基于卷积神经网络的心电图分类研究
2020-12-24李林献邱筱岷王正杰王小花
马 晶,李林献,邱筱岷,王正杰,王小花
(无锡市妇幼保健院,江苏无锡214002)
0 引言
近年来,我国心血管疾病的发病率和死亡率快速增长,心血管病死亡占城乡居民总死亡原因的首位,推算心血管病现患人数2.9 亿,占疾病死亡构成的40%以上,及早发现以及治疗是应对心血管疾病的有效措施[1]。心电图可反映心脏的变化情况[2],是诊断心脏正常与异常的重要信息。心电图虽应用广泛,但其对房室肥大的诊断有很大的局限性[3]。在大数据的热潮下,通过深度学习辅助诊断心电图信号正、异常成为了一个备受关注的研究热点。
深度学习已在心电图辅助诊断领域取得了很多成果。朱晓铭等[4]提出了一种基于卷积神经网络(convolutional neural networks,CNN)的十二导联心电图衍生方法,并证明了该方法具有极佳的适用性,明显优于传统算法。原永朋等[5]提出了一个通过构建CNN 生成心电图特征的方法,并验证了该研究方法在MIT-BIH 心电图数据库中识别心电图4 类心拍的指标高且稳定。Acharya 等[6]提出了一种基于CNN的计算机辅助诊断(computer aided diagnosis,CAD)系统,该系统可实现自动检测不同的心电图片段,并取得了很高的准确率。Zhai 等[7]提出了一种通过心电图自动诊断心律失常的二维深度CNN 模型,并将其与2 个著名的CNN 模型进行比较,结果表明该模型分类效果很好。
心电图可体现心脏兴奋的电学变化,血流不畅、服用药物等因素均会使心电图发生异常[8],因此对判断心脏是否健康具有一定的参考价值。本研究运用CNN 对心电图进行分类,实现了高准确率的心电图正、异常分类。
1 实验方法
1.1 数据集的选择
实验数据来源于PhysioNet 的开源数据库[9]。心电图记录共409 条,除去脏数据后共388 条,包括267条正常心电图记录和121 条异常心电图记录。在388条心电图记录中随机抽取95 条作为测试集,剩余293 条作为训练集。
现有2 种心电图数据输入:一种是利用https://physionet.org/cgi-bin/atm/ATM 网页中提供的功能将.dat、.hea 和.wav 文件转换为心电图(如图1 所示)作为输入;另一种是直接用wfdb 库中的rdsamp 函数读取.dat 文件得到心电图的幅值数据。本实验选择读取.dat 文件作为输入的原因包括以下几点:(1)输入数据维度约是心电图数据维度的1/18;(2)不需要进行预处理;(3)模型训练时间较短。

图1 原始心电图图像
1.2 CNN 结构
CNN 实质上是“端到端”的训练模式。其训练模型的超参数通过梯度下降方法不断完善,将原始数据逐层抽象为可以学习的最终特征[10],并以特征到任务目标的映射作为结束。由于CNN 省去了图像的前期预处理过程,可以直接把原始图像作为输入进行CNN 模型训练[11],在图像识别、语音识别等领域得到了广泛的应用。典型CNN 的基本结构包括输入层、卷积层、池化层、全连接层和输出层[12]。在本文的心电图正、异常分类识别过程中采用11 层网络结构,包括4 层卷积层、4 层池化层和3 层全连接层。

图2 CNN 结构图
如图2 所示,输入数据为2 000×1 的像素点构成的矩阵,第一个特征图层(卷积层C1)包含32 个特征图,采用5×1 的窗口对输入图像进行卷积,得到每个特征图的大小为2 000×1。然后第一个池化层(S2)则针对C1 进行降采样操作,选用最大池化方式同样得到32 个特征图,但特征图的大小减小到666×1。C3 层是一个卷积层,卷积核大小为3×1,得到每个特征图的大小为666×1。池化层S4 则在C3 的基础上进行降采样,选用最大池化方式得到64 个特征图,但特征图的大小减小到333×1。卷积层C5 的核函数大小为3×1,得到每个特征图的大小为333×1。池化层S6 在C5 的基础上进行降采样,选用最大池化方式得到128 个特征图,但特征图的大小减小到166×1。卷积层C7 的核函数大小为3×1,得到每个特征图的大小为166×1。池化层S8 在C7 的基础上进行降采样,选用最大池化方式得到128 个特征图,但特征图的大小减小到83×1,结束特征抽取的过程。随后在池化层S8 的基础上,通过一个全连接层F9,得到1×1 024 的输出结果。然后经过全连接层F10 得到1×512 的结果,最后通过全连接层F11 输出一个1×2的结果。在输出结果的1×2 的向量中最大概率对应的分类就是CNN 的分类结果。
1.3 CNN 超参数
在基础神经网络架构完成之后,提高模型准确率成为下一步工作。调整CNN 的超参数可有效提高模型准确率[13]。CNN 的主要超参数包括批尺寸(batchsize)、正则化参数(l2_regularizer)、学习率(learningrate)、丢弃值(dropout)、训练步数(epoch)[14]。
(1)batchsize 决定了训练一次模型所提供的样本数量。若训练样本量不大,建议每次训练都使用全部训练样本,以提高训练的准确率。
正则化项能够控制模型的过拟合问题,增加L2正则化只是对损失函数增加了系数惩罚(所有系数的二次方值的和)。原损失函数为
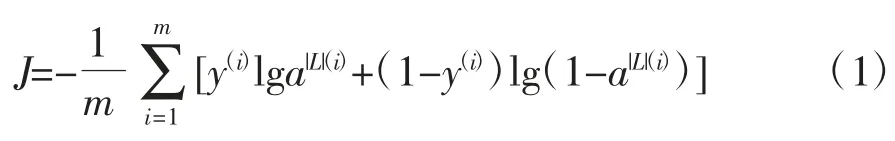
L2 正则化损失函数为

