基于RT-RBM协同过滤的图书馆个性化推荐系统的研究
2020-12-18郭新华林玉梅
郭新华,高 禹,林玉梅
(泉州信息工程学院 软件学院,福建 泉州 362000)
0 引言
当前图书馆正朝着智慧化的方向发展,其中图书馆的个性化推荐更是图书馆智慧服务的重要组成部分.图书馆资源利用情况关键看读者对馆藏资源的使用程度,所以要加强图书馆的智慧服务,特别是加强对读者的个性化推荐.
近年来个性化推荐技术被应用到很多领域,电商平台如淘宝、京东、唯品会等,及影视推荐平台如优酷、芒果、腾讯视频等.很多图书馆的推荐系统也采用了个性化推荐技术,这也逐渐成为近些年研究的热点.目前基于内容推荐、基于协同过滤的图书馆的推荐系统是占大多数的,比如王波提出了基于内容导向的图书馆知识服务模式研究[1],张麒麟等提出了基于文献内容的图书推荐机制研究[2],车毅光等提出了基于内容过滤的数字图书馆推荐系统研究[3],王仲钰等提出了基于协同过滤和关联分析的图书推荐系统[4],安德智等提出了基于协同过滤的图书推荐模型[5],席欢提出了基于协同过滤的高校图书推荐系统设计探析[6],还有混合推荐算法,如Ozbal等提出了一种基于内容提升的协同过滤算法,协同过滤算法的数据稀疏性问题得到了一定的解决[7].
目前图书馆的推荐系统基于内容的推荐技术和基于协同过滤的推荐技术占多数,都存在一些缺点.基于内容推荐存在的问题:1.item(产品)的特征抽取一般较难,如特征难以抽取、抽取不精准、无法区分抽取出来的特征完全相同的item;2.无法挖掘出用户的潜在深层次的兴趣,即个性化的推荐;3.无法为新用户产生推荐.协同过滤存在的问题:1.“冷启动”问题,没有历史数据的情况下较难对用户进行较好的推荐;2.忽略情景差异、小众喜好,即忽略了读者的潜在的个性化的特征.无论是基于内容推荐、基于协同过滤的推荐技术都存在共同的问题:只统计、分析了读者大众特征,而忽略读者潜在的个性化的特征;无法为新用户产生推荐.为了改进图书馆的推荐系统,本文提出基于实值的受限玻尔兹曼机及Top N算法(RT-RBM)的协同过滤的图书馆个性化推荐系统.
1 RT-RBM协同过滤的图书馆个性化推荐系统
1.1 协同过滤算法
协同过滤(Collaborative Filtering)作为诞生最早最经典的一种推荐算法,主要是用于预测和推荐.这种算法是基于用户历史性的行为数据,进行挖掘与分析,发现用户的偏好,再根据不同偏好对用户进行以群组的方式进行划分,并为用户推荐相似或相近的商品.在协同过滤推荐算法中常见的类型除了基于user-based(用户)的、基于item-based(项目)的,还有一种是基于model based(模型)的,本文所介绍的就是后者.基于模型的协同过滤作为目前主流的协同过滤类型之一,要解决利用历史的数据来预测未评分物品的评分,且把得到的最高评分物品列表推荐给用户.对于上面的问题,可以用机器学习来建模解决,常见的主要方法可分类为:关联算法、聚类算法、神经网络,还有图模型、分类算法、矩阵分解、回归算法以及隐语义模型.本文所采用的是基于神经网络来做协同过滤.
1.2 受限玻尔兹曼机
深度学习是机器学习研究中的一个新的领域,是指在多层神经网络上利用不同的机器学习算法解决如图像、文本等各类问题,可以看作是一个框架算法的集合.深度学习从大类上可以归为神经网络,它的核心为特征学习,利用低层特征的组合形成更加抽象的高层,来表示属性类别或特征,来得出数据的分布式特征表示.深度学习可以看作是一个框架,包含多个重要算法: CNN(卷积神经网络)、AutoEncoder自动编码器、Sparse Coding稀疏编码、 RBM(受限波尔兹曼机)、 DBN(深信度网络)、RNN(多层反馈循环神经网络).
