知识图谱研究进展及其前沿主题分析
2020-12-15谭晓张志强
谭晓 张志强


摘 要:文章基于收集的近30年知识图谱主题文献展示了知识图谱发展的趋势,利用关键词共现呈现了知识图谱领域主题的相互联系和结构,基于描述的热点前沿构建了内容层面分析的主题框架,从实体消歧、关系扩充、图谱改进、图谱集成、关联数据、动态构建等方面进行分析,总结了知识图谱的应用现状,并对知识图谱的发展趋势予以揭示。
关键词:知识图谱;实体消歧;嵌入模型;事件图谱;知识融合
中图分类号:G254.29 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2020027
Abstract Based on nearly 30 years collection of knowledge graph macro subject literature, the paper shows the trend of the development of the knowledge graph. Keywords co-occurrence is used to present knowledge graph topic in the field of the structure and interconnection. Based on the description of hot frontier, the theme of the analysis of the content level framework is constructed. In-depth analysis was made from the entity disambiguation, relationship expansion, graph improvement, graph integration, correlated data, and dynamic building to summarize the present situation of the application of knowledge graph. It also reveals the development trend of knowledge graphing.
Key words knowledge graph; entity disambiguation; embedded model; event graph; knowledge fusion
知識图谱(Knowledge Graph,KG)旨在描述客观世界中的实体、概念、事件、属性及其之间的关系。从结构化的、半结构化的、非结构化的数据源中抽取知识及知识间的关系,强调现实世界的实体、关系,并以图的形式进行组织,提供了从关系分析问题的能力。知识图谱技术包括知识图谱构建、管理、更新以及应用过程中使用的技术,融合了知识表示、信息检索和抽取、机器学习、自然语言处理、语义网以及数据挖掘等交叉领域。
互联网上的信息是碎片式的,并以不同的数据形式呈现,这使得用户对知识连续、系统、全面地收集和理解都很困难;在大数据时代,用户更喜欢获取知识,而不是从网络上获取页面;在信息环境和知识经济发展的背景下,图书情报工作核心定位于知识服务,已成为在面向科技决策、科技创新、科学研究以及产业发展等多层次的文献情报需求的核心,需要对异构的文本知识对象进行挖掘……为解决这些问题,知识图谱成为大数据时代最有效的知识表示及整合方法之一。一方面,知识图谱能同时被机器和人所理解,反映客观世界的组成和关系,为实现推理和决策提供关键组件;另一方面,知识图谱作为知识工程的一类技术,是实现智能的重要手段。近年来,知识图谱技术在科学研究和产业界得到了广泛的应用实践。但知识图谱并不是最近才出现的技术,它的发展一直伴随着人工智能技术发展历程。 人工智能经历了运算智能、感知智能和认知智能三个阶段,其中,认知智能可以让机器具备能理解思考、像人一样能够学习和推理的能力,而其知识描述和知识管理正是目前需要克服前进的方面。
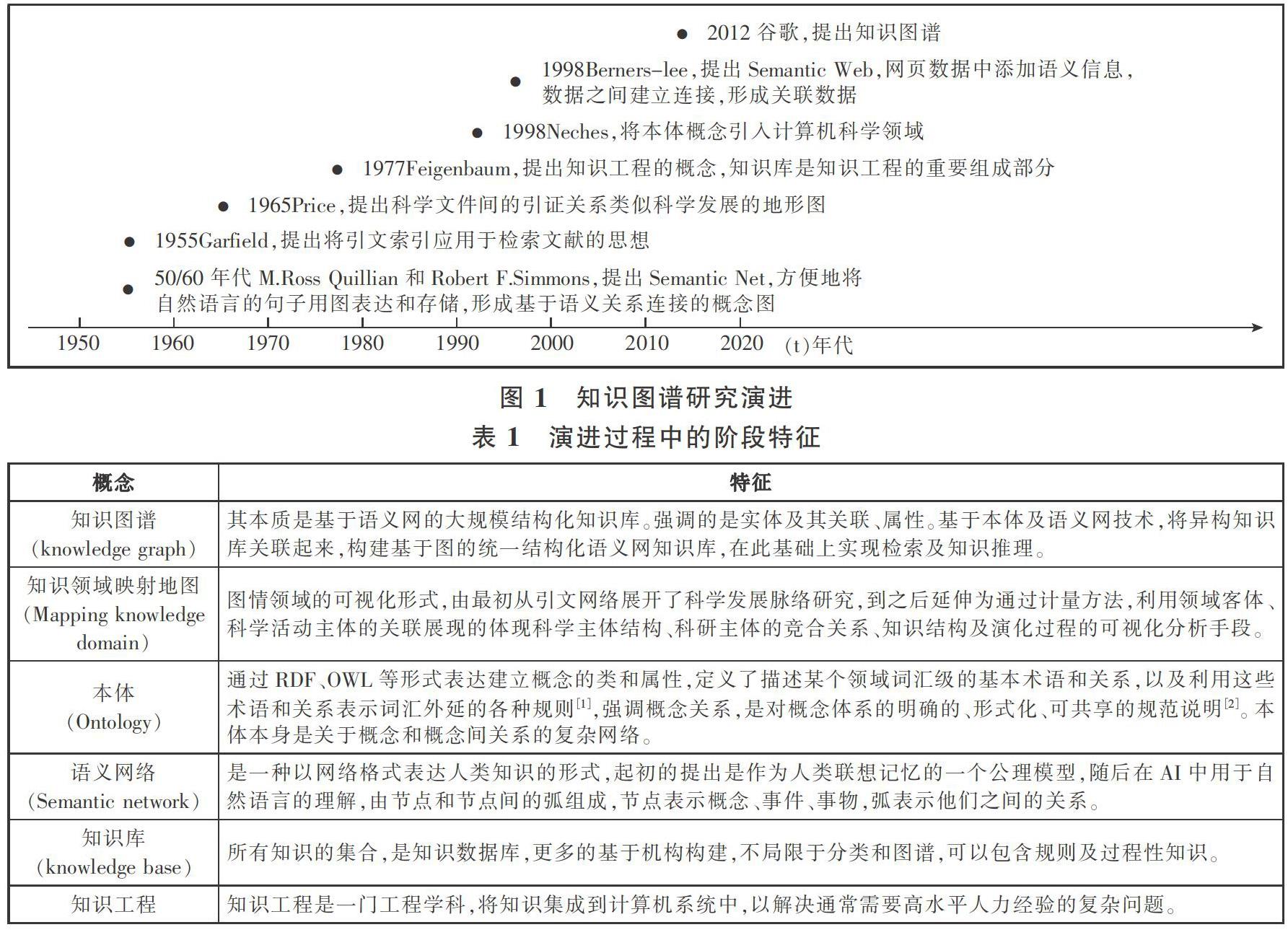
知识图谱与知识领域映射地图(Mapping knowledge domain)、本体、语义网、知识库有异同(见图1、表1)。
知识图谱属于知识管理的范畴。知识图谱紧密依存大数据理论,关注数据规范性和关联性的本体及语义网理论,以本体建模为手段,借助语义网络分析理论挖掘并发现新知识,应用语义网知识库关联方法实现知识的分布式存储,应用深度学习算法发现创新性知识,提供基于实体检索的智能检索及个性化推荐,为用户提供高质量知识服务;知识领域映射地图则是将科研活动主题或具有共同特征的领域客体作为研究对象,应用于计量学、引文分析、知识创新/演变预测等,展现的是科学活动主体、科学知识的结构及演变,应用的理论是库恩的科学发展模式,应用社会网络分析方法和聚类分析,构建社区及发现社区关键人物/主题,构建网络路径,通过关键人物共享和传播知识,在情报学领域,是跟踪科技前沿、选择科研方向、开展知识管理并辅助科学决策的有利工具。知识图谱与知识库两者都是通过更有效和智能地保存、管理已有的知识,同时对外提供一个便捷访问所需知识的接口。知识图谱最终形成的是知识库,同时,知识图谱构建的重要来源是知识库。
为了更清晰地了解知识图谱研究进展情况,文章收集了近30年的科学文献,通过对这些文献计量层面的分析能宏观了解知识图谱发展的趋势,利用关键词共现方法呈现知识图谱领域主题的相互联系和结构,基于描述的热点前沿,构建了内容层面分析的主题框架,并进行内容层面的深度解读,最后文章对知识图谱在各领域的应用进行了总结。
