汉语学习者连续言语中的音节感知
2020-12-21杨蓓
杨 蓓
(中山大学中国语言文学系(珠海),广东,珠海519000)
1.引言
在没有语境的前提下,语音的感知受到语音信号和语音解码等影响。有些感知理论(如肌动理论)认为,语音感知是基于言语产出、通过辨别音姿(gesture)特点的倾向而达成的(Libermann&Mattingly,1985)。这一理论虽有争议,却受到一些实验的支持,如范畴感知(categorical perception) 等。同时,研究者发现,除了听觉,其它感觉系统也可影响言语感知的结果,例如麦格克效应(McGurk effect),它证明了视觉感知到的音姿对听觉感知起了非常重要的影响。
然而,通常情况下,人类的言语是连续的、有语境的。这种语境下的感知与孤立状态下的语音感知是不同的。Pollack & Pickett(1964)曾从一段连续的言语中选出一些词,在无语境的情况下,让母语者辨认。虽然原始录音的话语清晰,母语者可以毫不费力地辨别这些音节,但是由相同音节构成的词在无语境下,母语者却无法辨认。可见言语的感知并不完全基于语音和音系的知识,词法、句法、语义等也起了重要的作用。
目前就连续言语(continuous speech)的感知而言,被广为接受的感知处理包括两种机制:自上而下加工(top-down process)和自下而上加工(bottom-up process)。例如,根据TRACE 模型 (Elman & McClelland,1988),母语者感知言语时,多层面的心理加工是同时进行的,而且是相互作用的。所以母语者在感知言语时,是自动处理自上而下和自下而上加工的(Anderson,1995)。但是二语学习者却因语言知识有限,一般不能自动处理这两种加工(Vandergrift & Goh,2012)。至于二语者对这两种加工的处理,早期的研究(如Goh,2000;Hasan,2000;Nunan,2002;Graham,2006;Nix,2016) 结果相似,但是解释却不尽相同。例如,学者普遍认为二语学习者不能充分处理自下而上的加工,但是,Goh(2000)认为这是因为二语学习者缺乏注意表层细节的能力;而Hasan(2000)则认为是因为二语者没有掌握自上而下的加工,所以无法用其补偿“下面”,即表层语音的细节。这些研究没有具体分析与自下而上加工相关的语言学处理。所以对于二语者自下而上加工的弱点的解释趋于宽泛、缺乏细节。
Broersma&Cutler(2008)指出,从二语听力教学的角度来看,过于宽泛的概念无法提供确切的教学建议;有效的感知训练必须基于有精确分析的实证研究。因此,本研究观察和比较二语学习者和母语者在句子层面感知音节的异同,从与音节相关的语义特征和语音特征分析其自下而上加工,探究二语学习者感知的心理机制。汉语的语音感知研究基本是在孤立状态下对音节的声母、韵母、声调、重音等几个方面进行实验并分析结果的(如张家騄等,1998;习洁等,2009;王韫佳等,2010;杨新柳等,2014),少数关注连续话语中的重音(王韫佳等,2003),但是很少从各语言学层面分析研究语流中音节的感知。而对于非母语者的音节感知大多也是无语境的单音节研究(如安然等,2007)。所以我们有必要研究语流中汉语音节的二语习得。
此外,本研究对二语教学也有一定的应用价值。首先,从学习者的角度而言,不能从自下而上加工中获取言语信息会影响学习的效率,阻碍学习者吸收(intake)新的语言知识(Schimidt,1990;Izumi,2002)。所以了解学习者自下而上加工中与母语者的不同之处,可以在教学中对症下药,整体上促进二语发展。第二,就教学法而言,本研究的结果可以转化为实用规则,帮助设计合适的教学活动,以期进一步提高二语学习者的听力理解能力。本项目有两个研究问题:
(1)在连续话语中,二语学习者能否感知到表层的音节,即是否会忽略表层的某个音节?其感知与母语者有何不同?
(2)二语学习者如何使用自上而下和自下而上两种加工机制感知语流中的音节?
