基于数据关联融合KCF与Kalman滤波的车辆多目标跟踪
2020-12-16宋俊芳王菽裕
宋俊芳, 王菽裕, 薛 茹, 李 莹
(1.西藏民族大学信息工程学院, 咸阳 712082; 2.长安大学信息工程学院, 西安 710064)
基于视频的运动目标跟踪主要任务是在图像序列中找到运动目标,并将不同帧中的同一目标关联起来,形成目标的运动轨迹,这一技术已经成为计算机视觉与人工智能领域中热门的研究课题之一。最初,学者主要从单目标如何设计外观模型和运动模式进行有效跟踪开展研究,如经典的Mean shift算法[1]、粒子滤波跟踪算法[2]、卡尔曼滤波跟踪算法[3]、TLD算法[4]、MOSSE算法[5]、KCF算法[6]、Staple算法[7]以及基于深度学习的C-COT算法[8]和ECO算法[9]等。后来考虑到目标在一定场景中,其运动相互之间存在关联性,Luo等[10]首次提出多目标跟踪的概念,但早期,跟踪还是以单目标检测的结果为基础,然后通过手动匹配关联目标的运动轨迹,这在实际应用中无法实现智能。随着高精度的目标检测已完善并普及应用,为智能数据关联的多目标跟踪技术实现奠定了扎实的基础,吸引大量学者纷纷展开研究,并认为通过对不确定性观测与已形成的目标轨迹簇的关联配对,来确定出极大相似关联度的目标-轨迹链的过程称之为数据关联。这一概念在1964年由Sittlter等[11]提出。随后,产生出很多基于数据关联的多目标智能跟踪算法,大多是基于贝叶斯概率模型的,如最近邻域标准滤波器[12](NNSF)、概率数据关联滤波[13](PDA)、联合概率数据关联滤波[14](JPDA)和多假设跟踪[15](MHT)。NNSF和PDA算法复杂度低、计算快,可以很好地满足工程应用需求,但对强杂波环境下的复杂目标跟踪,容易发生目标的偏移和聚合现象,而JPDA和MHT对此却展现出良好的性能,但其运算量巨大难以在工程中应用,在随后的几十年间,学者们致力于探究算法实用性和优良性能的良好均衡。直到2008年,Huang等[16]提出了经典的多层跟踪理论框架,片段轨迹由底层完成,片段轨迹之间的关联度量及全局最优评价由中层完成,完整轨迹的形成由高层完成。该框架一直被使用到2015年,伴随着机器学习的热潮,同时,Xiang等[17]提出基于马尔科夫决策的多目标跟踪算法,通过机器学习来强化训练多目标匹配模型的参数,采用构建出的激励函数来达到多目标状态跟踪分析的目的。随着神经网络的研究成熟,将深度学习用于多目标跟踪,从技术上优化了跟踪评价和目标间相似性度量算法,并获得较好的跟踪效果,然而,基于深度学习的多目标跟踪算法距工程应用还有一定的差距。为此,针对复杂交通场景下的车辆多目标跟踪,在单目标跟踪算法的基础上有效融合数据关联算法快速获取可靠的轨迹数据。
