具有中心移动特性的弹性网络聚类算法研究
2020-12-26衣俊艳杜小鹏
衣俊艳,杜小鹏
北京建筑大学 电气与信息工程学院,北京100044
1 引言
随着信息技术的飞速发展,聚类分析已成为数据分析最重要的研究方向之一。聚类算法的思想是使划分为不同类中的对象之间的相似性最小,而同一类中的对象之间的相似度最大[1]。相似度的计算方式有Jaccard相关系数、皮尔森相关系数、欧几里得距离、余弦相似度等[2]。针对数据集的分布、形状、数据量以及相似度计算方法等的不同,许多聚类算法已被学者提出。常用的聚类算法可以分为基于划分的聚类、基于层次的聚类、基于密度的聚类、基于网格的聚类和基于模型的聚类等[3]。
这些算法仍存在缺点,如,k-means和medoids等基于划分的聚类方法存在聚类结果不稳定[4-6]。与其他聚类方法相比,基于密度的聚类方法可以在嘈杂的数据中找到各种形状和大小的聚类。但是他们需要密度参数作为停止条件,计算量大,复杂度高。神经网络算法具有自学习能力和找到最佳解决方案的能力。但是,其找到复杂问题的最佳解决方案通常需要大量的计算。如Teuvo提出的自组织映射算法(SOM)[7],在模式识别、数据处理、数据挖掘等理论和应用领域中也做了很多贡献。但是,其网络初始状态中权重和参数的选择对网络的收敛性影响很大。
Durbin-Willshaw[8]的弹性网络算法(ENA),最初是一种启发式方法,用于解决TSP(Traveling Salesman Problem)问题。与其他神经网络算法相同,它同样具有无监督学习,无需人工指导的优点,但是其网络结构简单,计算复杂度较其他神经网络大大降低。后来,它被用于数据统计[9-10],模式研究[11-13]和图像识别[14]中的各种问题。
由于ENA 算法最初是用于解决TSP 问题,其原网络结构无法应用于聚类分析。本文依据聚类问题的目标调整并优化了弹性网络的能量函数,仅考虑数据点对弹性节点即聚类中心的影响力。进而提出了基于中心移动的弹性网络算法CMENA(Elastic Network Algorithm based on Center Movement for clustering),CMENA算法加强了数据点对聚类中心的影响力,可以使网络中的弹性节点更快地聚集到最佳聚类中心附近。另外,由于网络结构简化,降低了参数选择难度,减少了算法运行的时间。与k-means和k-medoids等使用随机生成的初始聚类中心神经元不同,由于该算法使用原始弹性网络提出的方法生成初始聚类中心神经元,该算法聚类结果唯一。
2 具有中心移动特性的弹性网络算法
弹性网络算法最初提出时是应用于求解TSP问题。其基本原理是根据城市点的坐标,计算出所有城市点的质心,再以质心为圆心,生成具有多个弹性节点(elastic points)的封闭小圆环,该圆环称为弹性带(rubber band)。随着弹性网络能量函数的最小化,弹性节点不断向城市点移动,直到所有的城市点被弹性节点覆盖,网络达到稳定状态,获得该TSP问题的近似解。假定弹性节点为Y(y1,y2,…,ym),其中m是弹性节点的数量。在算法迭代过程中,原弹性网络通过两种力来牵引弹性节点的移动:一种是与弹性节点yj相邻的城市点对弹性节点yj的吸引力,使得弹性节点yj逐渐向城市点靠近;另一种是与弹性节点yj相邻的弹性节点yj-1和yj+1对弹性节点yj的张力,迫使弹性节点之间的距离最短。本文依据聚类问题的目标调整并优化了弹性网络的能量函数,提出了CMENA算法,并对算法的原理进行了推理验证。
2.1 算法理论
在聚类问题中,SED 值是常用的评价指标之一。SED值可用式(1)表示:

其中,nj是属于第j类数据的个数,k是聚类数。在此基础上,面向聚类的目标,同一类中的对象之间的相似度最大,本文调整并优化了弹性网络的能量函数。本文提出的CMENA 算法是一种神经网络聚类算法。给定具有n个数据点的数据集,首先计算出所有数据点的重心,再以重心为圆心,在圆上均匀生成k个聚类中心神经元,聚类中心神经元的个数就是聚类的类数目。圆的半径可由公式(2)确定:

其中,G是数据X的二维重心。在解决高维问题时,选取前两维数据计算圆(即ENA 算法中的弹性带)的半径。重心由式(3)计算:

其中i=1,2。
对于给定的聚类中心Y(y1,y2,…,yk),对应的聚类结果为C(c1,c2,…,ck),xi(i=1,2,…,n) 属于cj(j=1,2,…,k)这一事件的概率为ωij,聚类问题可描述为求解Y(y1,y2,…,yk)及ωij使得:

即聚类中心yj与数据点xi之间欧式距离的平方,对应于SED值的距离衡量标准。
对于ωij,由于没有先验知识,不能确定其具体形式,故用统计物理学的极大熵原理[9]来确定。对于固定的Y(y1,y2,…,yk),定义聚类的能量函数和熵函数分别为:


图1 CMENA聚类过程

其中,T是常数参数,T∝t,其中t是模拟退火算法中的温度系数。
对于数据点xi的分布函数为:

进一步得到聚类问题对应物理系统自由能函数的一般形式[15-16]:
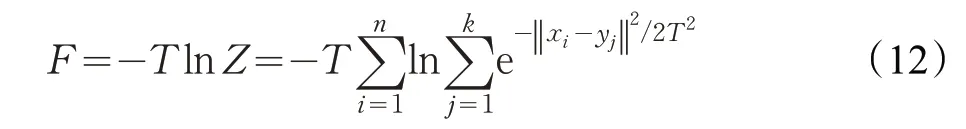
根据模拟退火算法理论,在退火过程中,系统在每一温度下达到平衡态的过程都应遵循自由能减少定律,系统状态的自发变化总是朝着自由能减少的方向进行,当自由能达到最小值时,系统达到平衡态。对应于原弹性网络理论,该公式也可描述为所有数据点对每个聚类中心神经元的牵引力之和,同样当牵引力达到最小值时,系统达到平衡态时。为满足实际计算要求,引入常数参数α。本文采用的自由能函数为:

其中,n是数据点的总个数。
根据弹性网络算法理论,通过对自由能函数求导,可得到动量公式:

其中,ωij可由式(8)得到。Δyj是聚类中心神经元yj需要移动的增量,α用来控制聚类中心神经元yj移动幅度的范围。聚类中心神经元根据下式更新:

采用一个小聚类问题的实际聚类过程图进一步说明CMENA的聚类过程。
如图1 所示,当参数α和T设置合理,随着弹性网络的能量函数的最小化,弹性节点即聚类中心神经元在每次迭代时不断向最佳聚类中心C移动,直到能量函数最小化,Δyj接近于0,聚类中心神经元不再移动,最终所得的聚类中心神经元Yend将无限接近于最佳聚类中心C。最后根据Yend计算最终的ωij,将数据点xi分配给其所属的ωij最大的聚类中心,得到聚类结果。
在原弹性网络中考虑神经元相互之间的作用力,其聚类中心根据公式(16)改变:

在图2和图3中对本文算法和上述弹性网络结构(ENC)进行了对比,数据采用UCI学习库中的wine数据集。
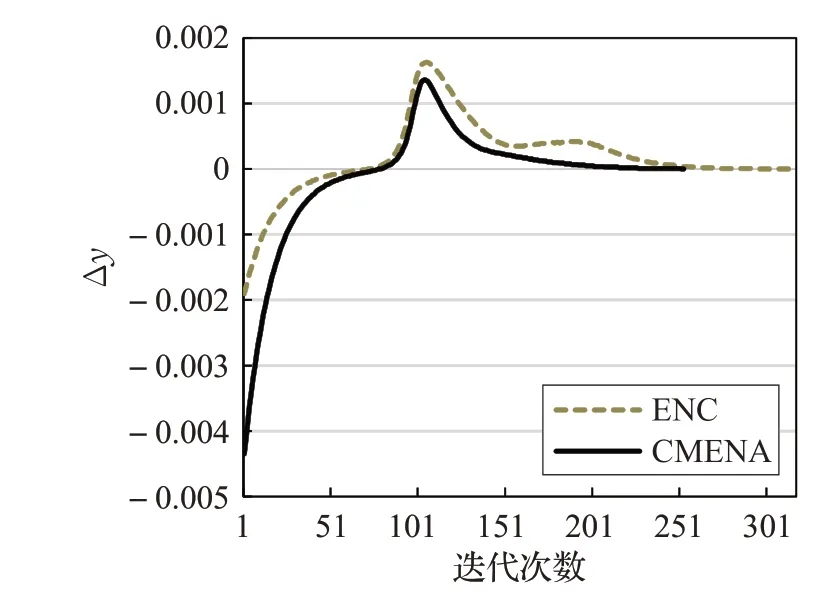
图2 聚类中心的Δyj 第一维的变化

