面向法律文书的中文文本校对方法研究
2020-12-26刘明洁艾中良贾高峰
刘明洁,梁 毅,艾中良,贾高峰
1.北京工业大学 计算机学院,北京100124
2.中国司法大数据研究院有限公司,北京100043
1 引言
法律文书,又称裁判文书,它记载着人民法院审理案件的过程和结果[1]。文本自动校对,是自然语言处理领域中的一个重要应用,中文文本的自动校对是应用自然语言处理技术检查文本中的语言书写错误[2-3]。
伴随市场经济的发展以及司法体制的完善,法律文书在司法机关办案过程中的重要性越来越凸显。由于审判任务繁重等原因,文书的书写会出现纰漏,例如当事人姓名引用错误、叙述事实文字使用错误、法律条款运用错误等等,这在一定程度上损害了文书的权威性和公信力。因此,研究面向法律文书的中文文本校对技术对提高文书的质量有着深远的意义。
法律文书中包含有当事人信息,案件信息和裁判结论等内容。每个部分都有语义的前后关联,对于一篇包含有大量法律专业术语和语义的文书,采用通用的文本校对方法很难发现其中的错误,例如,在“……为此请求法院判令被告填平路面,恢复原状”一句中,“判令”有“判决”和“施令”的意义,虽然词语本意无错,但在法律文书中不符合语言表达习惯,应纠正为“判决”。对法律文书的文本校对,需要结合语句中所表达的语义和语用来判别是否出现了字词的使用错误并给予提示。使用人工进行法律文书校对,不仅耗费过多的人力资源成本,还会由于各类的不可控风险导致漏判与误判。应用计算机自动文本校对技术判别法律文书的书写错误,目前的相关研究还比较少。
计算机科学领域内针对法律文书的自动校对技术研究比较少。张永安[4]利用定制的语料库构建了一个二元词知识库,使用N-gram模型对文书中的篇章结构和法律术语等进行检测,完成文书的自动校对。徐雅斌[5]使用条件随机场模型结合法律字词词缀特征对法律专业术语进行识别和校验。甘雨坤[6]利用第三方插件,使用语法树识别工具综合检查文书的语法逻辑和业务逻辑,以此来构建文书纠错系统。王云[7]综合计算机中文文本校对特点和原理概述了文本校对的一般方法。上述方法针对法律术语进行了校对技术的研究,但一篇完整的文书中除了法律术语以外,还存在着大量的日常叙述用语,如何区分法律术语和日常叙述语并针对这些用语分别进行自动校对仍然有很多难点需要处理。
本文使用现代汉语语法规则和法律文书写作规范,利用模糊分词和正则规则匹配技术,对照专业词库及自定义词库将句子拆分为若干词或词组,使用生词识别规则合并单字词散串为短语,将合成短语转换为对应的汉语拼音并找出与之相匹配的中文短语集合,然后使用词向量相似度算法进行识别计算,最后使用LSTM模型检查和纠正错误字词,实现法律文书的文本自动校对。
2 法律文书文本错误类型分析
法律文书的错误从表现形式上看主要分为叙事陈述时的直接错误和行文书写时的隐含错误。笔者通过对中国裁判文书网上公开发布的文书进行统计分析,对错误情况概述如下。
2.1 叙事陈述错误
本类别错误主要是在叙事陈述时发生错字、漏字、多字等错误。
(1)错字。错字即为字词使用错误,是指文书中的字词被另外的字词所替代从而出现错误。一般替换的字词具有音形类似的特点。
例1 按照《中华人民共和国民事诉讼法》低二百五十三条之规定
