基于改进MTCNN的人脸检测算法
2020-12-22蓝雯飞张盛兰朱容波熊文娟
蓝雯飞,张盛兰,朱容波,熊文娟
(中南民族大学 计算机科学学院,武汉 430074)
人脸检测是人脸识别技术的重要环节[1],作为一种生物特征验证技术,人脸检测与人脸识别具有不要求识别者主动配合、采集人脸方便等特点,如今,人脸检测技术已渗入众多行业,成为生活中必不可少的一部分[2].但是,由于传统的人脸检测方法比如基于ASM的人脸检测,达不到对数量规模较大的人脸图像进行检测的要求.随着科学技术的发展,近年来,使用与深度学习相关的目标检测算法去处理图像相关的任务成为最热门的研究之一[3].
CNN(卷积神经网络)是深度学习在图像方面的应用.吴纪芸等人提出了一种改进的MTCNN人脸检测算法,通过改进多任务卷积神经网络,整合不同网络模型,动态修改Minsize值,减少图像金字塔中图片生成数量,达到优化网络的目的[4]. ZHANG等人提出基于多任务卷积神经网络的人脸检测和对齐算法,文章通过三阶的卷积神经网络对任务进行从粗到细的处理并提出一种新的在线硬样本生成策略进一步提升性能[5].
受文献[5]及相关研究启发,本文对深度学习理论中的神经网络结构进行了深入研究,在继续采用三阶卷积神经网络训练图像的基础上,对原始MTCNN人脸检测算法做了改进,旨在提高模型的检测准确率和训练速度.
1 理论基础
1.1 MTCNN人脸检测算法
在深度学习中,MTCNN(Multi-task Convolutional Neural Network)人脸检测算法是人脸识别过程中较实用的、性能较好的一种检测方法,它可以根据人的正脸或侧脸来对一个人的脸部关键点进行检测.
1.2 检测原理
MTCNN是一个由三层网络(P-Net、R-Net、O-Net)组成的网络结构,其主体思路为级联卷积神经网络思想,并使用多任务的形式训练网络参数,来实现人脸检测由简到精的过程[6].
为确保不同尺寸的图片输入都能得到正确的输出结果,即实现对不同大小的人脸进行检测,MTCNN网络采用图像金字塔的形式,将原始的人脸图片按照网络模型设计,缩放为不同尺寸大小,然后将处理后的图片传入P-Net网络,接收到图片后,P-Net会首先对图片进行分析,生成很多的人脸候选框,然后对所有候选框进行NMS(非极大值抑制)计算,删除掉一些重复的人脸候选框,并将输出结果映射到原图像上;紧接着,该网络会在原图像上截取出所有由P-Net确定的(离散)图像片段,将其调至24×24像素大小后传入R-Net处理;R-Net接收到这些分散的图片后,将输出经由P-Net处理后的每一个候选框的修正值和置信度值.然后,运用NMS算法进行计算,矫正置信度值高于阈值的候选框并输出,经过R-Net处理后会获得一些相对正确的人脸框,将这些候选框调至48×48像素大小后传入MTCNN里面最精细的网络O-Net进行运算,同时,生成置信度和修正值,对候选框再次进行NMS计算,修正置信度值大于阈值的候选框,直到最终输出正确的人脸候选框和人脸特征关键点坐标为止.
MTCNN神经网络的训练流程如图1所示,原始图像经过P-Net、R-Net和O-Net处理后输出人脸候选框和关键点坐标.
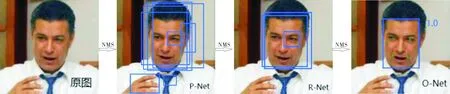
图1 MTCNN神经网络训练流程图Fig.1 Training flowchart of MTCNN neural networks
1.3 激活函数选择
日常神经网络训练过程中比较常见的激活函数有sigmoid、tanh、ReLU等[7].
sigmoid激活函数是使用范围最广的一类激活函数,常用于隐藏神经元的输出.它的函数定义如下:
(1)
它可以将网络中函数的值域R映射到(0,1)区间.sigmoid函数对中心区域的信号增益较大,对两侧区域的信号增益小,可以用来解决二分类问题[8].
tanh是在sigmoid函数基础上改进来的,它的函数定义如下:
(2)
tanh函数是一条以零为中心的曲线,取值范围为[-1,1],其优点是几乎可以适用于所有场景,该函数在特征相差明显时效果会很好.