1 知识图谱研究进展的宏观分析
本文采用的数据源为ISI Web of Science,检索主题为“知识图谱”,构建的检索式如下:
#1:
TS=("knowledge graph" OR "knowledge graphs")
#2:
TS=("semantic* net*") or ts=("semantic* web*") or ts=("semantic* relation*") or ts=("artificial intelligence" or "big data") or ts=("ontology *" or "ontology*") or ts=(RDF* or "Web Ontology Language" or ontology) or ts=("nature language *") or ts=("knowledge base") or ts=("deep learn*" or "machine learn*") or ts=("relation* extract*" or "extract* of relation*") or ts=("entit* extract*" or "extract* of entit*") or ts=( "link* data" ) or ts=("neural*")
#3
ts=("knowledge represent*" or "knowledge inference" or "knowledge reason*" or "knowledge acquisit* " or "knowledge extract*" or "represent* of knowledge")or ("knowledge descrip*") or (ts=("knowledge fusion"))
#1 or (#2 and #3)
截至2018年5月21日,共检索出知识图谱主题文献3892篇。
1.1 知识图谱文献时间分布
知识图谱主题的文献出现于1991年,之后一直到2017年论文呈现的是阶段性上涨的趋势。根据数据分析,期间大致有三次大幅增长段:1992-1994、2003-2006、2010-2017,论文产出持续增长,在1997年、2001年、2008年前后出现了较大的减退。从论文的作者量来看,呈现的是1991-2017年持续增长趋势,在1994年、2003年、2014年左右出现几次大幅增长,与论文大幅增长时期大致同步。在论文数量减退时期,作者数量也出现了较少的回落。从作者篇均投入水平来看,整体是上升的趋势,在论文三次增长时期,作者篇均论文数量为:2.38人/篇,3.03人/篇,3.83人/篇(见图2)。
1.2 知识图谱文献主题分布
基于关键词的共现关系可以用来描述表达学科领域集合内部的相互联系和结构,进行热点主题的揭示和发展动态预测。本文利用Citespace进行关键词共现聚类分析,得到25个类簇,结合TF-IDF和LLR,得到25个类簇的主题词(见图3)。主要集中在:神经网络应用(#0)、医疗文本挖掘/生物医学本体(#1、#3、#10)、快速推理(#2)、人工非单调神经网络(#4)、规则抽取(#5)、领域专家(#6)、增强学习算法(#7)、概念图谱(#8)、基于本体的数据挖掘方法(#9)、知识图谱嵌入(#11)、关联属性发现(#12)、维基百科(#13)、时序表示(#14)、信息库(#15)、异构知识表示(#16)、混合专家系统(#17)、变革管理(#18)、无监督学习(#19)、神经表征(#20)、网络系统开发(#21)、预测统计模型(#22)、模糊归纳学习策略(#23)、普适计算(#24)。
2 知识图谱研究主题现状
当今,随着知识图谱构建和应用的快速发展,很多知识图谱,如Freebase、DBpedia、YAGO及NELL,已经成功应用并通用于世界,其范围涉及到语义分析、命名实体消歧、信息抽取、问答系统等。在大数据时代,知识服务和应用对知识库从数据体量、动态更新和扩展性、异构性到价值性方面提出了更高的需求,当前面临着:从碎片化的数据中抽取知识,知识的动态演化导致真值发现难度大,语言表述时存在一词多义和一义多词现象,数据源的异源异构导致的知识质量参差不一使得知识价值评判难等问题。针对这些问题,文章对本文检索到的近4000篇文献进行了分析和归纳,利用关键词共现形成的主题簇构建了知识图谱进展研究的框架(见图4)。
2.1 实体消歧
实体消歧是实体抽取中的一个关键环节,其任务是将存在歧义的实体指称在众多候选实体中匹配出对应的目标实体,本质是计算实体指称项和候选实体的相似度,选择相似度最大的候选实体作为链接的目标实体。目前的实体消歧的方法分为实体的特征/属性和实体-实体的相关性。
(1)依据实体特征/属性消歧。依据实体特征进行消歧的方法包括字符串相似性、流行度、共性。字符串相似性是最直接和常用的方法,指稱实体和候选实体名称通过距离[3-4]或不同相似性系数进行对比。但是当候选实体或者指称实体有语义异构表达时,无法将语义相同的实体进行链接。基于流行度消歧的本质是基于概率统计的方法,具有领域依赖性,其思想是 “对于给定实体指代,与其对应的映射实体最有可能是现实世界中最著名的实体”,但缺陷在于:不论实体的上下文语义环境如何,都会固定指向某一候选实体。实体共性是在实体消歧中非常有效的特征,是指从语义分布到实体标注语料库计算的实体先验概率,其难度在于计算实体共性依赖于标注语料库,计算出的概率因语料库不完备可能造成实体覆盖受限。
