Method for detecting dragon fruit based on improved lightweight convolutional neural network
2020-12-25WangJinpengGaoKaiJiangHongzheZhouHongping
Wang Jinpeng, Gao Kai, Jiang Hongzhe, Zhou Hongping
Method for detecting dragon fruit based on improved lightweight convolutional neural network
Wang Jinpeng, Gao Kai, Jiang Hongzhe, Zhou Hongping
(210037,)
The real-time detection of dragon fruit in the natural environment is one of the necessary conditions for dragon fruit automated picking. This paper proposed the lightweight convolutional neural network YOLOv4-LITE. YOLOv4 integrates multiple optimization strategies, and its detection accuracy is 10% higher than traditional YOLOv3. However, the YOLOv4 requires a large amount of memory storage because of the complexity of backbone network and huge calculation, so it is not suitable to be deployed in embedded devices for real-time detection. The Mobilenet-v3 network was selected to replace CSPDarknet-53 as the YOLOv4 backbone network because it can significantly improve the detection speed. Mobilenet-v3 extends the depth of separable convolution and introduces the attention mechanism, which reduces the computation of feature maps and speeds up the propagation speed of feature maps in the network. In order to improve the detection accuracy of small targets, up-sampling is carried out on the 39-layers and 46-layers respectively. The 39-layers feature map is combined with the feature map of the last bottleneck layer, and upsampling is applied twice. The fused feature map uses a 1×1 convolution to enhance the dimension of the feature map. Then, up-sampling is conducted on the 46-layer to fuse with the 11-layer feature map, and the feature map is fused for multi-scale prediction. The convolution is performed three times to obtain a 52×52 scale feature map for the detection of small targets. The 51-layer feature map is combined with the 44-layer feature map and convolution is applied three times, and a 26×26 feature map is obtained for the detection of medium-sized targets. The 59-layer feature map is combined with the 39-layer feature map, and convolution is applied three times, and a 13×13 feature map is obtained for the detection of medium-sized targets. 2513 images of dragon fruit under different occlusion environments were used as data sets for the training experiment. Results showed that the lightweight YOLOv4-LITE network proposed achieved an Average Precision (AP) value of 96.48%, the average of the accuracy and recall rates (1 score)of 95%, average Intersection over Union (IoU) of 81.09%, and model occupying 2.7 MB of memory. Meanwhile, by comparing and analyzing different backbone networks, the detection speed of Mobilenet-V3 was improved, and 160.32 ms reduced the average detection time compared with CSPDarknet-53. YOLOv4-LITE took only 2.28 ms to detect a 1 200×900 resolution image on the GPU. YOLOv4-LITE network can effectively identify dragon fruit in the natural environment, and has strong robustness. Compared with existing target detection algorithms, the detection speed of YOLOv4-LITE was approximately 9.5 times higher than that of SSD-300 and 14.3 times than that of Faster-RCNN. The influence of multi-scale prediction on model performance was further analyzed, and four feature maps with different scales were used for fusion prediction. The AP value was improved by 0.81% when four scales were used for prediction, but the average time was increased by 10.33 ms, and the model weight was increased by 7.4 MB. The overall results show that the lightweight YOLOv4-LITE proposed in this paper has significant advantages in terms of detection speed, detection accuracy and model size, and can be applied to the detection of dragon fruit in a natural environment.
models; deep learning; fruitdetection;convolutional neural network; YOLOv4-LITE; real-time detection
0 Introduction
Recently, object detection technology have undergone continual innovation[1]. Target detection technology based on convolutional neural networks is divided into two main categories: one-stage methods such as YOLO[2]and SSD[3], and two-stage methods such as RCNN[4], Fast-RCNN[5], and Faster-RCNN[6]. Convolutional neural networks have improved recognition and classification capability because it addresses the problem of incomplete information extraction caused by artificial design features in traditional machine vision. At present, convolutional neural networks widely applied in fruit recognition[7], maturity detection[8], hyperspectral analysis[9-10], and crop growth prediction[11]of intelligent agriculture. The automatic harvesting in orchards is trending the development of intelligent agriculture. Some fruit with poor growth environments, mainly by handpicking, carry higher risk. Therefore, to improve labour productivity and reduce production costs, it is necessary to realize automatic fruit recognition and intelligent harvesting.
