基于域自适应与多子空间的人脸识别研究
2020-12-18韩晗,徐智
韩 晗, 徐 智
(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
人脸识别是近年来较为热门的研究方向,在公安、门禁系统和一些软件领域都有广泛的应用,但是其仍面临以下问题:1)训练数据和应用场景数据的分布存在差异;2)特殊领域的数据较难收集,并且标注图片是一项人力财力消耗巨大的任务,导致与应用场景分布相同的训练数据匮乏。
传统的机器学习方法如线性判别分析(LDA)、支持向量机(SVM)[1]能够较好地分类预测问题,但前提是假设训练数据和测试数据是从相同的分布中取样。当测试和训练数据来自不同域时,其性能将严重退化。为解决该问题,域自适应方法[2-3]将丰富的监督信息(源域)迁移到另一个不同但相关的领域(目标域)。子空间学习是域自适应的一种方法,文献[4]在保持数据的原始结构的同时,通过最小化源域和目标域之间的差异得到潜在的公共子空间。但上述方法只利用了源域和目标域的共同特征,忽略了目标域对分类任务有利的特定信息。文献[5]提出了一种TSD域自适应方法,带有标签的源域数据由公共子空间中的目标域数据(称为目标化源域)表示。TSD的公共子空间在较好地保持源域和目标域结构的基础上使源域和目标域数据具有良好的交融性。文献[6-7]提出多源域自适应方法,TMSD[8]是在TSD方法的基础上拓展为多源域的自适应方法,从多个源域迁移更为丰富的监督信息,从而提高模型的性能。
以上子空间方法使用的是单个子空间,当代价函数最小时,目标域表示的源域的最优结果是固定的,然而,单个子空间不能提供更为丰富的判别信息。为得到更多的判别信息,提出了一个域自适应的泛化学习框架,同一个样本在不同的子空间中能够获得不同的判别信息。首先,随机选择样本作为每个子系统的训练样本;其次,为每个子系统学习一个公共子空间,要求在公共子空间中源域和目标域特征能够很好地交融在一起,且域本身的结构也能较好地保留,用目标域数据进行线性组合来表示源域样本;然后,为每个子系统中新的源域数据学习一个判别模型;最后,通过多数投票与总和规则的策略将所有子系统结合起来得到最终的分类结果。实验结果表明,框架能够显著提高人脸识别的性能。
1 域自适应泛化学习框架
1.1 符号和定义
单源域中的源域样本为
其类别标签为
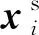
其类别标签为
多源域中,第i个源域的样本为

1.2 多子空间域自适应泛化学习框架
图1为多子空间域自适应泛化学习框架的示意图。框架分为训练部分和测试部分。在训练过程中,采用域自适应方法使源域的分布更接近目标域,然后在新的源域集上训练特征提取算法,提取特征子空间。具体步骤如下:
1)在源域和目标域数据集中随机选择样本,构造多个子数据集。
2)为每个子数据集学习公共子空间。
3)选择判别特征提取方法FLD进行特征提取:
其中:Sb为目标化源域的类间散布矩阵;St为目标域数据的总散布矩阵。

图1 域自适应泛化学习框架
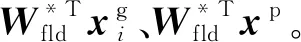
其中φ()为特征提取函数。通过统计所有子系统的识别数据得到最终的识别结果。
1.3 域自适应学习方法
采用公共子空间域自适应学习方法,TSD和TMSD分别作为单源域和多源域的域自适应方法。公共子空间需要满足2个条件:1)源域和目标域样本之间较好地融合,以减小域间的差异;2)保持源域和目标域的结构,以保持丰富的判别信息。使用稀疏重建[9]和最大方差来满足以上2个条件。稀疏重建能够使源域与目标域更好地满足统一分布,而最大方差则是为了保留域本身的特性。
由于源域和目标域可能存在较大差异,甚至数据分布在不同的空间,将源域和目标域分别投影到一个公共子空间中。单源域中,公共子空间中的样本分别表示为:
稀疏重建和最大方差表示后的目标函数为
其中,Vs、Vt为稀疏矩阵。由于上式中并非所有变量都为凸变量,对稀疏矩阵Vs、Vt和投影矩阵Ws、Wt进行迭代求解,直到投影矩阵和系数矩阵收敛或者达到最大迭代次数。所求得的目标化的源域数据为
为了能够从多个源域中迁移更丰富的监督信息,TMSD在TSD方法的基础上扩展为多源域自适应学习方法,源域数为s,目标域数为s+1,总目标函数为