其中,单字“低”就是单字“第”的音相似错误,此类错误会导致上下文语境理解不合理。
例2 人民法院在审理此类纠纷时,要对其试题权利能否对抗执行进行判断
其中,词汇“试题”是词汇“实体”的音似词错误,尽管词汇本身没有错误,但放在句子中同样会出现搭配不合理的问题。
(2)漏字。漏字即为字词缺失错误,是指文书中出现丢字、少词等情况从而导致句子意思表达不完整。
例1 被告在一审提交答辩状期对管辖权提出异议
其中,“答辩状期”后面缺少了“间”字,致使阅读句子的人需要通过猜测才能获知句子所要表达的真实意义。
例2 被告在火车上写下了上述文字内容
其中,“被告”后面缺少了“坐”字,出现语义牵连从而致使句子表达出现了理解错误。
(3)多字。多字即为字词书写重叠,是指在文书撰写过程中某个字重复书写或突然增加从而导致句子表达意义出现差异。
例1 询问上下午间车辆通行记录
其中,“上下午间”后面增加了“间”字,使得句子表达的意思发生了变化。
例2 查看机构的早晚日报告来检查运行状况
其中,“早晚日报告”中增加了“日”字,使得句子表达的意思发生了变化。
2.2 行文书写错误
本类别错误主要是在行文书写时发生涉案信息的前后文不统一情形,此类错误较第一类错误具有隐含性。包含有当事人信息不统一、公诉机关与审判机关不匹配、法条使用不规范等。
(1)当事人信息前后文不统一。当事人信息包含有涉案人的性别、出生日期、民族、住址、文化程度等。上述信息中,姓名的前后不统一最为普遍。例如,某篇文书前文中当事人姓名为“李俊为”,而后文中出现由于联想输入等因素而出现名字变化为“李俊伟”的情形,这使得文书的严肃性大打折扣。
(2)公诉机关与审判机关不匹配。公诉机关是代表国家执行公诉职能,依法向法院提请追究被告人刑事责任的机关,而审判机关是依照法律规定代表国家独立行使审判权的机关。两者之间一般来说是相互匹配的,而一旦出现机关地位不匹配的情形,削弱了文书的公正性。
(3)法条使用不规范。法条是量刑判罚的依据,在法院的判决活动中需要避免由于法律法规的更新和思维惯性从而导致的引用错误。对案件的法条引用出现疏漏会削减文书的权威性。例如,某篇文书中涉及一般民事赔偿的纠纷,而在判决中却引用了刑事赔偿的法条,致使判罚力度加大,无端造成涉案人员的额外损失。
3 文书错字自动识别校对设计及实现
通过对法律文书中的常见书写错误进行分析,可以看出,对叙事陈述错误,其错误形式较为明显,可以通过对文书中的语句拆分找出异常单字,继而通过单字合并、词向量距离计算等技术识别错误字词。而行文书写时的隐含错误,由于其错误形式更加隐蔽,通常需要严格的上下文语义判断,同时一些疑似字词的最终确定同样需要上下文语意的判断,这都需要引入更强有力的检查方法。
基于上述分析,本文设计的文书错字自动识别校对流程如图1所示。对于一篇法律文书,首先应利用文本挖掘技术将文书信息结构化,提取出涉案人员、审判过程、量刑结果等关键数据。在本文中设计使用正则规则匹配技术对文书进行解析。然后,基于中文分词等技术对结构化的文书进行处理,并使用词向量距离计算找出异常词语。最后,结合异常词语所在句子的上下文语义环境,使用深度学习算法,如神经网络等计算异常词语存在的概率以及确定接近正确语义的备选词语集合。