The detection of fruit in a natural environment provides theoretical support for the development of intelligent picking[12]. In the unstructured natural environment, several factors affect recognition, such as light changes, leaf occlusion, weather conditions, and fruit growth. Certain clustered fruits, such as citrus[13], grapes[14], and kiwi[15], with high density and severe occlusion, are difficult for traditional image processing technology to be applied in these scenes. At the early stage, the artificial extraction of fruit colour, shape, outline, and other characteristics are used to identify and locate fruit in the natural environment. However, the accuracy of extraction methods is generally low due to the large error[16]. With the development of deep learning and convolutional neural networks, several researchers have proposed fruit recognition methods[17]. Peng et al.[18]improved upon the Faster-RCNN algorithm using the ResNet50 network instead of the VGG16 network to extract weed image features, enriching the output feature information and improving detection accuracy. Liang et al[19]proposed a method for detecting litchi in the natural environment at night using the YOLOv3 network model that achieved the Average Precision (AP) value of 96.52%. Zabawa et al.[20]proposed an automatic target framework based on image analysis for grape recognition that uses a convolutional neural network to perform semantic segmentation to detect single berry in images. They used a connected component algorithm to calculate the number of berries, achieving an accuracy rate of up to 94%, which solves the identification problems caused by clustered grapes.
Sa et al.[21]used Faster-RCNN to carry out fruit detection through transfer learning. The Faster-RCNN algorithm is an advanced two-stage method that first generates a Regional Proposal Network (RPN) and then detects the target area. Faster-RCNN’s detection speed is slow, and it cannot produce real-time results with high-resolution images. The efficient single-stage methods YOLO and SSD achieve better detection results than Faster-RCNN in detection speed and detection accuracy. Tian et al[22]improved the dense network DenseNet and applied it to process feature maps with low resolution in the YOLO-V3 network to detect densely grown apples in the natural environment, achieving the average of the accuracy and recall rates (1 score) of 81.7%. Koirala et al.[23]proposed a network called YOLO-Mango for fruit detection and load estimation that achieves an1 score of 96.8%. At present, several advanced feature extraction networks are available, such as VGG16, ResNet, Darknet-19, and Darknet-53. However, when a harvesting robot is in operation, visual information is critical, which requires low latency and high precision model. The vision system of a harvesting robot is typically located in an embedded system or mobile device, which has high model and memory storage requirements. Thus, calculations cannot be prohibitively large. The existing target detection model has a deep network. As the network deepens, its accuracy rate gradually increases, but its detection speed decreases, which makes it challenging to meet the real-time requirements of harvesting equipment. Therefore, a deep network must be pruned to realize a lightweight model and further improve detection speed while ensuring detection accuracy. Lu et al.[24]proposed an improved YOLOv3 network for citrus recognition by optimizing the YOLOv3 backbone network and using MobileNet-v2 to extract features to reduce the number of network calculations. They reported a detection speed of 246 frames/s and achieved an AP of 91.13%. Shi et al.[25]optimized the YOLOv3-Tiny algorithm, and through their channel design and space mask, proposed an attribute partition method that removes part of the convolution kernel in the convolutional network. Their model required 68.7% less calculation and achieved 0.4% higher accuracy than the previous method.
At present, there are no relevant references to research on the recognition of dragon fruit. An investigation of the growth of dragon fruit in the natural environment revealed that the growth environment of dragon fruit is relatively complicated. Dragon fruit branches and leaves are long and cover a large surface at the mature stage, and fruit occlusion is severe, which makes the fruit challenging to identify. Traditional image processing methods are not well suited to dragon fruit recognition. Therefore, the present study article uses deep learning, namely, the advanced one-stage method YOLOv4[26]algorithm, to detect dragon fruit. Based on this algorithm, a lightweight YOLOv4-LITE algorithm is proposed by adjusting the backbone network to integrates MobileNet-3[27]. This paper is organized as follow. First, the collection of dragon fruit images under different natural environment scenarios for network training is described. Then, several existing networks are analyzed and compared. Finally, the advantages and disadvantages of YOLOv4-LITE are objectively evaluated.
1 Materials and Methods
1.1 Data collection
2 000dragon fruit images in theorchard and greenhouse wereobtained by a web crawler which ensured the diversity in dragon fruit dataset. 564 dragon fruit images were selected to form the dataset in occlusion, cloudy, sunny, backlighting, and intense light conditions.
1.2 Dataset preparation
The dataset was enhanced with OpenCV. The original images were rotated at a randomly chosen angle from -180° to 180°. The dataset was randomly flipped, and the data were enhanced by clipping and scaling, which prevented any overfitting caused by a single sample. The dataset was expanded by applying image processing techniques such as histogram equalization and adjusting saturation, hue, and brightness. The above methods were used to expand each image in the dataset, as shown in Fig.1.
The dataset was expanded through data enhancement, and 2 513 images were selected as the data set in this paper. Finally, the IabelImg tool was used to label the dragon fruit in the images. The PASCAL VOC dataset format was used for storage. The uniform distribution dataset was divided into a training set of 70% images, a validation set of 10% images, and a test set of 20% images. There are 1 036 occlusion images, 738 images on cloudy and sunny days, and 739 images with backlighting and hard lighting. The number of images in each dataset was shown in Table 1.