1.4 结合策略

(1)
对式(1)进行均值化和标准归一化,即

其中rki为第k个子系统输出的后验概率值,作为每个类别的一个分值。结合所有子系统的输出值得到xp的最终标签。
多数投票:每个子系统都会输出一个xp的类别标签,综合各个子系统,相同标签最多的作为xp的最终标签。
其中Labelk(xp)为第k个子系统中xp的识别结果。
总和策略:对每个子系统输出的类分值加和,最大分值所对应的标签为probe的最终标签。
2 方案的合理性
在域自适应泛化学习框架中,通过训练一个不包含所要识别类别的数据集,得到一个人脸识别模型。在一般的分类任务中,分类器的学习需要大量样本,但随着样本的增多会导致数据维度的增加,从而使计算复杂度呈指数级上升。因此,本框架通过多个子数据集学习,提高模型的整体效率;同时,不同样本的随机组合可以形成不同的特征空间,同一样本在不同的特征空间中保留不同的识别信息,从而获得更多的识别信息。
方案的合理性:
类内散布矩阵Sw和类间散布矩阵Sb分别是描述类内变化和类间变化特性最重要的2个参数,换句话说,几乎所有的分类方法通过对Sw、Sb或者总散度矩阵St=Sb+Sw进行特征值分析,然后求出特征向量,形成变换矩阵,对Sw和Sb的准确估计对识别性能有着至关重要的影响。性能越好,类内散布矩阵的特征值越小,而类间散布矩阵的特征值越大,但随着特征值的增大,相应特征向量的估计方差也随之增大,这同样会对识别性能产生负面影响,文献[10]进一步证明了这一点。因此,将一组弱学习器结合起来,可以提高类间的差异判定和识别能力。
3 实验和结果
3.1 实验参数设置
实验使用MultiPIE[11]数据集,根据人工标记的眼睛位置对齐面部图像,并在多像素设置中将图像标准化为40像素×32像素,通过堆叠原始像素,将每个图像调整为列向量,只有源域的数据带有类别标签。用主成分分析(PCA)分别对源域和目标域降维处理。根据经验,投影矩阵的列大小设置为300,τ、λ分别设置为3、0.05。所有结果均为10次试验的平均准确度。MultiPIE数据集包含337个类别,在各种姿势、照明和表情下的图像超过750 000张,示例图像如图2所示。根据人脸的拍摄角度(-45°、-30°、0°、30°、45°)分为5个子集,每个子集使用200个类别,每个类别随机选取7张进行训练。剩下的137个类别中,每个类别随机选择1张作为图片库样本数据,4张作为测试样本进行测试。
在实验中,所有的训练源域数据都给出了类别标签,而目标训练数据则未给出类别标签。为了更好地与其他实验进行比较,进行了4组不同的实验:1)200个类别中,每个类别随机选取4幅图像;2)200个类别中,每个类别随机选取5幅图像;3)随机选取100个类别,每个类别7幅图像;4)随机选取150个类别,每个类别7幅图像。

图2 MultiPIE
3.2 参数影响
主要测试3个参数的影响:子系统数;当类别数为200时每个类别的样本数;当每个类别的为7时的类别数。选择0°和45°作为单源数据集上的源域和目标域时,人脸识别率如图3、图4所示。从图3、图4可看出,在多数票和总和规则2种策略下,随着子系统数量M的增加,识别率呈上升趋势,当M趋于20时呈现平稳;M>20时,人脸识别率的变化值在0.8%以内;M<20时,2种策略都表明,样本数为5时的性能优于取值为4时的性能,类别数为150时的性能优于取值为100,这是由于样本数的增加有助于减少Sw和Sb的估计方差,从而增强置信度的可靠性。随着M越来越大,样本数的增加会降低子系统间的多样性,从而导致性能下降,但是差异很小。为考虑整个模型的高效性,在实验中M分别取10、15和20。单源域自适应泛化学习框架中,选择样本数为5,类别数为150;在多源域中,样本数为4,类别数为100。

图3 多数投票下的识别率

图4 总和规则下的识别率
3.3 实验验证与分析
将框架应用于域自适应方法,并对其性能进行比较。为了证明该方法的通用性,分别对单源域自适应方法和多源域自适应方法进行比较。
实验结果中,maj10表示10个子系统的多数投票策略识别结果,sum10代表总和规则策略识别结果。-45,45分别表示源域为-45°和目标域为45°;0,30_45表示2个源域分别为0°、30°,目标域为45°。
3.3.1 单源域自适应泛化学习框架
单源域框架与TSD进行比较。表1为当训练样本类别总数为200时每个类别随机选取5张图片时的识别率。表2为随机选取150个类别,每个类别为7张图片时的识别率,从表1、表2可看出,与TSD方法相比,本框架几乎在所有情况下表现更好;本框架设计的2种结合策略中,多数投票优于总和规则,特别是当子系统数量≥10时,所有识别结果均优于TSD,最佳性能可提高2.65%。在总和规则中,当子系统值≥15时,该框架优势较为明显。总体而言,多子空间泛化学习框架一方面有利于保留更多的判别信息,另一方面通过选择相关的组合策略提高了识别结果的可靠性。

表1 单源域每个类别随机5张的识别率 %

表2 单源域随机150个类别的识别率 %
3.3.2 多源域自适应泛化学习框架
在相同的参数设置下,多源域框架与TMSD进行比较,结果如表3、表4所示。从表3、表4可看出,多源域框架的识别性能均有所提高,这是由于增加源域能够提供更多的判别信息,并增加了样本的多样性,即便是每个类别样本数量仅有4张或者随机选择100个类别的样本,性能依然有较大提升。
4 结束语
针对人脸识别问题,提出了一种域自适应的泛化学习框架,通过随机抽取样本,在公共特征空间中将源域数据转换为目标域数据,采用2种策略得到最终的标签类别。由于同一样本在不同的特征空间中保留不同的判别信息,性能有所提升。对单域和多域的评估表明,框架优于其他域适应方法。此外,实验结果表明,不同的集成策略对识别性能有影响,下一步将改进集成策略以获得更好的识别性能。

表3 多源域每个类别随机4张的识别率 %

表4 多源域随机100个类别选择的识别率 %