2.研究方法
2.1 被试
一共有20 位美国汉语学习者(平均年龄:20.26;年龄范围:18~23;12 位男性,8位女性) 和20 位汉语母语者(平均年龄:25.32;年龄范围:22~29;10 位男性,10 位女性)参加了本项研究。所有美国学习者的母语都为英语,他们没有任何与汉语相关的背景或者在家中说汉语的情况。他们在美国高校学习汉语2 年,其汉语属于中级水平。所有母语者18 岁以前在中国接受教育,其后留学美国。参加实验时,在同一所美国大学就读。40 位被试听力正常。其中一位母语者的数据出现错误因而未被采用。因此,本研究最终得到19 位母语者和20 位非母语者的数据。
2.2 任务
本研究的设计综合了错误辨识任务(error detection task) 和跟述测试任务(shadowing task)。设计实验时,每个句子中都存在一个错误音节,被试需要在听完每个句子后立刻复述,并尽可能复述与原句一模一样的句子,而非修复句子中的错误音节。例如,被试听到的句子为“明颠我们要和小王去电影院看电影”,他需要复述的句子为“明颠我们要和小王去电影院看电影”,而非“明天我们要和小王去电影院看电影”。
跟述测试任务是言语感知领域广泛应用的一种实验方法(例如,Marslen-Wilson &Welsh,1978;Slowiaczek,1994;Spence & Read,2003)。本研究使用跟述测试任务观察被试是否会在复述时修正错误音节。因为每个句子中都有一个错误音节,如果被试可以准确的复述这些错误音节,说明他在自上而下和自下而上的加工中准确辨别了表层的音节。但是,如果被试修复了错误音节,说明他在自上而下的加工中,使用其它语言学知识修复(restore)了句子中的错误音节,而自下而上加工中涉及表层语言学知识的加工处理却未起作用。
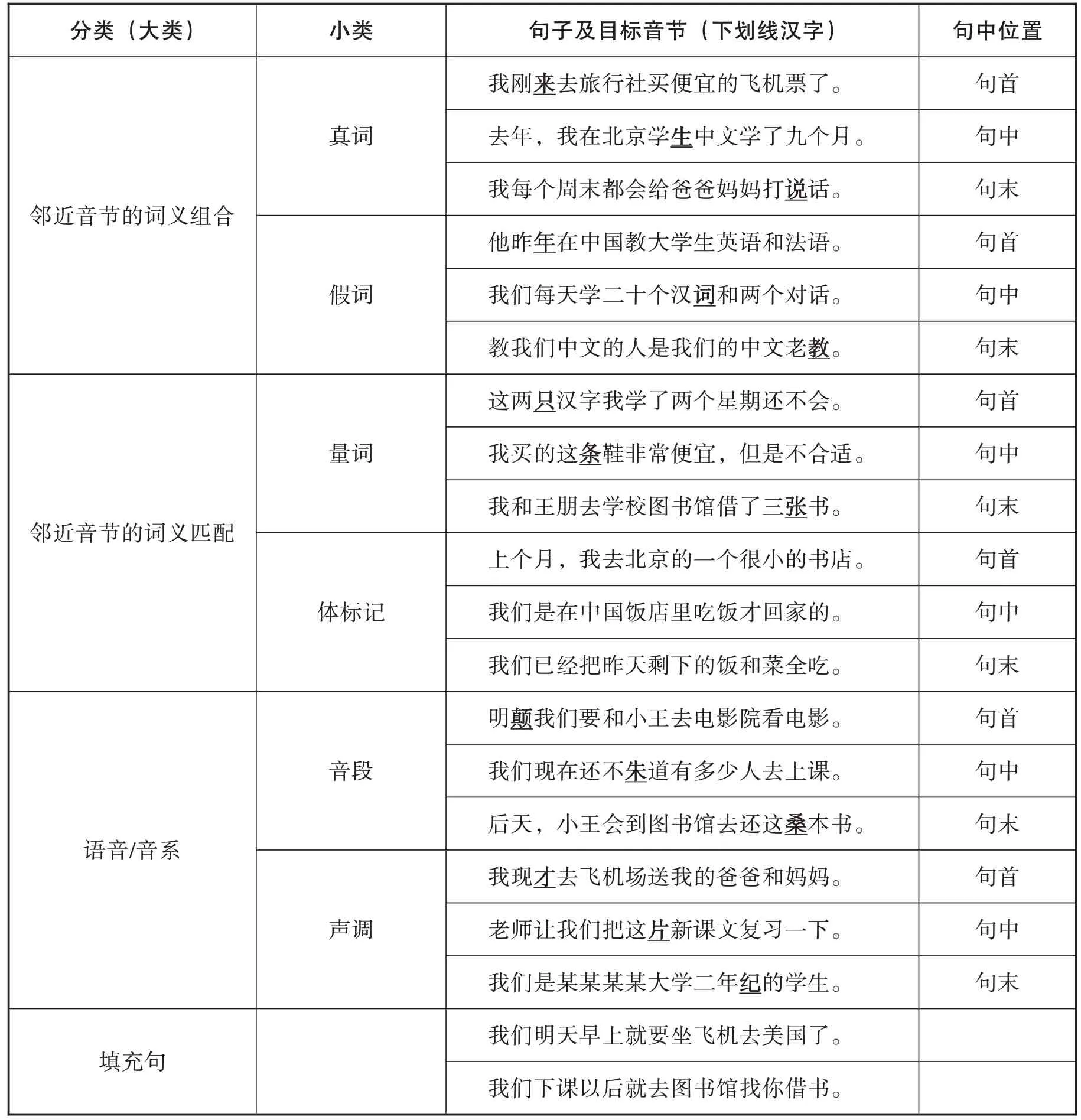
实验共设计了18 个实验句,另外还有2 个无意义的填充句(见附录)。每个句子有15 个音节。阅读句子的语速为200 毫秒/音节,比正常的语速略快。每个句子平均时长为3 秒。句子与句子之间的间隔为15 秒。每个句子之前有1秒的“嘟”声以提醒被试准备下一个句子。整个实验共计6分21秒。
句子中所有的词均从美国通行的一年级教材《汉语听说读写1》中选出,且句子中的刺激音为学习者所常用。句子内容基本与学习和校园生活有关,所以学习者较为熟悉。在实验前,一位具有中高级汉语水平的学习者听了所有的句子,并将其翻译成中文。其翻译基本正确。据该生反馈,18个实验句的难度基本相似。