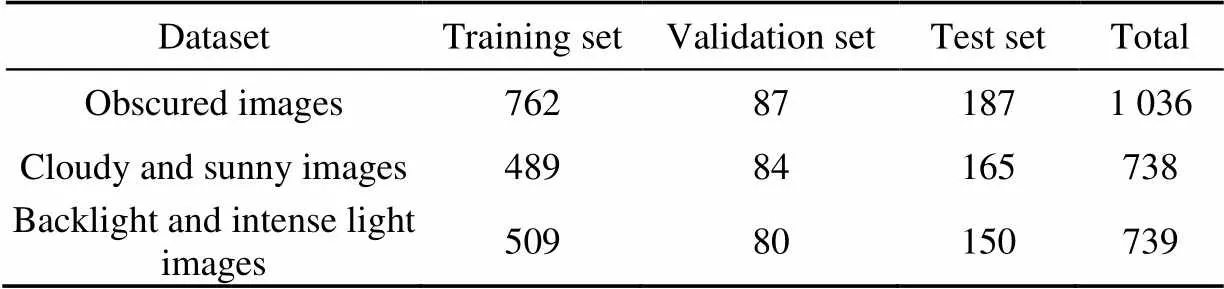
Table 1 Number of images in the datasets

Fig.1 Results of data augmentation
1.3 YOLO convolutional neural network
The YOLO network is an end-to-end rapid detection method that converts the target detection problem into a regression problem. Input image prediction can be achieved by using the convolutional neural network structure of the YOLO model. The YOLOv1 model uses GoogLeNet as its backbone network[2]. The end of the network uses a fully connected layer to predict the target; however, the detection effect is small for small and intensive targets, and the recall rate is low. The YOLOv2 and YOLOv3 models respectively use Darknet-19 and Darknet-53 as the backbone network to achieve feature extraction. The YOLOv2 model borrows the RPN idea from Faster-RCNN, introduces an anchor box, and deletes the fully connected layer and pooling layer in the original network[27]. The YOLOv3 model improves detection accuracy, which consists of convolutional and residual layers[28]. With the YOLOv3 model, the single-label prediction is improved to multi-label prediction classification, and combined with the FPN method for fusion prediction of feature maps at different scales, the detection accuracy of small targets is improved.
The YOLOv4 model integrates many existing algorithmic tricks, including Mosic, CIoU, DropBlock, PANet, NMS and Mish, and introduces an attention mechanism to enhance the feature map[26]. The detection accuracy of the YOLOv4 is 10% higher than that of the YOLOv3. The YOLOv4 proposes a new backbone network, CSPDarknet-53, as shown in Fig.2. The Cross Stage Partial Residual Network (CSPResNet) is added to the CSPDarknet-53 backbone network. CSPResNet divides the feature map into two components, one that passes through the residual block and another that passes through the convolutional layer and transfers the fused feature map to the next stage. The purpose of these components is to reduce the amount of calculation and achieve a richer representation. The gradient combination strengthens the learning ability of the backbone network and avoids the gradient disappearance problem caused by deep networks. At the end of CSPDarknet-53, the Space Pyramid Pool Network (SPP) is utilized to improve the sensing field and extract important feature information. The prediction layer in YOLOv3 adopts the Feature Pyramid Networks (FPN) network structure. FPN is mainly used to improve target detection by fusing high and low layer features, so the final output features better represent the information of the input picture’s various dimensions.

Fig.2 YOLOv4 network structure
However, in the deep network model, shallow feature information is crucial for semantic segmentation. FPN involves a bottom-up process; thus, the features of the shallow layer are transmitted through multiple layers, and the loss of information is more serious, resulting in decreased detection accuracy. YOLOv4 adds a bottom-up feature fusion layer called Path Aggregation Network (PANet) after the FPN network. Each layer of the PANet network is composed of five convolutional layers, which are used to retain more shallow feature information, make shallow feature information, and make in-depth feature information more complete to improve the detection of small targets significantly.
A 416×416 input image is taken as an illustrative example. After five downsamples, the output of the backbone network is a 13×13 size feature map. After two upsamples and the feature map output by the residual layer are fused, the fused feature map input to the FPN network propagates from top to bottom and transmits shallow information to PANet at the bottom of the FPN. PANet fuses the feature map in FPN to predict, create output, and obtain three types of 13×13, 26×26, and 52×52 images. The large, medium, and small targets are detected by using the feature map of different receptive fields.