(2)实体相关性消歧。利用实体相关性进行消歧,基于不同的信息源有不同的语义特征来计算实体相关性。可以从语义内容、上下文相似、图谱分析三个方面进行实体相关的语义消歧。
首先,基于实体的语义内容,利用以下方法在词袋或向量空间模型(VSM)中计算实体相关性:①实体描述或类别向量的点积或余弦相似性;②利用加权关键词组重叠率以及主题模型进行实体主题一致性计算;③实体分类层次的语义相似度。
第二,利用实体标注语料库、实体共现及实体分布计算实体间关联,其假设是在相似的上下文语境下出现的实体具有语义关联性,本质是基于被比较的文本间存在重叠。计算这种重叠相似性的常用指标是Jaccard或Dice系数。VSM被用来代表高维上下文语境及实体向量,计算特定文本集和词表的TF-IDF得分,上下文-实体的相似性是用点积或两向量间的余弦值。最近学界还提出了利用深度学习架构对指称实体、上下文、候选实体进行分布式向量表示,并基于Word2Vec将上下文词用相似词来扩展。此外,概率语言模型和主题模型已被应用于上下文-指称实体-候选实体的建模中。基于实体上下文能较好的弥补流行度的缺陷,在实体上下文信息足够丰富的情况下,可以取得较高的准确率,但是在短文本或文本稀疏存在噪音的情况下无法保障。
第三,图谱分析在测度实体关联上具有有效性。实体图谱分析是基于语义实体网络中点度分析。点度分析计算的是链接实体的边缘,关系分析则考虑实体之间的有意义的语义关系。这种差异导致了不同类型的实体关联方法。Milne等提出了一种基于入边和出边链接计算实体相关性的点度分析方法。这种实体关联方法已被广泛应用于命名实体消歧系统。类似点度分析的还包括互信息以及Jaccard距离。最近的研究开始关注图谱中实体之间的语义关系,基于实体间最短路径和最短路径的关系权重计算实体间的相关性。
各种不同的实体关联方法,可以通过对机器学习技术的结合以及多种方法的融合,进一步优化和增强实体相关性的性能。除了基于相似的方法,无监督的消歧方法是基于图的方法,将不同的消歧特性结合到图谱表示。上面描述的所有方法代表了处理命名实体歧义的不同方面的考虑因素,在实际应用中要根据数据集的具体特征和在召回率、准确率以及效率之间寻求应用需求,选择消除歧义的特征和方法。
2.2 关系扩充
关系预测与预测图谱中边的存在(正确性的概率)或者边的类型有关,这在知识图谱构建、关系扩充中十分重要,因为图谱中会缺失很多事实,包含的边可能是错误的。
机器学习研究方法,用于关系或图形结构的数据的统计分析。在大型知识图谱上“训练”统计模型,然后用来预测图中的新边。特别地,其中的两种完全不同的统计关系模型,它们都可以扩展到大量的数据集。基于张量因子分解和多路神经网络等潜在特征模型。Socher等[5]将链接预测问题视为矩阵或者张量的补全。初始的知识库可以看做是E×P×E三维稀疏矩阵G,E是实体数量,P是谓词数(关系数量),G(s,p,o)=1,如果存在一个从s到o的链接p,那么G(s,p,o)=0。可以通过将潜在的低维向量与每个实体和谓词进行关联来执行该张量的低秩分解,然后计算元素内积:Pr(G(s,p,o)=1)=σ(uskwpkvok)。σ(x)=1/(1+e-x)是逻辑函数,K-60是隐藏层,us,wp,vo是K维向量,将离散标记嵌入语义空间。Zhao等[6]将成对实体关系嵌入到低维空间进行学习,在Freebase中基于已存关系进行关系预测。第二个是基于在图中观察到的模式。Lange等[7]利用条件随机场在维基百科摘要中学习模式,Wu等[8]将这些潜在的和可观察的模型结合起来,并将这些统计模型与基于文本的信息提取方法结合起来,以便从Web自动构建知识图谱。
同样的,关联关系挖掘也可用于预测关系。Dutta和Kolthoff[9]利用关联规则挖掘寻找有意义的关系链来预测缺失关系。另一个预测关系的常用方法是远程监督,这个方法会使用大型文本语料库。远程监督的假设是一个句子中含有一个关系涉及的实体对,那么这个句子就是描述的这个关系。与远程监督类似,解决关系预测的方法还有路径排序算法(Path ranking algorithm,PRA),起始于所有的源节点,在知识图谱中完成随机游走,所有到达目标节点的路径都是成功的。这些路径的质量可以由它们的支持度和精確度来度量。PRA学习的路径可以解释为规则。由于多规则或路径可以应用于任何给定的实体对,可以通过设置二值分类器来组合。
许多知识图谱包含与其他知识图谱的链接。知识图谱之间的相互链接可以用来填补另一个知识图谱中的空白。Dutta等[10]提出了知识图谱之间的概率映射。基于类型和属性分布,它们在知识图谱之间创建了一个映射,然后可以用来在知识图谱中派生出额外的、缺失的事实。两个知识图谱所使用的类型系统彼此映射,一个知识图谱的类型可以被另一个知识图谱用来预测缺失的关系。
知识图谱包含实体和关系,每个实体关系由三元组形式表示:(h,r,t),h/t表示的头部尾部实体由两者之间代表的一种关系r进行链接。传统的知识表示不能很好的表示实体的语义相关性,为了解决这个问题,知识表示采用分布式方式。知识图谱嵌入,将实体和关系映射到连续的低维向量空间,可以应用于知识图谱完备、关系抽取、实体分类以及实体分解等,在这里主要介绍知识图谱嵌入在链接预测和关系挖掘中的有效性。经典的知识图谱嵌入技术包含三步:第一步指定实体和关系在连续向量空间中的表示,实体通常由向量表示,通过多源高斯函数对实体进行建模分布。关系通常可以表示为向量、矩阵、张量、多源高斯分布;第二步定义了计分函数fr (h,t),在每个事实(h,r,t)上来衡量其合理性;第三步学习实体和关系解决得了优化问题,使整体合理性最大化。
