人民币汇率的混频分析与预测
——基于半参数误差修正模型
2020-12-22鲁万波陈映彤
鲁万波,陈映彤
(1.西南财经大学 a.统计学院,b.经济与管理研究院,四川 成都 611130;2.西藏大学 a.珠峰研究院,b.财经学院,西藏 拉萨 850000)
一、引 言
汇率作为国与国之间货币兑换的重要指标,随着经济全球化趋势不断加强,汇率影响着国民经济的各个领域。自2018年以来,中美贸易纠纷作为中国经济中的新增不确定项,为人民币汇率的发展蒙上阴影。从2018年6月15日美方宣布对价值500亿美元的中国商品加征25%的关税开始,中美双方在近两年的时间内不断博弈,使得汇率市场的起伏牵动着中国经济发展的预期。在此背景下,如何破解贸易困境,化解需求困局成为中国经济学者关注的重点话题。中国只有自身稳定信心,深化改革扩大开放,提升经济发展的可持续性才能在这场持久的贸易摩擦中掌握更大主动权。汇率市场的稳定是当下稳定信心的重要抓手之一。目前,美元兑人民币汇率中间价已然破“7”,未来人民币汇率怎么走,是什么因素在主导汇率的走势,如何准确预测汇率走向而为市场提供有效信息从而采取必要的逆周期调节措施,稳定投资者情绪成为稳定人民币汇率的重要课题。
目前,人民币汇率波幅越来越大,影响汇率的因素亦随国际形势变动而愈加复杂。针对目前人民币汇率预测研究进展,本文从以下几个方面开展新的研究:
第一,基于混频数据应用的实际价值,采用高频金融数据与经济宏观指标相结合的方式,使用混频模型开展实证分析。在混合数据抽样(MIDAS)模型的基础上,首次使用半参数误差修正模型对美元兑人民币汇率中间价进行预测,使得汇率预测更精确。
第二,针对混频处理存在的方法问题,本文将非线性误差修正项引入存在协整关系的非平稳混频数据抽样模型,对混频数据进行直接处理,避免增加数据加总或插值导致的信息损失或处理误差,使得估计模型结果更加真实精准。
第三,研究数据选取自2008—2019年的数据,将2015年“811汇改”影响纳入研究模型,时间段涵盖国家政策调整部分,能够对汇率模型的变量选取提供一定的参考意义,对人民币汇率在中美贸易战期间的表现提供更多解释因素。
二、文献综述
(一)人民币汇率的影响因素分析
郭莹莹从长短期两个角度分别构建马尔科夫区制转换模型,表明中国净资本流入、国外通货膨胀和国际原油价格变动等因素对中国实际汇率影响相对较弱,而贸易条件、货币供给和外汇储备对中国实际汇率的影响最显著[1]。邓贵川等使用2005年汇改后的美元兑人民币、欧元、日元、英镑汇率数据,研究名义汇率、物价水平、名义利率、货币供应量、产出、产出缺口、通货膨胀、政府债务、贸易条件、贸易品与非贸易品价格比值、净国外资产等对人民币汇率的影响,结果发现宏观基本面数据在中长期预测效果更佳[2]。黄宪等使用指数自回归条件异方差(EGARCH)模型,引入货币政策虚拟变量,分析了货币政策对人民币汇率的影响及其程度[3]。周建等利用向量自回归(VAR)模型与马尔科夫区制转换方法对中国汇率市场化的内生传导机制进行研究,发现汇率波动的一个原因是自身冲击,其影响随时间递减[4]。易靖韬等在分析特朗普新政对人民币汇率影响时,从购买力和利率等传统的汇率决定理论角度出发,实证发现影响汇率变动的主要经济因素包括国际收支、通货膨胀和国内外利差状况[5]。
(二)美元兑人民币汇率的预测方法
第一,构建各类单频时间序列模型用以预测汇率变动。该类方法的发展已相对成熟,主要包括自回归移动平均(ARMA)模型、指数平滑技术、广义自回归条件异方差(GARCH)模型等。吴诣民等利用人民币兑欧元周数据,构建马尔科夫链模型分析人民币汇率波动性质并预测未来趋势[6]。而国外学者在利用货币模型对汇率进行研究时,发现模型预测结果相较随机游走更佳,进而表明模型预测可获得更好的预期效果;例如Yin等选取经济基本面变量建立无套利宏观金融模型,发现使用该模型可以解释57%的汇率预期变动[7]。在验证GARCH模型可用于汇率预测领域后,国内多位学者曾使用滚动与递归两种数据样本得到较好的预测结果。之后,非参数方法的提出与应用使得模型预测稳健性增强,汇率预测结果的精度得到有效改善。非参数方法因未对数据分布提前做出假设,进而避免了设定偏误对预测结果的干扰。在2015年“811汇改”后,张见对自2005年来几次汇率市场中间报价改革进行断点检验,并使用阶段自回归模型探究人民币汇率的调整机制[8]。随着计算机理论的应用与发展,混合人工神经网络模型也开始应用于统计预测领域,在与传统的时间序列模型结果进行了对比后发现混合人工神经网络强预测模型的预测能力显著优于传统模型。