1.4 YOLOv4-LITE lightweight neural network
1.4.1 YOLOv4-LITE backbone network
YOLOv4 improves detection accuracy but increases the calculation of the backbone network CSPDarknet-53 and has higher GPU memory and model storage requirements. On embedded platforms (Jetson Xavier NX), its video detection speed is only 25 frames/s. The lightweight YOLOv4-LITE network model for real-time detection was proposed to extract features by adjusting the backbone network and using Google’s MobileNet, a mobile feature extract network. MobileNet can realize real-time detection on embedded devices, and avoid insufficient memory and high latency caused by complicated models. MobileNet-v3[29]is obtained through the neural architecture search. There are two versions of MobileNet-v3, Small and Large. The Large version is 1.4% more accurate than the Small version on the ImageNet classification task, but its detection speed is reduced by 10%. In order to ensure real-time dragon fruit detection, the Small version was used as the backbone network of YOLOv4-LITE. MobileNet-v3 combines the deep separable convolution of MobileNet-v1[30]and with the inverse residual structure of MobileNet-v2[31], and adds an attention mechanism. MobileNet-v3 adds the squeeze and excite structure to the bottleneck layer, which modifies the expansion layer channel to 1/4, improving detection accuracy without increasing calculation time. In MobileNet-v2, a 1×1 convolution layer before average pooling improves the dimension of the feature map. However, in MobileNet-v3, the feature map is first reduced by 7×7 using average pooling to 1×1. Then, the feature map dimension is increased, reducing the amount of calculation by a factor of 49, and improving the speed of feature map calculation.
1.4.2 YOLOv4-LITE prediction network
YOLOv4 utilizes the same multi-scale prediction method as YOLOv3; however, YOLOv4 incorporates PANet at the prediction layer. In order to improve the detection accuracy of MobileNet-v3 on small targets, MobileNet-V3 is combined with PANet to realize multi-scale prediction. In this paper, 39-layer and 46-layer upsampling feature map fusion was featured. For example, 416×416 image as input, the 39-layers feature map was combined with the feature map of the last bottleneck layer, and upsampling was applied twice. The fused feature maps were used a 1×1 convolution to enhance the dimension of the feature map. Then, up-sampling was conducted on the 46-layer to fuse with the 11-layer feature map. The convolution was performed three times to obtain the 52×52 scale feature map for the detection of small targets. The 51-layer feature map was combined with the 44-layer feature map, convolution was applied three times, and the 26×26 feature map was obtained for the detection of medium-sized targets. The 59-layer feature map was combined with the 39-layer feature map, convolution was applied three times, and the 13×13 feature map was obtained for the detection of medium-sized targets. The YOLOv4-LITE backbone network structure and parameters were shown in Fig.3.
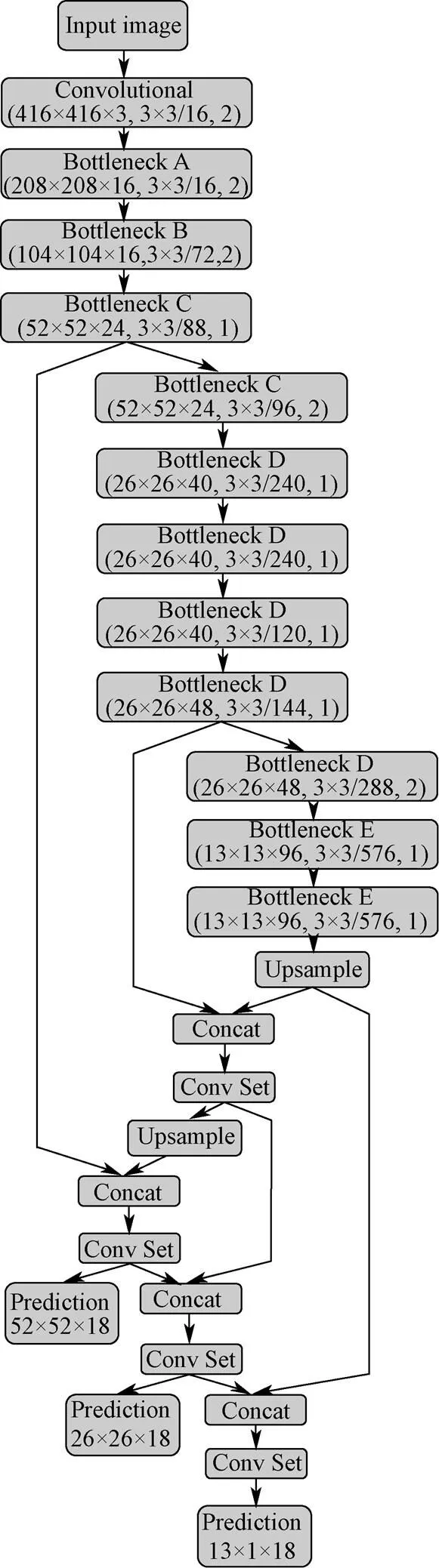
Note: The numbers in bracket were image resolution, size/filters, stride respecyively.
2 Experiment
2.1 Experimental platform
The training environment and test environment of the model was the same. The experimental setup used in this paper consisted of the Ubuntu 18.04 operating system, the darknet framework, the Intel (5) Core (TM) i5-9600KF, 3.7 GHz with six cores, 16 GB of memory, the NVIDIA GeForce GTX 1660Ti 6 GB video memory graphics card, and CUDA version 10.2 with CUDNN version 7.6 acceleration.
