基于深度学习的室内动态场景下的VSLAM方法
2020-12-14徐晓苏安仲帅
徐晓苏,安仲帅
(1.微惯性仪表与先进导航技术教育部重点实验室,南京 210096;2.东南大学仪器科学与工程学院,南京 210096)
视觉同时定位与地图构建(VSLAM)技术是无人驾驶、工业机器人、AR/VR、自主导航[1]等应用的基础技术。由于VSLAM 中的图像含有丰富的信息,并且和人类利用眼睛完成自身定位的机理类似,其在近年获得了较大的发展,许多先进的VSLAM 算法被不断提出,比如:ORB-SLAM2[2],SVO[3],DSO[4]等等。然而,这些算法大都基于静态环境的假设,一旦应用于道路行驶等动态环境,算法会受到运动物体的干扰,导致定位漂移,跟踪丢失等问题,严重影响算法的定位精度以及稳定性。
为了解决上述问题,已经有人进行了尝试。Zhong等人于2018年提出了Detect-SLAM[5],该算法利用SSD目标检测神经网络来检测物体,然后通过特征匹配和增加影响区域的方式完成运动概率的传播,以此来去除动态点的影响;然而由于目标检测框的范围较大,因此会导致误删除较多静态点。Berta 等人也在2018年提出了Dyna-SLAM[6],该方法使用了MASK R-CNN[7]实例分割网络和多视图几何的方法来筛选出动态特征点,此外还结合了区域生长算法来去除图片中的动态物体,然而由于MASK R-CNN 运行频率只能达到5Hz,所以该算法不能实时运行。Yu 等提出了DS-SLAM[8]算法,该方法在ORB-SLAM2的基础上结合了SegNet 语义分割网络,从而去除了环境中的运动的人的影响,并且可以构建语义八叉树地图[9]。
本文针对现有的SLAM算法在动态环境下定位精度较低、鲁棒性较差、特征容易跟丢且提取较慢等问题,对现有SLAM 算法进行了改进,主要完成了以下工作:
1.对ORB-SLAM2算法进行改进,利用GCNv2神经网络替换传统的基于图像金字塔的特征提取的方法,在不影响精度的同时,极大地提升了前端在提取特征时的速度。此外,GCNv2网络在动态环境下相比传统方法也有着更好的稳定性。
2.利用轻量级的ESPNetv2语义分割网络,来完成像素级的语义提取,结合改进的移动一致性检测来剔除动态特征,提升了动态场景下的定位精度。
3.建立带有语义信息的点云地图和八叉树地图,为机器人的导航、定位、智能交互提供语义信息。
4.在慕尼黑工业大学的TUM 数据集上,与ORB-SLAM2进行对比,评价本文算法的有效性。
1 算法组成