第二,将隐含波动率相关理论应用于汇率领域。该类方法在股市预测中应用广泛,但在汇率预测领域,由于中国外汇期权推出时间较晚,国内这一方向的研究文献较少。王琦等基于美元兑人民币汇率与人民币对外期权市场价格,构建随机波动率模型,对人民币汇率的稳态分布与均衡波动率曲面进行有效衡量[9];另有研究利用汇率数据,采用滚动预测与SPA检验,对汇率隐含波动率的预测能力进行评估,发现其效果更优。
但上述对人民币汇率的影响机制的研究方向均围绕同频数据展开,并未完全发挥不同频率数据的应用价值,也局限了预测效果的实际应用价值。第一类模型虽然较为成熟,但是在经济意义解释中始终存在一系列问题,特别是在汇率超出基本面波动时,模型结果存在较大偏差。第二类模型虽然考虑了汇率自身与外界因素变化,但在经济学解释中仍存在问题,且模型指标选取存在局限性,没有考虑综合宏观经济与金融市场的各类指标对汇率的影响。
综上,有关人民币汇率预测问题的研究存在以下几个方面的特点:
第一,国内对人民币汇率的研究集中于同频数据间线性与非线性的相互影响,虽然预测精度逐步提高,但是随着中国金融市场的逐步开放,考虑高、低频宏观变量间的相互作用比仅考虑同频变量间的关系更具有现实价值。
第二,汇率预测所用变量通常频度不一。总结以往文献研究特点,研究者们对金融高频数据与经济低频数据用于统一模型的方式一般分为两种,一是大多采用将高频数据转化为低频数据的做法,这类方法会丢失高频数据中蕴含的有效信息,可能使大量重要数据缺失而无法保证预测的准确性;二是将低频数据转化为高频数据而采用的插值法,这类做法虽然可以得到良好的统计特性,但因人为虚增变量导致经济意义的解释存在问题。
第三,对于当下中美贸易战的情势,目前大多数文献没有利用实际数据进行实证研究,大多停留在理论分析部分,存在较大的局限性,无法为投资者提供更多有效信息。
针对上述问题,本文考虑使用混频模型对美元兑人民币月度名义汇率进行预测研究。将误差修正项以非参数形式加入半参数误差修正(SEMI-ECM)模型,分析主要经济指标与金融混频数据对汇率的影响,并与传统模型结果进行比较。
三、研究方法
为了充分利用数据,减少数据频率不一而带来的研究局限性,国外学者提出了混合数据抽样模型。Ghysels等参照分布滞后模型思想构造出混合数据抽样(MIDAS,Mixed Data Sampling)模型[10]。该类模型能够改善分布滞后模型在利用数据样本中的劣势,可直接应用不同频率的数据于实际问题研究。因此,本文使用MIDAS模型方法,结合半参数误差修正模型思想对人民币汇率月度数据进行预测。
在原始混频自回归分布滞后(MF-ADL)模型满足稳定条件的基础上,即在其对应的差分方程所得到的特征根均小于1的情况下,该模型可表示为MF-ADL(pl,qu,ql),具体形式如下:
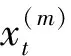
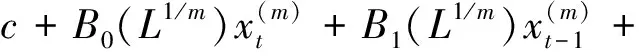
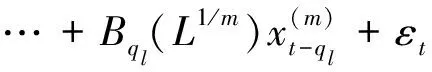
(2)
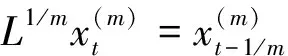
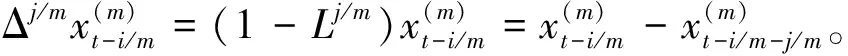
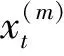
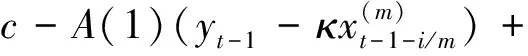
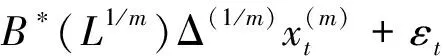
(4)
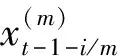
SEMI-ECM模型与MIDAS模型结合,相对于ECM-MIDAS模型的一个优势就是允许误差修正项以非参数形式进入式(4),且无需对非线性部分进行参数设定,从而避免预测精度下降的问题。
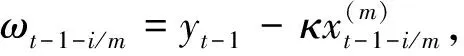