1 多目标关联跟踪实现
基于数据关联的多目标跟踪其核心就是解决目标与轨迹间的关联匹配,但这一问题在复杂交通场景下的车辆目标之间,因为其较高的相似性和交互性使得难度骤增,一方面要保证匹配精度,另一方面还要考虑实时性。以往绝大部分方法都是先在感兴趣区域完成多帧的目标检测,然后将当前帧的目标测结果作为关联匹配的观测量,通过设计最优匹配算法判断出前后帧与各观测量的关联度,最后再整体绘出目标轨迹,这样的处理方法轨迹形成要利用后续的检测结果,导致基于轨迹的行为分析相比目标检测要滞后,无法保证实时性,如果能够以在线跟踪的方式边检测目标边在当前帧实时更新状态轨迹,将对交通智能分析大有好处。
利用YOLOv3检测器获取输入视频序列的检测结果,从第二帧的检测结果开始,用IoU相似性度量对当前目标框与已形成的轨迹进行关联匹配,得到目标与轨迹的关联矩阵;然后通过改进的关联判定准则寻找关联矩阵中的最佳关联对,完成初步轨迹匹配;考虑目标检测可能存在漏检和遮挡的情况,将KCF与Kalman相结合改进目标跟踪方法,实现目标轨迹的持续跟踪。整个跟踪算法的流程如图1所示。下面从目标与轨迹的数据关联以及不同关联结果的目标-轨迹处理两方面进行研究。
2 数据关联
在零漏检和零误检的相对理想状态下,目标的轨迹链通常由跟踪过程中每帧的目标检测标识框直接相连而得。真实而复杂的交通环境下,受到噪声的干扰,无法做到车辆零漏检零误检,这样就会导致目标相连容易出现断层,跟踪无法持续。那么如何设计一个稳定的数据关联算法实现目标的持续跟踪成为多目标跟踪的关键之一。数据关联的过程主要包括关联数据选取、关联相似度度量和寻找最优关联对3个模块。下面分别从这几个方面展开研究。
2.1 目标-轨迹 IoU相似性度量
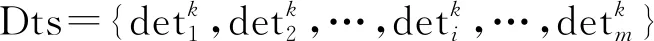
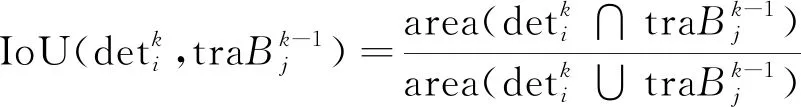
(1)
总之,寒地水稻的品种的特性以及粒穗受力角度和水稻穗头的含水率等因素都直接关系到收割机脱粒损失的大小以及脱粒带柄率与损伤率的高低,影响收割机性能的正常发挥。该研究可为及时确定最佳的收割时间和为设计新的脱粒滚筒奠定了基础。
按照此方法,结合式(1)计算最终可得到m个候选目标与n条跟踪轨迹基于IoU双向的相似性度量结果,用矩阵Amn表示为