每一个句子中有一个错误音节。句子中的错误音节分为三类(详见附录):1)错误音节与相对应的正确音节语音不同,但与邻近音节构成真词或假词,这些词与相对应的正确词的语义相关;2)错误或者丢失的音节与相对应的正确音节语音不同,但有聚合关系,其相对应的正确音节与邻近音节的语义匹配;3)错误音节与相对应的正确音节语音相似,只有一个同类的音段或者声调与相对应的正确音节不同。在每一类中,目标音节(也就是每个句子中的错误音节)分别位于句首、句中和句末(详见附录)。这是因为有些研究(例如Glisan,1985;Ito & Strange,2009)的结果显示,(超)音段或者音节在句子中所在的位置会影响感知。如果实验结果显示存在位置效应,那么我们会在位置效应的框架下进行讨论。但是,若无比位置效应,在数据分析中,位置效应就不在观察之列。在实验设计中,我们还加入了三类汉语特有的特征,量词、完成体“了”和声调,这三个特征是英语中没有的。
一位母语为北方方言的女性根据要求朗读了这20 个句子。她所朗读的句子被录音,然后让学习者听辨。录音的工具为一个Olympus LS-10 Linear PCM 录音机和一个Sony ECMMS907录音话筒。
2.3 实验步骤
40 位被试分别参加了本项研究,39 位被试按要求完成了所有实验。实验前,我们将详细的实验步骤告知每位被试。然后,他们使用Logitech USB 头戴式耳机听这20 个句子,并进行复述。被试被要求每听完一个句子后,立即复述所听到的每一个音节。不管句子内容如何,只需根据所听到的每个音节进行复述。被试的复述被录音。录音的工具为一个Olympus LS-10 Linear PCM 录音机和一个Sony ECMMS907 录音话筒。
2.4 数据分析
完成实验的39 位被试的录音被转写成汉字,填充句除外。对于不同语音或声调,本研究采用与该音节或声调语音相同的汉字转写,而该汉字的字义不做考虑,仅表示该音节的读音。
3.结果
3.1 位置效应
在18 个实验句中,6 个目标音节位于句首,6 个目标音节位于句中,另外6 个目标音节位于句末。
19 位母语者都完全复述了这些句子。除了体标记小类中57 个需要增补的目标音节外,其余无所遗漏。母语者共复述了342 个目标音节,其中包括原目标音节和85个被修复的音节。
20 位非母语者共听了360 个目标音节。然而,除了体标记小类中60 个需要增补的目标音节,有61 个目标音节在复述中丢失,只有239个目标音节被复述。加上体标记小类中的音节,被修复和准确复述的音节(其中包括体标记小类中准确跟述,即没有添加音节的数量)一共有282 个音节,这其中有171 个音节被修复。非母语者复述加修复的282 个音节,108 个位于句首,93个位于句中,81个位于句末。