1.1 算法框架
本文算法在ORB-SLAM2的RGB-D模式的基础上进行改进,在原本的跟踪、局部建图和回环检测三线程之上,增加了用于语义分割的线程和建立语义八叉树地图和语义点云地图的线程。整体算法框架如图1所示,由RGB-D相机得到的RGB图像同时传入跟踪线程和语义分割线程,在跟踪线程中,利用GCNv2网络来替代原本的基于图像金字塔的ORB特征点提取方式,然后对网络输出进行非极大值抑制,得到ORB特征点和描述子。在语义分割线程中利用ESPNetv2对RGB图像进行像素级的语义分割,得到每个像素的语义标签。通过移动一致性检测获得潜在的运动局外点,如果在物体的语义边界内有超过一定数量的潜在运动局外点,那么将此物体视为运动物体,将其中的动态特征作为局外点剔除,利用剔除后的静态特征进行位姿估计,并根据语义分割的结果赋予点云不同的颜色来生成语义地图和八叉树地图。
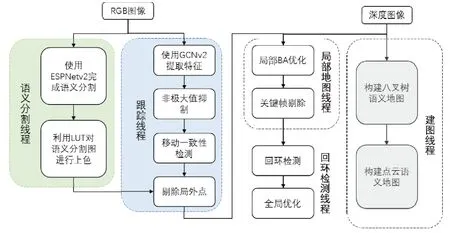
图1 算法框架图Fig.1 Algorithm frame work
1.2 特征提取
传统的ORB特征提取通过将输入图像的分辨率不断降低,组成不同分辨率的图像金字塔,然后对每一层图像划分成许多30×30像素的网格,在每个网格中提取角点,最后对提取的角点来计算描述子,因此,整个过程的计算十分复杂,非常耗时。为了改进传统的基于图像金字塔的特征提取方法在动态环境下鲁棒性不足以及计算量较大问题,本文使用基于Pytorch实现的GCNv2[10]神经网络来直接获得ORB特征点和描述子。
GCNv2使用TUM和SUN-3D[11]数据集进行训练,不同于其他使用单张图片进行训练的网络,GCNv2使用图像对进行训练,通过将图像对之间的相对位姿参与到损失函数的设计中来,可以让本网络所提取的特征更加适用于特征匹配和计算位姿,因此,其获得的特征相比传统方法,在动态环境下的鲁棒性高,不容易发生特征的跟丢。如图2所示,GCNv2将单通道灰度图片调整为320×240像素的大小输入网络,通过前向传播得到两个矩阵:一个是3×320×240像素的包含特征点位置信息和置信度的矩阵,另外一个是256×320×240像素的包含对应描述子的矩阵。然后对特征进行非极大值抑制和均匀化处理,具体步骤如下:首先为了处理边缘的特征,对图像的边缘进行插值填充,将原图像扩充为328×248像素,然后将图像划分为许多8×8像素的网格,提取出每个网格中置信度最大的特征点的索引,根据索引查找对应的描述子,最终获得了分布均匀的特征点及其对应描述子。