Amn=
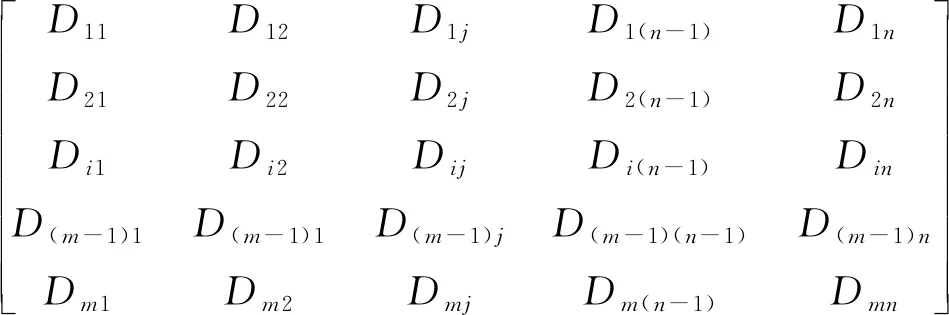
(2)
式(2)中:Dij=1-IoU(i,j)由目标特征信息、位置信息和状态信息等组成,行i表示当前帧中候选目标与所有轨迹在最后一帧目标框的相似性度量,列j表示已形成踪轨迹最后一帧目标框与当前帧中所有候选目标的相似性度量,称矩阵Amn为多目标关联矩阵,此矩阵首次提出双向表示目标与轨迹之间的关联度,为确定最佳关联规则奠定了基础。
2.2 行列最优耦合寻找最佳关联对
数据关联的最后一步是基于关联矩阵,设置关联判定准则搜索最佳关联对。鉴于提出的双向相似性度量方法,首先输入相似性度量值集,设置经验阈值k(取0.5)初步筛选出候选关联对,然后用行列最优准则选取最佳关联对,即每一行搜索到的最优度量对应的列其最优度量恰好也对应此行。这种方法不是单一考虑它们的度量应该完全一致,而是充分考虑到关联匹配的误差,在寻找最佳关联对时,只要目标与轨迹相互数据关联达到最优即可,这样不仅计算速度快,还不用计算复杂的匹配误差,结果也非常准确。基于此关联判定准则,最终会出现图2所示的三种关联结果。第一种情况被认定为当前帧有新目标出现,将作为下一帧的关联数据;第二种情况被认定为目标与轨迹配对成功;第三种情况是在当前帧中目标消失,可能是漏检,也可能是目标离开检测场景。
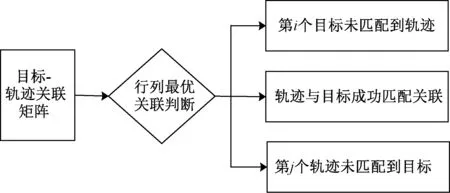
图2 关联判定结果Fig.2 Data association judgment results
3 轨迹处理
针对图2的关联判定结果,目标-轨迹处理又分为如下四种情况。
(1)新目标出现,不能直接认定为有效的车辆目标,因为在复杂交通场景里,目标检测算法精度再高也无法保证不出现车辆误检,可以在目标首次出现时启动一个计数器,当该目标连续三帧都被检测到时才开始跟踪,否则认为是无效目标,直接删除。
(2)轨迹与目标配对成功,则持续跟踪。
(3)目标丢失,若目标连续th帧再无出现,认为目标离开了当前场景,目标轨迹不再进行预测更新;若目标连续丢失帧小于th,认为是检测算法不鲁棒造成了目标漏检,需要进行位置预测。
(4)目标离开遮挡,目标重新被检测到,再次对目标与轨迹进行关联配对。
3.1 基于KCF最大响应预测位置
KCF核相关滤波跟踪算法[6]在目标尺度不变的情况下跟踪精度高,而且预测速度快,以至于许多跟踪算法都以KCF为基石完成构建。