式中,m 表示数据集的数量;y 表示真实标记的分布;y(i)表示第i 个真实标记的正常或异常;a|L|为训练后的模型的预测标记分布;a|L|(i)表示第i 个预测结果的正常或异常;λ为正则化参数为L2正则化项。
(2)learningrate 控制着基于损失梯度调整神经网络权值的速度。learningrate 太大会导致找不到准确的极值点[15];learningrate 太小会导致收敛时间过长。
(3)dropout 的主要作用是防止过拟合。与L2 正则化类似,dropout 会压缩权重,防止过拟合;不同之处在于L2 正则化对不同权重衰减取决于倍增的激活函数的大小。
(4)epoch 代表所有训练样本进行训练的次数,即1 次epoch 意味着所有的训练样本完成一次前向传播(forward propagation,FP)运算以及一次反向传播(back propagation,BP)运算。
2 结果
2.1 数据预处理及扩充
减少输入数据量可以有效地加快模型的运行效率。原始心电图数据的采样频率为2 000 Hz,经测试采样频率为400 Hz 时可以满足识别的要求,故本实验中将采样频率由2 000 Hz 降到400 Hz,这意味着原输入数据维度(心电图时长为35 s)由35×2 000 降为了35×400,将大大减少模型训练时间。
实现CNN 的高准确率需要大量训练数据。由于本研究选取的心电图数据较少,所以采用随机选择起点以5 s 为间隔生成训练集样本以增加训练集中的样本数量,即每次训练的数据都会不一样。
2.2 CNN 的最优超参数
实验中对batchsize、l2_regularizer、learningrate、dropout、epoch 5 个超参数在一定数值范围内的分类效果进行了对比,从而选出最优的超参数组合。
2.2.1 batchsize
在除batchsize 以外的4 个参数设置相同时,将batchsize 的范围设定为60~130 中以10 为间隔的正整数。图3 为在其他参数设置相同的情况下batchsize 值与分类指标准确率的关系图。

图3 batchsize 值与分类指标准确率关系图
由图3 可知,batchsize 为100、110 和120 时分类准确率最高,考虑到batchsize 越小训练时间越短,故batchsize 的最优参数为100。此时分类准确率、灵敏度、F1 值(整体指标)分别为83.61%、84.1%、83.79%。
2.2.2 l2_regularizer
l2_regularizer 的范围设定为[0.01,0.05,0.001,0.005,0.000 1,0.000 5]。图4 为在batchsize 为100 且其他参数设置相同的情况下l2_regularizer 与分类指标准确率的关系图。
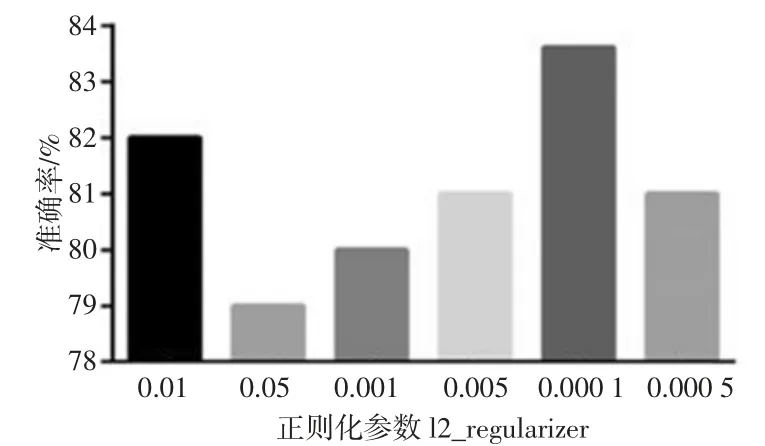
图4 l2_regularizer 值与分类指标准确率关系图
由图4 可知,l2_regularizer 为0.000 1 时分类准确率最高,其准确率、灵敏度、F1 值分别为83.61%、83.95%、83.86%。故l2_regularizer 选择0.000 1 作为最优参数。
2.2.3 learningrate
learningrate 的范围设定为[0.000 125,0.000 75,0.000 5,0.001,0.001 5,0.002]。图5 为在batchsize 为100、l2_regularizer 为0.000 1 且其他参数设置相同的情况下learningrate 值与分类指标准确率的关系图。