图3 聚类中心的Δyj 第二维的变化
为验证算法的有效性,对聚类过程中第一个聚类中心神经元前两维数据的Δyj变化轨迹进行了跟踪。两种算法设置同样的参数T=2 和α=0.1,ENC 的β=0.001 时。对两种算法采用同样的停止标准,即对于任意yj的Δyj的绝对值均小于0.000 1 时,算法终止。从图2 和图3 可以看出,CMENA 算法优先收敛。其中ENC 算法花费了318 次迭代,CMENA 算法仅仅花费了255次迭代。在每次迭代的花费上,由于本文算法网络结构更加简单,算法运行时间也少于ENC 算法。在聚类质量上,ENC算法聚类结果的SED值为24 856,CMENA聚类结果的SED为24 410,CMENA较ENC优化了18%。因此CMENA 算法总的运行时间较ENC 算法有较大的减少,求解质量显著提高。
2.2 算法分析
对于初始聚类中心神经元的生成方式,考虑三种方法:RAND 方式、ENC 方式和CMENA 方式。下面分别介绍三种不同的方法。RAND方式:在数据点中随机选取k个数据点作为初始聚类中心神经元,k为聚类簇数;ENC方式:首先计算出所有数据点的重心,以0.1倍的区域半径为半径,在圆上均匀生成k个数据点作为初始聚类中心神经元,区域半径根据式(17)计算:

CMENA 方式:首先计算出所有数据点的重心,再以重心为圆心,以所有数据点到重心的距离之和的平均值为半径,在圆上均匀生成k个聚类中心神经元,聚类中心神经元的个数就是聚类簇数。
为了验证以上三种方法的有效性,针对同一个三簇共60 个数量的聚类问题,分别采用以上三种初始神经元设置方法进行了求解,聚类结果对比图如图4 所示。从图4可以看出,采用RAND方式的算法求解的SED值大于ENC 和CMENA 方式。采用ENC 算法和CMENA方式均能使算法收敛于更优解。采用RAND、ENC 和CMENA 方式所得聚类结果的SED 值分别为92.91、25.44、25.35,相比于RAND 和ENC 方式,CMENA 分别优化了72.7%、0.4%。另外,采用ENC 和CMENA 方式算法收敛速度较采用RAND方式更快。相比于ENC方式,CMENA方式能更快的收敛。

图4 不同初始聚类中心的聚类结果
由此可见,RAND 方式随机性大,无法保证初始聚类中心的分布状态,所得聚类结果不稳定。ENC方式虽然能在数据的区域范围能均匀的得到初始聚类中心神经元,但没有充分考虑数据的分布情况,容易受到孤立点的影响。CMENA方式以数据的重心作为圆心,充分考虑了数据的分布状况,且其半径的确定也考虑到每个数据点,使得CMENA 方式算法收敛最快,所得的聚类结果更好。因此本文中采用CMENA 方式作为初始聚类中心神经元的生成方法。
经过实验发现,本文算法中参数α的取值范围为(0.1,1),参数T的取值与数据量有所关联,对于数据量为0~1 000的聚类问题,T=3;对于数据量为1 000~5 000的聚类问题,T=6;对于数据量为5 000~10 000的聚类问题,T=9;对于数据量为10 000 的聚类问题,T取(10,100)的随机整数。为了验证参数选择策略的有效性和算法运算的实时性,本文采用一系列随机生成的二维数据集进行了验证,将它们聚为三类,通过上述的参数选择方法选择了CMENA 的参数,实验结果如图5 所示。从图5中可知,算法所需迭代次数与数据量的大小无关,证明了上述参数选择方案的正确性和有效性,以及算法运算的实时性,体现了CMENA算法在解决大数据量问题时的优势。

