model as shown in Figure6. One encoder and two decoders are included. The encoder maps a sentence to a sentence embedding and the two decoders predict the previous and the next sentences using that sentence embedding. Here RNN with GRU is used as the encoder and decoder.

Figure 5
Figure 5: Training phase of the Skip-Thoughts model. Given a sentence tuple (si-1,si,si+1) of contiguous sentences,siis thei-th sentence.The sentencesiis encod-ed and the model tries to predict the previous sentencesi-1and next sentencesi+1. In this example, the input is the sentence triplet I got back home.I could see the cat on the steps. This was strange. Unattached arrows are connected to the encoder output,the hidden state.Colors indicate which components share parameters.<eos> is the end of sentence token.
For every sentence tuple (si-1,si,si+1) in the text for training. Letdenote thet-th word for sentencesiand letdenote its word embedding.

Decoder. The decoder is a neural language model which depends on the encoder output hi. One decoder is used for the next sentencesi+1,and another is used for the previous sentencesi-1. Different parameters are used for each decoder with the same vocabulary matrix V.
The objective optimized is the sum of the log-probabilities for the previous and next sentences conditioned on the encoder representation. The total objective is to maximize the sum over all such training tuples.
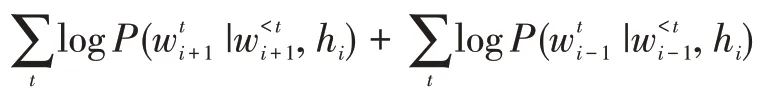
2.3.2 Use Phase
Using the above training strategy,we can train an encoder. In our framework, then we can use the encoder to encode recognized text(a paragraph of text)into the sentence embedding. So far, the text can be converted into a high-dimensional vector.

Figure 7:To use Skip-Thoughts encoder to encode text into high dimensional vectors.
2.4 Binary Classification
After detecting the text line, recognizing the text and encoding the text into sentence embedding,we need to perform binary classification to get the label. There are various methods that are used for training binary classifiers including: DNNs, Bayesian classification, SVM, logistic regression,etc.
Before performing the binary classification,the generated vocabulary is usually insufficient.For example,a sentence from the test set might contain nouns that do not appear in this vocabulary. A solution is to learn a mapping that transfers word representations from one model to another[10]. Specifically, we loaded the word embeddings from a trained Skip-Thoughts model and from a pre-trained Word2Vec model(which has a much larger vocabulary).Then we trained a linear regression model to learn a linear mapping from the Word2Vec embedding space to the Skip-Thoughts word embedding space. We then applied the linear model to all words in the Word2Vec vocabulary,yielding vectors in the Skip-Thoughts word embedding space.
3 Experimental Results
This section will show the results of 4 experiments,which are text detection,text recognition,sentence embedding and binary classification. And 3 datasets were used for training our automated labeling framework. ICPR 2018 MTWI dataset was for text detection,synthetic text was for text recognition, text descriptions of ultrasound images were for training Skip-Thoughts vectors.
3.1 Datasets
ICPR MTWI 2018: There are totally 20000 images.The data set is all derived from network images, mainly composed of composite images, product descriptions, and online advertising.These images are the most common image types on the web. Each image contains either complex typography, dense small text or multilingual text, or a watermark.
Synthetic text: A total of about 3.64 million pictures,divided into training set and validation set by 99:1.The data is generated randomly using Chinese corpus through changes in font, size, grayscale, blur, perspective, stretching, etc. Each sample is fixed at 10 characters, and the characters are randomly intercepted from the sentence in the corpus. Picture resolution is uniformly 280x32. There are 5990 different characters including Chinese characters, English letters, numbers and punctuation totally. The sample is shown as Figure8.

Figure 8:The synthetic text which is generated through digital image processing and fixed at 10 characters.
Text descriptions of ultrasound images:This is the dataset we manually labeled. We use the text descriptions of thyroid ultrasound images to train Skip-Thoughts vectors.For each text description, there are several sentences, every sentence is related to its previous and next sentence.The <previous,current,next> triples are used as the training data. There are totally 18861 text descriptions. A typical description is shown in Figure9.

Figure 9:An example of text descriptions of ultrasound images.
3.2 Text Detection
3.2.1 Training details
In the training phase, we adopted 9 groups as the training set, and 1 group as the testing set, each group included 1000 images. The parameters of training CTPN is as follows. As for generating anchors, the height of anchor is in [11, 16, 23, 33, 48, 68, 97, 139, 198, 283], the width is 16. There are 256 training anchors per image, and the stride of anchor is 16, the ratio of positive anchors is 0.5.As for generating text proposals, the min score is 0.7, the nms thresh is 0.35, the max number of text proposals is 2000, the width is 16. As for generating text line boxes,the min score is 0.7,the max horizontal gap is 50,the nms thresh is 0.3,the min number of proposals is 1,the min ratio is 1.2,and the min vertical overlaps is 0.7.As for training parameters, the shape of input image is(720,720,3),learning rate is 0.01,learning momentum is 0.9,weight decay is 0.0005, gradient clipping norm is 5, batch size is 5 and epoch is 100.
3.2.2 Experimental results
There are three loss functions in the CTPN: CTPN class loss, CTPN regress loss, and side regress loss which compute errors of text/non-text score,coordinate and siderefinement, respectively. The losses are shown in Figure10,Figure11 and Figure12.