2.2 Experimental parameters
In order to compare different networks, the network batch size, learning rate, momentum, iteration, and initial weight parameters were the same. Consider the memory of the computer; the batch size was set to 64; the learning rate was set to 0.001. The learning rate decreased to 0.000 1 after 35 000 iterations and 0.000 01 after 40 000 iterations. Momentum was set to 0.95, decay was set to 0.000 5, and the iteration was set to 50 000 in this paper.
Anchor box clustering was applied to the dragon fruit dataset in this paper, using K-means clustering and, nine anchor boxes of different sizes (19, 23), (34, 38), (57, 60), (68, 93), (115, 81), (94, 135), (127, 164), (185, 167), (216, 265), which were evenly distributed to three differently scaled feature maps for prediction.
2.3 Model evaluation
After training the model on the training set,1 score, AP value, average Intersection over Union (IoU), average time, and model weights as evaluation indicators to evaluate the model. The1 score and AP value were defined as follows:

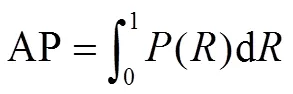
whererepresents the accuracy rate,represents the recall rate,1 represents the reconciled average of the accuracy and recall rates, and AP represents the average value of the positive sample recognition accuracy
The IoU evaluates the performance of the model by calculating the overlapping ratio of the prediction and true bounding boxes. The IoU was defined as follows:
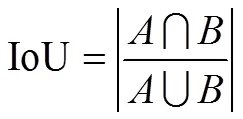
whererepresents the prediction bounding box, andrepresents the true bounding box.
3 Results and analysis
3.1 Analysis of dragon fruit recognition results
The YOLOv4-LITE model allowed for the rapid identification of dragon fruits in cloudy (Fig.4a) and hard light environments (Fig.4b), as well as and backlight environments (Fig.4c). Fig.4 showed that fruits were occluded in three different environments. Fruit surfaces occluded by 1/2 or even 2/3 could still be identified. Due to their complex environment, some fruit surfaces may not be recognized. Overall, the YOLOv4-LITE model exhibits performance and strong robustness and allowed for dragon fruits recognition in the natural environment.
3.2 Analysis of different backbone networks
The experimental results from training Darknet-19, Darknet-53, Tiny, MobileNet-v2, and MobileNet-v3 were shown in Table 3. The detection accuracy of CSPDarknet-53 was 6.57% higher than Darknet-53, reaching 97.91%. However, The CSPDarknet-53 backbone network was excessively complicated with high model weight of 256 MB and long average detection time of 162.60 ms. Therefore, it was difficult for deeper backbone networks to meet high-speed requirements on embedded devices. MobileNet-v3 simplifies the backbone network with an AP value of 96.48%, which was slightly lower than CSPDarknet-53, but its detection speed was improved. It took only 2.28 ms to process a 1 200×900 resolution image on the GPU, and 160.32 ms reduced the average detection time compared with CSPDarknet-53. With