图5 参数实时性分析
CMENA 算法主要有两个参数T和α,在图6 至图9 使用分为三簇的二维随机数据集对参数T和α在CMENA算法中的作用进行分析。其中“⋅”代表聚类成功,“×”代表聚类失败。此处采用一个分为三簇,共60个数据点的数据集。在图6 和图7 中,分别将α设置为0.5、1、5,将T设置为1~10的整数。从图6和图7可知,在α相同时,T值越大,算法收敛性越差,容易导致聚类失败,算法所需迭代次数越多;反之T值越小,越有利于算法快速收敛,算法运行时间越短。但根据原弹性网络算法理论,如果在算法初始阶段,T值过小,会导致算法的能量函数收敛于某一极小值,无法得到正确的聚类结果。因此本文在算法初始阶段给参数T设置一个较大的初始值,在算法演进时T不断衰减,直到T=0.01。以提高网络在算法初始阶段的活性,使得相似度大的数据点对同一聚类中心的牵引力显著增强,后期通过减小参数T,使已经在相似度较大的数据点附近聚类中心神经元向更加接近最佳聚类中心的位置移动,最终实现聚类中心神经元与最佳聚类中心尽可能地重合,得到好的聚类结果。
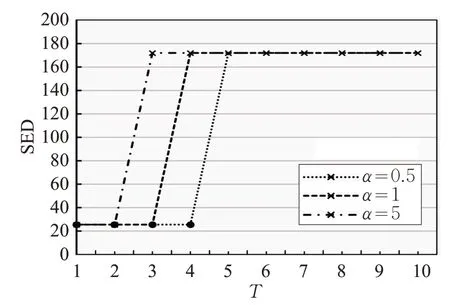
图6 参数T 对聚类质量的影响

图7 参数T 对运行速度的影响

图8 参数α 对聚类质量的影响
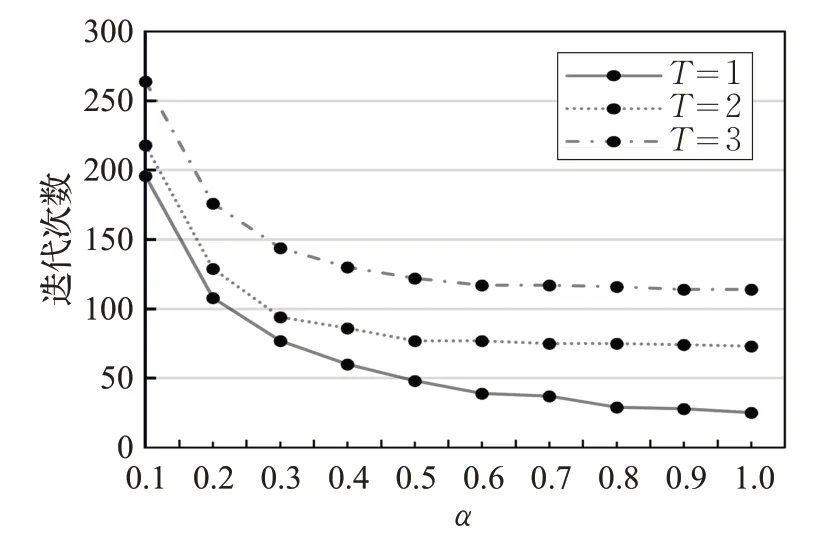
图9 参数α 对运行速度的影响
α是用来控制每次迭代弹性节点即聚类中心神经元移动幅度的大小,在图8和图9中设置参数T为1、2、3,α设置为0.1~1。从图8中可以得知,在合适范围内的α对聚类的质量影响较小。从图9中可以得知,在T相同的情况下α越大,算法运行所需迭代次数越少。
在图10 中采用8 簇共160 个数据的聚类问题通过对CMENA、k-means、k-medoids 三种算法在聚类过程中SED值的变化分析发现。从图10可以看出k-means,k-medoids 收敛速度极快,但CMENA 算法的聚类结果的SED优于其他两种算法,且CMENA算法聚类时SED值的变化过程也更加平滑。实际上k-means、k-medoids和CMENA分别用4、7、261次迭代。k-means、k-medoids和CMENA 算法的聚类结果的SED 分别为94.6、95.3、43.7,CMENA 算 法 较k-means 和k-medoids 优 化 了53.8%、54.1%。另外SOM 的SED 值为45.5,CMENA 相比于SOM优化了4.0%。