其中,g(·)为待估函数,式(6)为式(4)的一般形式。但在模型构建中面临的另一问题是,解释变量的非参部分ωt-1-i/m难以观测。鲁万波等为解决该类问题,使用两阶段最小二乘法结合前人理论对式(6)的估计给出了具体估计流程,获得了基于半参数估计的被解释变量预测值[13],具体表达式如下:
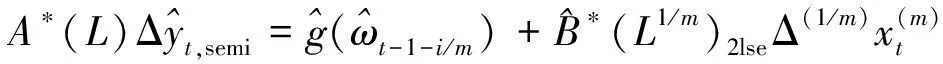
(7)
四、实证检验及分析
(一)变量选择
本文使用在岸美元兑人民币名义汇率月度数据(USD_CNY)作为原始被解释变量。
已有文献已发现:通货膨胀、广义货币供应量(M2)、贸易条件(TOT)、贸易开放度、美联储基准利率、非贸易品与贸易品价格比等变量对汇率变动有显著影响。考虑经济学和统计学意义,在消除共线性并剔除非显著变量后,本文将以下三个宏观经济变量作为预测汇率的主要变量:贸易条件(TOT)、非贸易品与贸易品的相对价格比(CPI/PPI)、美联储基准利率(FFR)。
贸易条件(TOT):贸易条件主要反映一个国家的贸易状况与贸易优势,通过计算进出口价格指数之比来衡量一国国际竞争力来源。中国并未发布出口与进口指数相关官方数据,于是我们通过构造中国一定时期出口与进口总额的比值替代本变量。关于贸易条件与汇率二者间的关系研究至今未有定论,不同地区贸易条件对于对该地汇率的影响效应各异。国外研究曾利用多国数据构建三部门均衡模型,对贸易条件向好状态下汇率及利率上涨做出实证;而同时期国内研究发现,不同时期贸易条件对汇率的作用不可一概而论。早在1988年,Edwards曾利用一般均衡模型研究贸易条件对人民币汇率的影响机制,在对收入效应与替代效应两条路径进行研究后发现,当贸易条件改善时,收入效应大于替代效应,会促进汇率攀升;反之,汇率下降[14]。当前的中美贸易战会导致中国在全球的贸易环境恶化,此时替代效应大于收入效应则会导致人民币贬值,由此本文将贸易条件作为解释变量之一加入模型。由图1可以看出,汇率与贸易条件的走势大致呈正相关性,本文将利用模型给出进一步的实证分析结果。
非贸易品与贸易品的相对价格比(CPI/PPI):由于非贸易品与贸易品价格指数数据不可直接获取,本文查询相关学者文献后将CPI作为非贸易品价格指数,PPI作为贸易品价格指数,以反映非贸易品相对于贸易品生产部门生产增长率的变动情况。回顾往期研究主要结论,两部门间相对劳动生产率是相对价格比的主要决定因素,而且此相对价格比对实际汇率产生了明显的影响。当贸易联系越紧密、财政支出占GDP的比重越低、制造业比重越小,相对价格比对实际汇率的影响越大。由于B-S效应仅通过生产率解释实际汇率的变化,没有研究其对名义汇率的影响,所以本文将对生产率相对变动可否实时影响名义汇率进行研究。图2为汇率与非贸易品与贸易品相对价格比走势,大致可以看出与汇率呈正相关,具体关系将在文中进行验证。
美联储基金利率(FFR):随着中国货币与资本市场的进一步开放,中美两国间经济政策的溢出效应显著增强。美元作为世界货币,其对中国汇率市场的影响程度较深。美联储加息使得美元指数上升,加速国际游资对新型经济体资产的抛售并重新回流美国,加重人民币贬值负担。在基于SVAR模型的一项实证研究,对2008年后美国货币政策影响人民币汇率的方式进行探索,实证发现美联储基准利率对人民币汇率波动具有显著冲击,即美国货币政策会对人民币币值的稳定性产生影响。而另一项利用汇率数据,构建带有时变参数因子的VAR模型的研究,发现美国货币政策将对中国宏观经济、私人经济和金融市场产生不同程度的冲击。同样,基于VAR模型来研究新一轮美联储加息对中国跨境资本流动的溢出效应时,结果则表明中国跨境资本流动仍受美联储政策影响,但由于人民币“811”汇改的实施,其影响节奏较以往相对缓和,而对于人民币汇率的作用仍然存在。
同时,由于本文研究时间跨度包含2015年“811汇改”,本文加入汇改政策虚拟变量(POLICY),将2015年8月份之前虚拟变量值设为“0”,2015年8月份后虚拟变量设为“1”,引入模型观察“811汇改”对美元兑人民币汇率月度数据影响。
综上分析,TOT、CPI/PPI、FFR与人民币汇率有很强的相关性,本文将这些变量作为解释变量来预测汇率。
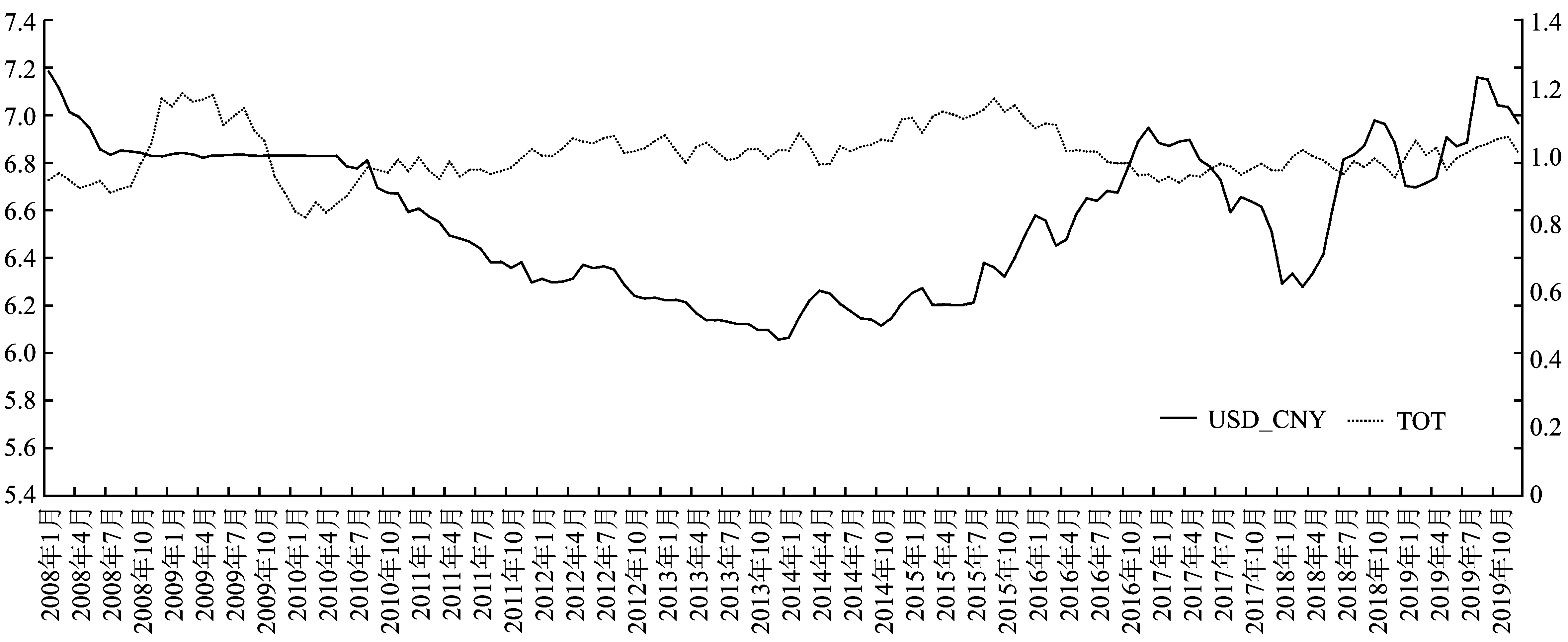
图1 汇率与贸易条件走势图
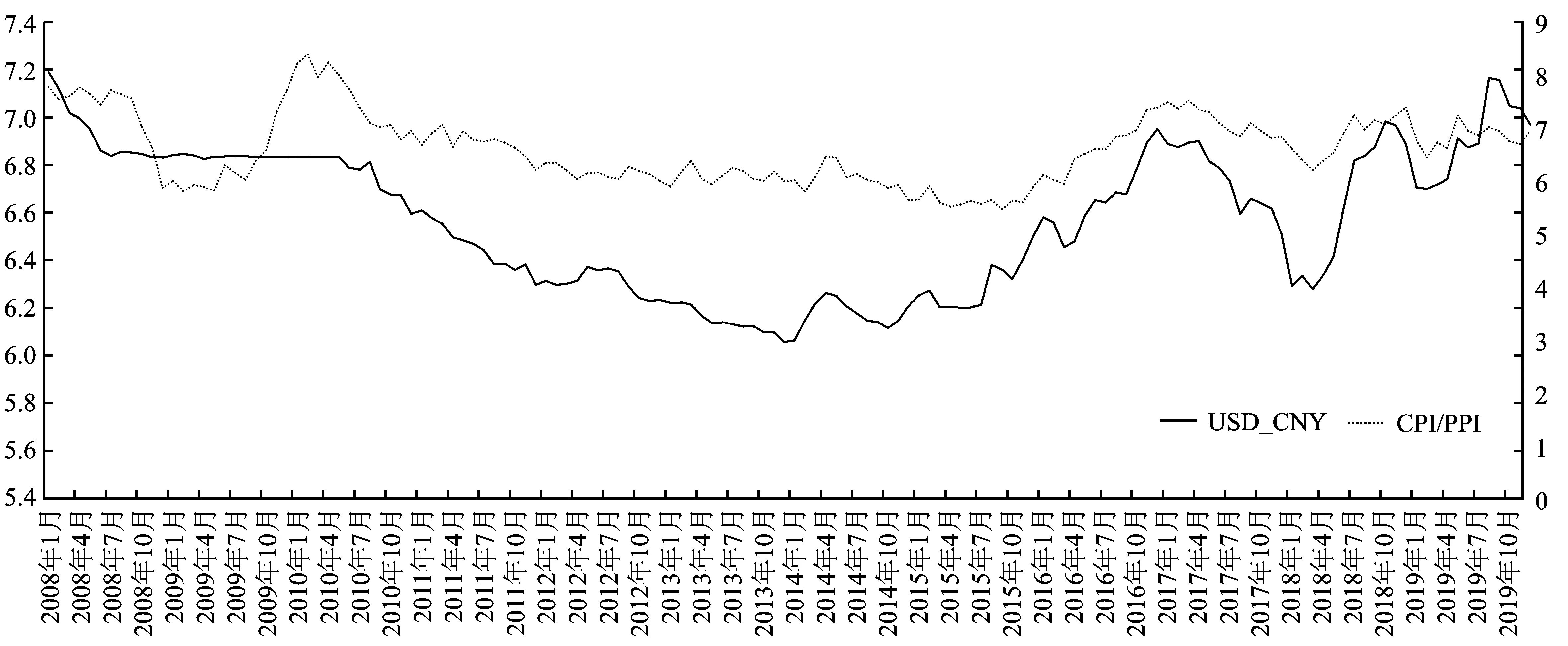
图2 汇率与非贸易品贸易品相对价格比走势图