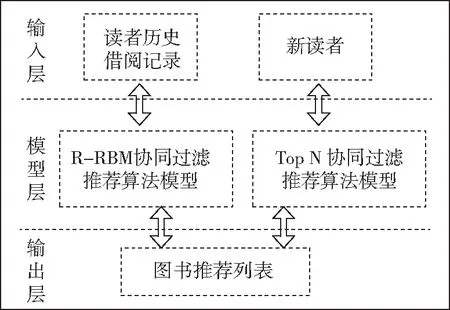
图1 RT-RBM的协同过滤的图书馆个性化推荐系统框架
近来年,国内外不少学者把深度学习的技术应用到推荐系统中并进行了研究,其中受限波尔兹曼机也逐渐成为近几年的研究热点.在波尔兹曼机基础上, Smolensky于1986 年提出受限波尔兹曼机,是一种生成式的随机神经网络,也是一种概率图模型.这里的随机指的是网络中的神经元是未激活或激活这样的两种状态,即随机,可以用0和1(二进制)来表示,这两种状态的取值由概率分布函数来决定.RBM在推荐系统也有一定的研究成果,如刘宇宁等提出了基于RBM模型的豆瓣小组推荐系统设计与实现[8],郑志蕴等提出了一种基于云计算的受限玻尔兹曼机推荐算法研究[9],李飞等提出了一种基于权值动量的RBM加速学习算法研究[10],孙天凯等提出了一种基于对称受限玻尔兹曼机的协同过滤算法[11].为了改进图书馆的个性推荐系统的功能,本文提出了RT-RBM的协同过滤的图书馆个性化推荐系统.
1.3 RT-RBM的协同过滤的图书馆个性化推荐系统框架
RT-RBM的协同过滤的图书馆个性化推荐系统框架可分为三层:分别是输入层、算法模层、输出层.输入层输入的数据分为两种情况,一种是读者的历史借阅记录,另一种是新读者;算法层模型根据输入层的数据情况分别由两种子算法模型组成,一种为R-RBM协同过滤推荐算法模型,另一种为Top N协同过滤推荐算法模型,这两种模型分别处理读者的历史借阅记录和新读者的情况.输出层用于输出图书推荐列表的结果.RT-RBM的协同过滤的图书馆个性化推荐系统框架如图1所示.
2 RT-RBM的协同过滤的图书馆个性化推荐算法
RT-RBM的协同过滤的图书馆个性化推荐算法由两种子算法模型组成,一种为R-RBM协同过滤推荐算法模型,另一种为Top N协同过滤推荐算法模型,这两种模型分别处理读者的历史借阅记录和新读者的情况,下面就分别介绍这两种算法.
2.1 R-RBM协同过滤推荐算法
2.1.1 RBM模型原理
受限波尔兹曼机(RBM)包含可见层(visible layer)、隐藏层(hidden layer) 两个层.所有神经元的连接具有层间全连接而层内无连接的特点.其中层内无连接是指可见层(或隐藏层)层内的神经元之间无连接.层间全连接是指可见层(或隐藏层)中的每一个神经元,与隐藏层(或可见层)中的全部神经元都有连接.由此可知,把神经元作为顶点、神经元之间的连接作为边,则RBM所对应的图可以看出是一个二分图.图2给出了受限玻尔兹曼机结构图示意图,其中:

图2 受限玻尔兹曼机结构图
n表示可见层v神经元的个数,m表示隐藏层h神经元的个数,隐含层h与可见层v神经元之间连接的权值矩阵为W,假设a为隐藏层h的偏置向量,b为可见层v的偏置向量.假定可见层单元、隐藏层单元都是均为二值的,即状态取值为{0,1} .
V=(v1,v2…,vn)T:为可见层v的状态向量,vi表示可见层v中第i个神经元的状态.
h=(h1,h2…,hm)T:为隐藏层h的状态向量,hj表示隐藏层h中第j个神经元的状态.
a=(a1,a2…,an)T:为可见层v的偏置向量,ai表示可见层v中第i个神经元的偏置.
b=(b1,b2…,bm)T:为隐藏层h的偏置向量,bi表示隐藏层h中第j个神经元的偏置.
