PIC数据库的搭建及数据提取、研究的基本方法
2020-12-16黄韬王新宇冯敖梓李莉吕军
黄韬,王新宇,冯敖梓,李莉,吕军
儿科重症医学(PCCM)是专门研究从胎儿到青春期各年龄阶段危重病症的基础、预防和临床的理论与实践方法,以进行及时有效救治的儿科医学一级学科[1]。重症监护病房(ICU)为需要侵入性治疗的重症患者提供护理与监控,这个过程中会产生大量数据。有效利用这些数据,分析患者状态、用药等与疾病之间的关系,有助于为医生的临床诊断与治疗提供科学依据。现有的重症监护数据库如MIMIC[2]、eICU[3]等,收集了共计40多万例重症患者的临床诊疗数据,并且众多研究者在这些数据库基础上取得了丰富的研究成果,如结合机器学习模型预测脓毒症[4],循环衰竭的早期预测[5]等。但这些数据主要针对成人重症患者,并没有全面的儿童与青少年患者数据。儿童的发育状态与成人不同,对诊疗方法的反应和康复轨迹也不同[6]。对于不同疾病,儿童发病率、死亡率等数据指标与成人也有明显区别[7,8]。因此,在成人临床数据上的研究成果应用于儿科之前,都应在儿科数据上进行重新验证。PIC数据库为儿童疾病的临床研究以及与成人重症数据的比较上提供了研究的基础。
儿科重症监护(PIC)[9]数据库是一个大型的单中心儿科专用数据库,收录了浙江大学医学院附属儿童医院在2010至2018年期间入住院内多个不同ICU的所有患者临床数据,共计12 881例不同儿科患者的13 499例入院信息。数据内容包括了患者的人口统计学、药物使用、体液平衡、全面的实验室检测结果及整个住院期间的微生物学信息等,同时还包括了手术过程中从麻醉信息管理系统收集的生命体征信息。PIC数据的性别、年龄分布如图1和图2所示,可以看出男性患者多于女性,且多为刚出生婴儿。PIC数据库建立在广泛使用的MIMIC[2]数据库的成功基础上,经过注册、申请、认证后可免费下载。认证过程包括完成相关的培训课程,并签署数据使用协议。

图1 PIC数据患者性别统计

图2 PIC数据患者年龄数据统计
1 数据库基本信息及表的关系说明
PIC数据共拥有16张表格,为便于加载到关系型数据库中,所有表格均以逗号分隔值文件(CSV)的形式存储。如表1所示,根据表格信息内容主要可分为四类:患者住院信息、医院记录系统中收集的数据、手术室信息及字典信息。其中患者住院信息(ADMISSIONS,ICUSTAYS,PATIENTS)主要用于定义和跟踪患者的住院情况,表中的SUBJECT_ID,HADM_ID以及ICUSTAY_ID作为患者的唯一个人、唯一入院、唯一ICU标识符联结着所有的表格,是用于索引其他临床数据的主键。具体来说,PATIENTS表中的SUBJECT_ID是用于指定单个患者的唯一标识符,ADMISSIONS表中的HADM_ID是患者多次入院的唯一住院接收号,而ICUSTAYS表中的ICUSTAY_ID则是患者进入重症监护室的唯一标识符。这里每个SUBJECT_ID可能具有一个或多个相关的HADM_ID,且每个HADM_ID具有一个或多个相关的ICUSTAY_ID。