图5 learningrate 值与分类指标准确率关系图
由图5 可知,learningrate 为0.000 75、0.001 和0.001 5 时分类准确率最高,为了便于计算learningrate选择0.001 作为最优参数。此时分类准确率、灵敏度、F1 值分别为83.61%、83.96%、84.05%。
2.2.4 dropout
在batchsize 为100、l2_regularizer 为0.000 1、learningrate 为0.001 且其他参数设置相同的情况下,dropout 值与分类指标准确率的关系如图6 所示,其中dropout 的取值范围为[0,0.2,0.4,0.5,0.6,0.7]。
由图6 可知,dropout 为0.5 时分类准确率最高,其准确率、灵敏度、F1 值分别为83.61%、83.96%、84.05%。故dropout 选择0.5 作为最优参数,即保留一半神经元。

图6 dropout 与分类指标准确率关系图
2.2.5 epoch
在batchsize为100、l2_regularizer 为0.000 1、learningrate 为0.001、dropout 为0.5 且其他参数设置相同的情况下epoch 值与分类指标准确率的关系如图7 所示,其中epoch 的取值范围为[5 000,10 000,20 000,40 000,50 000,60 000]。
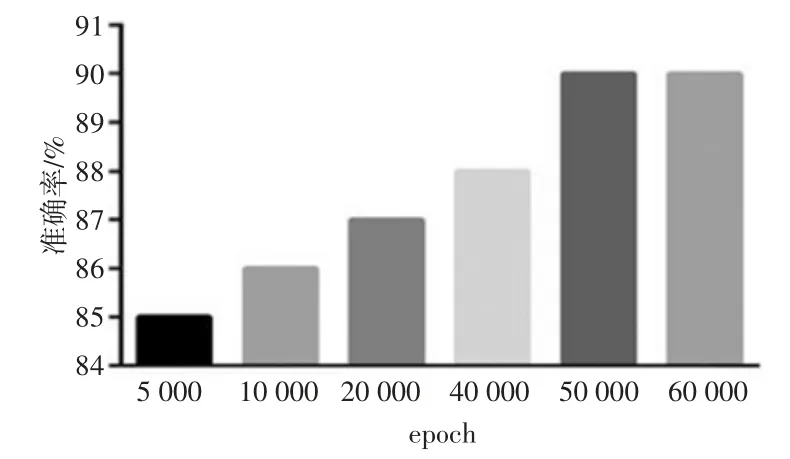
图7 不同epoch 的效果对比图
由图7 可知,epoch 为50 000 和60 000 时达到了最高准确率,考虑到epoch 越小训练时间越短,故epoch 选择50 000 作为最优参数。此时分类准确率、灵敏度、F1 值分别为90.0%、89.7%、90.4%。
未优化超参数时分类准确率可达到72%,在对batchsize、l2_regularizer、learningrate、dropout、epoch 这5个超参数进行参数调优后,分类准确率、灵敏度、F1值均得到了很大提高,其中准确率可达到90%,比优化前提高了25%。实验结果证明:当batchsize、l2_regularizer、learningrate、dropout、epoch 分别为100、0.0001、0.001、0.5、50 000 时分类准确率最高,达到90%。
3 讨论
近几年,智能辅助诊断在图像分类领域取得了很好的成就。在实际训练时,为了提高模型的鲁棒性和泛化能力,本研究所收集的数据来源于PhysioNet数据库的公开数据集,并从中剔除了脏信号。在心电图分类诊断过程中对比了原始心电图文件和.dat 文件后,发现.dat 文件具有数据维度小、无需预处理、训练时间短的优势。针对数据量小的问题,提出了随机选择起点以5 s 为间隔生成训练集样本以增加训练集数量的解决方案。在基础模型上优化超参数,以此找到一个准确率最高的CNN 模型。
本文利用CNN 对心电图进行分类诊断,从而实现了心电图正、异常的自动分类。通过对CNN 模型超参数的对比结果可看出,batchsize、l2_regularizer、learningrate、dropout、epoch 并不是数值越大分类效果越好,数值太大可能会导致过拟合或训练时间过长等问题。尽管本文的初步研究取得了良好的心电图分类效果,但PhysioNet 数据库的心电图数据大多来源于国外医院,且不同品牌心电图机和不同环境下采集的心电图信号可能会夹杂一定的干扰信息,应进一步进行广泛的研究和测试。
4 结论
本研究基于CNN 对心电图信号进行下采样及扩充数据集,输入CNN 进行训练,训练后的模型用于验证分类效果,并通过对比模型的超参数将分类准确率提高至90%,结果证明了该方法具有潜在的临床应用价值。