目标音节被修复的百分比从被试的组别和句中的位置两方面分别做了对比,详见表1 。方差分析的统计结果显示,母语组在音节的位置上不存在显著差异,非母语组在音节的位置上也不存在显著差异。
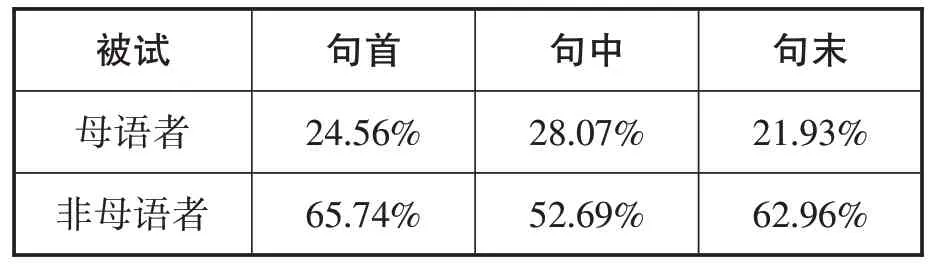
表1:目标音节在不同位置被修复的百分比
以上结果显示,母语者和非母语者对音节的感知不存在位置效应。所以,在后面的分析中,我们综合所有的数据,不考虑句首、句中和句末的情况,只根据母语者和非母语者的组别,以及目标音节的错误类型进行分析。
3.2 丢失的音节
如3.1 所述,19 位母语者听了342 个目标音节,除了体标记小类中57 个需要增补的目标音节外,其它285 个目标音节全部复述、无一遗漏。但是20 位非母语者听了360 个目标音节,除了体标记小类中60 个需要增补的目标音节,有61 个音节在复述中丢失。就丢失音节而言,方差分析的结果显示,母语组和非母语组之间存在显著差异(F(1,31)=14.493,p=.001)。这说明非母语者丢失的音节显著多于母语者。表2显示了根据目标音节分类,非母语者在复述中丢失音节的数量和百分比。
从上面词汇表中的词汇,不难看出,与之相关的听力材料是关于大学生交学期论文的事情。还能预测出某个学生没能按期提交老师布置的论文,并且为不能如期交作业找原因或借口。
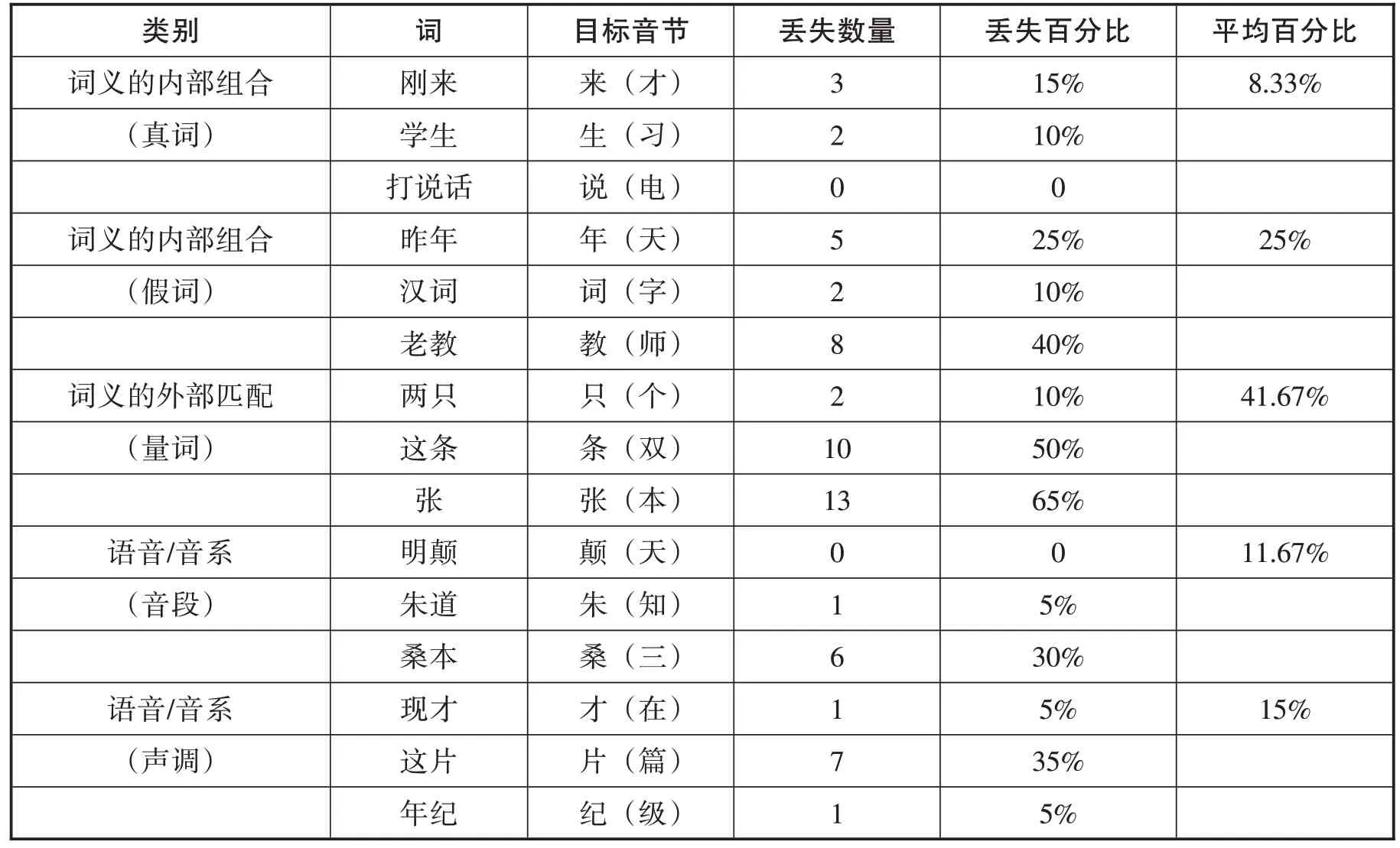
表2:非母语者复述中丢失音节的数量
结果显示假词和量词中的音节在复述中最易丢失。至少有25%的音节在这两类音节中丢失。根据表2,在假词类别中,有25%的音节丢失。假词是非母语者不熟悉的一类,所以较难复述。同时,近乎一半(41.67%)音节在量词类的音节中丢失。在声调类别中,有15%的音节丢失。这些结果表明,和汉语显著特征相关的音节,如量词、声调等,因为在英语中不存在,非母语者不熟悉,所以较难复述。
3.3 修复的音节
就修复的音节而言,根据方差分析,两组(母语与非母语) 之间存在显著差异(F(1,37)=52.692,p=.000)。换言之,非母语者在复述句子时,比母语者修复了更多的音节,且具有统计显著性。
表3 显示了每个目标音节被修复的数量和百分比。此表显示母语者一般不修复目标音节,但是他们却几乎修复了所有音段的错误(74%~100%)。同时,母语者也修复了少量声调错误的音节(21%~47%)。对于语音和语义都相近的音节,不管是真词还是假词,母语者有30%左右的修复率,比如真词小类中的学生(习)和假词小类中的汉词(字)。
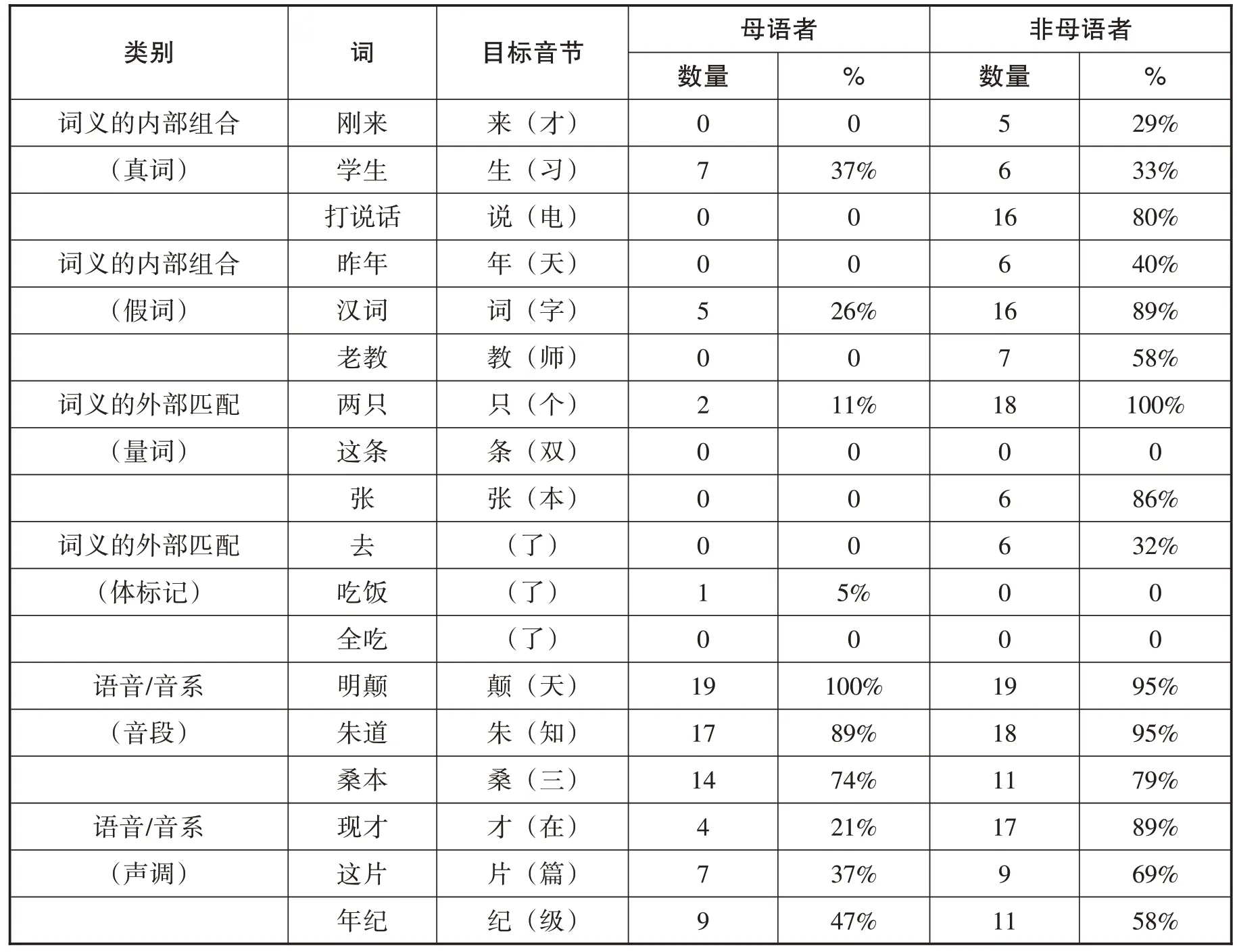
表3:被修复音节的数量