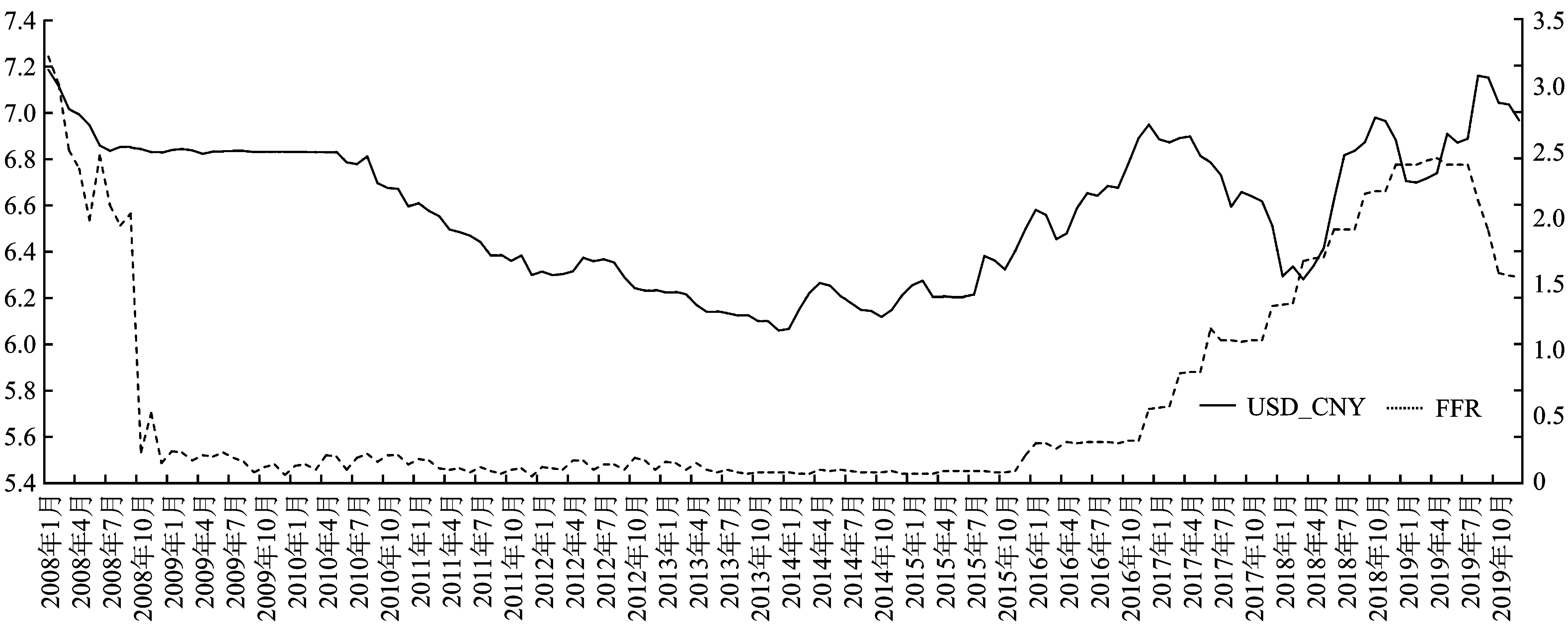
图3 汇率与美联储基准利率走势图
(二)数据来源
本文使用2008年1月至2019年12月间的数据,其中在岸美元兑人民币名义汇率月度数据来源为国家外汇管理局,中国出口与进口总额、中国CPI数据、中国PPI数据均来自国家统计局网站、美联储基准利率数据来自美国联邦储备局官方网站。
(三)描述性统计
首先,我们需要对汇率周原始数据和月度宏观经济数据间进行匹配,并采用规范化处理以避免模型计算时量纲造成的人为误差。样本区间内有576个周,但其中每月周汇率最多可有5条记录,最少的4条记录,且实际上每个月均只有4个交易周。考虑到MIDAS模型中频率倍差m不具有时变性质,本文初步使用2008年1月1日至2019年12月31日共计626个观测样本。经综合考虑,我们设定混频数据的倍差m=4,即每个月共四周,则共需576个数据即可。具体处理方法为:首先,将2008年1月1日至 2019年12月31日的626个周数据从月末开始往前依次保留共4个数据。对于研究中出现超过4周的月份,本文对该月第一周数据进行剔除处理。若由于节日等原因造成工作周数不足,则利用上月份相邻周数据予以补齐,保证每月数据量相同。最终共保留576个周数据。
由图4、5、6所示,TOT、CPI/PPI、FFR与人民币月度汇率均存在一定联系,变量之间波动变化趋势相似,而TOT和CPI/PPI对人民币月度汇率的领先或滞后关系在不同时期并不确定。具体来看,2015年汇改以前,TOT是人民币月度汇率的先行指标,而在2015年汇改后,TOT却是人民币月度汇率的领先指标,这在一定程度上说明中国在2015年汇改政策可能对汇率影响机制产生一定作用。对于CPI/PPI和人民币月度汇率的关系而言,CPI/PPI在绝大多数时间下均是人民币月度汇率的领先指标,仅在2012年时出现了人民币月度汇率的平缓增加并未导致CPI/PPI明显增加的情况。在2015年汇改后,人民币月度汇率与FFR间的联系愈加密切。且通过图1~3可以看出,TOT和CPI/PPI与人民币月度汇率呈正相关,而FFR相对于人民币月度汇率呈负相关。通过以上初步分析,可以发现TOT、CPI/PPI和FFR在大部分时期对于人民币月度汇率来说具有明显的先行指标特征,这也进一步证明其作为解释变量用来预测人民币月度汇率走势的合理性。
表1为文中各变量的描述性统计结果,其中均值和中位数结合可提供数据分布中心的大致位置,标准差用于表示数据离散值对中心的偏离程度,偏度和峰度则用于分辨数据偏离正态的分布状况。
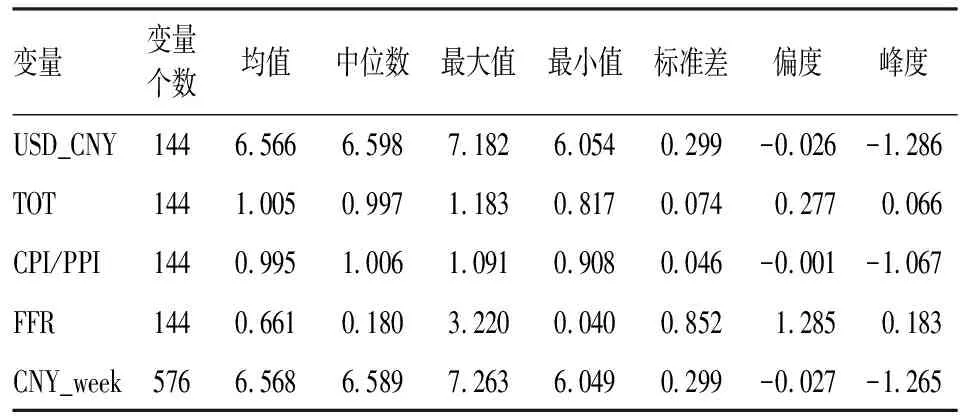
表1 描述性统计
观察USD_CNY的统计量,左偏扁平分布,均值和中位数在6.5附近,标准差0.29,最大值7.182,最小值6.054,说明人民币月度汇率集中在7.1和6.0之间,波动幅度较大。
观察TOT的统计量,右偏扁平分布,均值和中位数相近,集中在1.0附近,标准差0.074,最大值1.183,最小值0.817,显示出中国贸易条件存在较大幅度的变动。
FFR为美国同业拆借市场利率。美联储作为美国的中央银行,通过调节联邦基金利率对商业银行的资金成本产生直接作用,借此将美联储的市场判断与金融政策通过资金余缺信息传递给工商企业,进而对美国乃至世界经济起到“牵一发而动全身”的效果。联邦基金利率和再贴现率的调节都是由美联储宣布的,不具有随机性,其数值根据美国经济状况决定,可体现美方政府对经济调整的态度。其最大值与最小值相差极大,美联储通过不断加息与调整影响美国乃至全球经济。
考虑到原始数据由于量纲不同且某些变量具有季节效应而难以比较,本文将各数据进行标准化处理并取对数值后去除季节效应再次观察。此时,可以清楚地看到TOT是人民币月度汇率的先行变量,CPI/PPI在2015年汇改后相对于人民币月度汇率仍具有一定的先行性,FFR的波动始终在确定范围内,与人民币汇率的相互作用有待进一步分析。
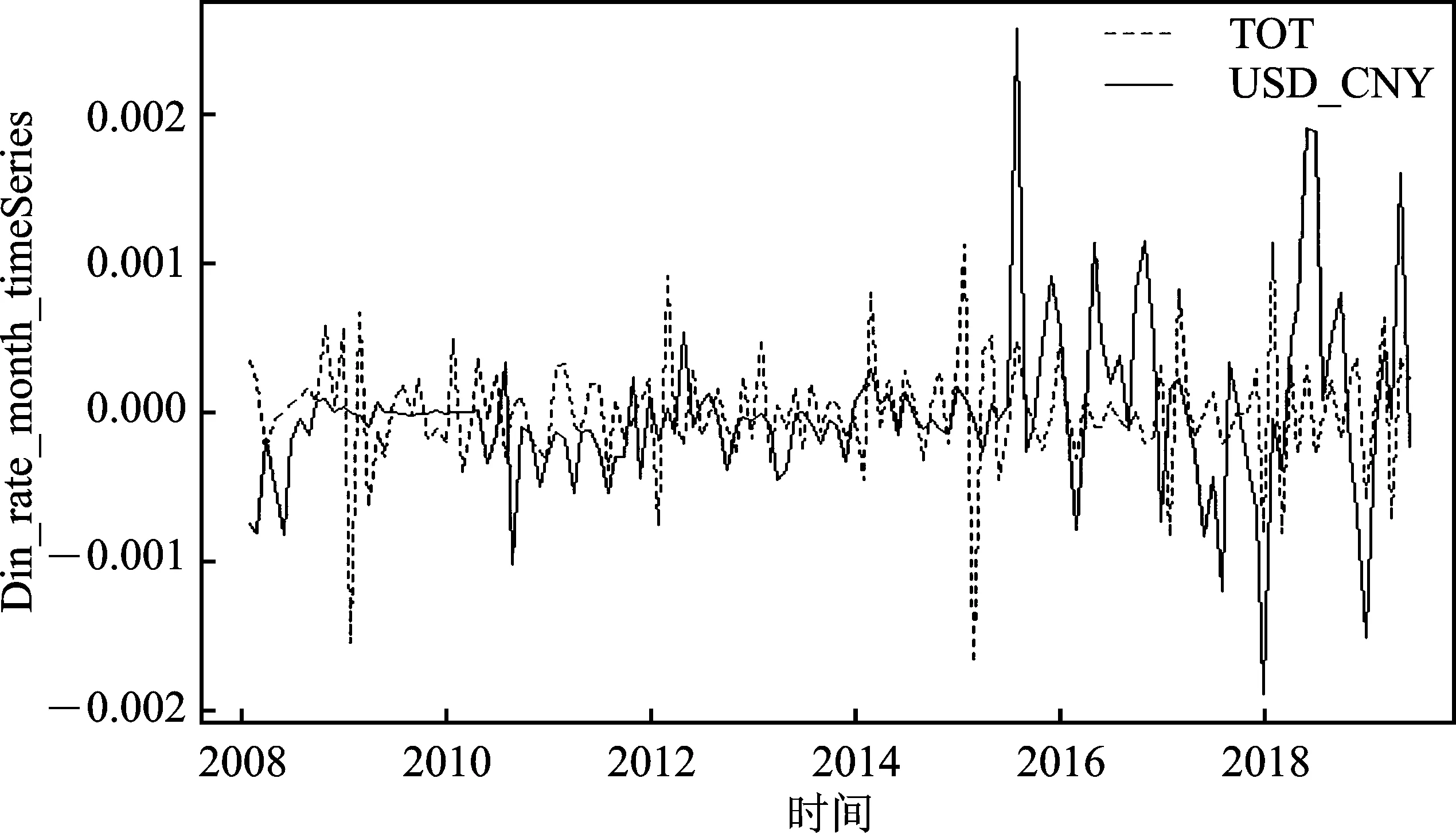
图4 去除季节效应后汇率与贸易条件趋势图
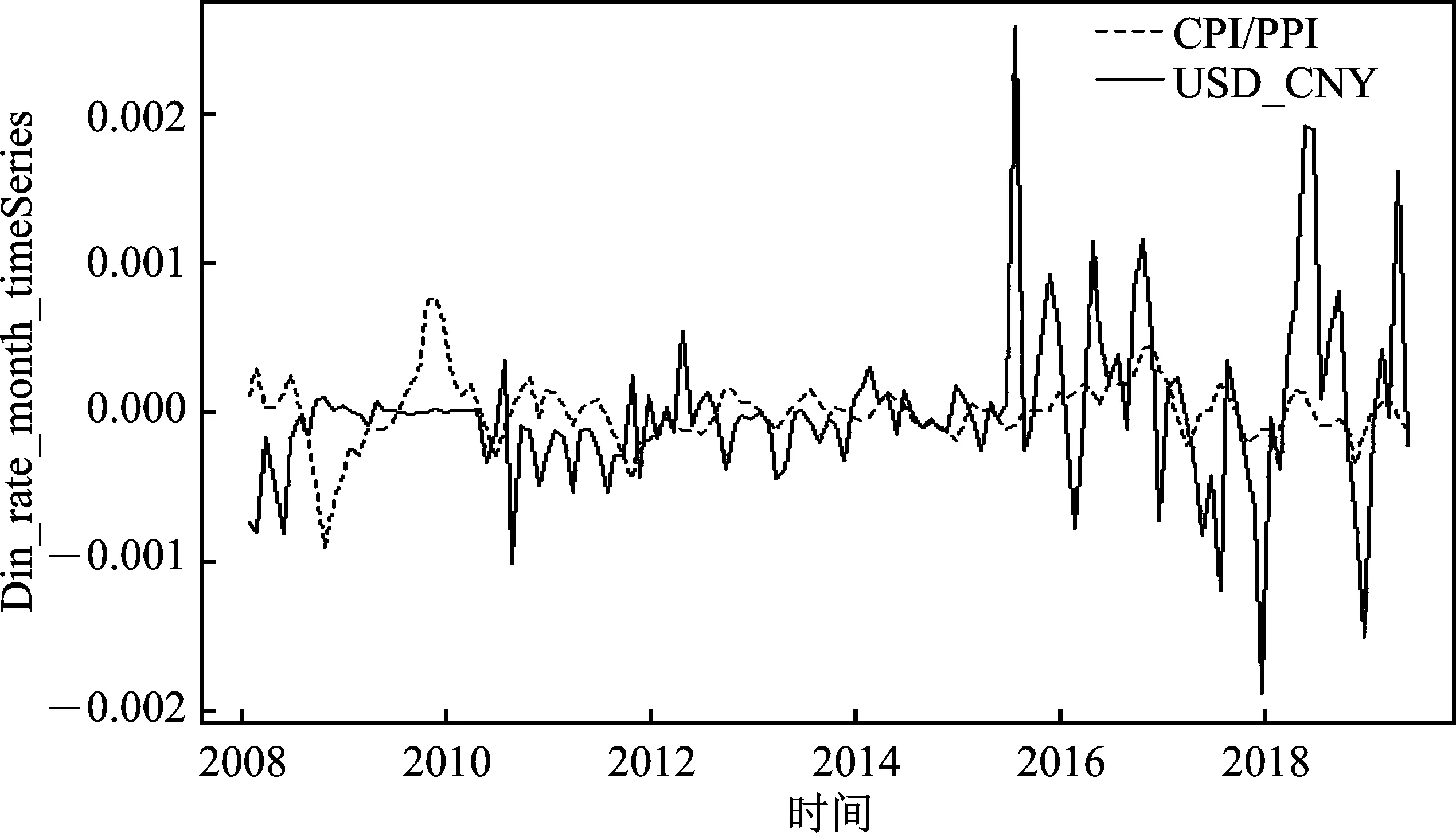
图5 去除季节效应后汇率与非贸易品与贸易品的相对价格比趋势图