基于方向梯度直方图(HOG)特征提取对跟踪目标建立跟踪器是KCF的原理,其方法是在当前帧检测区域内,通过跟踪器模板循环采集,进而优化处理得到每一个采样区域对应的响应,将响应最大的采样区域作为目标在当前帧的预测位置。但是通过研究测试发现, KCF在进行遮挡漏检目标位置预测时,由于遮挡是一个从信息不完整到信息丢失再到信息逐渐恢复的过程,跟踪模板持续更新会将错误信息引入跟踪器,导致跟踪失败。
为解决此问题,用KCF算法没有直接先进行位置预测,而是用它先判定目标是被遮挡还是异常丢失。由于遮挡和非遮挡状态下车辆正常行驶,用KCF计算得到的最大响应变化曲线显著不同。如图4所示,是对图3连续多帧计算得到的最大响应变化曲线。从图4看出,正常无遮挡情况下,最大响应值较高,都大于0.7;反之,大部分响应均小于0.5,两者分界较为明显。究其原因,遮挡发生时,跟踪模板不能一成不变,需要将改变的目标特征实时更新到新模板中,导致最大响应值较正常情况明显降低。为此,通过最大响应值阈值约束,即可快速判断出目标是否被遮挡。如果没有被遮挡是异常丢失,则直接用KCF预测目标位置是准确的;如果是被遮挡,则KCF停止模板更新,改用Kalman滤波预测目标位置,这样可以避免由于跟踪模板持续更新造成的错误匹配。

图3 不同情形下车辆连续行驶态势Fig.3 Unobstructed and covered vehicle moving process
基于KCF预测目标位置流程如图5所示。初始化KCF跟踪器的过程即依据已形成的目标轨迹,在最后一帧目标出现位置的附近选择2.5倍区域循环采样,提取其HOG特征构建目标跟踪器模板;然后在当前帧的候选区域内,利用KCF跟踪器计算出每个采样样本的响应,并将响应最大的位置标注为目标预测位置,同时更新跟踪器模板,作为下一帧的关联数据。
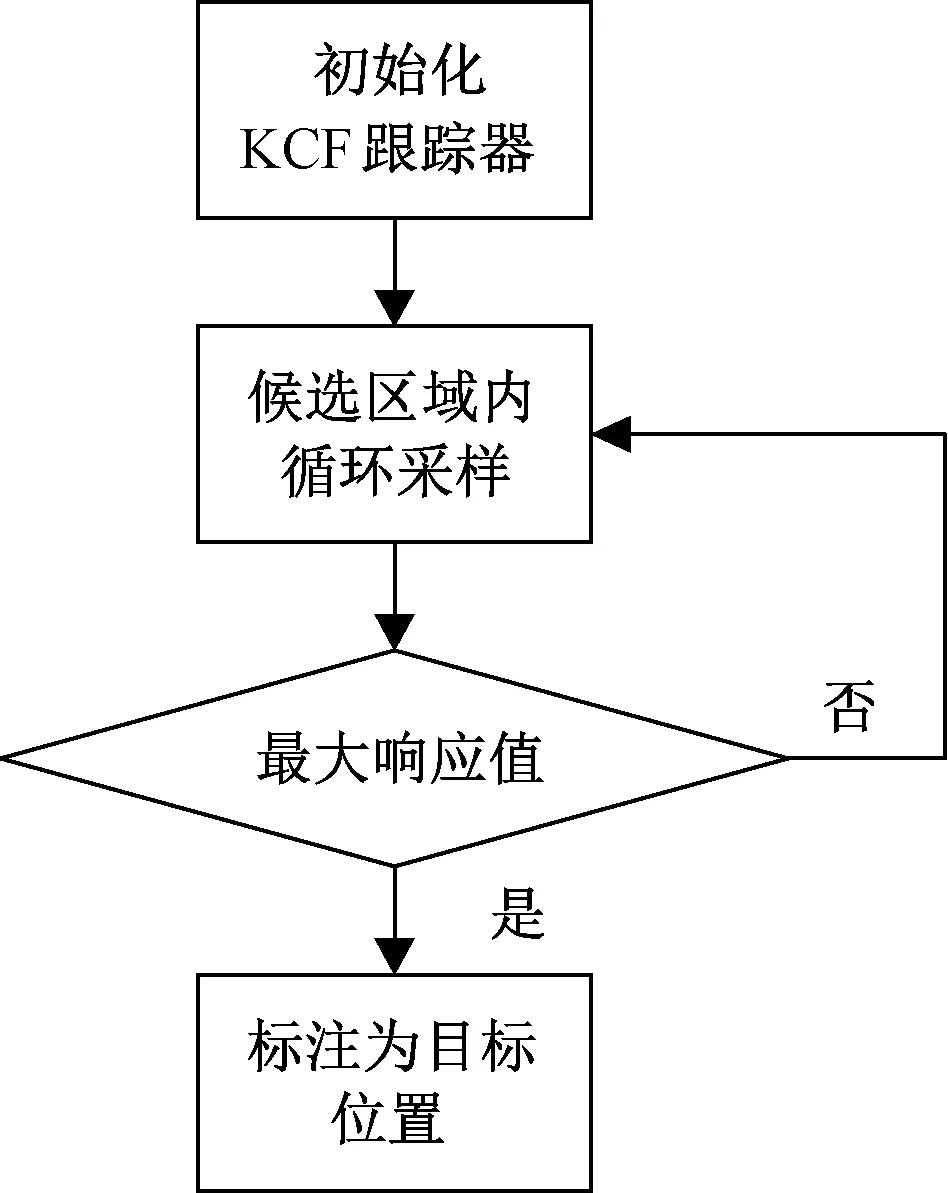
图5 KCF预测目标位置流程Fig.5 Process of predicting target position combined KCF
3.2 基于Kalman滤波预测位置
在复杂交通场景下,车辆在短时间内的运动可以看作是匀速直线运动,而Kalman滤波本身是一个线性滤波器,其预测修正过程计算量较小,比较适用于实时处理。因此,可以在KCF完成遮挡检测后,用Kalman滤波对遮挡目标进行位置预测,不至于明显降低运算速度。
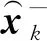
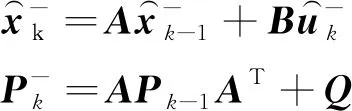