粗略的将知识图谱嵌入分为两类:平移距离模型和语义匹配模型。前者是基于距离得分功能,后者是基于相似度。其中,平移距离模型典型方法包括TransE、TransH、TransR、CTransR、TransF、TransM等。在所有的基于翻译模型的知识图谱嵌入中,TransE是最经典的模型,它的基本假设:当被编码为度量空间时,关系是从h到t的转化/翻译,也就是三元组(h,r,t)适应于表达式h+r≈t,基于此,关系补全通过寻找r*使得h+r*≈t。当一个实体对有多个关系时,多度量空间的方案被提出,这些基于翻译的不同模型的区别在于如何将一个向量从一个空间表示为另一个空间。语义匹配模型探索了基于相似的得分函数,通过潜在语义匹配测度事实的实体和关系在向量空间表示的合理性。
2.3 知识图谱改进
来源网页的数据抽取存在噪音,实体和关系存在不完整和易错性,知识图谱改进主要体现在数据的完备性和错误数据修正,范畴包含实体类别、实体关系以及知识真值(解决异源知识间的冲突和不一致),涉及到的研究领域有概念层面及实例层面。
知识图谱的完备性目标主要是增加知识图谱的覆盖率,完备性相关的研究内容主要集中在缺失实体的预测、缺失实体类型的预测以及实体间缺失关系的判断。①在预测实体类型方面:Paullheim等[11-12]提出了一种基于条件概率的方法,如CAST类型有向内的边,则节点为Actor的概率较高,SDT算法利用了这种可能性;Sleeman和Finin[13]利用支持向量机在DBpedia和Freebase中输入实体,利用知识图谱之间的相互链接,根据属性对知识图谱中的实例进行分类,以提高知识图谱的覆盖率和精确性;Nickel等[14]提出在YAGO中使用矩阵分解来预测实体类型。由于许多知识图谱都有类层次结构,因此类型预测可以看做是一个层次分类问题[15]。在数据挖掘中,利用关联规则的共现性预测图谱中缺失信息,既确保有足够重叠的信息来学习关联规则,又确保有许多实体在系统中的类型唯一。Heiko[16]利用这种关联规则基于冗余信息预测DBpedia中缺失的类型;Sleeman等[17]提出利用主题建模进行类型预测,知识图谱中的实体表示文档,在文档上应用LDA查找主题,通过分析主题和实体类型的共现,为实体分配新的类型。还可以利用外部知识进行实体特征表示进行类型的预测。Nuzzolese等[18]提出使用K近邻分类器利用Wikipedia链接图谱来预测实体类型;Aprosio等[19]使用不同距离度量的KNN分类器利用不同DBpedia语言版本的实体类型作为预测缺失类型的特性;Gangemi等[20]使用不同语言的摘要来提高覆盖率和精确性。②在预测实体关系方面:分类方法也可用于预测实体关系,在3.2中的关系扩充中提到了Socher等[21]训练一个张量神经网络预测新的关系;Krompaβ等[22]提出了类似的方法,使用定义的或诱导的模式对知识进行细化,可以显著提高链接的性能; Kolthoff等[23]使用了关联规则挖掘的方法寻找有意义的链接进行关系预测。实体关系也可以利用文本源进行预测;Lange等[24]在Wikipedia摘要中使用条件随机场进行模式学习。预测两个实体间的关系的另一个常用方法是远程监控;Mintz等[25]与Aprosio等[29]通过命名实体识别将知识图谱中的实体与文本语料库链接起来;然后,基于图谱中的关系寻找对应关系类型的文本模式并应用这些模式在文本语料库中寻找附加的关系;Mu?觡oz等[26]认为对于在维基百科表格中共存的两个实体,在知识图谱中可能共享一条边。为了填充这些边,首先从表中提取一组候选元素,使用在两列中可能的关系。然后,基于该提取的标签子集,使用不同的特征来进行分类以识别在知识图谱中实际存在的关系;Ritze等[27]将这种方法扩展到任意的HTML表格。
基于已建图谱的三类扩充改进,提炼出的推理主要集中在四类方法:利用逻辑推理进行规则学习、基于图谱推理和学习算法、基于推理的实体和关系嵌入以及统计关系学习方法。
(1)逻辑推理。在图谱关系中存在的规则,由抽象或具象的霍恩子句进行表示,基于逻辑规则进行推理。规则都有某种特定的属性,可以揭示在现存图谱不同关系实例中的矛盾。
在AI领域中知识图谱出现之前的一阶学习系统是GOLEM和FOIL,从数据实例中建立一阶霍恩子句规则。为了提高可扩展性,利用Dirichlet先验多项式分布估计每个N-FOIL规则的条件概率P。SOFIE是第一个将逻辑一致性图例和信息抽取进行整合的系统。该系统将已知事实、新事实假设、单词到实体的映射、模式以及約束转化为逻辑子句。将权重分配给从数据统计证据中派生出来的子句。其目的是找到满足最大约束条件的真子句,并将问题转化为加权最大满足性问题。
(2)图谱推理和学习。为了提高收敛率,各种算法已经直接对图进行推理以生成新的关系实例。随机游走相关的图算法已经用于推理,一种常用的测度方法是重启随机游走(random walk with restart, RWR)。Lao等提出了用于关系检索的路径排序算法,应用该方法在大规模知识库用“数据驱动路径寻找”完成学习和推理任务。Gardner等进一步用潜在句法线索进行推理。Wang等提出使用个性化的PageRank用于图的推理,这是对随机逻辑程序的扩展,G的随机遍历由每个节点的概率选择来定义。每条边都与一个具有各自权重的特征向量相关联,每个节点都有一条边指向受重启随机游走测度的启发,参数通过随机梯度下降(SGD)进行学习,可以适应并行学习任务。
(3)基于推理的实体和关系嵌入。知识图谱补全的目标是实现实体间的链接预测,但是传统的链接预测不适用于知识图谱的知识补全,因为知识图谱中的实体有复杂的类型和属性、知识图谱中的边也有不同的类型。现有的很多研究和工作是关于实体和关系嵌入技术的。