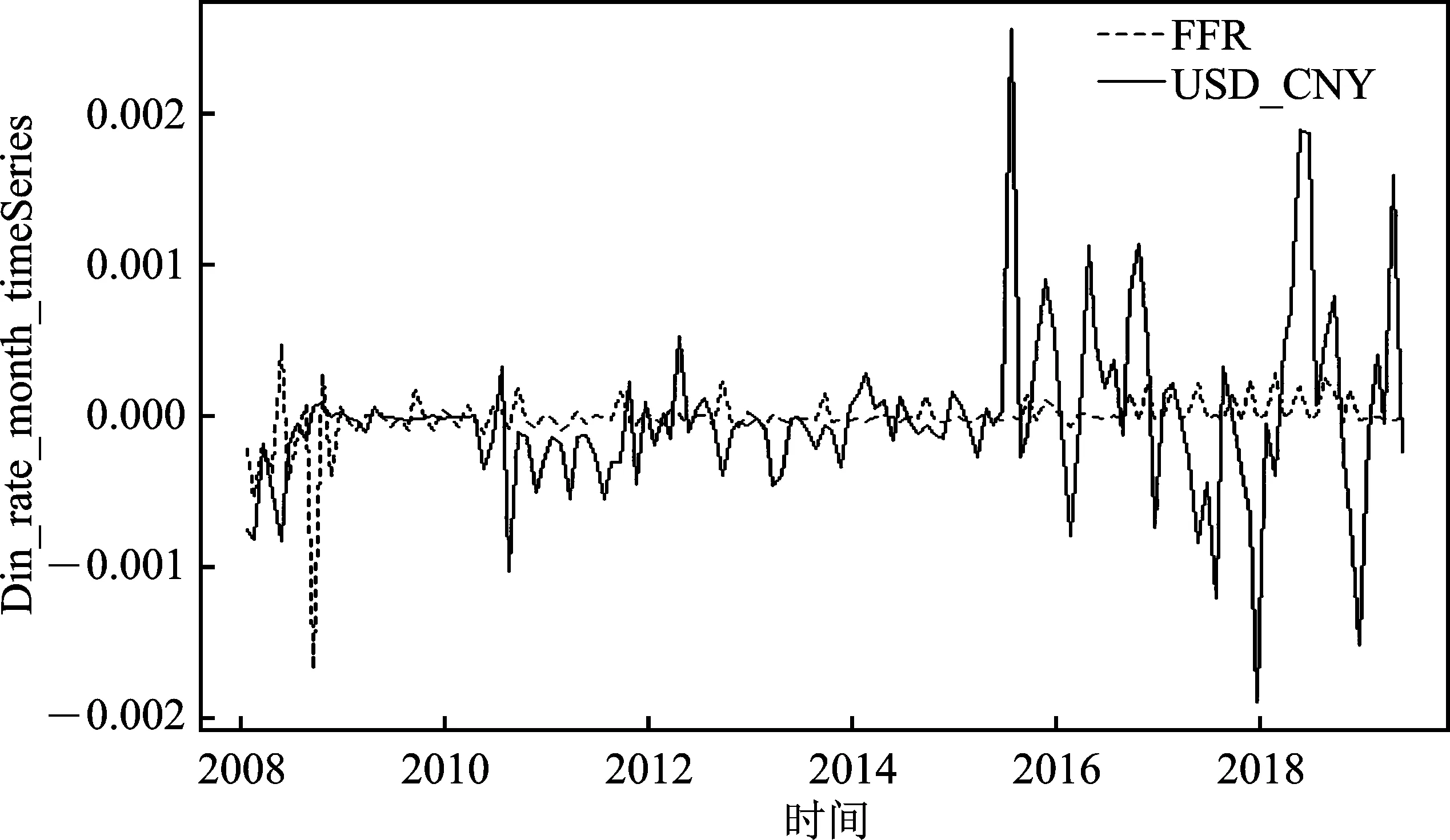
图6 去除季节效应后汇率与美联储基准利率趋势图
(四)数据相关检验
1.平稳性检验。在利用时间序列数据进行建模前,首先需对文中各变量的平稳性进行检验,对于非平稳时间序列采用协整理论处理。由于本文数据包括月度和周度两种频率,因此我们对CNY周数据,以及对应的每个月第1、2、3、4周数据作为月度数据的代理变量分别进行平稳性检验,并用lnCNY_week_1、lnCNY_week_2、lnCNY_week_3和lnCNY_week_4表示;除lnCNY_week和DlnCNY_week为周数据之外,其他均为月度数据。在经ADF平稳性检验后发现,TOT、CPI/PPI的对数序列均平稳,USD_CNY、FFR对数序列不平稳但经过一阶差分后平稳,由此构建同阶单整模型。从CNY_week对数周数据中对应抽取的月度数据也均为一阶单整过程。
2.协整检验。由式(5)可知,在ECM-MIDAS模型中,其协整关系在动态混频中并不唯一;因此本文尝试构建多种误差修正模型,以验证该类协整关系在变量间是否显著。由上文可知本文选取的指标中,月度数据与周数据间倍差m为4,于是对高频数据,我们试用以下形式:
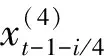
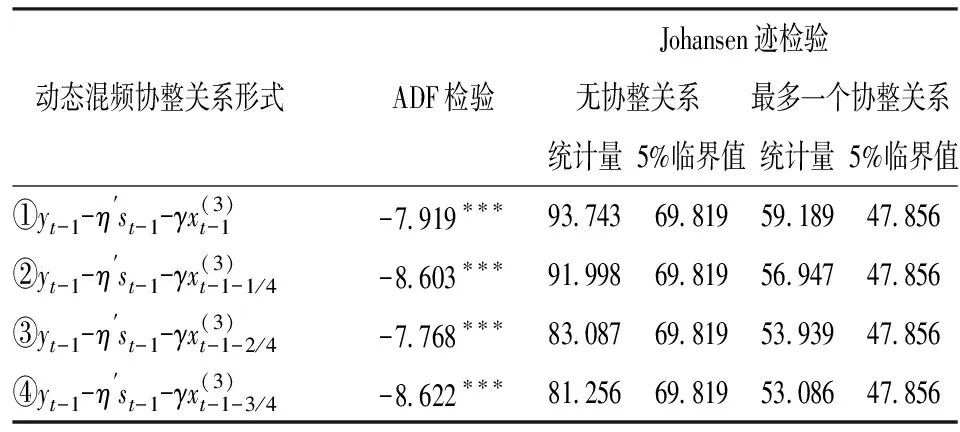
表2 协整关系检验
如表2所示,基于回归残差的协整检验以及Johansen迹检验,对动态混频模型不存在协整关系的原假设均予以拒绝。本文先采用动态混频协整关系形式①构建模型予以分析,为确保模型稳健性,我们会在后文详细研究其余②、③、④动态混频协整关系对预测效果的影响。关于文中USD_CNY、CPI/PPI、FFR、TOT、POLICY月度数据最优滞后阶数的选择方面,本文AIC值为准则,从滞后0~12期中选择最优滞后阶数。经模型筛选发现,滞后1期的USD_CNY、滞后1期的CPI/PPI、滞后1期的FFR、滞后1期的TOT和滞后1期的POLICY的AIC值最小,因此使用该结果构建SEMI-ECM混频模型。同时,使用最小二乘法,代入①形式获得长期误差修正项:
(0.013)(0.101)
PPIt-1+0.001lnFFRt-1-0.023lnTOTt-1+
(0.275) (0.061)
(0.009) (<0.001) (9)
由式(9)括号中的p-value统计量可知,滞后一期的贸易条件(TOT)与滞后1期的政策虚拟变量以及USD_CNY周数据对应的系数分别在10%和1%的显著性水平下与0存在显著性差异,由此可见贸易条件(TOT)、政策变量(POLICY)与滞后1期的周汇率CNY_week对于月度汇率USD_CNY具有较强的解释能力。
3.拉姆齐RESET检验。由于影响汇率的因素繁多,为保证数据的有效性与实验结果的可靠性,本文使用一般性方法检验——拉姆齐RESET检验(regression specification error test)来检测模型中是否具有遗漏变量以及模型函数形式是否被正确设定。其基本思想是通过最小二乘法估计出解释变量的高次幂(平方、三次方以及更高次幂)作为替代变量,估计并检验其参数是否显著不为零;若计算结果无法拒绝原假设,则不能认定本文设定的模型中有变量遗漏,也不能认定模型中含有设定错误所带来的误差。
本文继而对SEMI-ECM、U-MIDAS、ECM-U-MIDAS、R-MIDAS、ECM5种模型中解释变量以及模型设定进行检验。由于ARIMA模型是自回归模型,模型中不存在其他解释变量,因此不进行该项检验。
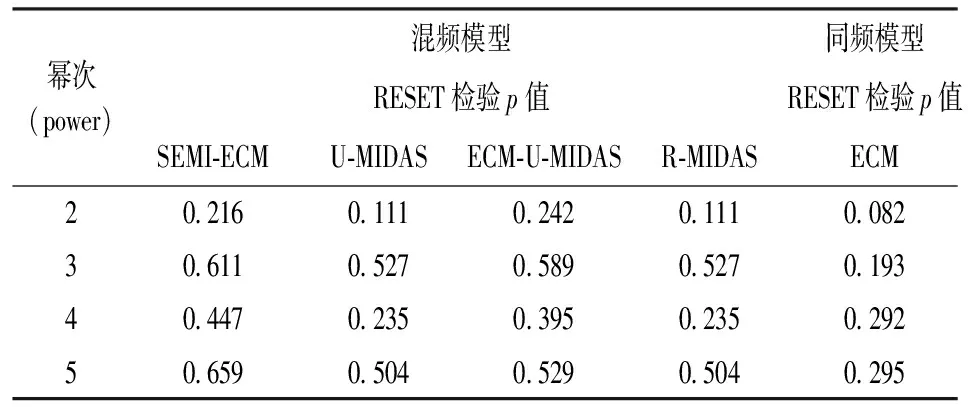
表3 拉姆齐RESET检验
综合上述检验结果,RESET检验在上述5种模型中,p值在5%的显著性水平上均无法拒绝原假设,即模型不存在遗漏变量或模型设定问题。
(五)模型估计与比较
1.无约束混频数据抽样(U-MIDAS)模型。在对MIDAS模型参数进行估计前,我们通常需要限定其滞后权重多项式。但在某些情况下,事前设定滞后权重多项式的客观性有待商榷。Foroni等为规避这一设定缺陷,在原始MIDAS模型基础上构建了非限定的MIDAS模型[15](即U-MIDAS模型)以简化模型设定,使得改进后的模型无需再对滞后权重多项式限定条件。
