基于LSTM 和TF-IDF 的反弹Shell 检测方法*
2020-12-23张宇涵吴毅良
张宇涵,薛 质,施 勇,吴毅良
(1.上海交通大学,上海 200240;2.广东电网公司江门供电局,广东 江门 529099)
0 引言
高级持续性威胁(Advanced Persistent Threat APT)已成为网络空间所面临的主要安全威胁之一[1]。随着网络安全形势日趋严峻,越来越多的商业组织和政府机构成为APT 攻击的目标,虽然这些被攻击目标通常都已安装防御和检测系统,用于提升安全防护能力,但依然遭受APT 攻击的持续威胁,部分攻击可能持续数月未被发现[2]。恶意命令是一种常见的APT 攻击方式,而反弹Shell 攻击则是一种典型的恶意命令攻击。反弹Shell 与SSH 等标准Shell 对应,本质上是网络概念中的客户端与服务端的角色互换。在通常概念的网络攻击中,攻击者会通过端口扫描找到目标机器的漏洞端口,从自己的机器向目标机器发起连接,这种方式也被称为正向连接,形如远程桌面、SSH、Telnet 等都是正向连接。但是在一些特殊情况下,正向连接无法使用,比如目标机器在局域网内,攻击者无法直接连接;目标机器IP 动态改变,攻击者不能持续控制;由于防火墙限制,目标机器只能发送请求,不能接收请求等。在上述情况下,攻击者往往就会采用反弹Shell 来进行攻击。反弹Shell 是通过未检测到的恶意远程访问木马(Remote Access Trojan RAT)来进行攻击的[3]。攻击者首先设法利用漏洞将伪装过的木马脚本植入目标主机,使用户在执行命令的同时运行木马脚本,通过RAT 木马,被攻击者会发起请求连接到某个攻击者正在监听的TCP/UDP 端口,并将其命令行的所有输入输出转出到该端口,从而受到攻击者的远程控制。此外,由于使用反向外壳程序而不是绑定外壳程序将命令注入受害计算机中,使得反弹Shell 在网络和主机级别中具有比较好的隐蔽性。
1 相关工作
针对用户Shell 的恶意命令检测近年来一直是研究的热点。国内外已经开展了采用机器学习(贝叶斯模型,马尔可夫模型等)和深度学习(如卷积神经网络(Convolutional Neural Network,CNN)和递归神经网络(Recurrent Neural Network,RNN)等)技术在伪装攻击检测中的应用研究。L Huang[4]等人的研究在现有基于隐马尔可夫检测模型(HMM)的基础上提出了一种基于轮廓隐式马尔可夫模型(PHMM)的检测方法,针对HMM 中的隐藏状态进行检测。实验结果证明,当使用的训练数据有限时,最佳的检测策略是使用PHMM。而当积累了足够的训练数据后,使用HMM 会有更好的效果。Kim H S等人[5]研究了基于 SVM 支持向量机的方法来进行伪装恶意代码检测。J Seo[6]等人对Kim 的方法进行了改进,通过应用基于序列的信息检测来提高伪装检测系统的性能,并将SVM 和基于序列的内核方法结合起来,进一步降低了检测系统的误报率。Sai Charan[3]等人提出了一种通过分析从被攻击机器收集的大量安全信息和事件管理(Security Information and Event Management SIEM)系统事件日志文件,借助长短期记忆神经网络(Long Short Term Memory LSTM)实时检测恶意命令的技术。Bhatt[7]等人提出了一种使用具有逻辑层的Apache Hadoop 进行行为建模的检测框架,该框架以描述攻击方法以及攻击的预期效果的方式对多阶段攻击进行建模,并结合日志文件来提升识别攻击的准确性。
2 相关知识
2.1 TF-IDF 算法
TF-IDF(Term Frequency -Inverse Document Frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF 指的是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)[8]。TF-IDF 是一种基于统计的方法,用来评估一个词条对于一个文件集的其中一个文件的重要程度。词条的重要性随其在文件中出现过的次数成正比增加,但是会随着其在整个文件集中出现的频率成反比下降。
对于第j个词条在第i个文件中的TF 值tfi,j的计算方法如下:

式中ni,j是第j个词条在第i个文件中的出现次数,∑knk,j是第j个词条在其他所有文件中出现过的次数总和。
对于第i个文件中的第j个词条,它的IDF 值计算公式如下:
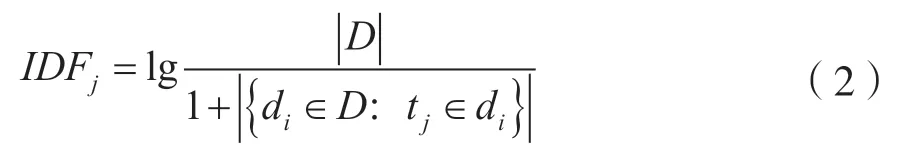
式中|D| 是在语料库中的文件总数,{di∈D:tj∈di}是包含词条tj的文件数目。
TF-IDF 是TF×IDF 的缩写,如果某个词条在特定文件内的词频率很高,并且该词条在整个文件集合中的出现频率很低,就可以使用该词条产生出高权重的TF-IDF。TF-IDF 会倾向于过滤掉常见词语而保留重要的词语。
TF-IDF 算法的结构较为简洁,容易实现,缺点是没有考虑词语的语义信息,无法处理一词多义与一义多词的情况,但是在处理Shell 命令特征的过程中有着不错的效果。
2.2 长短期记忆网络(LSTM)