表3 亦显示了非母语者修复音节的情况。学习者在每个类别中都修复了很多音节,除了体标记和量词“条”。可能的解释是,与体标记相关的音节在原句中并未出现,而学习者对于汉语的体标记也并不熟悉,所以容易忽略。至于量词“条”,可能是非母语者对潜在的被修复词不太熟悉,所以其修复率很低。
我们用方差分析比较母语者修复的三大类音节,即实验设计时考虑的三类音节错误:1)邻近音节的语义组合错误,即错误的目标音节与邻近音节构成的真词或假词,和修复后的音节语义相关;2)错误音节与修复后的音节有语义聚合关系,修复后的音节与邻近音节的语义匹配;3)语音/音系错误,即错误的目标音节与修复后的音节语音相似。这三类错误 的 修复具有统计显著性 (F(2,54)= 59.874,p=.000)。Post Hoc Test 显示邻近语义组合错误的修复和音系错误的修复之间具有统计显著性(p=.000),邻近语义匹配错误的修复和音系错误的修复之间亦具有统计显著性(p=.000)。然而,邻近语义组合错误的修复和邻近语义匹配错误的修复之间没有显著差异。这个结果表明,母语者修复的与音系错误有关的音节远多于与语义相关的音节。但是其声调修复率较低,尤其是“才”和“在”。由于与“在”相对应的声调错误(阳平)的汉字不存在(此处用音近汉字“才”表示错误音节),母语者较易辨认,所以修复率比其它声调更低。
我们用方差分析比较非母语者修复的三大类音节。这三类错误的修复具有统计显著性(F(2,57)=51.429,p=.000)。Post Hoc Test 显示邻近语义组合错误的修复和音系错误的修复之间具有统计显著性(p=.000),邻近语义匹配错误的修复和音系错误的修复之间具有统计显著性(p=.000),邻近语义组合错误的修复和邻近语义匹配错误的修复之间亦具有统计显著性(p=.000)。这个结果表明,非母语者修复的与音系错误相关的音节远多于语义组合错误的音节数,而语义组合错误的音节数又多于语义匹配错误的音节数。
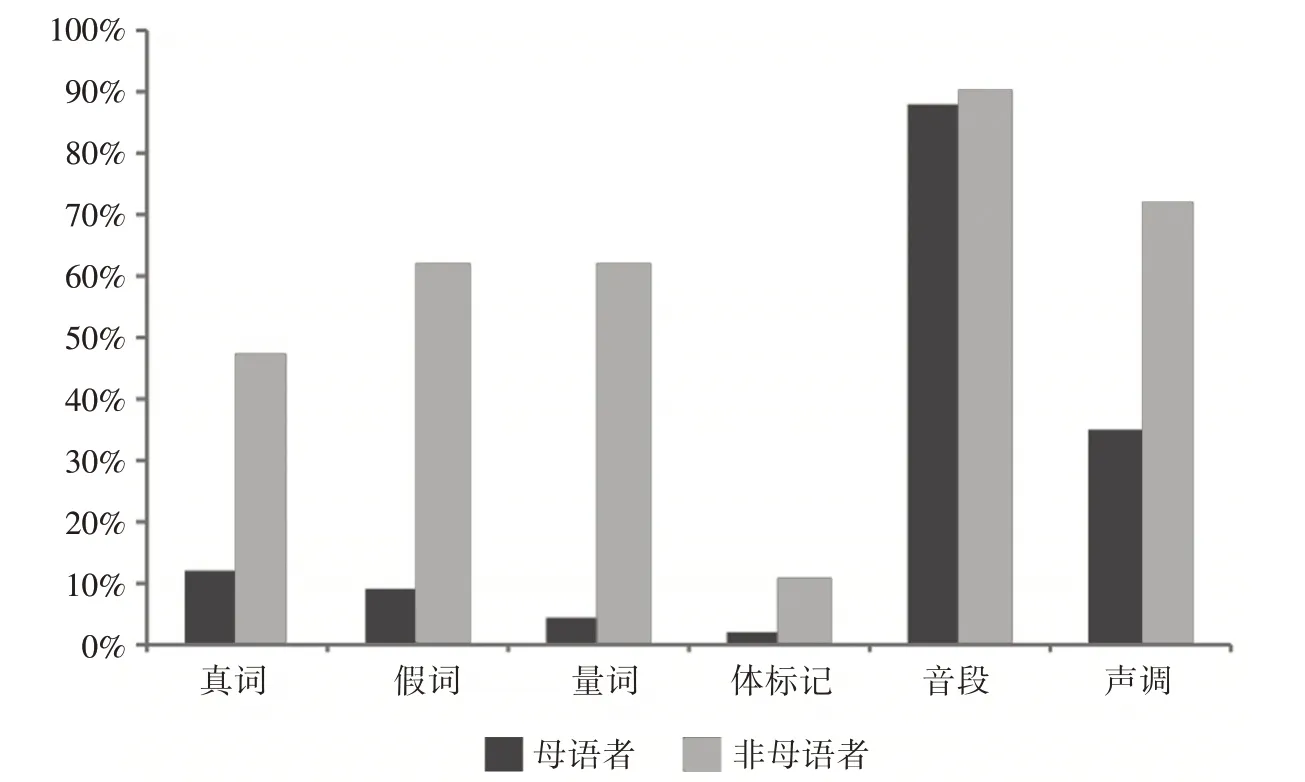
图1:母语者和非母语者的音节修复比较
图1 比较了母语者和非母语者在各错误小类中修复音节百分比。如图所示,母语者和非母语者都修复了90%左右的音段错误的音节。与其它小类相比,在体标记小类中,母语者和非母语者的修复率都是最低的,但是非母语者的修复率还是高于母语者。在真词、假词、量词和声调小类中,非母语者修复率却远高于母语者的修复率。