(4)统计关系学习。统计关系学习是可以同时表示不确定性和关系结构的模型。提供了利用机器学习的方式实现学习和推理的通用框架。马尔科夫逻辑网络在关系学习中被证明是最通用的。
马尔科夫逻辑网络(Markov logic network, MLN)是一种简单的表示,结合了概率图模型和一阶逻辑,在经常出现的冲突和不确定性的数据中,应用马尔科夫逻辑网络软化约束,每个公式都有一个权重,表示公式的强度。马尔科夫逻辑框架可以看成构建马尔科夫网络的模板。随机变化和依赖性形成了马尔科夫随机场。
受约束的概率模型不同于MLN,它是将概率和声明进行分离的模型,允许概率部分作为任意条件分布。另外,先验知识编码为约束条件,应用于信息抽取和语义角色标注。
2.4 知识集成/知识图谱融合
知识融合是使来自不同数据源的知识在同一框架规范下进行消歧、对齐、合并、推理验证、更新等的高层次知识组织。当前具有增值规模的知识库包括Wiki百科、Freebase、YAGO、微软Satobri以及谷歌知识图谱。增加现有事实规模,前期的方法都是基于文本抽取,结果会有较大的噪音。Knowledge Vault(KV)将从网页抽取的知识与现存的知识库中的先验知识相结合,同时利用监督机器学习的方法将不同的信息资源进行融合。
谷歌搜索不再是简单的网页链接,而是直接回答问题的知识引擎,不过现有的知识图谱依然依赖Freebase,KV自动进行知识扩充, KV的三个主要组件:抽取器、先验图谱学习、知识融合,通过KV的知识融合,知识图谱自动构建的新技术知识集成的借鉴。知识融合包含三种融合:实体融合、关系融合、实例融合。可细分为实体对齐和知识库融合。
将从不同数据源抽取的信息进行组合的简单方法是为抽取的每个三元组t(s,p,o)构造一个特征向量f(t),然后应用二值分类器来计算Pr(t=1|f(t)),并为每个谓词分别设置一个分类。每个抽取器的特征向量由两个数字组成:提取器从中提取此三元组的源数量的平方根,以及来自此提取器的提取内容的平均得分。此外,由于每个谓词都有一个单独的分类,也可以模拟它们的不同可靠性[28]。
2.5 事件图谱建模
基于概念的知识表示较多的描述静态特征,无法反映事物动态变化,为了动态表示,构建以事件为中心的图谱,考虑了事件的发生时间、地理属性、发生原因、事件结果、事件方案。事件在信息抽取中是指在某个特定的时间片段和地域范围内发生的,由一个或多个角色参与,由一个或多个动作组成的一件事情;在话题检测跟踪中,事件是指关于某一主题的一组相关描述。为了描述知识的动态性,用事件对知识进行表述,把事件定义为参与对象在一定时间和环境条件下进行的动态过程[29]。
事件图谱研究的层次分为三层:第一层是面向事件的语料库构建;第二层是时间识别与抽取、事件关系识别与抽取[30];第三层是面向事件的自动问答、面向事件的自动文摘。
傳统的事件抽取依赖于精细的特征设计和复杂的自然语言处理工具,消耗大量人力、易产生错误及数据稀疏问题。Chen等[31]为了捕获词汇的语义规律,并能考虑不遗漏重要信息,提出了利用动态多池化卷积神经网络(Dynamic Multi-Pooling Convolution Neural,DMCNN)进行事件抽取工作,能够从词和句层面的特征进行自动化感应,在一个句子中为每个事件抓取充分的情报。词特征层面从大量未标记数据中学到的词嵌入对于捕获词的有意义规则更为强大[32],应用Skip-gram模型预先训练词嵌入[33],句子特征层面的抽取,分为两个步骤:第一步是触发词分类,对每个句子的单词进行分类,进而识别触发词;若含有触发词,进行第二步参数分类,应用DMCNN进行参数分配并对齐参数的角色。为了提取句子层面的特征,预测触发词和参数候选词之间的语义交互是参数分类的关键, DMCNN用于捕捉这些重要线索的三种类型:①上下文词特征:将整个句子中所有单词作为上下文,通过查找单词嵌入转换的每个单词标记的向量;②位置特征(Position feature,PF):在参数分类中指定单词是候选参数,PF用来定义当前单词到预测触发器或候选参数的相对距离,每个距离值也由一个嵌入向量表示;③事件类型特征:当前触发器/触发词的事件类型对于参数分类很有价值,将触发器分类阶段预测的事件类型编码为DMCNN的重要线索。在每个特征图中为了抽取重要特征(最大价值),有必要捕捉关于候选词变化的最有价值的信息,并在参数分类阶段预测触发器/触发词。
利用融合的图谱将面向不同数据源提取的相似事件进行机器读取更有效,机器阅读可以从一个整合图中获取包含在多个文本中的知识,该问题的解决通过MERGILO,利用图谱对齐和词的相似性。Alam等[34]提出了一种对MERGILO的进化,改进的主要重点是事件融合,融合知识图谱通常用于多文档摘要,或者用于检测跨文档系列的知识演化。为了收集事件的完整语义表示,使用FRED语义网页机器读取器与框架一起使用,利用语义框架来增强提取的事件知识,基于语义框架的图形结构和框架内定义的语义角色的包容层次结构,扩展了MERGILO的相似之处。
Rospocher等[35]提出了一种从新闻文章中自动构建事件知识图谱的方法和工具。新闻文章用最先进的自然语言处理和语义Web技术来创建以事件为中心的知识图谱(ECKGs)。ECKGs以事件为中心意味着在时间和地点锚定时间并将它们链接到实体来表示长期的开发和故事线。在确定事件的关联中,首先将语义角色标签层的谓词和具有相同引文的所有谓词或在WordNet 2.0以上具有相似度评分的谓词链接到一个单独的引用集中,通过聚合来自同一源中所有引用的参与者和时间表达式来创建所谓的复合事件对象。