detection accuracy guaranteed, MobileNet-v3’s detection speed was approximately 71 times that of CSPDarknet-53. Furthermore, the model weight was only 2.7 MB, which was 253.3 MB less than CSPDarknet-53, which significantly reduced the operating cost of embedded devices. In summary, MobileNet-v3 has the characteristics of high detection accuracy, high detection speed, and low model memory consumption, making it distinctly advantageous for robotics and embedded devices.
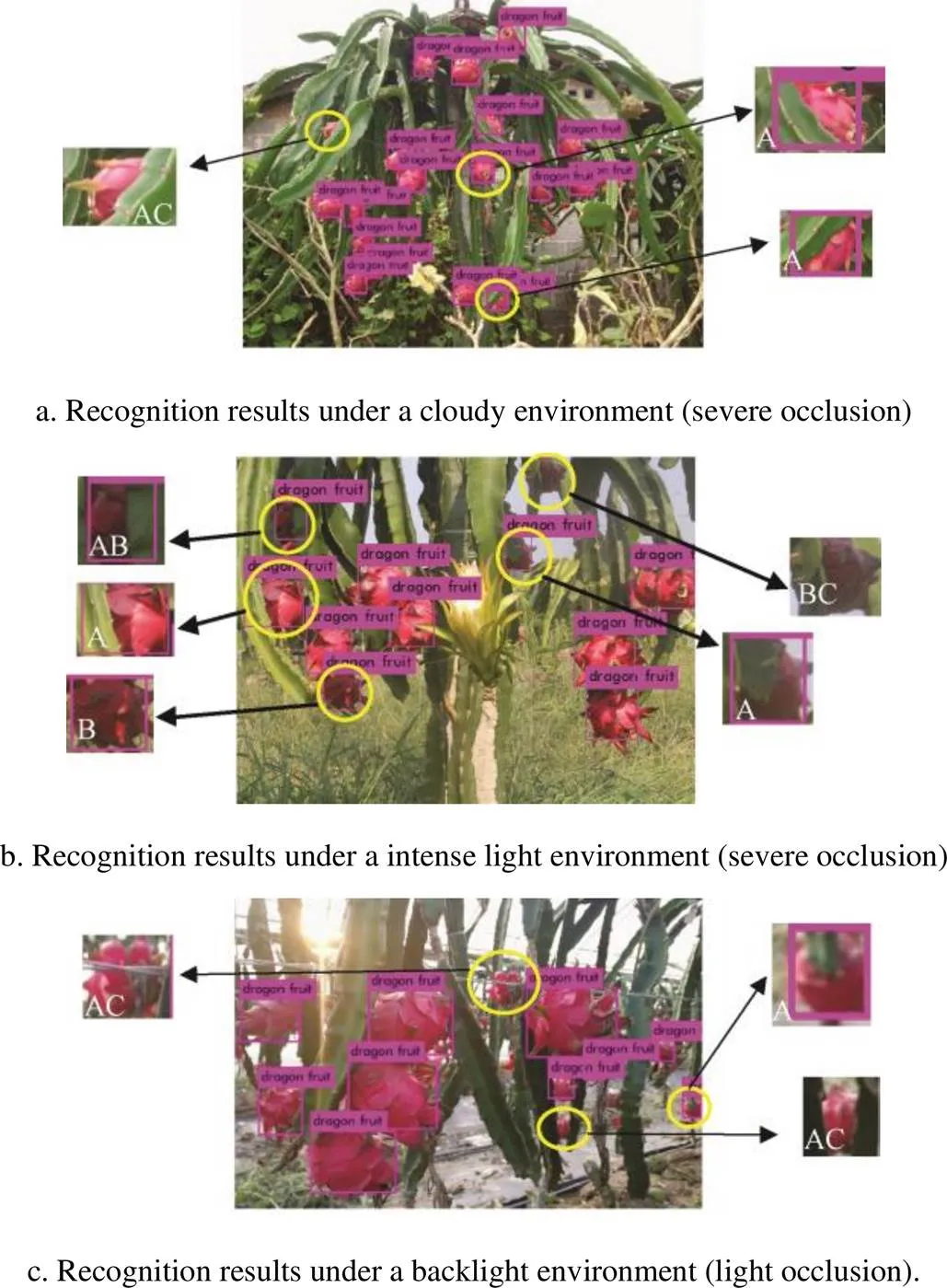
Note: A represents occluded fruit, B represents shadowing on the surface of the fruit, and C represents undetected fruit.

Table 3 Performance of different backbone networks through 50 000 iterations
Note:1 score represents the average of the accuracy and recall rates. Same as below.
3.3 Analysis of multi-scale prediction results
In order to further improve the detection accuracy of MobileNetv3, the YOLOv4-LITE used different scales feature maps for prediction. Table 4 showed four scales model (YOLOv4-LITE-4L) detection accuracy was 0.81% higher than that of three scales model (YOLOv4-LITE), but the average time was increased by 10.33 ms, and the model weight was increased by 7.4 MB. Multi-scale prediction increased the computation of feature map, and improved the detection accuracy but reduced the detection speed. Thus, YOLOv4-LITE’s detection speed was more suitable for real-time detection.

Table 4 Comparision of different scales network models
3.4 Analysis of different network models
YOLOv4-LITE has a faster convergence rate. When iterating to 10 000, the loss of YOLOv4-LITE was approximately 0.2, that of SSD-300 was approximately 0.5, and that of Faster-RCNN was approximately 0.8. When iterating to 35 000, the learning rate decayed to 0.000 1, and the loss of all three models were decreased. After iterating to 40 000, all three models were converged, and YOLOv4-LITE had the lowest loss. The experimental results were shown in Table 5, where the AP value of the YOLOv4-LITE algorithm proposed in this paper was shown to be 8.29% higher than Faster-RCNN and 6.36% higher than SSD-300. YOLOv4-LITE also has significant advantages in terms of its detection speed, which was approximately 9.5 times that of SSD-300 and 14.3 times that of Faster-RCNN. The detection results of the three models were shown in Fig.5. To further verify the performance of the algorithm in this paper, it was compared with the fruit detection methods of YOLOv3[24], YOLOV3-dense[22], and R-FCN[32]. The YOLOv4-LITE’s1 score showed 2%, 13%, and 5% improvement over YOLOv3[24], YOLOV3-dense[22], and R-FCN[32], respectively. Besides, YOLOv4-LITE’s AP value was 5.35% higher than YOLOv3[24]and 1.38% higher than R-FCN[32]. Remarkably, YOLOv4-LITE’s average detection speed time was 327.72 ms faster than YOLOV3-dense[22]and 197.72 ms faster than R-FCN[32]. Base on the comparison of existing target detection models, the lightweight YOLOv4-LITE network model delivers a significant advantage in terms of detection speed and accuracy.