W=(wij)n×m∈Rn×m:为隐藏层h与可见层v连接的权值矩阵,Wi,j表示隐藏层h中第i个神经元和可见层v中第j个神经元的连接权重.
记θ=(W,a,b)表示RBM中的未知参数的组合,即将W、a、b中的所有分量组合起来得到的长向量.
对于一组给定的状态(v,h),可定义RBM模型的能量函数为:
(1)
(1)中对∀i,j有vi,hj∈{0,1}.利用RBM模型的能量函数(1),在给出状态(v,h)的联合概率分布:
(2)
其中
(3)
为归一化因子.
由于RBM 模型的层内无连接,在给定可见层h的单元状态值时,隐藏层v的各单元的激活条件是独立的,由式(1)和式( 2)可导出隐藏层v的各单元的条件激活概率公式:
(4)
当给定隐藏层h单元的状态时,根据RBM的对称性,可知可见层v单元的激活也是条件独立.同样可得:
(5)
2.1.2 R-RBM协同过滤推荐算法及参数
RBM模型的学习目标就是最大程度地拟合观测数据.RBM模型通过条件概率公式P(h|v)来计算输出向量h(隐藏层),再由向量h及条件概率公式P(v|h)反过来计算向量v(可见层),得到新的可见层向量v和原始输入样本向量v进行比较,不断修正参数,最终使得最新得到的向量v(可见层)向原始输入样本向量v不断靠近,以达到误差的要求.
实际上如果用吉布斯采样来估计RBM的分布,其复杂度很高.一般采用Hinton教授的 Contrastive Divergence(CD),即对比散度算法,可用k步的CD算法(CD-K)来近似RBM的分布,当k取1即可获得良好的效果.所以在CD-K算法中在给定一个训练样本Q(|Q|=g)后,只需要1步Gibbs采样就可以获得较好的RBM的参数估计.使用CD-K实现RBM参数更新,wij、ai、bj参数的更新公式如式(6)、(7):
(6)
Δbi=Δbi+[P(hj=1|v(0))-P(hj=1|v(k))]
(7)
算法1 RBM模型训练算法:
第1部分 初始化
1)确定训练样本集合Q(|Q|=g).
2)确定F为训练周期,并确定学习率η、CD-K算法的参数k.
3)给出可见层v、隐藏层h的单元数目n,m
4)初始化a、b(偏置向量),初始化W(权值矩阵)
第2部分 训练
FORiter= 1,2,...,FDO
1.调用CDK(k,Q,RBM(W,a,b); △W,△a,△b),得到新的△W,△a,△b
2.更新参数式(7)
}
在RBM模型训练算法中,参数的初始化一般利用正态分布N(0,0.01) 产生的随机数进行权重矩阵W的初始化.隐藏层h偏置b初始化的值为零.可见层v偏置a按如下公式进行初始化:
(8)
其中pi表示训练样本中第i个特征取值为1的样本所占的比例.
读者对图书的兴趣评分矩阵作为R-RBM模型可见层v的输入数据.实际中,读者对图书的评分是非常稀疏的,这样可能难以精准地预测图书的评分,也就较难实现个性化的推荐.在本文中以读者的借阅图书的历史记录为依据,这些历史记录包括图书类型、图书借还周期、是否续借、图书借阅时间、还书日期等信息.以借阅时间为主来定义读者对图书的兴趣度,这样可以较有效地解决数据稀疏的问题.读者对图书的兴趣度的计算如公式(9):
(9)
其中,In表示读者对图书的兴趣度,γ表示读者所有借阅图书中最小的时长,δ表示图书最大的借阅时长.t为某图书被借阅时长,t的取值特殊情况的处理:当t≤γ时,t取值为γ;当t≥δ时,t取值δ.接下来要对In的值如式(10)进行转换,即转换为1~5的评分值,其中Mri为转换后的评分值.