图10 不同算法聚类过程中SED的变化

图11 不同T 值下,自由能函数的变化

图12 不同α 值下,自由能函数的变化
在图11和图12中采用一个分为3簇共60个数据的数据集,对采用不同参数时,CMENA 算法的能量函数的变化过程进行了分析。可以发现,能量函数的总体趋势为逐渐收敛于0。在T和α取值恰当时,CMENA 算法通常在能量函数接近0 时停止,进而得到聚类结果,网络收敛。在图11 中,α的取值为0.1,T的取值为2、4、6、8、10。可以看出,T越小,算法收敛速度越快,所需聚类时间越短。在图12 中,T的取值为3,α的取值为0.2、0.4、0.6、0.8、1.0。实验发现α越大,算法收敛速度越快,算法收敛值越偏离于极小值。
为了进一步验证本文算法的有效性,采用一组具有8簇共160个数据的二维随机数据,对其分别用k-means、k-medoids、ENC、CMENA 算法进行了聚类。ENC 和CMENA 算法采用同样的参数T=2 和α=0.1,ENC 的β=0.01。可以从图13和图14可以清晰地看出k-means、k-medoids在聚类时,出现将不同簇的数据聚为一类,相同簇数据聚成两类的错误。而在图15 和图16 中ENC和CMENA 算法能准确地将8 簇数据聚为8 类。四种聚类算法的SED 值分别为96.83、90.05、46.39、43.77。CMENA 聚类结果的SED 值比k-means、k-medoids、ENC分别优化了55%、46%、6%。
总之,与k-means 和k-medoids 算法相比,CMENA聚类质量显著提高。相较于ENC算法,CMENA首先减少了参数的选择难度,其次降低了算法运行花费的时间,在聚类质量上也有较大提高。

图13 k-means聚类结果

图14 k-medoids聚类结果

图15 ENC聚类结果

图16 CMENA聚类结果
2.3 算法描述
本文在弹性网络的基础上,针对聚类问题的特点,依据聚类评价指标SED值,调整并优化了弹性网络算法的能量函数,并对动量公式等进行了重新的推导。当CMENA算法的能量函数最小化,动量公式(14)所得任意yj的Δyj接近于0 时,算法收敛。CMENA 算法的具体步骤如下:
(1)给定一个数据集X(x1,x2,…,xn),为方便计算可以将数据统一转化到(0,10)的区域内。给定聚类数k。根据数据维度高低和数据量大小设置CMENA算法的参数T和α。
(2)选择数据的前两维数据,根据公式:

计算要生成聚类中心神经元的圆(弹性带)的半径。根据弹性带的半径生成具有k个弹性节点即聚类中心神经元的弹性带,弹性节点均匀分布在弹性带上,此时生成的弹性节点就是初始聚类中心神经元Y0(y1,y2,…,yk)。
(3)根据CMENA算法的动量公式:
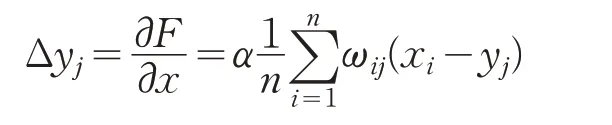
计算每个弹性节点需要移动的距离,根据公式:

更新聚类中心神经元的坐标。
(4)计算由动量公式得到的Δyj的最大值,如果Δyj的最大值大于阈值(本文采用0.000 1)时,重复步骤(3),直到多次迭代Δyj的最大值均小于阈值,执行下一步。
(5)根据Yend计算最终的ωij,将数据点xi分配给其所属的ωij最大的聚类中心,得到聚类结果。
3 实验仿真
本文采用了大量的随机数据集和真实数据集进行实验仿真。由于随机数据集无标准的聚类结果,随机数据集的实验结果通过聚类评价指标SED值来评估,真实数据集的实验结果通过Accuracy 来评估。Accuracy 的计算方法如式(18)所示:

其中,ai为属于第i类的数据点是被正确分类的数据点个数,N为数据集中所有数据点的个数。
3.1 随机数据集
由于k-means、k-medoids 算法对初始聚类中心敏感,其聚类结果的SED 值取20 次聚类结果的平均值。对于在预定时间内无法得到聚类结果情况,使用N/A标记。在表1和表2中,列出了k-means、k-medoids和CMENA算法在100到900个数据时聚类结果的SED值。CMENA算法聚类结果的SED比k-means平均小18%,比k-medoids平均小20%。在表3 中,列出了k-means、k-medoids 和CMENA算法在1000~10 000个数据时聚类结果的SED值。CMENA 算法聚类结果的SED 值比k-means 平均小21%。除10 000 个数据点外,与k-medoids 相比,CMENA聚类结果的SED值平均优化了18%。在表4中列出了k-means和CMENA算法在20 000~100 000个数据时聚类结果的SED 值。由于k-medoids 算法无法在预计时间内得到聚类结果,所以未曾列出。CMENA算法聚类结果的SED 值平均比k-means 小15%。从表3可以看出CMENA算法可以解决比k-medoids更大数量级的聚类问题。