我们用方差分析比较母语者和非母语者修复的每个大类的音节数。就邻近语义组合错误而言,母语者的修复数和非母语者的修复数存在显著不同 (F(1,37)=66.162,p=.000);就邻近语义匹配错误而言,母语者的修复数和非母语者的修复数存在显著不同 (F(1,37)=41.824,p=.000);就语音/音系错误而言,母语者的修复数和非母语者的修复数无显著不同。进一步的分析发现,就音段错误而言,母语者的修复数和非母语者的修复数无显著不同;但是,就声调错误而言,母语者的修复数和非母语者的修复数存在显著不同 (F(1,37)=8.693,p=.006)。
4.讨论
4.1 母语者和非母语者的异同
在感知过程中,自上而下和自下而上加工是同时处理的。在本研究中,由于语速较快,对于自下而上的处理相对而言有一定的难度。故母语者和非母语者的表现有异同。
母语者和非母语者相同之处在于,他们都修复了90%的音段错误。这说明母语者和非母语者都没有通过自下而上加工提取所有的语音特征来辨别音节,而是通过自上而下加工为其提供了补偿。这与早期音位修复(phoneme restoration) 实验的结果 (Warren,1970;Warren&Warren,1970;Samuel,1981) 相同。在连续话语的感知中,如果语境信息足够预测表层信息,母语者自上而下的加工信息,如语法、词义等就会补偿自下而上信息(如音段特征)的不足,自动修复音段的缺失或错误。
母语者和非母语在本实验的感知中有两处不同,体现了他们自下而上处理能力上的不同。第一,非母语者丢失的音节数远大于母语者。主要体现在假词、量词和声调这三小类里。这与非母语者有限的长期记忆和短期记忆相关(详见4.2)。第二,除了音段小类,非母语者修复的音节数远大于母语者。这说明母语者在其它小类的感知中,自上而下处理比较彻底,所以他们可以分辨出具体的音节,并没有根据自上而下的加工信息做修复;但是非母语者自下而上的处理能力有限,所以根据自上而下的加工信息修复了音节,补偿了自下而上加工的不足。这体现了非母语者自下而上加工的薄弱,4.2和4.3详细分析了哪些(接近)表层的因素影响了非母语者自下而上的加工。以上两点不同之处,为非母语者学习汉语提供了具有实证研究基础的教学建议(见4.4)。
4.2 非母语者的长期和短期记忆
非母语者对相关因素的熟悉与否,决定了长期和短期记忆的存取(Baddeley,2003)。例如,假词和汉语特有的特征(量词、声调等)容易被忽略,所以在复述中这类音节会被丢失。就假词而言,母语者和非母语者都不熟悉,不存于他们的长期记忆中。但是母语者可以完全复述,而非母语者却大量丢失。这说明两者的短期记忆不同,非母语者需要在短期记忆方面多加训练。就量词而言,母语者是熟悉的,而非母语者因其母语中没有所以不熟悉。在非母语者的长期记忆中,量词这个新的范畴刚刚建立或者还未完善,所以非母语者在长期记忆中获取相关的信息比母语者弱,再加上非母语者短期记忆的有限性,其丢失的相关音节比假词更多。