(3)
基于当前状态的预测结果,只要再收集现在状态的测量值Zk。通过对测量值和预测结果的加权平均处理,即可得到现在状态的优化估算值xk:
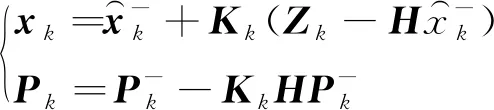
(4)
式(4)中:Kk为卡尔曼增益,其计算过程为

(5)
式(5)中:H表示测量系统的参数。以此迭代,并更新协方差Pk完成目标位置的连续跟踪。
4 实验与分析
针对高速公路交通场景下的车辆目标,在YOLOv3检测器获得检测结果之后,加载本文算法和经典方法线上全天候跟踪实验,取得如下实验结果。实验在杭金衢高速公路路段交通场景下完成,实验过程中设置最大响应阈值为0.5,th=40。
4.1 正常数据关联跟踪结果
经数据关联行列最优匹配得到图6所示的关联度量结果,图6(a)是第188帧的目标检测及配对结果,图6(b)是第189帧的目标检测结及配对结果,两帧目标轨迹关联配对得到图6(c)所示关联矩阵,在矩阵中都找到了行列最优度量,即5个目标都与前一帧轨迹配对成功。
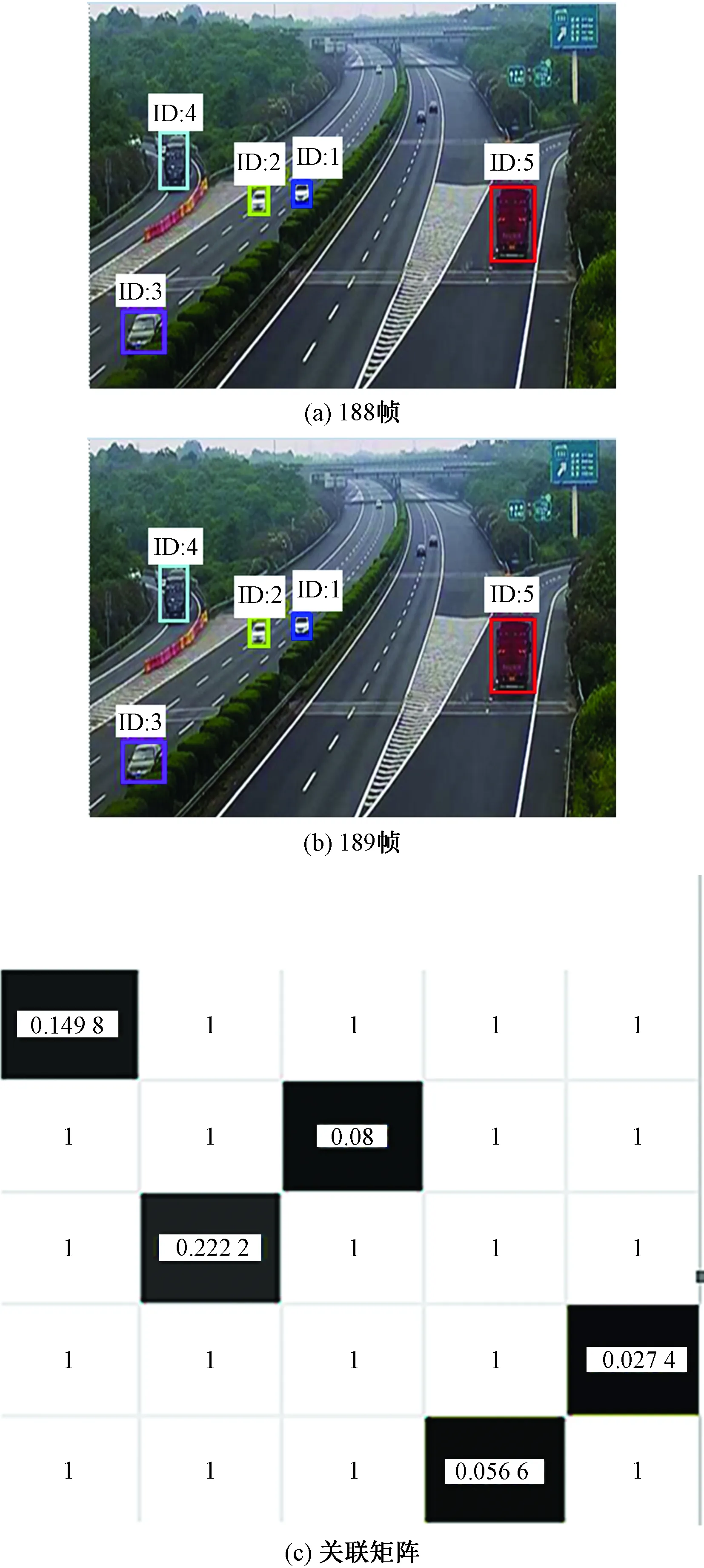
图6 正常数据关联结果Fig.6 Normal data association results
4.2 KCF目标位置预测结果
图7是实际测试实验中目标非遮挡情况下漏检,启用KCF算法预测丢失车辆在当前帧中位置的代表性结果。
在第2 182帧,用目标检测算法检测到6个目标,且目标-轨迹关联配对正常,共形成6条有效轨迹,但在第2 183帧,ID标识号为59的车辆没有被检测到,导致目标-轨迹数据关联失败,出现第6条轨迹未匹配到检测目标的关联判定结果,经KCF算法在候选区域循环采样计算最大响应为0.78,判定出目标是异常丢失,启动KCF进行位置预测,结果用黄色框标注显示,人眼直观分析预测位置较为准确。

图7 漏检情况下的轨迹处理结果Fig.7 Trajectory processing results under the condition of target loss
4.3 Kalman滤波目标位置预测结果
图8、图9是实际测试实验中目标遮挡情况下漏检,启用Kalman滤波算法预测车辆在当前帧中位置的代表性结果,包括目标相互遮挡和障碍物引起的遮挡两种特殊状况。