2.6 与LOD集成
关联数据(Linked Data)概念是万维网的发明人Tim Berner-Lee于2006年首次提出的,2007年启动关联开放数据(LOD)项目,其目的是用协议来规范发布和连接Web的各种数据,建立一个计算机能理解的、可描述的、富含语义、具有结构化的、互联互通的知识网络,从而更加高效地利用这些相互关联的信息。关联数据就是把数据通过开放标准关联在一起,揭示出数据间的相互关联和相互联系的规律,从而发现更多的新事物,产生更大的效益和更好的应用。
语义网上的知识图谱通常由关联数据提供[36]。关联数据是RDF描述的一种较新的知识表示和发布形式, RDF Schema (RDFS)的核心思想是扩展RDF词汇表,并允许将语义附加到用户定义的类和属性。RDFS由于不能表达链接实体之间的隐式语义,不能充分利用RDF的潜力。为了填补这一空白,Pu等[37]设计了新的语义标注和推理方法,从不同属性扩展更多的隐式语义。首先,为链接数据源建立了定义良好的语义增强注释策略。并提出了一种新的通用语义扩展的链接数据源方案,通过语义增强推理实现对目标链接数据源的语义扩展。LOD的语义内容结合SPARQL提供的高级搜索和查询机制,不仅为增强现有应用程序,而且为开发新的和创新的语义应用程序提供了前所未有的机会。然而,SPARQL不足以处理诸如比较、排序和排序搜索结果等功能,针对这一问题, Meymandpour等[38]提出了一种系统的关联数据资源语义相似度度量模型。提出了一种基于内容的通用信息方法。测量相似度在关联数据中是比较新的趋势。语义相似性反映了两个概念、实体、术语、句子或文档之间的均值关系。语义相似度的措施可以分为以下类别:①基于距离模型, 在语义网络中被称为边缘计数或基于路径的方法,将相似性定义为概念之间距离的函数。基于路径的方法将给定分类法中概念的相对深度融入到语义相似度评估中[39]。其他被广泛使用的基于链接的图(如万维网链接结构或引文网络)的相似性度量包括SimRank、PageRank、HITS、Co-citation和SALSA。然而,这些方法没有明确考虑链接的类型,所有链接类型都被视为相同的;②基于特征模型,该方法假设概念可以作为特征集来表示。它们根据特征集之间的共性来评估概念的相似性:概念之间公共特征的任何增加都会导致更高的相似性得分,而共享特征的任何减少都会导致较低的相似性水平。在此基础上,可以采用Jaccard、Dice等基于集合的指标进行相似性评估;③统计方法,统计相似性度量将来自基础域各个方面的统计信息合并到相似度计算中。有几种方法使用文档中术语的流行程度作为其信息量的度量,并以此作为度量相似性的基础。
3 知识图谱的应用现状
3.1 基于知识图谱的推荐系统
推荐系统是一种信息过滤系统,基于用户画像(用户所表达的偏好、过去行为或者其他数据)生成有意义的推荐,在越来越多的领域得到了应用。基于协同和基于内容的推荐系统是常用的两类,基于协同的方法需要来自许多用户的大量数据进行用户相似度的测度,从而提供有效建议,涉及到用户隐私;基于公共内容的方法测度了不同内容间的相似性。基于知识图谱的推荐系统有效地解决了上述问题。RERA[40](Relation of entities recommendation agent)充分利用了出现在用户历史记录中的实体和出现在候选内容中的实体之间的关系,提出了一种新的个性化PageRank对建议内容进行排序,分别提取实体作为用户感兴趣实体集合set1和从提议内容提取实体set2,分析两个集合连接性,进而判断内容相关性,从而实现基于内容的推荐。
知识图谱是一种表示在Web数据中编码的知识方式,也是为了提取新的和隐式信息进行推理的工具。Oramas等[41]描述了如何创建和利用一个知识图谱来提供一个混合的推荐引擎,并在描述音乐和声音项目的文档集合的基础上构建信息。基于构建的知识图谱,使用一种特性组合混合方法来计算,可以获得两个显式的图形特征映射,从而捕获嵌入在图中的知识。这些内容特性与来自隐式用户反馈的附加协作信息进一步结合在一起。最终形成混合的信息,基于此构建推荐引擎。
3.2 跨媒体推理
信息的获取、传播、处理和分析已经逐渐从一种媒体形式转变为文本、图像、视频、音频、立體图像等多种媒体类型。不同媒体类型和形式代表了全面的知识,反映了个人和群体的行为。由此,人们认识到一种新的信息形式,即跨媒体信息。传统的方法无法实现从多种媒体模式中提取语义,无法处理跨媒体数据分析,无法处理具有复杂组合、不同表示和复杂关联的跨媒体场景。在跨媒体统一表示的理论和模型、跨媒体知识图谱建设和学习方法、跨媒体知识的演变和推理等方面呈现方法、进展和未来方向。
(1)跨媒体统一表示模型。第一个跨媒体统一表示模型是CCA[42],它通过最大化两两并行异构数据之间的相关性来学习共享空间,并通过线性函数进行投影。CCA只能对两种媒体类型的相互关系建模,为了解决这一限制,Zhai等[43]和Peng等[44]通过对XMedia数据集(包含了文本、图像、视频、音频和3D模型)的五种媒体类型进行图形正则化,在统一框架下对相关性和语义信息进行联合建模;Yang等[45]提出了多媒体文档(Multimedia document,MMD)模型,每个MMD具有不同模式但是相同语义的媒体对象,MMD之间的距离与每个模态相关,这样就可以进行跨媒体检索;主题模型是跨媒体统一表示学习中另一种技术,假设包含相同语义的异构数据共享一些潜在的主题,Roller等[46]将视觉特征融入到LDA中,提出了一种多模态LDA模型来学习文本和视觉数据的表示,Wang等[47]提出了一种称为多模态相互话题强化模型(multimodal mutual topic enhanced model, M3R)的方案,该方案旨在通过模型因素之间的适当交互来发现相互一致的语义话题。