Figure 10:ctpn_class_loss

Figure 11:ctpn_regress_loss
Figure 12:side_regress_loss
3.3 Text Recognition
To train the DenseNet with CTC loss, we establish two network models. The first one is the base DenseNet model by which we can extract the feature of the input text image. The output of the base model is a vector ofndimensions, denoted asy_pred(n is the total classes of characters, here the value is 5990). In the second model,the inputs arey_pred,the true labels of the input text,the input length(the width of the input text image divided by 8)and the label length(number of characters in text image). The learning rate is 0.0005, learning rate decay is 0.4 per epoch, batch size is 128 and epoch is 10. After 10 epochs,the validation accuracy reached 98.3%.
3.4 Sentence Embedding
3.4.1 Training details
Before training the Skip-Thoughts vectors, we need to preprocess the dataset.First of all,we counted all words shown in the dataset and got the vocabulary. In the training stage, the sentence was transformed into a sequence of integers, and then passed through a word embedding matrix to be a sequence of vectors. Finally, the sequence will be sent into the Skip-Thoughts model to train the encoder and decoders.
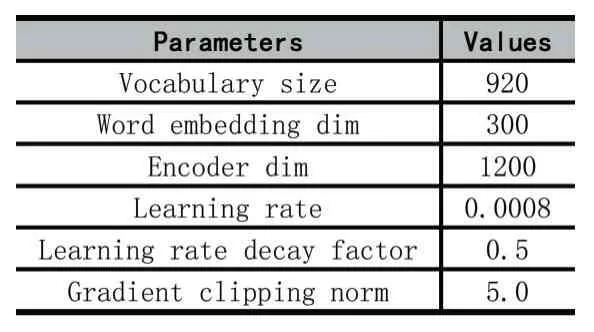
Table 1:Parameters for training the Skip-Thoughts model.
3.4.2 Experimental results
After about 110 thousand steps, the loss of pre-decoder and post-decode began to converge. And the losses are shown in Figure13 and Figure14.

Figure 13:decoder-pre-loss

Figure 14:decoder-post-loss
3.5 Binary Classification
3.5.1 Training details
Here we perform three sets of comparative experiments, logistic regression, DNN and SVM. The experiments are performed on 32 positive samples(benign)and 29 negative samples. As for SVM and logistic regression,we performed a double loop 10-fold cross-validation.Outer loop was for held-out evaluation and inner loop was for hyperparameter tuning, specifically, looking for the best regularization parameter.Alternative regularization parameters are[1,2,4,8,16,32,64,128,256].As for DNN,we use a 2-layer neural network with 5 and 2 neurons.
3.5.2 Experimental results
The 10-fold cross validation results of three comparative experiments are shown in Table2, Table3, Table4.The best average accuracy of total examples is 75.48%,from DNN.
4 Conclusion
In this paper, we present an automated labeling framework for pathology reports based on deep learning.Text detection, text recognition, sentence embeddings and binary classification are included in our framework and all of them are based on deep learning.Our framework is highly integrated and efficient.Since there is not such a framework,we filled the gap in this area.
We believed that our framework is crude preliminary and can be improved in the following aspects.(a)More advanced CNN model for abstracting features.(b)More fast and efficient model for text detection.(c)Sentence embeddings that extract contextual information more effectively.

Table 2:10-fold cross validation results of logistic regression.
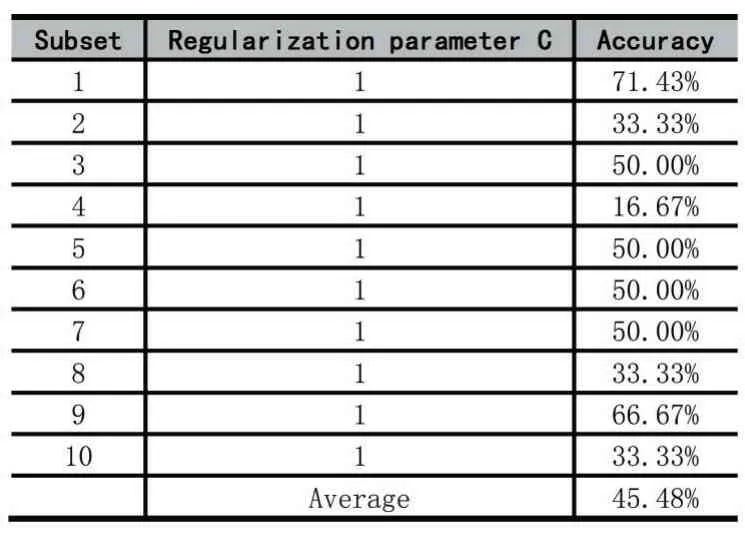
Table 3:10-fold cross validation results of SVM.
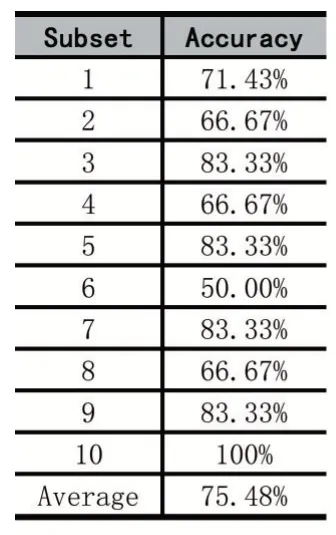
Table 4:10-fold cross validation results of DNN.