表1 PIC数据表格信息说明
PIC与MIMIC数据库一样包含包括患者的人口统计学、药物使用、体液平衡以及微生物敏感性测试等信息数据,不同之处主要有两点:一是PIC数据库收集了麻醉信息管理系统的患者生命体征数据,每5 min记录一次,生成了新的CSV表格SURGERY_VITAL_SIGNS.csv。二是由于PIC是首个国内全面的儿科患者(0~18岁)重症监护数据,院内许多临床文件和报告都是使用中文记录的,由于无法直接保存叙事性长文本,因此在数据收集的过程中使用了自然语言处理(NLP)的技术从临床进展记录和出院摘要中提取了患者主要症状,生成了EMR_SYMPTOMS表。作者测试NLP模型的平均准确率为91.9%,共生成3410个临床症状。同时为了使PIC数据库能在世界范围内得到广泛使用,数据表内提供了中英双语字典表,不仅使用原始的中文属性记录信息,同时提供了英文的对应代码。数据中包含中文的表和列的具体信息如表2所示。
PIC数据库搭建的主要流程如表3所示。用户需要先申请并下载PIC数据,安装相关数据库软件后导入数据,然后再从数据库中提取需要的数据信息进行研究。
2 数据下载及数据库的搭建

表2 数据中带有中文的表和对应列

表3 数据库搭建到使用基本流程
如前所述,用户需要先下载数据并建立数据库,才能进行数据提取,并开展研究工作。本章节具体讨论数据的下载、库的搭建、数据导入以及提取的具体方法。
2.1 PIC数据的申请及下载要使用PIC数据,研究人员首先需得到认证。获得认证主要有两种方式:完成CITI(Collaborative Institutional Training Initiative at the University of Miami)的“Data or Specimens Only Research”课程,或从中国当地研究所获得GCP(药物临床试验质量管理规范培训证书)认证。随后签署数据使用协议,审核通过后便可下载PIC数据。数据下载页面如图3所示。可直接下载ZIP压缩包,其中包含了全部的数据文件,同时提供了MySQL和PostgreSQL两种数据库导入代码。也可选择单个文件的预览或下载。如果用户使用的Linux系统,则可直接通过下面的代码在系统的命令行窗口下载数据(注意将username改为用户在Physionet中注册的用户名):


图3 数据下载页面
2.2 PostgreSQL数据库软件的下载与安装下载数据后,用户可直接使用CSV文件,结合Excel、SPSS等数据分析软件进行数据处理。但文件在使用过程中易损坏,且直接使用CSV文件既不利于存放海量数据,也不利于对数据的查询和管理,在程序中控制也不方便。为了更安全有效地存储、检索和管理数据,这里使用数据库的方式进行管理。PIC数据提供了MySQL及PostgreSQL两种数据导入数据库的代码,用户任意选择其中一种即可。参考文献[10]下载并安装PostgreSQL软件。
2.3 数据导入与索引建立安装好数据库软件后,需要将CSV文件数据导入到数据库中[10]。为更高效的获取数据结构,导入数据后需为数据创建索引,创建索引主要有以下好处:
①创建唯一性索引,保证数据库表中每一行数据的唯一性。
②加快数据检索速度,这是创建索引最主要的原因。
③减少磁盘IO访问,向字典一样可直接定位数据。
④通过使用索引,在查询的过程中,使用优化隐藏器,提高系统性能。
⑤加速表和表之间的连接,特别是在实现数据的参考完整性方面具有意义。
2.4 数据库连接与数据提取连接数据库主要有两种方式,一种是使用数据库管理工具如DBeaver、Navicat Lite、Webcat等,主要优点是管理数据库更轻松快捷。可以直观进行常规数据库管理功能,如查询、编辑或设计表、数据写入、SQL转储,和创建或编辑用户等,同时也可以进行数据的导入/导出、报表创建等。Navicat软件界面如图4所示,参考文献[11]使用Navicat连接数据库并进行数据查询。另一种方式是使用Java、Python等代码直接连接数据库,并进行数据查询、导出等过程,优点是获取数据更加便捷,得到数据后不需转存而直接进行后续分析工作。但相比数据库管理工具直观性差,如图5所示。