本文训练过程中采用的是一种后来才出现的激活函数——ReLU函数,其定义如下:

(3)
相比sigmoid函数与tanh函数,ReLU函数有以下优点[9]:
(1)加入非线性因素,使网络有更好的表达能力,加强模型的学习能力;
(2)算法简单,网络运算效率更高;
(3)梯度是常数,不会出现梯度消失,使得模型收敛速度稳定;
(4)收敛速度比sigmoid和tanh函数快.
2 算法及改进
2.1 人脸对齐模块
模型训练时,将经历图像金字塔处理后的各种尺度的图像送入卷积网络中处理,经过多次卷积、池化和再卷积操作,最终得到输出图像,由输出图像得到目标矩形框,如图2所示.

图2 处理后的人脸图像Fig.2 Face image after processing
当训练集中的图片经过网络模型时,若出现边界框左上角y轴坐标值小于0,即说明人脸信息不全,自动舍弃此类人脸图像.
本文使用自然环境下的人脸训练样本,人脸特征点定位使用的损失函数公式如下:
(4)
2.2 模型参数调整
人脸检测大体上分为两个阶段:1)找出所有可能是人脸的候选区域;2)通过边界框回归从候选区域中选出最可能是人脸的区域.MTCNN算法通过P-Net、R-Net和O-Net解决了边框回归和关键点定位的问题,在此基础上,本文对此算法做了进一步改进,对MTCNN关键参数nms_threshol,threshold,minsize进行微调. 改进后的流程图如图3所示.
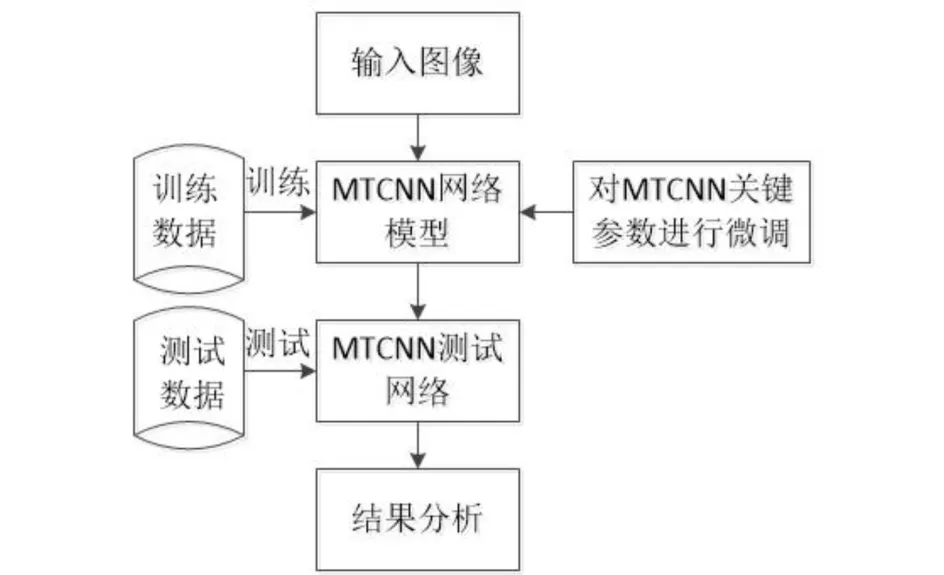
图 3 改进后的流程图Fig.3 Flowchart of improved algorithm
如图3所示,模型训练时对关键的参数进行了调整.nms_threshol表示采用非极大值抑制算法筛选人脸框时的IOU阈值,threshold表示人脸框得分阈值,minsize表示最小可检测图像,本文通过边界框回归和非极大值抑制算法进行最佳人脸候选框的选择,从而给参数设定合适的阈值.threshold的值设置得过大,会导致冗余计算;设置得过小,则会出现一系列问题比如人脸检测候选框太小提取不到合适的人脸特征信息等.
通过对网络模型进行测试和分析,并经多次实验对比,得出结论:当MTCNN中R-Net和O-Net的nms_threshol值分别设置为0.7和0.15、threshol分别设置为0.7和0.15、minsize值设置为24时,在同一测试集上的人脸效果最好.