一般来说,U-MIDAS模型的具体形式如下:
本文基于AIC准则选取最优滞后阶数,将所有变量的滞后阶数限定在0~12阶范围内(即一年时段内)。本文使用网格搜索,选取各变量代入模型后具有最小AIC值的最优模型阶数,其中DUSD_CNY的最优滞后阶数为1阶。在滞后阶数选择上,对于CPI/PPI和CNY_week的滞后阶数选择均设定在1~4阶,FFR与POLICY的滞后阶数范围设定为1~6阶,TOT的滞后阶数范围设定为1~7阶;对应的AIC值为277.455。
2.混频数据抽样误差修正(ECM-U-MIDAS)模型。由表2已知,解释变量CNY_week、TOT、CPI/PPI、FFR之间存在长期稳定的协整关系,因此可以在U-MIDAS模型的基础上做进一步的推广,把动态混频误差修正项(2)加入模型之中,考虑了长期的误差修正机制后的ECM-U-MIDAS模型,如果长期误差修正机制存在,那么模型的预测效果应该会得到显著提升,并且在误差修正机制下误差修正参数应该显著为负;对应的AIC值为271.787。
3.有约束混频数据抽样(R-MIDAS)模型。介于U-MIDAS模型中具有较多的待估参数,Ghysels在该模型的基础上创建了对参数施加函数性约束的混频模型,在精简模型形式的同时也提高了拟合模型精度。本文构建均含有两个参数的阿尔蒙多项式函数(Almon)和标准化指数阿尔蒙函数(Nealmon),并对实际结果进行比较,选取其中AIC值最小的函数作为最优函数并得到相应的最优滞后阶数。结果表明,变量CPI/PPI、FFR、TOT和POICY的参数形式均以Nealmon形式为佳,所对应的最优滞后阶数均为1~2阶;对应的AIC值为266.057。
4.误差修正(ECM)模型。在构建同频误差修正模型时,由于解释变量中存在高频数据,本文将周高频数据CNY_week以月为单位等间隔抽取样本作为月度数据,即采用每个月份对应的某一个周的数据作为月度数据,月度汇率数据采用1美元兑人民币汇率数据的月度均值表示。在选择同频ECM模型最优滞后阶数方面,我们依赖于AIC准则,对解释变量的滞后阶数自0到12阶进行网格搜索,当CNY_week的滞后阶数为1~4阶、CPI/PPI的滞后阶数为1~4阶、FFR的滞后阶数为1~6阶,被解释变量滞后阶数为1时达到AIC值最低;对应的AIC值为338.362。
5.差分整合移动平均自回归(ARIMA)模型。本文采用包含一阶单整的单变量ARIMA模型,在参照AIC准则后确定模型具体形式为ARIMA(1,1,1);对应的AIC值为327.624。
基于训练数据,本文建立半参数混频误差修正(SEMI-ECM)模型及上文提到的其他三种混频数据模型,ECM模型以及ARIMA模型这两种同频模型对实证数据进行分析及预测。基于AIC准则,本文使用网格法筛选出最优参数,得到各模型的系数估计值如表4所示。
从表4可以得到如下几个结论:
第一,在赤池信息准则下,SEMI-ECM模型相较其他模型具有卓越的拟合优势。这说明,人民币月度汇率的当前值与历史值之间存在很强的相关性,仅利用历史数据就可以在样本范围内得到较好的拟合模型。此外,相较于非限制性的混频抽样模型,限制性模型的拟合优度明显优于前者,这是因为限制性混频抽样模型中引入误差项后模型的待估参数变少,复杂度降低、AIC值变小。两种同频模型较混频模型存在明显劣势,而不同混频模型间拟合效果则差异较小。因此,可近似认为半参数混频误差修正模型在样本内的拟合效果相较于传统同频模型具有显著优越性,且在其他混频模型中表现优秀。
第二,由该表可得,文中加入的误差修正机制较显著。ECM与ECM-U-MIDAS模型中的误差修正项系数均为负值且显著,这意味着在这两种不同模型下都存在着有效的反向误差修正机制。根据实验结果,这种修正机制能够合理降低AIC,改善拟合效果;同时对于存在协整关系的非平稳混频时间序列数据,误差修正项的进入也可达到上述目的。
第三,2015年“811汇改”对人民币汇率走势具有显著影响,在SEMI-ECM、U-MIDAS与ECM-U-MIDAS中政策变量(POLICY)滞后4期系数p值在1%水平上显著为负,这说明“811汇改”对人民币汇率的升值起到“降温”作用,与历史文献中“811汇改”后人民币币值被低估的结论一致;美联储基金利率(FFR)并未对中美汇率造成显著影响,究其原因可能是因为中国在市场政策上的限制,美国资本及外汇市场变动产生的影响不会立即反映于中国市场,因此中国汇率在短时间内并不会因此原因产生较大的变动和调整,而是由投资者预期和国际贸易的经常项目进行传导,使得美元兑人民币汇率发生变化。