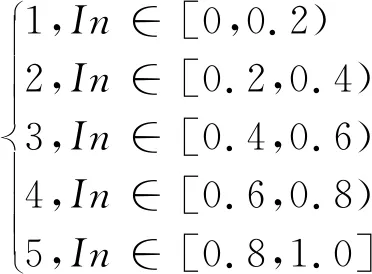
(10)
假设图书馆的图书总本数为N本,图书馆读者人数为O人,式(10)中的i取值从1到N.未借的图书用x来表示其评分状态,为读者对图书的兴趣评分1~5,用M表示.基于用户行为矩阵的构建方法,构造的读者图书兴趣评分矩阵如表1.R-RBM模型中的可见层v替换为N*M的矩阵(读者图书兴趣评分列矩阵),其中M为M个二值评分结果,设M=5.

表1 读者图书兴趣评分列矩阵
2.2 Top-N协同过滤新用户推荐算法
对于新用户由于没有历史借阅记录,所以很难用R-RBM协同过滤推荐算法模型去推荐,本文采用Top-N协同过滤推荐算法对新用户进行推荐.算法的思路:1.新用户对图书大类进行选择并进行兴趣度的评分;2.根据新用户所选的大类,筛选出相关大类所有图书的其他用户的评分;3.求第2步中每个大类的所有图书用户的平均评分;4.利用协同过滤Top-N筛选出第3步中每个大类评分最高的前5个;5.把第4步评分高的推荐给新用户, 如果没有第1步,那么可以把所有图书用户平均评分最高的前5个图书、最热门的前5个图书推荐给用户.
2.3 基于RT-RBM协同过滤的图书馆个性化推荐系统算法设计
结合2.1.2 R-RBM协同过滤推荐算法及2.2 Top-N协同过滤新用户推荐算法,确定基于RT-RBM协同过滤的图书馆个性化推荐系统模型中的各个参数:N*M的矩阵(读者图书兴趣评分列矩阵)作为训练样本Q(|Q|=g),新用户训练样本为Q1(|Q1|=g1);基于训练数据对可见层和隐藏层的状态进行初始化时,利用对比散度方法仅需1步Gibbs采样即可获得不错的RBM的参数估计.训练的次数F为10[12],隐藏层的单元数最佳为30[7];学习率η取值较大时,算法的收敛速度快,但可能导致算法的不稳定,而当η较小时,虽可避免算法的不稳定的情况,但算法的收敛速度变慢.为克服这一矛盾,学习率η的初始值可设置为0.001,η的更新通过Adam方法实现.
下面是基于RT-RBM协同过滤的图书馆个性化推荐系统算法设计:
1)输入:读者r,图书d;
2)判断读者r为新用户还是老用户(是否有借阅历史记录);
3)读者r为老用户时执行4),为新用户时执行5);
4)R-RBM协同过滤推荐算法;
5)Top-N协同过滤新用户推荐算法;
6)通过4)或5)得出训练好的预测分数,利用协同过滤TOP-N算法得出读者评分最高的前N本书;
7)输出:评分最高的前N本书,并推荐给用户.
3 实验仿真
3.1 仿真实验环境配置
进行仿真实验来验证本文提出的算法的有效性.仿真实验都是在MATLAB 10.0 、Windows 7旗舰版的操作系统环境、联想i5-9400F 16G 512GB纯固态 GTX1660SP-6G进行的.以本学院图书馆的借阅数据为例进行实验,选择2 000名老用户读者的8 000条图书借阅记录,400名新用户(没有借阅记录),5 000条图书数据,对于抽取的数据加以修改,作为仿真实验的测试、训练集.将8 000条的记录及400名新用户按随机的方式划分为10个部分,随机选取2个部分作为仿真实验的测试集,剩下的8个部分数据集作为训练集.
3.2 实验评价
仿真实验的评价指标采用准确率Pr,设Q3是仿真实验的训练集合即8 000 条图书借阅记录,其中用户r1感兴趣的图书集为S(r1);以老用户读者图书借阅记录为基础,通过R-RBM协同过滤算法模型为用户r1推荐的图书列表,记作I(r1),长度设置为n1,;给用户r1图书推荐准确率的计算见公式(11).