(2)跨媒体知识图谱建设和学习方法。在跨媒体检索中,不仅从文本数据语料库中定义和提取实体和关系,而且从文本、图像、视频等大量松散数据形式中提取实体和关系,跨媒体知识图谱为跨媒体语境下的语义关联分析和认知层次推理提供了基本的可计算的知识表示结构,促进了跨媒体智能的理论和技术发展。为了将数据网络转化为知识网络,Suchanek和Weikum[48]认为跨媒体知识图谱的研究需要考虑几个问题;首先,研究从异构跨媒体信息源中提取实体和构建关系的有效技术;其次,研究基于跨媒体知识图谱的信息搜索与检索,为更多样化的应用环境提供更有效的知识获取和信息检索机制;第三,开发跨媒体知识图谱的挖掘和推理,促进知识的获取和对实际应用的高层次推理;第四,需要知识驱动的跨媒体学习模型来实现更多的泛化和学习能力,从而产生更高级的跨媒体智能。
(3)跨媒体知识的演变和推理。现实世界中的知识和推理过程通常涉及语言、视觉和其他类型的媒体数据间的协作。大多数现有的智能系统仅利用来自单一媒体类型的信息来执行推理过程。视觉问答(Visual question answer, VQA)是跨媒体推理的一个很好的案例[49]。VQA的目的是以图像和自然语言相结合的形式,为所给的问题提供自然语言的答案。Johnson等[50]试图借助场景图来提高图像检索的并行性,这也体现了跨媒体推理的思想。场景图表示对象及其属性和关系,可用于指导语义级的图像检索。然而,这些系统仍然难以充分利用互补媒体类型所包含的丰富语义信息,无法对多媒体进行复杂的跨媒体分析和推理。
跨媒体大数据本质上是多模态、跨领域的,使用不同的表示形式和复杂的关联。现有的智能系统和框架在很大程度上依赖于特定领域的结构化输入和知识。高效的智能引擎将成为技术与应用之间的桥梁,可以整合跨媒体的统一表示、关联学习、知识进化、推理等。人工智能时代的到来,以及海量跨媒体数据的可用性,正在彻底改变所有行业的格局。其中,跨媒体Web内容监控、Web信息趋势分析和医疗数据融合与推理是三个关键的应用,以医疗数据融合与推理为例,数据驱动的医疗分析基于海量跨媒体数据的融合,正在将经验诊断和循证医学改革为个性化和精准医疗。医疗分析是一个关键的技术,为广泛的现实所应用(见图5)。
3.3 知识图谱在生物医学领域的应用
生物医学领域知识的复杂性和规模性推动了从结构化和非结构化知识库中挖掘异构数据的研究工作。在这个方向上,有必要结合事实,形成关于领域概念的假设或者结论。
在生物医学领域,各种知识的发展规模和速度已经超过个人的能力。目前大规模数据给医学领域带来信息提取及知识融合产生新知识这两个难题。Swanson[52]展示了在结合不同来源的事实中发现新的、未知知识的潜力;Srinivasan等[53]开发了一套系统,该系统通过一组预定义类型的共现概念,从感兴趣的概念开始搜索两个概念间的路径,从而发现潜在关系;Weissenborn等[54]利用依赖关系树作为句子中两两概念的句法依存工具,在知识表示和融合中,基于知识图谱将异构的知识集成到一个一致的表示模式,解决概念的相互映射问题,并利用语义向量减少关系空间。通过训练模型发现不能直接提取的概念之间的隐藏关系,可以进行全新知识的推断;Vlietstra等[55]展示了如何从生物医学文献和结构化数据库中提取语义集成的知识来自动识别潜在的偏头痛生物标志物。
药物间的相互作用(Drug-Drug interaction,DDIs)是可预防的药物不良反应的主要原因。已知现有的公共和专有的DDI信息来源不完整或不准确。Abdelaziz等[56]提出了一种基于相似度的大规模框架Tiresias,通过链路预测来预测DDIs。Tiresias将各种与药物相关的数据和知识来源作为输入,并将DDI预测作为输出。这个过程从输入数据的语义集成开始,生成一个描述药物属性的知识图谱,以及与各种相关实体(如酶、化学结构等)的关系。然后使用知识图谱在可伸缩和分布式框架中计算所有药物之间的几个相似性度量。
3.4 其他
知识图谱在语音识别、智能问答、网页生成视频、图像特征学习等方面都有广泛的应有。此外,知识图谱在垂直领域的应用也很广泛,包括让消费者能快速掌握产品功能及技术的产品知识图谱、金属材料知识图谱、地质知识图谱、交通知识图谱、城市治理知识图谱等领域方面的应用。
4 结语
文章从文献计量和主题内容挖掘出发,分析了知识图谱的研究进展及其相关新技术发展,更详细地讨论了知识图谱的构建、改进和应用方面的现状和面临的主要挑战,以及处理这些问题的方法。
可以看出,近年来知识表示、知识组织和知识理解已经成为最重要的知识系统。现有学术研究和产业界提出了大量与知识图谱加速发展相关的研究问题、应用和产品。然而,在知识图谱领域仍然存在着诸多机遇和挑战,特别是在强调知识集成、知识服务、知识发现的情报学领域,研究对象已经深入到知识内容层面,知识图谱为情报研究发展提供了很好的思路。富媒体时代,随着需求的不断增加,以及知识图谱的涌现,需要在数据、对象、情景、作用和工作流等层面进行图谱集成、推理、应用方面的评估,并利用图谱中的各類感知信息及关系在各领域展开更为智能和广泛的应用。
参考文献:
[1] Rober Neches,Richard Fikes,Tim Finin,et al. Enabling technology for knowledge sharing[J].Ai Magazine,1991,12(3):36-56.
