基于门控循环单元的图像描述方法
2020-12-18王少晖莫建文
王少晖, 莫建文
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
图像描述能够使计算机生成与图像内容对应的描述性语句,这种计算机“视说能力”倍受研究人员青睐。20世纪90年代就有了相关的研究[1],由于当时计算机计算能力的局限性,该技术的研究与发展受到了限制。近年来,计算机的计算能力得到飞跃的提升,图像描述的研究得到有力支持,再次成为研究热点。
随着神经网络在许多领域取得卓越成果,研究人员将卷积神经网络[2](convolutional neural networks,简称CNNs)和循环神经网络[3](recurrent neural networks,简称RNNs)引入到图像描述任务中,实现了图像语义特征的提取和语义特征语句的构建,这种基于神经网络的网络模型简称为CNN-RNN模型。Mao等[4]最先采用CNN-RNN模型,其中CNN子网负责图像的特征提取,RNN子网将CNN子网提取的特征作为辅助信息生成语句,值得一提的是该方法中RNN子网仅是传统的RNN。Vinyals等[5]提出的方法中使用长短期记忆网络[6](long short-term memory,简称LSTM)代替RNN来生成语句,训练网络时出现的梯度消失和爆炸[7]状况得到了改善。Karpathy等[8]在RNN子网中采用了一种改进的LSTM,称为双向长短期记忆网络[9](bi-directional long short-term memory,简称BLSTM),并通过该网络构建了更紧密的映射关系。Wang等[10]借助斯坦福句法分析器将语句分解为结构和属性,用2个LSTM组成RNN子网分别生成结构和属性,根据先验知识得到描述性语句。为了使图像描述更快地生成语句和更高效地利用计算机资源,针对LSTM中采用3个门分别控制信息的传递方式过于复杂的问题,在Vinyals等[5]的方法中引入门控循环单元,提出一种基于门控循环单元的图像描述方法。
1 LSTM
LSTM的内部结构如图1所示。
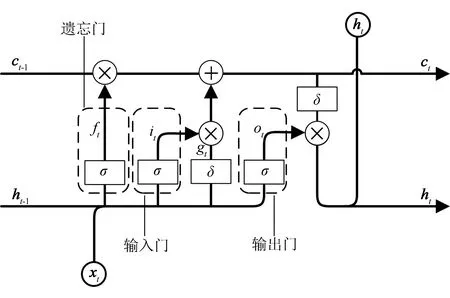
图1 LSTM的内部结构
LSTM内部结构有单元状态c和状态h两个隐含状态,遗忘门、输入门、输出门3个门。LSTM的内部运算为3个门对信息的处理。
1)假设当前LSTM处于t时刻且输入为xt,前一时刻单元状态ct-1的信息保留,遗忘门读入当前输入xt和前一时刻隐含状态ht-1,通过计算得到ft∈[0,1],ft控制单元状态ct-1信息保留程度,即
ft=σ(Wf[ht-1,xt]+bf)。
ft=1时表示信息完全保留,ft=0时表示信息完全丢弃,σ(·)为Sigmoid激活函数,保证了输出为0~1的实数。
2)输入xt,保留前一时刻隐含状态ht-1的信息,输入门读入当前输入xt和前一时刻隐含状态ht-1,通过计算得到it,it∈[0,1],it通过对输入xt和前一时刻隐含状态ht-1的新表示形式gt进行操作来控制输入xt和前一时刻隐含状态ht-1的信息保留程度,即
it=σ(Wi[ht-1,xt]+bi),
gt=δ(Wg[ht-1,xt]+bg),
其中δ(·)为Tanh函数。
3)更新单元状态ct-1,将遗忘门操作后的单元状态ct-1与输入门操作后的gt相加得到t时刻单元状态ct,
ct=ftct-1+itgt。
4)输出门读入当前输入xt和前一时刻隐含状态ht-1,通过计算得到ot∈[0,1],ot对经δ转换的当前时刻单元状态ct进行保留操作,得到LSTM的t时刻输出ht,
ot=σ(Wo[ht-1,xt]+bo),
ht=otδ(ct)。
LSTM的门结构减缓了梯度消失或爆炸,但也增加了RNN子网的时间复杂度和空间复杂度。通过3个门逐一对信息的处理增加了计算量,各自的权重和偏置需要占用更多的计算机资源。
2 基于门控循环单元的图像描述
2.1 门控循环单元
门控循环单元[11](gated recurrent unit,简称GRU)的内部结构如图2所示。
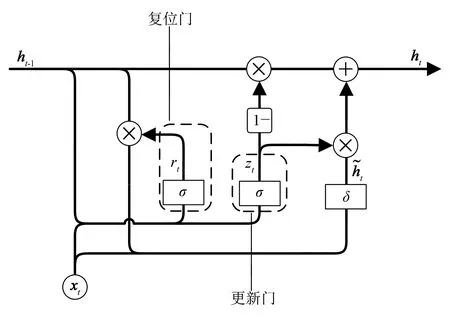
图2 GRU的内部结构
从图2可看出,仅需计算隐含状态h和复位门、更新门。
1)当t时刻的输入xt传入GRU时,首先保留前一时刻隐含状态ht-1转换为候选信息前的信息,复位门读入当前输入xt和前一时刻隐含状态ht-1进行计算得到的rt∈[0,1],rt控制前一时刻隐含状态ht-1的信息保留程度,即
rt=σ(Wr[ht-1,xt]+br)。
zt=σ(Wz[ht-1,xt]+bz),
其中δ(·)为Tanh函数。
3)对前一时刻隐含状态ht-1进行更新,更新门的输出zt减1后,将前一时刻隐含状态ht-1控制后的结果与更新门保留操作后的候选信息ht相加,得到GRU的t时刻输出ht,
循环神经网络中,运算量主要集中在各个门权重矩阵与输入的乘法上,因此在计算时间复杂度时将门的运算量记为N,则LSTM的时间复杂度为4N,GRU的时间复杂度为3N。占用存储空间的参数主要是由隐含状态和门的权重、偏置组成,隐含状态参数个数与门总的参数个数相近,因此在计算空间复杂度时将隐含状态和门的空间复杂度记为S,则LSTM的空间复杂度为5S,GRU的时间复杂度为3S。
在LSTM与GRU的内部结构、运算过程分析和复杂度比较中,显然GRU的内部结构更为简洁,运算过程更为高效,复杂度更有优势,因此GRU可以有效地优化内部运算过程,减少RNN子网的网络参数。通常,网络在运行时需要将参数加载到内存中,因此减少参数个数会使网络占用的内存相应减少。考虑到GRU的这些优点,引入GRU作为RNN子网的循环神经网络,通过优化RNN子网来提高网络的实时性,减少网络消耗的计算机资源。为了突显方法的有效性,在Vinyals等[5]的方法基础上进行改进,设计了基于门控循环单元的图像描述网络。
2.2 基于门控循环单元的网络结构
基于门控循环单元的网络结构如图3所示。CNN子网与Vinyals等[5]的方法相同,使用的是Google研究团队提出的Inception v3,而RNN子网与Vinyals等[5]的方法不同,使用的是GRU这种循环神经网络。