除了音段小类,非母语者修复的音节数远多于母语者。这表明非母语者没有感知到表层或者接近表层的特征细节;或者感知到了这些细节,但是由于短期记忆存储空间有限,所以获取的信息不全或者很快就被释放了。因此,他们用自上而下加工补偿了这些信息。因为本实验中句子的语速比一般语速快,所以非母语者部分获取或者完全没有获取目标音节的信息是正常的;但是母语者的短期记忆比非母语者强,所以他们可以顺利地获取完整的目标音节信息,并准确地复述目标音节而不做任何修复。这揭示了非母语者在感知中缺乏用表层或者较“下层”的语言学知识(如声调、邻近音节的语义关系等)来获取(接近)表层的信息,所以只能用“上层”的语境信息(如整个句子的语义结构等)来补偿表层目标音节的信息。
综上所述,我们发现非母语者无论在长期记忆还是短期记忆上都比较薄弱。从音节丢失和音节修复两个方面来看,短期记忆的有限是其主要因素,更需加强。
4.3 非母语者自下而上的加工
如果非母语者成功地修复了一个音节,这说明他在自上而下加工中,根据语境,在语义或者语音相近的音节中选择了合适的心理表征(mental representation),但同时他从自下而上加工中获取原目标音节的相关信息却失败了。这表明非母语者在自下而上的加工方面需要更多训练。
母语者很少修复音节,但是非母语者修复的却比较多。其修复的音节有两类。第一类是与邻近音节的语义相关而与整个句子语义相悖的目标音节。对母语者而言,这类音节不易被修复,但是,非母语者却容易修复。例如“我每个周末都会给爸爸妈妈打说话”,母语者没有修复目标音节“说”,但是80%的非母语者修复了它。这说明“下层”的邻近音节的词义信息并未被大多数非母语者完全获取,从而影响了表层音节的输出,所以他们在自上而下的加工中,从临近语境中的信息补偿了自下而上加工中未准确获取的(接近)表层的信息。因此,最后大多数非母语者修复了这个目标音节。
第二类是声调错误的音节。在孤立情况下,赵荣等(2016)的实验表明,母语者在汉语音节感知中对声调的敏感性不及韵母。而在连续话语中,本实验的结果表明,对母语者而言,声调的影响要略强于音段,当然音段这个单位是小于等于韵母的。但是对非母语者而言,声调的影响并不大。例如,“老师让我们把这片新课文复习一下”,部分母语者修复了目标音节“片”,但是几乎两倍(79%)的非母语者修复了它。这说明“下层”的声调信息并未被大多数非母语者完全处理,从而影响了表层音节的输出,所以他们在自上而下加工中,用语境的信息补偿了自下而上加工中未准确获取的音节信息。这说明非母语者对声调信息的自下而上的加工处理明显弱于母语者。
综上所述,我们发现非母语者在自下而上的加工处理过程中,容易忽略的“下层”信息主要是超音段信息和受邻近音节语义干扰的信息。但是非母语者可以在自上而下的加工处理中,以整个句子语境和语义结构补偿了这两个方面的不足。