[2] Studer R,Benjamins V R,Fensel D.Knowledge engineering principles and methods[J].Data and knowledge engineering,1998,25(1/2):161-197.
[3] Liu X,Li Y,Wu H,et al.Entity linking for tweets[J].ACL,2013(1):1304-1311.
[4] Dredze M,Mcnamee P,Rao D,et al.Entity Disambiguation for Knowledge Base Population[C].Association for Computational Linguistics,2010.
[5] Socher R,Chen D,Manning C D,et al.Reasoning With Neural Tensor Networks for Knowledge Base Completion[C].International Conference on Neural Information Processing Systems,2013.
[6] Yu Zhao,Sheng Gao,Patrick Gallinari,et al.Knowledge base completion by learning pairwise-interaction differentiated embeddings[J].Data Mining and Knowledge Discovery,2015,29(5):1486-1504.
[7] Lange D,Christoph B?觟hm,Naumann F.Extracting structured information from Wikipedia articles to populate infoboxes[C].Acm International Conference on Information & Knowledge Management.ACM,2010.
[8] Wu F,Hoffmann R,Weld D S.Information extraction from Wikipedia:moving down the long tail[C].Acm Sigkdd International Conference on Knowledge Discovery & Data Mining,2008.
[37] Pu L,Bao X,Aftab A,et al.SES LDS:An Extension Scheme for Linked Data Sources Based on Semantically Enhanced Annotation and Reasoning[J].International Journal of Intelligent Systems,2017,33(7209):233-258.
[38] Rouzbeh Meymandpour,Joseph G.Davis.A semantic similarity measure for linked data:an information content-based approach[J].Knowledge-Based Systems,2016,109:276-293.
[39] Leacock C,Chodorow M.Combining Local Context and WordNet Similarity for Word Sense Identification[C].WordNet:An Electronic Lexical Database,1998.
[40] Chaudhari S,Azaria A,Mitchell T.An entity graph based Recommender System[J].AI Communications,2017,30(2):141-149.
[41] Oramas S,Ostuni V C,Noia T D,et al.Sound and Music Recommendation with Knowledge Graphs.[J].ACM Transactions on Intelligent Systems and Technology,2016,8(2):1-21.
[42] Rasiwasia N,Costa Pereira J,Coviello E,et al.A new approach to cross-modal multimedia retrieval[C].ACM Int.Conf.on Multimedia,2010:251-260.
[43] Zhai X,Peng Y,Xiao J.Learning cross-media joint representation with sparse and semi-supervised regularization[J].IEEE Trans.Circ.Syst.Video Technol.,2014,24(6):965-978.
[44] Peng Y,Zhai X,Zhao Y,et al.Semi-supervised cross-media feature learning with unified patch graph regularization[J].IEEE Trans.Circ.Syst.Video Technol.,2016,26(3):583-596.
[45] Yang Y,Zhuang Y,Wu F,et al.Harmonizing hierarchical manifolds for multimedia document semantics understanding and cross-media retrieval.[J].IEEE Trans.Multim.,2008,10(3):437-446.
[46] Roller S,Schulte im Walde S.A multimodal LDA model integrating textual,cognitive and visual modalities[C].Conf.on Empirical Methods in Natural Language Processing,2013:1146-1157.
[47] Wang Y,Wu F,Song J,et al.Multi-modal mutual topic reinforce modeling for cross-media retrieval[C].ACM Int.Conf.on Multimedia,2014:307-316.
[48] Suchanek F,Weikum G.Knowledge bases in the age of big data analytics[C].Proc.VLDB Endow.,2014:1713-1714.
[49] Antol S,Agrawal A,Lu J,et al.VQA:visual question answering[C].IEEE Int.Conf.on Computer Vision,2015:2425-2433.
[50] Johnson J,Krishna R,Stark M,et al.Image retrieval using scene graphs[C].IEEE Conf.on Computer Vision and Pattern Recognition,2015:3668-3678.
[51] Peng Y,Zhu W,Zhao Y,et al.Cross-media analysis and reasoning:advances and directions[J].Frontiers of Information Technology & Electronic Engineering,2017,18(1):44-57.
[52] Swanson D R,Fish Oil.Raynauds Syndrome,and Undiscovered Public Knowledge[J].Perspectives in Biology and Medicine,1986,30(1):7-18.
[53] Srinivasan P,Libbus B,Sehgal AK.Mining medline:Postulating a beneficial role for curcumin longa in retinal diseases[C].Workshop BioLINK,linking biological literature,ontologies and databases at HLT NAACL,2004.
[54] Weissenborn D,Schroeder M,Tsatsaronis G.Discovering relations between indirectly connected biomedical concepts[J].Journal of Biomedical Semantics,2015,6(1):1-19.
[55] Vlietstra W J,Zielman R,van Dongen,et al.Automated extraction of potential migraine biomarkers using a semantic graph[J].Journal of Biomedical Informatics,2017,71:178-189.
[56] Abdelaziz I,Fokoue A,Hassanzadeh O,et al.Large-scale structural and textual similarity-based mining of knowledge graph to predict drug-drug interactions[J].Web Semantics:Science,Services and Agents on the World Wide Web,2017,44:104-117.
作者簡介:谭晓(1983-),女,北京市科学技术情报研究所助理研究员,博士,研究方向:情报方法研究、战略情报、文本挖掘;张志强(1964-),男,中国科学院成都文献情报中心研究员,博士生导师,研究方向:科技战略与规划、科技政策与管理、科学计量学与科技评价。