(11)
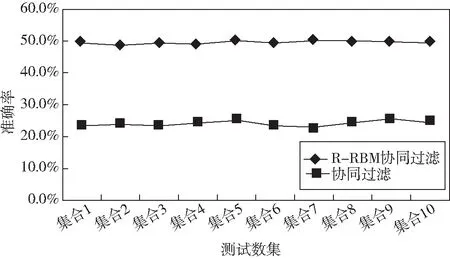
图3 两种推荐算法的准确率对比图
利用本系统模型轮流在10个数据集中分别进行了协同过滤推荐算法和R-RBM协同过滤算法的实验,对两种算法的准确率如图3所示,进行了比较,发现本系统的R-RBM协同过滤算法准确率明显较高.
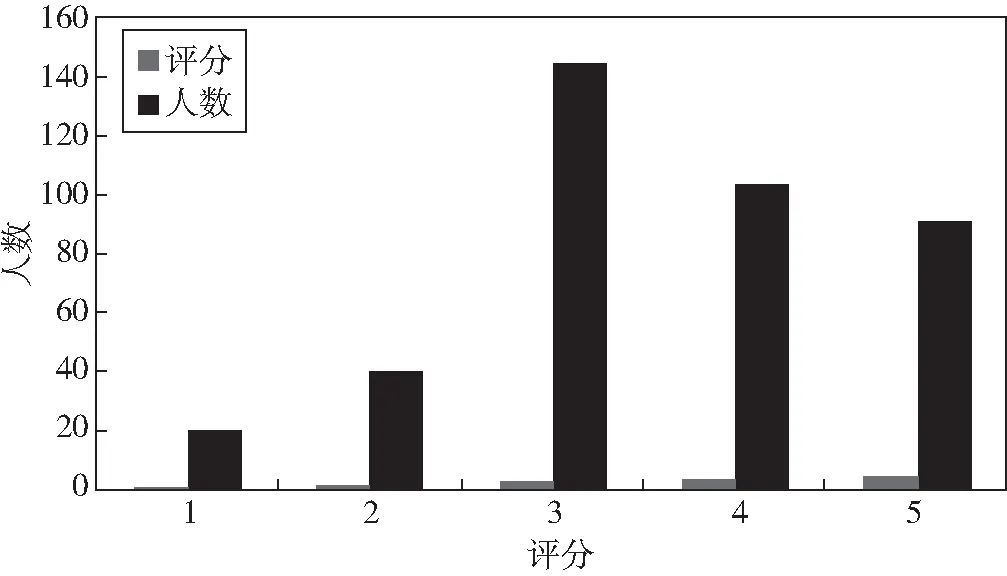
图4 新用户评分图
另外在仿真实验中Q4为400名新用户(没有借阅记录),上面公式(12)的推荐都是基于用户历史借阅数据进行评价的,但对于新用户而言并没有历史借阅记录,所以对其推荐质量评估是存在一定困难的.本文通过400名新用户(本校的师生)对推荐结果进行1分-5分的评分,评分结果如图4所示:约23%的新用户评分为5分,对于推荐结果非常满意;26%新用户评分为4分,对于推荐结果满意;36%新用户评分为3分,对于推荐结果较满意;10%的新用户评分为2分,对于推荐结果感觉一般;5%的新用户评分为1分,对于推荐结果感觉较差.评分的结果表明新用户对于本系统的推荐是较满意的.
4 小结
本文提出的RT-RBM的协同过滤的图书馆个性化推荐系统,比协同过滤推荐的算法准确率较高,这表明了本系统更能挖掘读者个性化信息的深层次特征,能为读者提供更精准的推荐.同时本推荐系统还可以通过Top-N协同过滤新用户推荐算法对新用户进行推荐,从新用户的评分来看,还是较满意的,这也较好地解决了受限波尔兹曼的协同过滤推荐算法存在的“冷启动”问题.但本系统对于新用户这块算法还需要完善,以加强这部分算法的泛化性,这是本系统后续需要进一步研究的问题.