2.3 引入人脸误检判别公式
研究发现:在进行了关键参数的微调后,网络模型在自然环境中测试集上的人脸检测效率有了较明显的提高,但是部分人脸被误检的情况仍旧存在.通过对测试集人脸置信度数值进行分析对比发现,当人脸置信度的值高于或等于0.96时,候选框中是完整人脸的概率较大,被误检的人脸(给出的人脸候选框)的置信度都小于0.96.由此,本文引入一个人脸误检判别公式,公式的阈值通过对实验结果进行对比而得:

(5)
p表示MTCNN神经网络对自然环境下人脸检测的人脸候选框置信度的大小,当f(p)=1时,表示检测到的目标区域是人脸;反之,f(p)=0,则为误检的情况,并对该检测区域进行舍弃.本文通过对MTCNN网络模型参数进行微调,得到了不同的检测结果,对比实验结果发现:设置p的值为0.96时,此MTCNN网络模型能在自然环境中的测试集上取得最好的效果,与此同时误检率也能最大程度地降低,其流程图如图4所示.
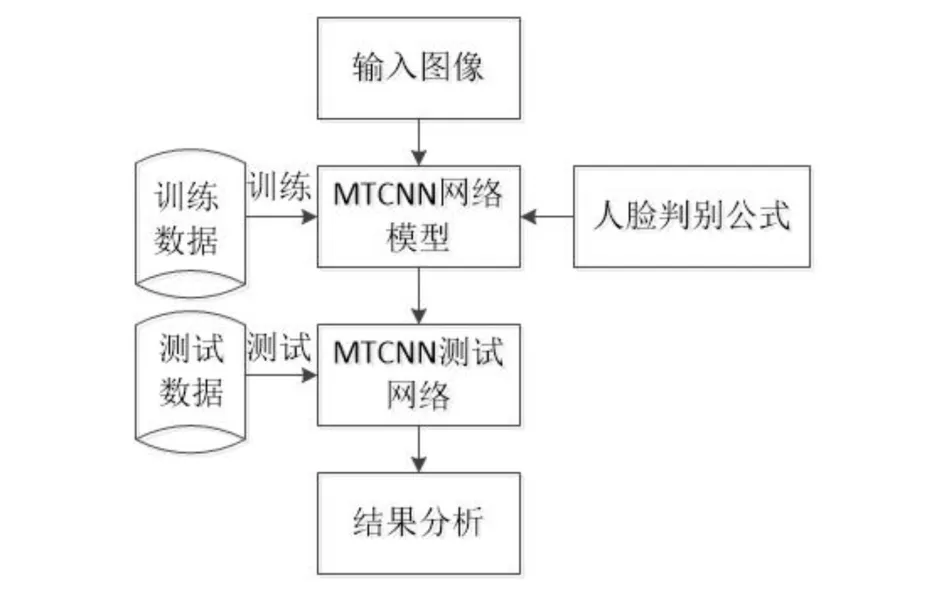
图4 使用人脸误检判别公式后的流程图Fig.4 Flowchart of using face misdetection discrimination formula
引入人脸误检判别公式后,虽然存在个别图像被误检的情况,但网络模型在同一测试集上的人脸检测误检率明显降低.本次的实验结果是在对网络模型参数进行微调的基础上取得的,实验结果表明:判别公式引入后,该网络模型在人脸检测的准确率和鲁棒性上都有了提高.
2.4 模型的核心算法
(1)非极大值抑制(NMS)算法是一个寻找局部最大值的过程,它可以准确、快速地去掉标定为不合格但重合度却很高的候选窗口[10].就本次的人脸检测过程来说,在训练的初始阶段,P-Net网络会框出很多的人脸候选框,其中不少是重复的,使用NMS算法则可以舍弃很多预测分数较低的候选框、保留预测分数较高的候选框,最后再将对应的人脸候选框映射到原图像上.
(2)人脸检测就是在一张图中找到所有的人脸,它是一个分类任务,本文选择交叉熵损失函数来实现其功能,函数公式为:
(6)
该函数能表征真实样本标签和预测概率之间的差值,可以无限增加“分类失误”的惩罚力度,加快模型训练速度.
3 模型训练
模型训练流程如下.
(1)确定网络的输入变量和输出变量:
输入变量:对MTCNN检测出来的人脸图片进行灰度处理操作,转化为单通道的图片数据,再把图片缩放到宽度和高度都为64的图片.
输出变量:输出变量是每张输入图片经过卷积网络处理后的带有人脸候选框和置信度的图片,是离散变量.
(2)数据集划分:
将人脸图像数据按照8∶2的比列,划分为两部分:一部分用于训练集,另一部分是进行检验的验证集.