第四,贸易条件(TOT)的变化对汇率的影响效应乘数为正,说明贸易条件改善则人民币升值,即在所考察的时间区间内贸易改善所产生的收入效应大于替代效应。
第五,滞后1期、2期和4期的周汇率对当期月度汇率关系密切,系数显著为正,影响乘数在0.5~1.15之间,表明滞后1期、2期和4期的周汇率数据对月度汇率的预测具有很强的指导意义。
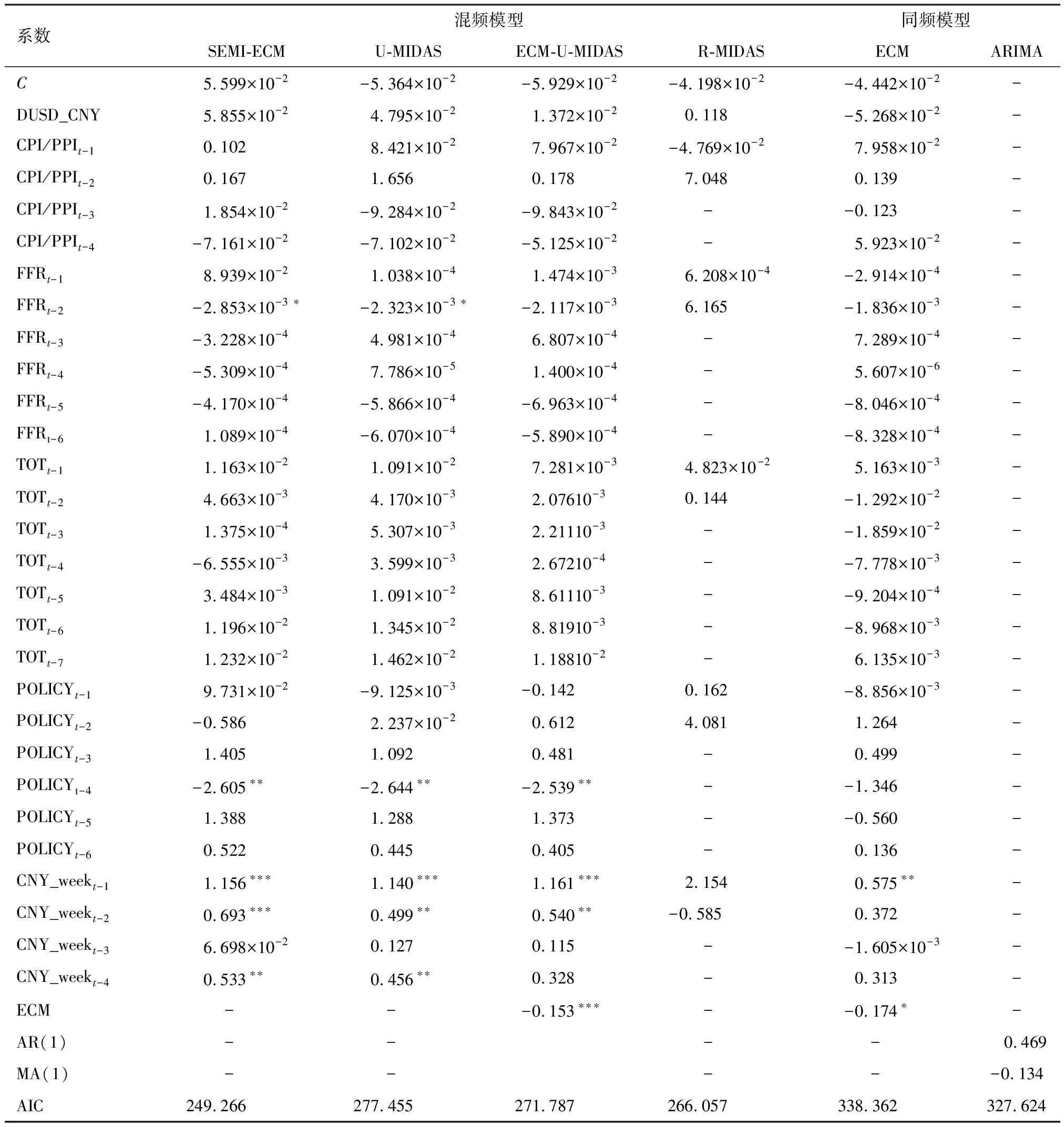
表4 最优滞后阶数下不同模型的估计结果
(六)一致性检验
在上文建模与估计部分,我们基于AIC准则,对包括SEMI-ECM模型在内的6种模型选取最优拟合效果的参数。如果我们将AIC作为模型拟合优劣的评价标准,则通过表5可得本文重点构建的SEMI-ECM模型AIC值最低,这在一定程度上表明该模型在此数据集中具有最优拟合估计效果。但是,仅基于AIC准则不能证明半参数混频误差修正模型的使用在统计上具备合理性。为验证SEMI-ECM模型是否适当,本文使用广义似然比(GLR)检验统计量进行检验。同时,考虑到ECM-MIDAS和MIDAS两个参数模型之间的嵌套关系,本文需要在模型加入动态混频误差修正项后,对其拟合效果有无改进进行验证。本文利用传统的似然比检验,对参数回归模型函数形式框架下加入的修正项进行探究,并观察加入后对新模型的拟合的提升作用。MIDAS模型(模型1)、ECM-U-MIDAS模型(模型2)和SEMI-ECM模型(模型3)基于似然比检验和广义似然比检验的具体结果详见表5。

表5 参数回归模型函数形式的一致性检验
(七)预测表现
在上一部分中,SEMI-ECM模型在样本拟合中与其他模型相比具有较大优势。为进一步检验该模型在预测中能否同样具有最佳结果,我们对SEMI-ECM模型与其他5种模型在样本外数据进行一步预测,比较对一个季度、半年及一年内的汇率预测效果。为了避免因样本选择而产生人为误差,本文将数据以递归(Recursive)、滚动(Rolling)及固定(Fixed)方式进行抽样,分别进行一步预测,并根据预测样本规模以对一个季度的汇率走势进行连续预测。最后利用实际观测值与模型估计值计算均方根误差(RMSE)和平均绝对误差(MAE),预测效果见表6~8。
从表6~8来看,SEMI-ECM预测在3、6、12期中表现卓越,在第12期中的预测效果趋于普通,主要原因为混频模型的准确性依赖于高频数据的实时更新,当预测期数扩大后,混频数据对趋势的捕捉能力下降,从而导致预测效果与其他模型大致相同。
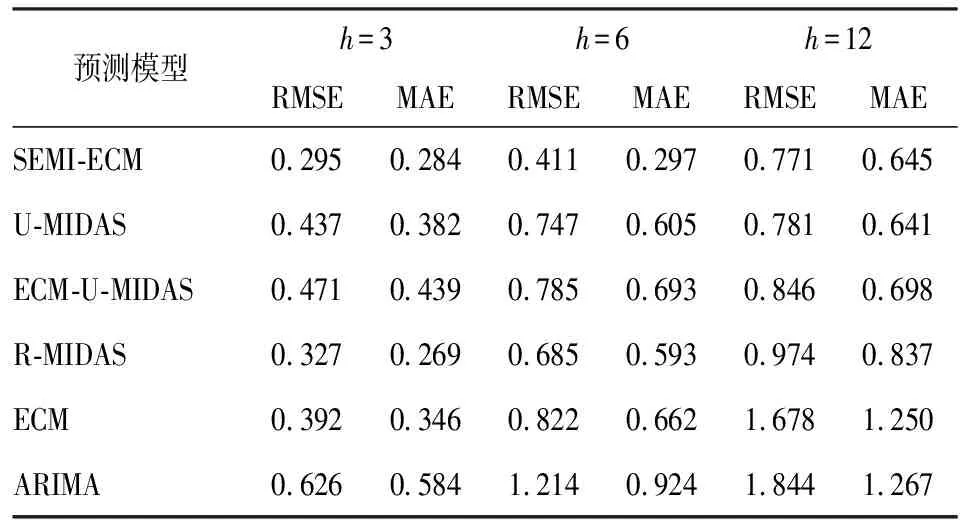
表6 递归样本预测结果(×10-4)
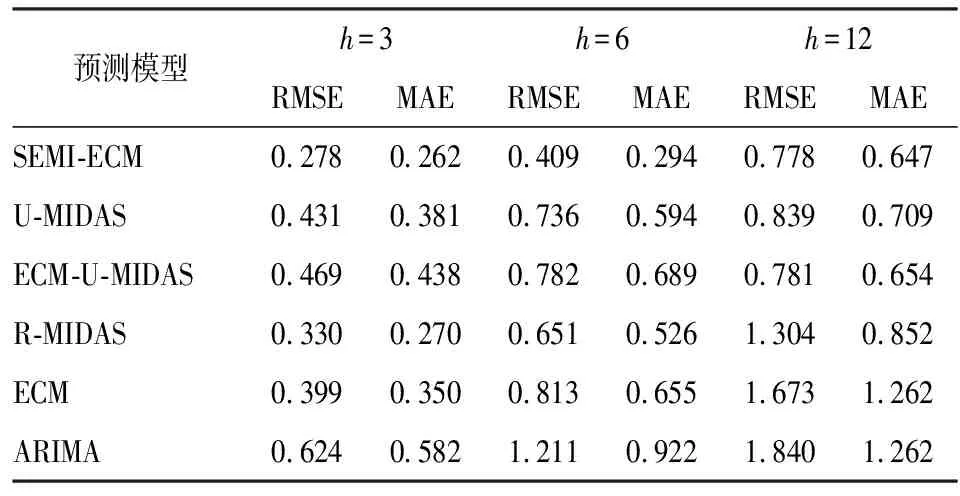
表7 滚动样本预测(×10-4)
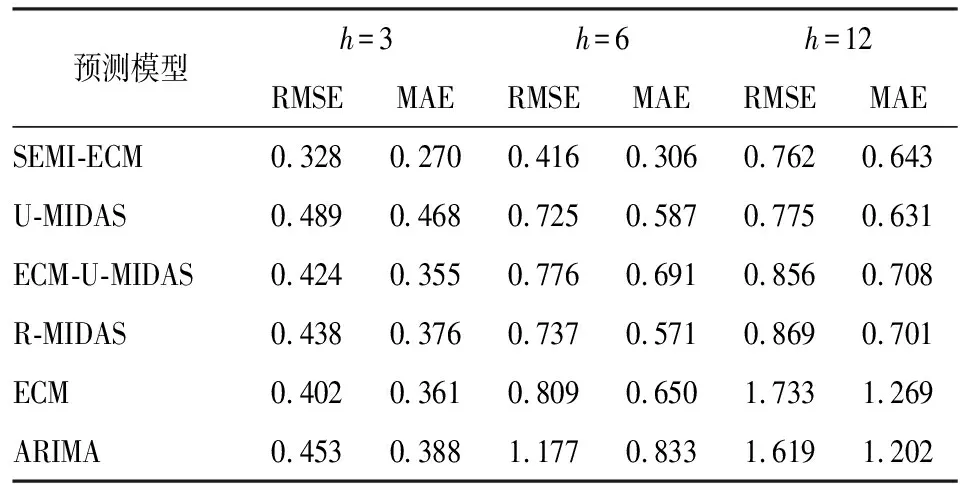
表8 固定样本预测(×10-4)
ARIMA模型预测效率相对低主要是因为仅依赖自身历史数据,且ARIMA本质上只能捕捉线性关系,对于非线性关系存在捕捉局限。人民币月度汇率数据是非稳定的,常常受政策和新闻的影响而波动。因此在该种数据类型下,ARIMA无法体现其自身优势。SEMI-ECM模型则是综合宏观和微观两方面信息而对汇率做出预测,以上结果说明混频数据模型在汇率预测中相对于传统汇率模型具有优势。同时,这也体现出混频模型在短期经济模型估计及预测上的显著优越性:第一,其能够充分利用不同频率的数据,兼顾低频数据的精确性以及高频数据的及时性,相较于传统模型,减少了对原始数据信息的隐藏或破坏,从而增强对宏观监测的准确性。第二,它能够利用最新公布的高频金融数据补救低频宏观经济数据客观的时滞缺陷,提升宏观经济预报的时效性和短期预测的精确度。
整体来看,SEMI-ECM的预测效果在短期预测中结果相对其他方法更加优秀,在预测3到6期的结果更加体现出SEMI-ECM的优越性,预测精度远高于其他模型。这也进一步表明,在进行短期即时预测时,本文使用的SEMI-ECM模型具有良好的应用前景。
五、结论与启示