图2 GCNv2网络完成特征提取Fig.2 Feature extraction using GCNv2network
1.3 语义分割
为了得到图像中每个像素的语义标签,进而确定潜在的运动目标,本文采用Mehta等人于2019年提出的一种轻量级、高效率、通用的卷积神经网络:ESPNetv2[12]来完成图像的语义分割任务。近年来不断有学者提出新的语义分割网络,但是大多追求分割的准确性,导致运行速度较慢,如:PSPNet[13]速度为5帧/秒,SegNet[14]为17帧/秒,而ESPNetv2由于使用了新的轻量化的CNN架构,拥有着更快的速度以及更少的参数,其最快速度为83帧/秒。因此综合速度和精度两方面考虑,选择ESPNetv2。此网络基于Pytorch 实现,使用PASCAL VOC2012[15]数据集进行训练,可以将图片分割成包括背景在内的21个类别。
语义分割的处理过程如图3所示,ESPNetv2的输入是384×384大小的RGB图像,而网络的输出是384×384像素的单通道灰度图,每个像素点的灰度值表示其代表的语义标签,我们对网络输出使用LUT 查表法上色处理,最终输出彩色的语义分割图。
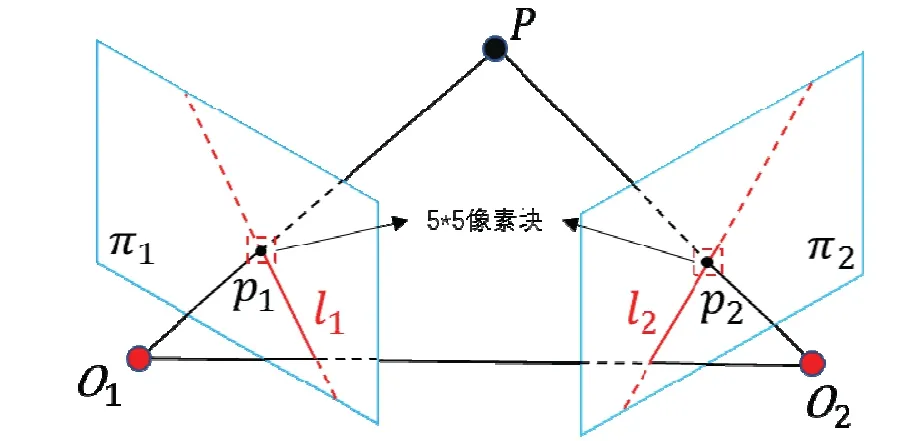
图3 ESPNetv2网络完成语义分割Fig.3 Semanticsegmentation using ESPNetv2
1.4 改进的移动一致性检测
利用语义分割,我们可以获得具有潜在运动可能性的区域,但是考虑到可能存在着静止的人等特殊情况,因此还需要进一步来判断潜在的运动目标是否真的在运动。常用的检测动态点的方法为背景减除法和帧间差分法[16],基本原理均是基于图像的差分,在相机静止时可以取得较好的效果,但均不适用于相机运动的情况。基于稠密光流的运动物体检测方法虽然可以用于相机运动的情况,但因为要跟踪每一像素点的光流,实时性较差。因此本文采用DS-SLAM[8]中提出的基于稀疏光流的动态点检测方法:移动一致性检测,并对其进行改进,详细讨论了点在极线上和极线外两种情况。
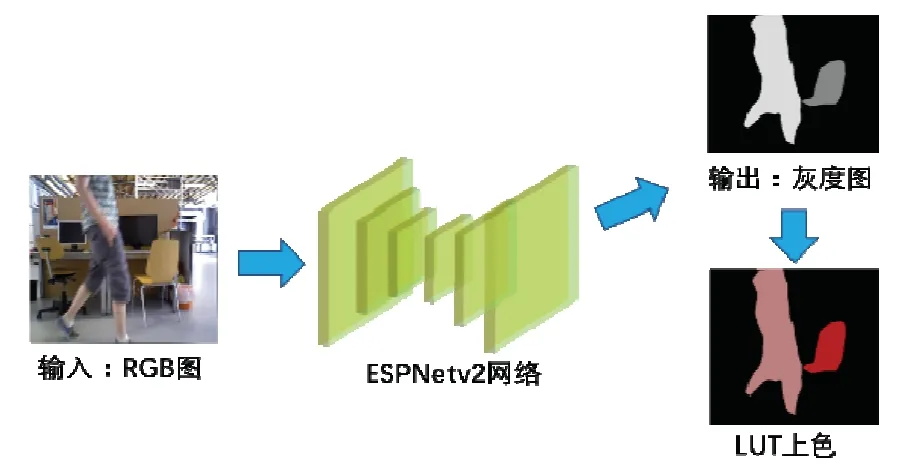
图4 移动一致性检测Fig.4 Mobileconsistency detectio n
其原理如图4所示,左右两个四边形表示在不同位置的相机的成像平面π1和π2,O1,O2表示相机的光心,点p1,p2表示空间点P在不同屏幕投影的像素坐标,其对应的归一化坐标为P1,P2:

点P,O1,O2组成的平面和成像平面相交所产生的直线就是极线:l1,l2,根据对极几何的知识可知,基础矩阵F表示的就是P1到极线l2的映射,即:
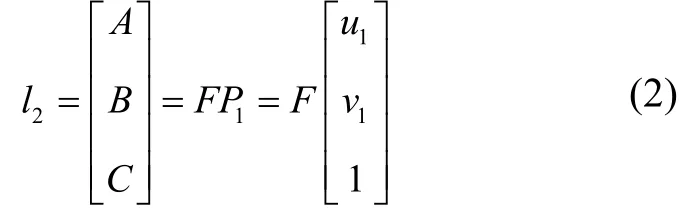
因此,极线l2表示空间点P在π2平面上可能的投影位置,极线l2在平面的方程为Ax+By+C=0,因此,我们可以根据p2和极线l2之间的关系来判断p2是否是一个动态点,因为所有的静态点都应满足上述投影模型,如果不满足则说明该点是动态的。
基础矩阵F的计算则是通过跟踪连续两帧之间的稀疏光流找到匹配的特征点,然后带入式(3)求出。

我们可以将p2和l2之间的位置关系分为以下两种:
1) 点p2在极线l2外:
则计算点到直线之间的距离,即p2到l2之间的距离D:

如果距离D大于阈值,那么判断为动态点。
2) 点p2在极线l2上:
即使p2在l2上,也不能确定p2就是静态点,考虑到l2上可能存在着很多和p2相似的点,如图4所示,我们取p1和p2周围大小为5×5 的像素块,来进行块匹配,判断像素块之间的相似度。本文使用去均值的归一化互相关(NCC)来计算像素块之间的相似度,计算公式如下:

其中p1和p2周围的5×5 像素块分别记为:A、B,而其均值分别为:、,其中i,j=- 2,- 1…1,2。两个像素块之间相似度够高则认为是静态点,否则是动态点。
如果语义分割得到的潜在的运动目标范围内存在的动态点的数量超过一定阈值,则认为目标是运动的,将其范围的特征点作为局外点剔除,使用剩下的静态特征点进行位姿估计。否则,将目标视为是静止的,其范围内的特征点将会全部参与位姿估计。这样,可以更为准确地判断环境中的动态物体,提升动态环境下的定位鲁棒性。
2 试验验证与结果分析
本文采用德国慕尼黑工业大学开源的 TUM RGB-D 数据集[17]来验证本文算法在动态环境下的鲁棒性和定位精度。该数据集包括了39 个不同室内环境的图像序列,由RGB-D Kinect 相机以30 Hz 的频率录制,内容包括:RGB 图、深度图,以及由动作捕捉系统获得的相机轨迹真值。其中的sitting 和walking 两个子序列是动态环境,sitting 序列是两个人坐在桌子前,同时伴随着小幅度运动,而walking 序列则是两人围绕着桌子做大幅度的运动。此外,这两个动态子序列还对应着四种相机的运动方式(1)halfsphere:相机沿着直径1 m 的半球面运动;(2)xyz:相机沿着x,y,z轴方向运动;(3)rpy:相机沿着横滚、纵摇、方位轴转动;(4)static:相机静止。
本文使用的评价指标为绝对轨迹误差(ATE),该指标通过比较真值和估计值之间的位移差来进行评估。第i帧的绝对轨迹误差ATEi计算公式如式(6)所示:

其中,i= 1…n,n为总帧数,Qi,Pi∈SE(3)分别表示第i帧的真实位姿和估计位姿,S∈SE(3)表示从估计位姿到真实位姿的变换矩阵,trans()表示只取位姿中的平移部分。我们对绝对轨迹误差分别计算其对应的均方根误差(RMSE)、均值(Mean)、中值(Medium),其中均方根误差(RMSE)的计算公式如式(7)所示:

实验的运行环境为:Intel Core i7-9750H,8GB 内存,NVIDIA GTX-1650,4GB 显存。
2.1 特征提取实验
为了验证使用GCNv2 神经网络来提取特征相对于传统方法更具优势,我们仅将ORB-SLAM2 算法的前端的提取特征部分替换成使用GCNv2 网络,而其他的部分保持不变,以此来保证公平。我们分别使用运动幅度较小的sitting 序列和静态序列来比较两种方法的定位精度和速度。评价的指标是绝对轨迹误差的均方根误差(RMSE)和平均每帧跟踪的时间以及其变化幅度。其中变化幅度的定义为:

其中ori表示ORB-SLAM2的运行结果,ours表示本文提出的方法的运行结果。
从表1可以看出,无论在静态场景或是在弱动态场景下,利用GCNv2来提取特征,相比传统方法在精度上皆有提升;此外,提取特征的速度也有提升,提升的幅度在10%~50%之间。
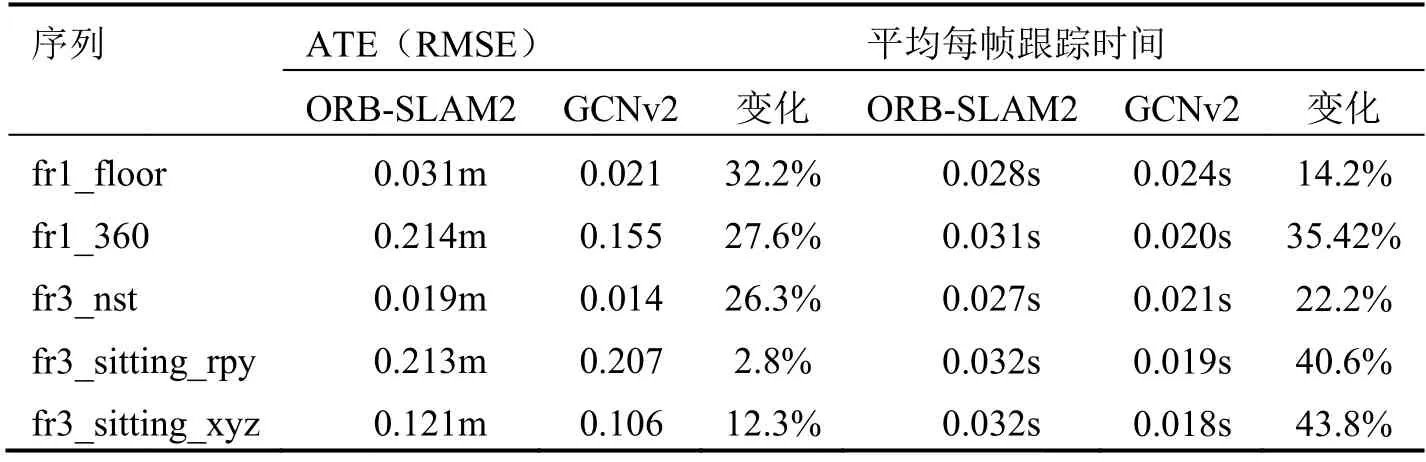
表1 ORB-SLAM2和GCNv2的绝对轨迹误差和平均每帧的跟踪时间对比Tab.1 Comparison of the ATEand theaverage tracking speed per frame between ORB-SLAM2and GCNv2
图5则显示了利用改进的移动一致性检测所得到的动态点和极线,其中,标注的红点为动态特征点,红线为极线。

图5 动态点与极线Fig .5Dynamic points and polar lines
2.2 定位误差实验
为了验证本文算法在较大动态环境下的性能,我们使用高动态场景的walking 子序列分别对ORB-SLAM2和本文的完整算法进比较。
表2显示了ORB-SLAM2 和本文算法在高动态的walking 子序列中的绝对轨迹误差的比较,其中的half表示halfsphere序列。可以从表格看出,本文算法的绝对轨迹误差有着较为明显的减少,减少幅度在87%至98%之间,平均减少95%。