Table 5 Performances of different network models

Fig.5 Detection results of the three models
4 Conclusions
This study explored the detection of dragon fruit in the natural environment. The YOLOv4-LITE model proposed in this paper used the MobileNet-v3 feature extraction network to improve the YOLOv4’s detection speed. YOLOv4-LITE significantly reduced the feature extraction network's calculation and accelerated the detection speed of the model while ensuring detection accuracy. Experimental results showed that, compared with YOLOv4, the detection speed of YOLOv4-LITE was improved by 71 times; it takes only 2.28 ms to process a 1 200×900 resolution image on the GPU. YOLOv4-LITE AP value was 96.48%, the1 score was 95%. Furthermore, the robustness of YOLOv4-LITE was stronger than the Faster-RCNN and SSD-300. The YOLOv4-LITE model had the advantage of small weight and made it more suitable for use in embedded devices and mobile terminals. In general, YOLOv4-LITE can better solve the problem that dragon fruit is difficult to recognize in the natural environment, and this model can be applied in the field of fruit detection.
[1] Rehman T U, Mahmud M S, Chang Y K, et al. Current and future applications of statistical machine learning algorithms for agricultural machine vision systems[J]. Computer and Electronics in Agriculture, 2019, 156: 585-605.
[2] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//IEEE Conference onComputer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 779-788.
[3] Liu W, Anguelov D, Erhan D, et al. SSD: Single shot multibox detector[C]//European Conference on ComputerVision. Cham: Springer, 2016: 21-37.
[4] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision andPattern Recognition. Columbus: IEEE, 2014: 580-587.
[5] Girshick R. Fast R-CNN[C]//IEEE International Conference onComputer Vision. Santiago: IEEE, 2015: 1440-1448.
[6] Ren S, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in Neural Information ProcessingSystems.The United States: IEEE, 2017, 39: 1137-1149.
[7] Bargoti S, Underwood J. Deep fruit detection in orchards[C]//IEEE International Conference on Robotics and Automation.Sydney: IEEE, 2017: 3626-3633.
[8] Caladcad J A, Cabahug S, Catamco M R, et al. Determining philippine coconut maturity level using machine learning algorithms based on acoustic signal[J]. Computer and Electronics in Agriculture, 2020, 172: 105327.
[9] Hong G, Abd El-Hamid H T. Hyperspectral imaging using multivariate analysis for simulation and prediction of agricultural crops in Ningxia, China[J]. Computer and Electronics in Agriculture, 2020, 172:105355.
[10] Ni C, Li Z, Zhang X, et al. Film Sorting Algorithm in seed cotton based on near-infrared hyperspectral image and deep learning[J]. Transactions of the Chinese Society of Agricultural Machinery, 2019, 50(12): 170-179. (in Chinese with English abstract)
[11] Zhu F, Zheng Z. Image-based assessment of growth vigor for phalaenopsis aphrodite seedlings using convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(9): 185-194. (in Chinese with English abstract)
[12] Kamilaris A, Prenafeta-Boldú F X. Deep learning in agriculture: A survey[J]. Computer and Electronics in Agriculture, 2018, 147: 70-90.
[13] Deng Y, Wu H, Zhu H. Recognition and counting of citrus flowers based on instance segmentation[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(7): 200-207.(in Chinese with English abstract)
[14] Liu P, Zhu Y, Zhang T, et al. Algorithm for recognition and image segmentation of overlapping grape cluster in natural environment[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(6): 161-169. (in Chinese with English abstract)
[15] Fu L, Feng Y, Eikamil T, et al. Image recognition method of multi-cluster kiwifruit in field based on convolutional neural networks[J].Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(2): 205-211. (in Chinese with English abstract)
[16] Sun J, Tan W, Wu X, et al. Real-time recognition of sugar beet and weeds in complex backgrounds using multi-channel depth-wise separable convolution model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(12): 184-190. (in Chinese with English abstract)
[17] Liu X, Fan C, Li J, et al. Identification method of strawberry based on convolutional neural network[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(2): 237-244. (in Chinese with English abstract)
[18] Peng M X, Xia J F, Peng H. Efficient recognition of cotton and weed in field based on Faster R-CNN by integrating FPN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(20): 202-209. (in Chinese with English abstract)
[19] Liang C, Xiong J, Zheng Z, et al. A visual detection method for nighttime litchi fruits and fruiting stems[J]. Computer and Electronics in Agriculture, 2020, 169: 105192.
[20] Zabawa L, Kicherer A, Klingbeil L, et al. Counting of grapevine berries in images via semantic segmentation using convolutional neural networks[J]. Journal of Photogrammetry and Remote Sensing, 2020, 164: 73-83.
[21] Sa I, Ge Z, Dayoub F, et al. Deepfruits: A fruit detection system using deep neural networks[J]. Sensors, 2016, 16: 1-8.