图3 基于门控循环单元的网络结构
网络的运算过程分为2步:
1)CNN子网将待描述的图像I经前向传播生成图像语义特征向量Ie。

Ie=CNN(I),h0=GRU(Ie,0),
其中:I为输入图像;CNN(·)为CNN的前向传播计算;Ie为输入图像I经CNN前向传播计算后生成的图像语义特征向量;GRU(·)为GRU的前向传播计算;h0为0时刻隐含状态;E为词嵌入矩阵;W、b分别为输出层的权重、偏置;t=1,2,…,n。
网络训练时,CNN子网将图像作为输入样本,将图像对应的语句标签P作为监督信号,则损失函数为
3 实验设计及结果分析
网络验证时,采用主流的MSCOCO数据集进行网络训练和测试[12]。网络性能的衡量采用BLEU、METEOR、ROUGE和CIDEr这4种评估方式,其中BLEU由B@1、B@2、B@3和B@4组成。
为了更好地比较性能,采用与NIC[5]相同的训练方式和超参数设置。训练完成后,生成的示例如图4所示。从图4可看出,本方法生成的描述性语句能够简洁地反映出图像内容。

图4 本方法生成的示例
客观性能评估方面,将本方法(inception v3+GRU)与Deep VS、m-RNN、NIC(inception v3+LSTM)在MSCOCO测试集上进行比较,得到性能评价如表1所示。

表1 4种方法在MSCOCO数据集上的性能评价
从表1可看出,本方法在7种评估方式中的评分比Deep VS、m-RNN有明显优势;与NIC(改进前的方法)在小数点后一位依然保持一致,因此这2种方法整体生成的语句质量相差甚微,实际上,在训练时这2种方法的收敛情况并无显著区别,具体收敛情况如图5所示。

图5 2种方法的收敛情况
从图5可看出,在10×105次迭代中2种方法得到的曲线基本重合,即收敛情况相当,本方法与NIC[5]方法在生成语句的整体质量及其收敛情况无法分出高低,但在生成语句时消耗的时间以及占用的计算机资源存在明显差异,本方法中RNN子网生成语句时消耗的时间和占用的内存均少于NIC方法。2种方法在不同模式下RNN子网生成语句消耗的时间如图6所示。

图6 2种方法中RNN子网消耗的时间
从图6可看出,2种方法都远远超过了各自CPU模式所消耗的时间,本方法无论在CPU模式下还是GPU模式下RNN子网生成语句消耗的时间都更少。2种方法RNN子网生成语句的平均时间和参数个数如表2所示。

表2 2种方法RNN子网生成语句的平均时间和参数个数
从表2可看出,CPU模式下,本方法RNN子网生成语句的平均时间比NIC方法减少了0.03 s,占NIC方法平均时间的3.15%;GPU模式下,本方法RNN子网生成语句的平均时间比NIC方法减少了0.01 s,占NIC方法平均时间的2.5%;参数个数方面,本方法减少了25%,通过参数个数的大幅度减少,使得网络运行时占用的内存相应地减少。
4 结束语
将门控循环单元引入图像描述任务中,提出了一种基于门控循环单元的图像描述方法。该方法有效地解决了RNN子网生成语句时消耗时间较长和网络运行时占用的内存较大的问题。在生成语句的性能评估中,本方法生成的语句质量仍然保持原方法的水平,且生成语句消耗的时间显著减少,其中CPU模式下仅需0.92 s,GPU模式下仅需0.39 s;同时,通过减少RNN子网大约77万个参数的方式,使得网络运行时占用的内存更小。