4.4 教学建议
根据4.2 和4.3 的讨论,我们需要在教学上训练学生的短期记忆;同时,在训练自下而上加工时,需要着重于声调辨识和邻近音节的语义组合与搭配。因此,我们在教学方法上需要注意以下三点。
首先,采用不同的教学任务加强学生短期记忆和自下而上加工的心理机制。例如,本研究所使用的实验方法——跟述任务(shadowing task),即是一个非常好的训练自下而上加工、加强短期记忆的教学方法。要准确跟述一句句子,不仅需要自上而下加工,更需要自下而上的加工,否则很多细节会被忽略。老师可以根据学生的水平来决定跟述句子的长短、速度等。还可以根据教学目标,将需要学生注意的语言特征放入句中。同时,在学生跟述完一句句子后,老师需要及时指出学生跟错的音节,让学生重新跟述,这样可以帮助学生注意被自己忽略的细节,加强自下而上的加工。
其次,在声调的教学上需要采用音义结合的方法。传统的教学只注重声调的语音形式而忽略其语义。老师可以用声韵相同而声调不同的音节进行比字训练和辨义练习。
此外,我们还应该训练学生邻近音节的语义组合和搭配能力。例如在词汇教学中采用系联法,将新的字组合已学过的语义相近的音节一起学习,以避免混淆。我们也可以让学生根据语境选择词语,或者老师给出句子学生判断对错。在篇章教学中,让学生听一段话,并就细节处提问,请学生回答,或者给出一些音义相近的音节供学生选择。
总之,语流中音节的感知不是孤立的,需要掌握各种语言学知识并能熟练运用。音节的感知不仅需要自上而下的语境,更需要语音/音系、词义等来促进自下而上的加工处理。
附录:实验句子
分类(大类)邻近音节的词义组合邻近音节的词义匹配语音/音系填充句小类真词假词量词体标记音段声调句子及目标音节(下划线汉字)我刚来去旅行社买便宜的飞机票了。去年,我在北京学生中文学了九个月。我每个周末都会给爸爸妈妈打说话。他昨年在中国教大学生英语和法语。我们每天学二十个汉词和两个对话。教我们中文的人是我们的中文老教。这两只汉字我学了两个星期还不会。我买的这条鞋非常便宜,但是不合适。我和王朋去学校图书馆借了三张书。上个月,我去北京的一个很小的书店。我们是在中国饭店里吃饭才回家的。我们已经把昨天剩下的饭和菜全吃。明颠我们要和小王去电影院看电影。我们现在还不朱道有多少人去上课。后天,小王会到图书馆去还这桑本书。我现才去飞机场送我的爸爸和妈妈。老师让我们把这片新课文复习一下。我们是某某某某大学二年纪的学生。我们明天早上就要坐飞机去美国了。我们下课以后就去图书馆找你借书。句中位置句首句中句末句首句中句末句首句中句末句首句中句末句首句中句末句首句中句末