长短期记忆网络(Long Short Term Memory LSTM)是从循环神经网络(Recurrent Neural Network,RNN)中发展出来的。RNN 是一种用于处理序列数据的神经网络。相比一般的神经网络来说,RNN能够结合上一时态的输出和当前时态的输入进行学习,从而能够处理序列变化的数据。而LSTM 网络是一种改进后的RNN 网络,主要用于处理长时序序列训练过程中的梯度消失和梯度爆炸等问题。LSTM 有着与RNN 相同的重复模块链的结构[9],但与RNN 相比,LSTM 在单个模块结构的内部做了一些变化,其网络结构如图1、图2 所示。
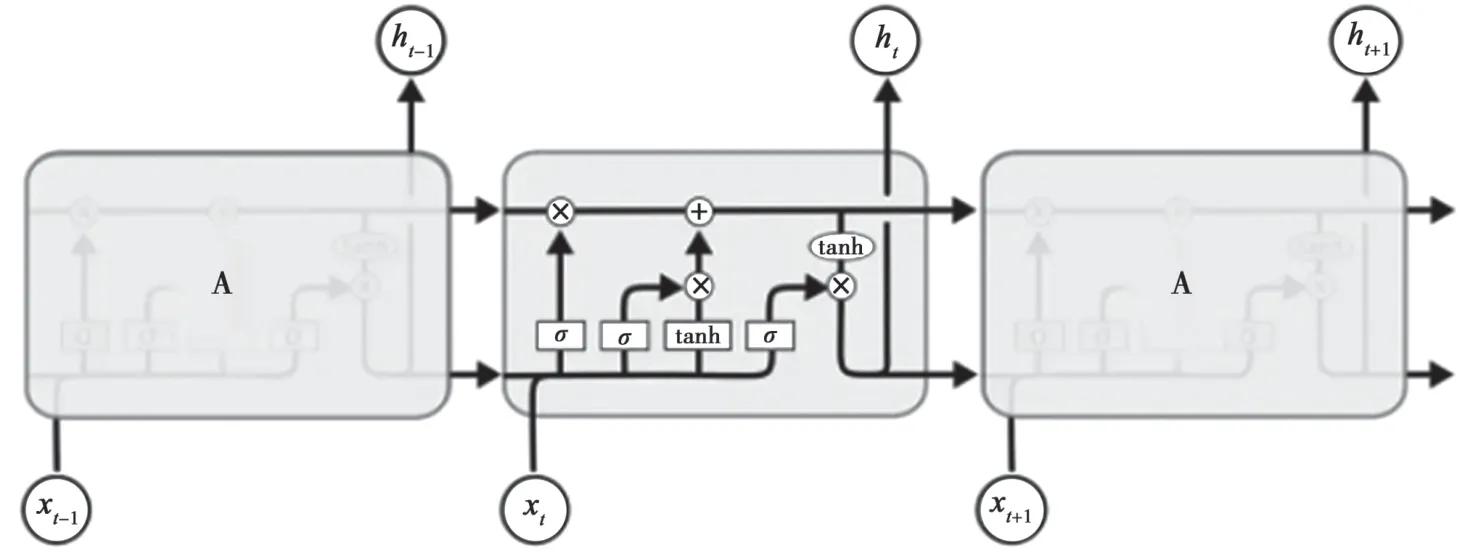
图1 LSTM 链式结构
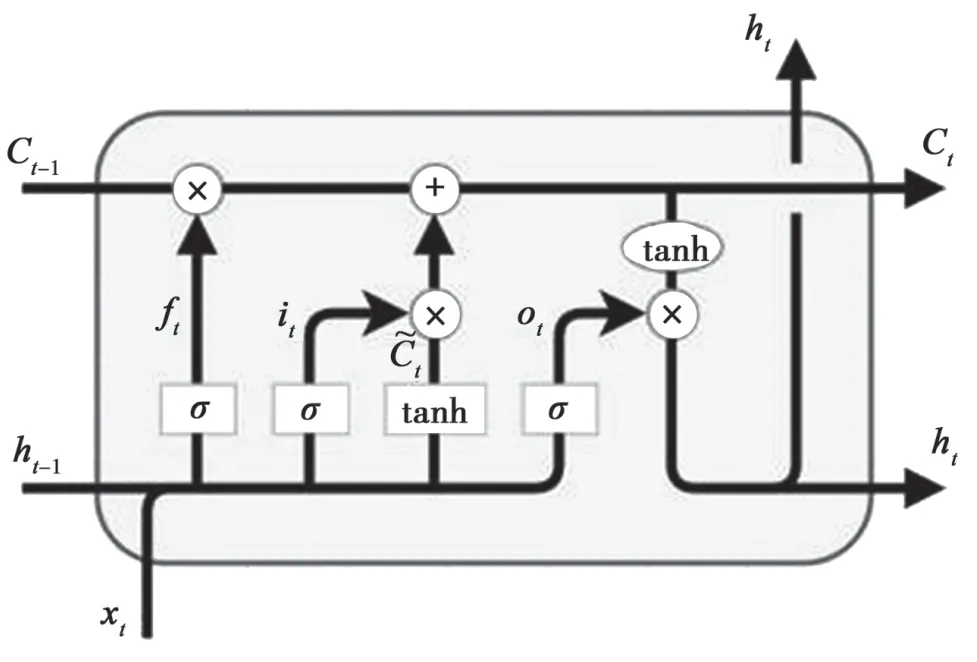
图2 LSTM 细胞结构
LSTM 网络通过遗忘门、输入门和输出门来控制细胞的状态变化。在每轮迭代中,首先将上一轮的输出ht-1和本轮输入xt经过遗忘门来决定要舍弃的信息。公式为:

第二步是通过输入门来决定要更新的信息,输入门中有一个包含激活函数的层,将ht-1和xt通过该层最终得到新的候选细胞信息
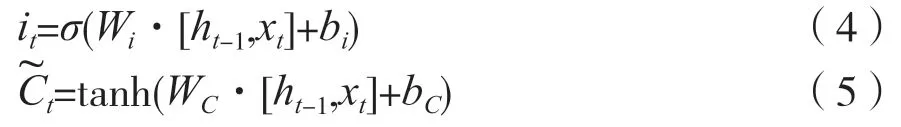
然后将遗忘门和输入门的信息汇总,更新旧细胞信息Ct-1,并通过得到新的细胞信息Ct。

最后将ht-1和xt通过输出门的激活函数层得到判断条件,从而决定本轮输出的细胞状态特征。


LSTM 的结构设计特点使得它在学习更高级别特征序列中的长程依赖性和时序性有着很大的优势,可以在前后文之间更好地捕捉语义依赖,提高检测准确率。
3 TF-IDF 和LSTM 实现反弹Shell 检测
3.1 SEA 数据集
由于目前尚未有组织或机构制作专门针对Shell命令的数据集,因此本实验采用由AT&T Shanon 实验室发布的SEA 实验数据[10]作为基础数据集,并在此基础上加以修改作为实验用数据集。SEA 数据集包含了70 个用户的命令日志,对每个用户采集了15000 条命令。本实验从中随机选出50 个用户,将每个用户的数据按照连续50 个指令一组,划分为1300 个块,作为本实验的基础数据集,并以此为基础进行后续的特征提取和训练过程。
3.2 特征提取和数据处理
由于SEA 数据集中的命令仅由Shell 命令短语组成,不包含其他参数,因此本实验选择使用TFIDF 算法结合SEA 数据集对收集到的反弹Shell 样本进行分词并提取特征,提高检测的准确率。
将反弹Shell 样本和部分SEA 数据集命令输入TF-IDF 算法中,提取出的部分特征短语如图3 所示。

图3 TF-IDF 特征提取
本实验将原始SEA 数据集中的数据块视为正常数据,然后从中随机抽取一部分数据块,将其中的部分命令替换为反弹Shell中提取的特征命令记录。本实验将这些被修改过的数据块视为异常数据。正常数据和异常数据的格式如图4 所示。其中标签设为1 的是插入了特征命令记录的异常数据块,标签设为0 的是未经修改的正常数据块。

图4 数据集格式
3.3 实验结果与分析
本研究在SEA 实验数据集的基础上进行了一定改动,并以此为新数据及进行实验。网络架构基于LSTM 和TF-IDF 特征提取。本实验随机选取了200个不参与训练的数据块作为测试集检测训练效果,并使用相同的神经网络和参数另外训练了一个未经TF-IDF 特征提取的检测模型作为对比。通过不断调整参数训练网络,实验结果如表1 所示,对比结果如表2 所示。

表1 实验结果

表2 未经TF-IDF 特征提取的实验结果
本次实验共使用了200 个数据块作为测试数据,其中正常数据块128 个,异常数据块72 个。通过表1 和表2 对比可以看到,该模型准确率超过了98%,误报率在2%以下。与未经特征提取的模型相比有了较大的提升,展现出了较为出色的预测能力。可见,在是否存在反弹Shell 的二分类问题中,本文所设计的基于TF-IDF 和LSTM 的反弹Shell 检测方法展现出了较好的检测能力。
4 结语
本文设计了一种基于TF-IDF 和LSTM 的针对隐蔽性较高的反弹Shell 检测方法。LSTM 的结构设计特点使得它较为适合处理时间离散序列数据,并能够解决序列中的长程依赖性,可以在前后文之间更好地捕捉语义依赖。结合TF-IDF 对样本进行特征提取,得到了更高质量的特征向量信息,在针对反弹Shell 生成的基于SEA 数据集的训练数据集中得到了较高的准确率和较低的误报率,展现出较高的综合检测能力,与未经特征提取的检测结果相比有了较大的提升。下一步的研究目标在于逐步将模型由有监督训练向无监督训练转化,从而将监测范围拓宽到更多的攻击场景,这对模型的构建提出了更高的要求。