在图8远端场景中,右侧左车道的小车从2 166帧开始到2 205帧,一直被中间车道的大车遮挡,目标检测算法未能成功检测到小目标车辆,导致其轨迹在与目标关联失败。经KCF算法在每帧候选区域循环采样计算最大响应都小于0.5,判定出目标持续被遮挡,停止KCF算法更新模板,启动Kalman滤波进行位置预测。从2 171、2 188、2 205帧中预测标注的结果和形成的轨迹看出,卡尔曼滤波跟踪在目标间相互遮挡较为严重的情况下,依然准确地预测出目标的位置。

图8 目标间严重遮挡情况下的轨迹处理结果Fig.8 Trajectory processing results under the condition of target occlusion
在图9场景中右侧左车道的车辆在图9(a)中关联配对成功,在图9(b)中,目标轨迹正常关联配对失败,自感应KCF跟踪器启动,判定此时车辆被路牌开始遮挡,确定采用卡尔曼滤波完成接下来的位置预测和配对,直到图9(c),车辆彻底被路牌淹没,期间卡尔曼滤波跟踪器都较好地完成了车辆的位置预判一直到图9(d),车辆再次被成功捕捉,恢复到正常的目标跟踪状态。
4.4 方法对比
为定量分析本文方法的性能,从MOTA、MOTP、MT、ML、IDS和检测速度几个技术指标与传统方法进行对比试验和分析。MOTA表示目标定位准确性,与目标漏检率和虚警率相关,值越大,越利于跟踪;MOTP表示目标框的平均重叠率,值越大,跟踪效果越好;IDS表示轨迹与目标切换的次数,值越小,稳定性越好;MT表示目标与轨迹配对成功占比,一般认为值大于80%算法较为稳定;ML表示目标跟丢的轨迹占比,此值一般要求小于20%。
从表1得知,本文方法在目标定位准确性相同的情况下,由于改进了应对遮挡漏检等特殊情况下的新举措,联合KCF算法和卡尔曼滤波对漏检和严重遮挡引起的轨迹关联失败进行有效预测,结果在MT、ML和IDS指标上明显优于JPDA、MHT、MDP经典方法,不仅如此,在检测时间上也有很大的优势,能更好地满足实时性要求。
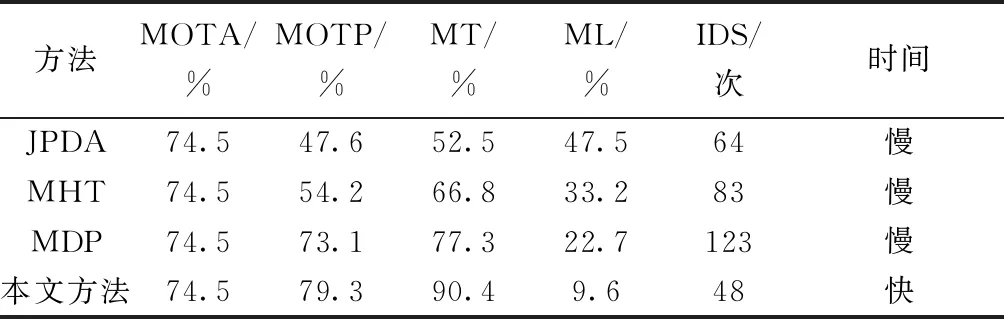
表1 方法对比结果
5 结论
在目标检测结果的基础上,针对复杂交通场景下的车辆多目标跟踪,提出基于数据关联融合KCF与Kalman滤波的车辆多目标跟踪方法。完成了基于IoU相似性度量和行列最优耦合原则关联评价目标-轨迹配对的过程,并针对关联异常,通过最大响应值遮挡检测联合卡尔曼滤波分层递进处理,实现了目标轨迹的准确持续跟踪。实验结果表明,本文所提跟踪方法对误检、漏检及严重遮挡问题均可以准确有效解决,并且在高速公路环境下可以准确实现对目标轨迹的定位,因此该算法能给予城市智能交通可靠的数据保障。