表1 2维和3维的100~900个数据的聚类结果

表2 5维和10维的100~900个数据的聚类结果
3.2 真实数据集
选择了UCI 机器学习库中数据集进行真实数据聚类的准确率,包括Zoo、Iris、Wine、Handwritten Digits 和Skin 数据集。k-means 和k-medoids 对初始点的选择敏感,故对数据量较小的三个数据集取20 次运行结果的平均值,对其余取10 次运行结果的平均值。由于k-medoids 聚类算法对“HandwrittenDigits”和“Skin”数据集的聚类未能在预期的时间内完成,因此未在表5中列出。从表5可以看出,CMENA算法准确率比k-means平均提高12%。对数据集Zoo、Iris 和Wine 的CMENA的聚类准确率比k-medoids 的平均高14%。与SOM 相比,SOM也不能在预期时间内解决Digits和Skin数据集的聚类问题,对于其他三个数据集的聚类中,CMENA在准确率上也平均有19%的优化。原始的弹性网络通常只能解决数百个数据的TSP 问题。而CMENA 算法所解决的Skin 数据集的聚类问题有24 万个数据之多。在k-medoids 和SOM 聚类算法都无法解决的情况下,CMENA 算法却能在短时间内解决并且得到的聚类结果的准确率比k-means高15%。

表3 2维和3维的1 000~10 000个数据的聚类结果

表4 2维和3维的20 000~100 000个数据的聚类结果
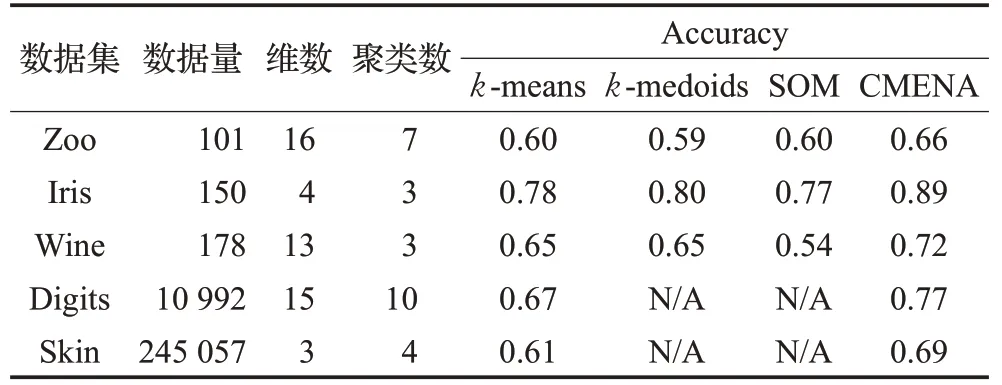
表5 真实数据集聚类结果
4 结束语
本文针对传统聚类算法k-means和k-medoids对初始聚类中心的敏感,导致聚类结果不稳定。虽然弹性网络聚类算法ENC 稳定,但需花费过多时间的。针对这些聚类算法的不足,面向聚类问题的特点,提出了具有中心移动特性的弹性网络聚类算法。实验证明CMENA具有以下优势:
(1)因为弹性网络的弹性带生成初始聚类中心神经元,聚类结果稳定。
(2)聚类过程中聚类中心神经元的位置可跟踪,实现聚类过程的实时观测。
(3)运算速度较原弹性网络结构明显加快。
(4)聚类准确率较k-means,k-medoids 以及SOM等聚类算法均有显著的提高。在聚类数目k较大时,CMENA仍能准确地根据聚类数k聚类。
(5)解决大数据量聚类问题的能力有了极大的提高,最大解决了24万数据的聚类问题。
本文根据聚类的目标SED 值调整并优化了弹性网络算法的能量函数,提出了面向聚类分析问题的CMENA算法,通过对大量随机数据和真实数据的实验,验证了CMENA算法的有效性。相较于其他常用的聚类算法,CMENA 性能显著提高,该算法具有更高的稳定性,高效性,准确性。