(3)卷积神经网络由3个卷积层和1个全连接层组成,详细结构为:
(i)第一个卷积层:用32个3×3×1的卷积核对输入图像做卷积,后面的×1是因为输入的图片是单通道的,卷积核移动步长为1.卷积之后,为增强模型的拟合能力,用ReLU激活函数作为非线性映射函数;之后对每个2×2的区域做最大池化操作;最后用一个dropout层防止过拟合,dropout层的做法是以一定的概率p,让某个神经元停止工作,这次训练过程中不更新权值,也不参加神经网络的计算,但其权重需保留下来;
(ii)第二个卷积层:用64个3×3×32的卷积核对第一个卷积层产生的feature map再卷积,这里的32是因为第一个卷积层用了32个卷积核,产生的feature map也是32维的;
(iii)第三个卷积层:用64个3×3×64的卷积核对第二个卷积层产生的feature map做卷积,后面的结构跟之前的卷积层一模一样;
(iv)全连接层:一个普通的神经网络结构,把卷积层学习到的特征和最终的输出层连接起来.全连接层的输出通过softmax函数传递,会输出样本属于各个类别的概率值,那么样本分类结果就是概率值最大的那一类.损失函数定义为交叉熵函数,用梯度下降法传递误差.
(4)每次训练都从训练集中随机抽取100个样本进行训练,训练达到一定次数后,考察模型在测试集上的性能,如果预测的准确率达到某个阈值,即可停止训练,本文中的阈值设为0.96.
4 实验与结果分析
4.1 数据预处理
为验证上述方法在识别准确率和识别速率方面的优势,本文做了相关的实验.
选用公开的LFW人脸库作为本次实验的训练数据集,该数据集提供的人脸图片均来源于生活中的自然场景,一共包含5000多人,约1680人包含两张以上的人脸,人脸库分为光照、遮挡、表情等不同情况,该数据库被广泛应用于评价人脸检测与识别算法的性能.
实验之前,首先对人脸图像数据进行预处理,将图像尺寸缩小至64×64像素,灰度值控制在0~1范围内.整个训练过程中,使用真实的人脸坐标区域计算IoU值(IoU值表示的是子窗口与真实窗口的交集与并集的比值),若IoU值大于0.65,为正样本,小于0.3则为负样本,IoU值在0.4到0.65之间的视为只含有部分人脸的图片信息.
4.2 实验结果分析
在MTCNN人脸检测算法中,主要关注3个指标,即检测准确率、误检率和检测速度.本文将人脸数据集分为两部分,其中80%作为训练集,20%作为测试集.为方便对参数微调前后的MTCNN网络模型作对比,本文将参数微调前后的两个模型一起在测试集上做了测试,得到的检测结果见表1.
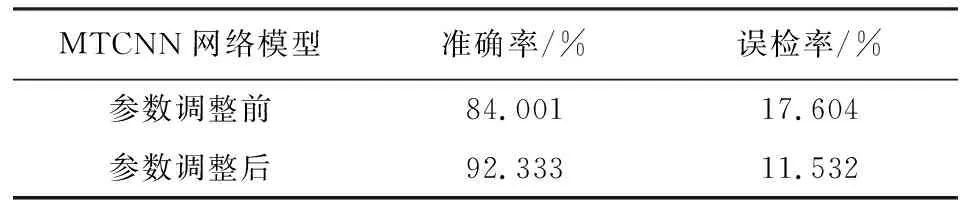
表1 参数微调前后的模型对比结果Tab.1 Model comparison results before and after fine-tuning parameters
MTCNN网络模型引入人脸误检判别公式后,再次对网络模型进行训练,改进前后的测试结果如表2所示.

表2 引入判别公式前后模型测试结果Tab.2 Model test results before and after introducingthe discrimination formula
4.3 实验结果对比
MTCNN人脸检测算法改进前后在检测速度上的对比见表3.

表3 改进前后检测速度对比Tab.3 Comparison of detection speed before and after improvement
从表3可以看出,本文改进后的人脸检测算法在提高检测准确率的同时,检测速度也有所提升.
5 结束语
本文在原MTCNN人脸检测算法的基础上,对原有的网络模型进行迁移学习即对算法涉及到的参数进行了讨论,同时对模型的关键参数进行了微调,从多组实验结果中选择效果最佳的参数并确定人脸置信度的阈值,同时提出了人脸误检判别公式,当目标区域的阈值小于给定的阈值时,判定该区域不是人脸,对此区域进行舍弃.实验表明:微调参数后的MTCNN检测算法结合了人脸误检判别公式,与原MTCNN算法相比,人脸检测性能有了很大程度的提升,优化后的算法能够提高人脸识别率、降低训练时间,有助于人脸检测技术的推广和发展.