图1 文书错字识别校对流程图
3.1 单字词散串合并
单字词散串合并是纠正错别字词的第一步,它是由对法律文书进行分词后,将未识别单字生词组合生成的。如果文书中包含有错字错词,则该错字或错词会被分成单字,即可对单字词合并成字串并构造词向量进行后续的近似度计算。汉语分词是语法、语义分析的基础,一个分词质量高的算法对文本校对的结果有着重要的作用[8-9]。本文中使用了基于标注的中文分词方法,把对整篇文书的分词过程看成是字词在字串中的标注问题。
标注过程,即依据预定义特征进行词位特征的学习并形成一个概率模型。对待标注字串进行标注时,应依据字与字之间的紧密程度得到标注结果。标注过程使用了分词表,在分词表中注明了各类词汇以及词性,即预定义特征。
常用的分词表缺乏领域专业词汇,本文根据法律文书的行文特点,按照不同的文书类别和审理程序抽取法律专业词汇和短语形成专业词汇表,扩充至常规分词表中对文书进行分词标注。同时,在构建专业领域分词表时,本文进行了优化,将所有法律专业词汇重新定义了词性标注。同时,将一些常用字词合并成短语形成的自定义词语也新定义了词性标注。新词库词性标注类别如表1所示。

表1 新建词库词性标注
句子分词标注完成后,本文中将正确的分词使用特殊符号进行了标记,保留无法识别的单字词并通过以下规则进行单字词的散串合并[2]:
(1)相邻两个串中,两个串均是单字且两个单字成词的概率小于阈值,则进行合并。
(2)相邻两个串中,第一个串为单字,第二个串为多字,则进行合并。
(3)相邻两个串中,第一个串为多字,第二个串为单字,则进行合并。
3.2 词向量距离计算
词向量间的距离,其结果标识了两个文本之间的相似程度。直观来看,两个文本之间相同的部分越多,相似度越高。基本的词向量相似距离计算由于词向量生成维度过高从而增加了相似距离计算时的资源消耗。同时,传统的计算方法对字词顺序敏感,因此会出现同一字词替换不同位置的单字而相似距离计算有很大差异的现象[10-12]。
获得单字词散串后,还需有与之相比较的短字词文本才能进行计算。本文中,获取比对短字词文本集的方式首先是将单字词散串转换成汉语拼音,然后在搜索此汉语拼音所对应的短字词文本,形成比对集合。计算相似度时,本文定义待计算短字词文本组成的单字集合为s,即
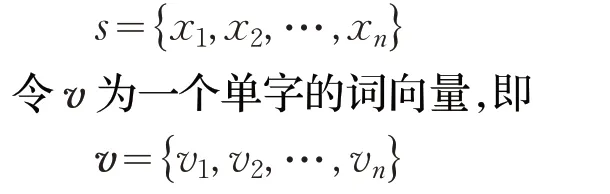
则两个短字词文本之间的相似度计算公式为:

相似度取值范围在0 和1 之间,且只有当两个短字词文本完全相等时取值为1。
3.3 错误字词识别
词向量距离计算解决的是对于两个短语或句子之间的相似程度。在获得了相似度符合阈值的字词短语后,还要对单字散串所在句子的上下文语境关系进行识别,以便确认疑似错误字词是否存在和备选字词是什么。
在结合上下文语境确认疑似错误字词时,本文使用了LSTM 模型并进行了针对法律文本的改进训练。LSTM模型于1997年由Seep和Jurgen提出,模型通过设置输入门、输出门、遗忘门等解决了出现在循环神经网络训练中的梯度消失现象[13-14]。其模型示意如图2所示[15]。
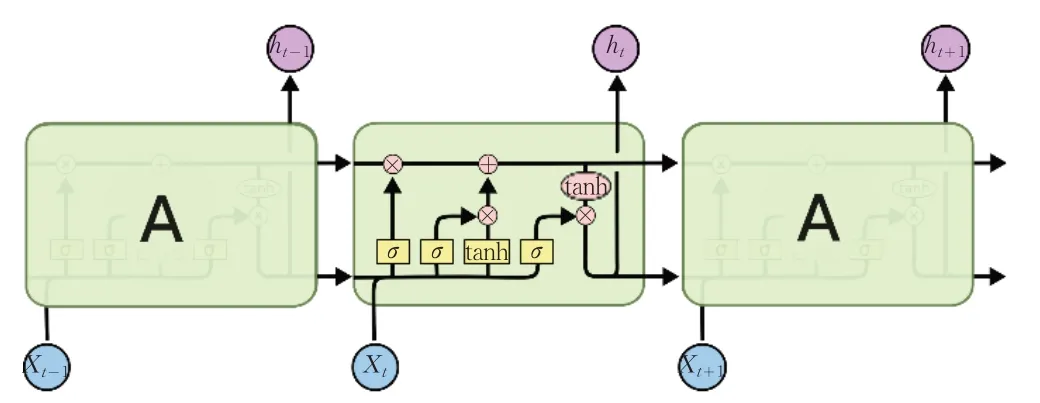
图2 LSTM模型图示
本方案使用LSTM模型进行疑似字词判断,模型的输入即为疑似字词所在短句,且每一时刻输入句子中的一个单字短语。在模型运算时,先将短句文本转换为词向量Xi作为模型的输入数据。而遗忘门读取hi-1和Xi并输出一个0 到1 之间的数值来表示舍弃信息的权重,计算公式为:

同时,模型通过输入数据计算状态数值,利用遗忘门数值来决定每个网络节点状态的变更,即

式中,C为状态值。最后,输出门联合状态值以及输入序列得到输出值:

通过模型计算后输出结果即为标注结果,如果是正确字词,则输出原有字词;如果是错误字词,则使用标注符号ERRDIC进行标记输出,即为hi。模型使用softmax交叉熵损失函数,通过不同时刻的逐字词输入,结合语义计算词语是否正确的概率并将最终概率最大的标注进行标记,以此来标识输入句子中的字词是否为疑似字词。
3.4 面向法律文书的文本校对实现
根据上述设计,实现逻辑见下述伪代码所述。
算法1 面向法律文书的文本校对算法
输入:法律文书
输出:错字错词组
1. 使用正则匹配规则对文书按照书写规范分为标题、首部、正文、尾部四个部分,形成段落数组X
2. for each s in X do
3. 利用词库对s进行分词
4. 将分词正确的词语进行标记
5.使用散串合并规则将单字合并
6. 对合并形成的散串转换汉语拼音
7. 使用转换后的汉语拼音搜索相对应的短语字词形成集合
8. 将第7步搜索出的字词集分别与第5步中形成的散串计算相似度
9. 对相似度数值进行分析,如果没有相似度为1的情形,则进入下一步进行纠错处理;如果有相似度为1的情形,则判定为正确字词,结束算法
10. 使用LSTM模型结合语义找出短语字词集合中与单字词散串匹配度最优的字词,将之判定为纠错词
11. 将确认错字错词与纠正词输入返回列表
12. End For
4 实验结果和分析
4.1 测试集的构建
本文使用中国裁判文书网上公开发布的法律文书数据构成实验数据集,该网站公布各级法院判决生效的裁判文书,具有实时性。实验数据选取了某省2019 年发布的各类具有代表性判决书、裁定书、决定书共2 000篇。通过预先人工筛查的方式找出文书中的错字错词,统计出实验数据中错字错词占比及文书分布情况。
4.2 评价标准
实验评测以召回率、准确率和F-Score 作为评价标准。召回率本意是指应被正确分类的样本数占某分类总样本数量的百分比,准确率是指被分类器正确分类的样本数量占分类器总分类样本数量的百分比,F-Score是平衡召回率和准确率而引入的指标数值,是召回率和准确率的调和平均。本评测实验中主要是获取文书中的错字错词,因此指标定义如下:

4.3 结果分析
使用本文提出的方法对实验数据集进行实验,得到召回率81%,准确率80%,F-Score为81.03%。实验数据如表2和表3所示。
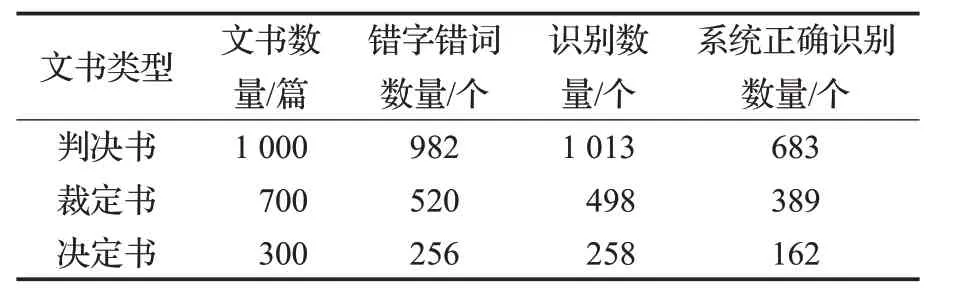
表2 实验数据

表3 实验结果 %
表3中,准确率、召回率以及F值均由表2中相对应的数据依公式计算得出。观察表2的数据,三类文书中识别出错字错词的准确率均大于召回率,这说明本文中所述方法并没有把所有可识别的错字错词正确识别。同时,判决书类型的错字错词纠错准确率和召回率均是三种文书类型中最低的。探究其中的原因,主要是有以下几方面:
(1)判决书类型在文书中的数量众多,除了法律术语外,文书内的日常性叙述语言众多,对日常用语的经验性常识和书写规则仍然需要收集。
(2)文书书写有标准,但由于错误众多且分散,又由于错误字词所在句子是因语义或语用造成的错误,这仍然需要收集大量语料进行深度学习模型的训练。
5 结束语
本文对法律文书出现的书写错误进行了分析和总结,提出了一种规则匹配和概率统计相结合的文本纠错校对方法,实验结果显示,该方法有效地解决了对法律文书中书写错误的纠错识别。实际应用中给法律文书的质量提升拓展了上升空间,同时,此方法也积累了一系列的法律专业术语和文书日常用语。实验结果表明该方法有效。本文的后续工作将进一步搜集语料,丰富专业词库。完善模型训练数据,提高识别准确率。