图4 Navicat软件界面
数据提取需使用SQL语言代码,而与数据库的连接方式无关。PIC数据网站提供了数据的样例展示。如图6所示,研究者可根据性别、是否死亡、入住ICU的时间长短、以及入院定位等条件筛选数据并预览,预览结果如图7所示,展示了患者进入ICU时间少于5 d的样例。更详细的数据结果需研究者自己从搭建好的数据库中提取。

图5 使用Python连接数据库并结合SQL语句提取数据

图6 PIC网站数据统计条件选取页面
2.5 提取数据开展研究的基本方法PIC数据库中可用的数据包括实验室测量值、患者住院期间的图表观察结果、从笔记中提取的结构化症状以及患者在手术室中时记录的生命体征等信息。其完整的数据内容为普通医生,特别是重症医学科医生开展临床研究提供了极大便利。开展研究首先需确定一类待研究的病症,然后从DIAGNOSES_ICD表中提取出待研究病症的患者的主键(SUBJECT_ID,HADM_ID,ICUSTAY_ID),根据主键可从其他表中定位需要的数据。如图8所示为患者被诊断出各种疾病的人数统计表,其中早产儿、肺炎、室间隔缺损的患者数量占据了前三位。这里以患者数量最多的早产儿患者生存分析为例,简述提取数据开展研究的基本方法。

图7 患者入ICU时长小于5 d的数据样例
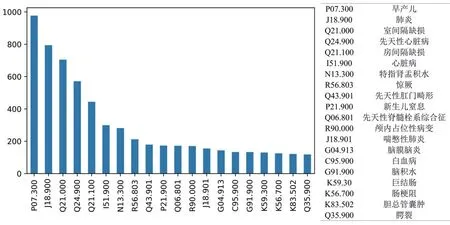
图8 PIC数据疾病患者数量统计
确定了研究问题,还需确定感兴趣的医疗指标。例如:先从DIAGNOSES_ICD表中提取出ICD10_CODE_CN为P07.300(早产儿)对应患者的主键(SUBJECT_ID,HADM_ID),然后考虑具体指标的选取;D_LABITEMS是一个存储了所有实验室指标的字典,选取其中感兴趣的指标,结合患者的主键从LABEVENTS表中提取相应数据;再根据主键从PATIENTS、ADMISSIONS表中提取患者基本特征,如年龄、性别、入院时间、死亡或出院时间等;根据患者入院时间及死亡或出院时间即可计算出患者在医院就医的时间跨度。可选的研究思路为:先确定待研究的问题,获取对应研究对象的基本特征,包括人口学特征、实验室检查结果、临床监测结果等,计算其他需要参数;然后采用Kaplan-Meier曲线和Cox风险比例模型等方法分析患者特征与生存概率的关系。
3 总结
重症医学的研究随着MIMIC、eICU等数据库的开放下载近年来得到了迅速发展。研究者通过深度挖掘、分析重症病房医疗大数据,了解重症患者的个人状态、临床用药与疾病间的相互作用关系,以更科学的方式诊断疾病并提出治疗方案,推进了重症医学的研究进程,提升了医疗水平,促进了医疗行业的发展。儿科重症监护(PIC)[9]数据库是依据MIMIC数据库的构建方法搭建的儿科专用数据库,收录了浙江大学医学院附属儿童医院在2010~2018年间的所有患者临床数据,共计12 881例不同儿科患者的13 499例入院信息。PIC数据库的提出一方面填补了儿科重症患者数据的空白,为科研人员分析儿童病症及与成人患者重症数据的比较上提供了宝贵资源;另一方面,PIC数据库的数据来源是国内医院,其整合了中文的实验记录、药物记录、病历、检查等信息,为科研人员提供国内医疗数据信息的同时解决了语言障碍。科研人员可根据不同症状、年龄、性别、疾病等属性提取相应的信息进行分析。本文通过介绍PIC数据的相关信息以及数据库的搭建、数据的提取方式等,帮助医学研究人员快速了解数据基本结构,明确数据库的搭建流程,为科研过程节省一定的时间成本。