本文以中国的月度宏观经济数据和周度的汇率数据为研究对象,利用SEMI-ECM模型,对中国的人民币对美元月度汇率的预测做了深度研究。本文对数据的非平稳特性,设定多种形式比较最优拟合效果并建立协整关系构建误差修正模型,并与同频数据模型进行对比。
介于宏观经济变量所具备的非线性特征,本文参照鲁万波等构造的一种允许误差修正项具有非线性形式的SEMI-ECM-MIDAS模型,对人民币月度汇率影响因素进行估计预测。模拟结果表明,由于将非线性误差修正项引入存在协整关系的非平稳MIDAS模型,SEMI-ECM模型在处理存在非线性误差修正机制数据时具备了明显的预测优势,能够提高模型预测精准性,同时高频数据的实时性特点使得模型的实用性得以增强,填补了理论模型在实际应用中存在的部分客观缺陷。
在实证过程中,主要有下几点结论:
第一,在实证研究中,本文引入中国非贸易品与贸易品的相对价格比、贸易条件以及美联储基准利率的月度信息、“811汇改”政策虚拟变量以及高频金融数据对美元兑人民币汇率月度数据的预测效果进行了研究,并与其他预测模型进行了比较。实证结果表明:美联储基准利率、“811汇改”政策和高频金融数据能够显著影响美元兑人民币汇率。通过最优拟合模型可得,高频金融数据以及“811汇改”政策对人民币汇率影响程度尤为明显。出现这一结果的原因,其一是美元作为世界货币,其对于全球经济的引导作用能够对中国的贸易经常项目和资本流动施加影响;且中国的外汇储备主要是美元,美联储基准利率一定程度反映美元余缺,从而反映于美元兑人民币汇率中。其二是中国“811汇改”将汇率市场化大幅推进,在汇改后人民币汇率的波动幅度加大,不可避免地增加市场风险,对投资者情绪甚至是金融市场造成一定的影响。高频数据的滞后一期对汇率月度数据有显著影响,表明月度汇率有滞后效应,可以通过高频数据得出更为准确的预测。
第二,混频模型的预测精度普遍优于同频模型。对比本文共选取的六种混频与同频模型,前者的预测能力相对于后者有所提升。对所有模型的样本内估计的均方根误差进行比较后发现,混频模型在预测上的优势显著,其中本文着重应用的SEMI-ECM效果最佳。这是由于同频数据需采用低频作为最终频率,长期内会损失大量的数据波动信息,从而降低预测精度。总而言之,模型对有效信息的利用方式能够在一定程度上决定预测能力的强弱,混频数据模型对不同频率数据的容纳程度决定了其预测能力通常强于同频数据模型。同时,预测结果可随高频信息的更新速度不断及时更新拟合及预测结果。
第三,实证结果表明,CPI/PPI、FFR、TOT、CNY_week和人民币月度汇率之间协整关系的充分利用可以显著提高模型的预测能力。在构建参数误差修正模型时,误差修正项始终保持显著的反向修正机制。在进行连续预测时,无论选用递归、滚动抑或是固定样本,本文重点运用的SEMI-ECM模型具有极佳预测精度。同时,为保证实证结果的稳健性,本文进一步选取其他所有可供使用的动态混频协整关系进行建模验证,并对比相应的预测结果,发现本文选用的SEMI-ECM模型预测精度并不会受到混频动态协整关系的影响。因此,SEMI-ECM模型具有最小预测风险这一优点不再受混频动态协整关系影响,该模型在应用中存在一定的稳健性。
总之,混频误差修正模型在宏观经济领域具有广阔的应用前景,其具有克服混频时间序列不平稳而避免伪回归的显著优势,充分利用各频率市场信息,提升对宏观经济预判的准确性。本文使用的SEMI-ECM模型可以进一步丰富和完善混频模型在人民币月度汇率预测中的应用,利用易获取信息便可大大提高对人民币月度汇率预测的精度。
基于本文的理论探究,我们量化了人民币汇率的影响因素,汇率同时受以上变量的实时影响。通过混频模型估计可得,人民币汇率受中国宏观政策影响更大,同时也受到美国相关政策的一定影响。中国经济具有良好的基本面,这一背景有力地支撑着人民币汇率,保持人民币汇率在可接受范围内合理运行。人民币汇率对于美联储基准利率的反映表现并不明显,这就体现出汇改浮动汇率制的优越之处——不再盯住单一美元,中间价与市场价格的偏离得到校正,中间价的基准作用明显增强。在当前贸易战背景下,其可以起到自动稳定器的作用,有利于奖出限入,改善贸易平衡。总体来看,对于人民币汇率兑美元目前面临的贬值压力,在经济下行压力明显的情况下,稳定投资者信心,稳增长保就业仍是国内经济政策的重中之重。促进中国经济的长期持续健康发展才是稳定人民币汇率的根本方式。