[22] Tian Y, Yang G, Wang Z, et al. Apple detection during different growth stages in orchards using the improved YOLO-V3 model[J]. Computer and Electronics in Agriculture, 2019, 157: 417-426.
[23] Koirala A, Walsh K B, Wang Z, et al. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO.’[J]. Precision Agriculture, 2019, 20: 1107–1135.
[24] Lu A E, Iou A. Orange recognition method using improved YOLOv3-LITE lightweight neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(17): 205–214. (in Chinese with English abstract)
[25] Shi R, Li T, Yamaguchi Y. An attribution-based pruning method for real-time mango detection with YOLO network[J]. Computer and Electronics in Agriculture, 2020, 169: 105214.
[26] Bochkovskiy A, Wang C Y, Liao H. YOLOv4: Optimal speed and accuracy of object detection[Z]. 2020, [2020-07-03], https://arxiv.org/abs/2004.10934.
[27] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger[C]//IEEE Conference on Computer Vision andPattern Recognition. Honolulu: IEEE. 2017: 7263-7271.
[28] Redmon J, Farhadi A. YOLOv3: An incremental improvement[Z]. [2020-07-03], https://arxiv.org/abs/1804.02767.
[29] Howard A, Sandler M, Chen B, et al. Searching for mobileNetV3[C]//IEEE International Conference on Computer Vision. The United States: IEEE. 2019: 1314-1324.
[30] Howard A.G, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[Z]. [2020-07-03], https://arxiv.org/abs/1704.04861.
[31] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[Z]. [2020-07-05], https://arxiv.org/abs/1801.04381.
[32] Wang D, He D. Recognition of apple targets before fruits thinning by robot based on R-FCN deep convolution neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(3): 156-163. (in Chinese with English abstract)
基于改进的轻量化卷积神经网络火龙果检测方法
王金鹏,高 凯,姜洪喆,周宏平
(南京林业大学机械电子工程学院,南京 210037)
在自然环境下对火龙果进行实时检测是实现火龙果自动化采摘的必要条件之一。该研究提出了一种轻量级卷积神经网络YOLOv4- LITE火龙果检测方法。YOLOv4集成了多种优化策略,YOLOv4的检测准确率比传统的YOLOv3高出10%。但是YOLOv4的骨干网络复杂,计算量大,模型体积较大,不适合部署在嵌入式设备中进行实时检测。将YOLOv4的骨干网络CSPDarknet-53替换为MobileNet-v3,MobileNet-v3提取特征可以显著提高YOLOv4的检测速度。为了提高小目标的检测精度,分别设置在网络第39层以及第46层进行上采样特征融合。使用2 513张不同遮挡环境下的火龙果图像作为数据集进行训练测试,试验结果表明,该研究提出的轻量级YOLOv4-LITE模型 Average Precision(AP)值为96.48%,1值为95%,平均交并比为81.09%,模型大小仅为2.7 MB。同时对比分析不同骨干网络,MobileNet-v3检测速度大幅度提升,比YOLOv4的原CSPDarknet-53平均检测时间减少了160.32 ms。YOLOv4-LITE在GPU上检测一幅1 200×900的图像只需要2.28 ms,可以在自然环境下实时检测,具有较强的鲁棒性。相比现有的目标检测算法,YOLOv4-LITE的检测速度是SSD-300的9.5倍,是Faster-RCNN的14.3倍。进一步分析了多尺度预测对模型性能的影响,利用4个不同尺度特征图融合预测,相比YOLOv4-LITE平均检测精度提高了0.81%,但是平均检测时间增加了10.33 ms,模型大小增加了7.4 MB。因此,增加多尺度预测虽然提高了检测精度,但是检测时间也随之增加。总体结果表明,该研究提出的轻量级YOLOv4-LITE在检测速度、检测精度和模型大小方面具有显著优势,可应用于自然环境下火龙果检测。
模型;深度学习;果实检测;卷积神经网络;YOLOv4-LITE;实时检测
Wang Jinpeng, Gao Kai, Jiang Hongzhe, et al. Method for detecting dragon fruit based on improved lightweight convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(20): 218-225.doi:10.11975/j.issn.1002-6819.2020.20.026 http://www.tcsae.org
王金鹏,高 凯,姜洪喆,等. 基于改进的轻量化卷积神经网络火龙果检测方法[J]. 农业工程学报,2020,36(20):218-225. (in English with Chinese abstract) doi:10.11975/j.issn.1002-6819.2020.20.026 http://www.tcsae.org
date: 2020-07-24
date: 2020-10-12
Jiangsu Science and Technology Project (BE2018364); National Natural Science Foundation of China (51408311)
Wang Jinpeng, associate professor, engaged in intelligent agricultural research. Email: jpwang@njfu.edu.cn
10.11975/j.issn.1002-6819.2020.20.026
TP301.6;TP181
A
1002-6819(2020)-20-0218-08