表2 ORB-SLAM2和本文算法的绝对轨迹误差的对比Tab.2 Comparison of the ATE between ORB-SLAM2and our algorithm
图6(a)显示了walking_half 序列中,ORB-SLAM2和本文算法在x、y、z轴方向上的位移估计值和真值的比较。(b)则显示了姿态角真值和估计值的比较。(c)和(d)显示了ORB-SLAM2和本文算法在x,y轴平面估计值和真值的可视化轨迹曲线,其中,黑线为轨迹真值,蓝线为实际运行轨迹,红线为距离误差。由图像可知,本文算法明显提升了在动态环境下的定位准确性。
将本文算法与同类算法进行实时性比较分析如表3所示,其中Mask Fusion 的实时性和其跟踪的模型数目有较大关系,当动态目标较多时,耗时将大大增加。根据表格可以看出,本文算法相比同类型算法具有较好的实时性。
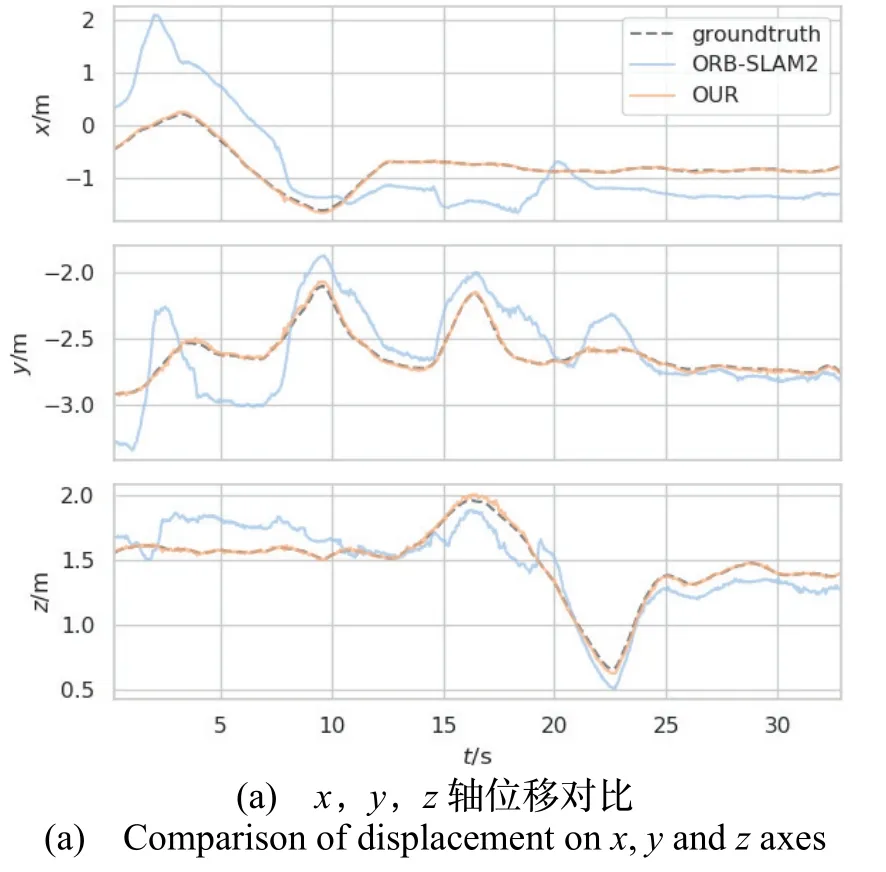

图6 fr3_walking_half 序列中ORB-SLAM2和本文算法的位移、姿态角和轨迹对比Fig.6 Comparison of displacement,rotation and trajectory between ORB-SLAM2and the proposed algorithm in sequence fr3_walking_half
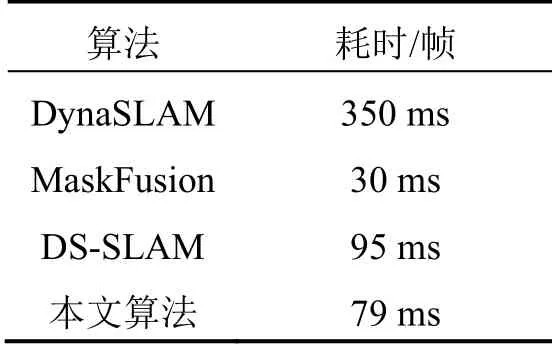
表3 时间对比Tab.3 Timecomparison
2.3 语义点云地图和语义八叉树地图
本文算法借助PCL 库和OctoMap库来分别构建点云地图和八叉树地图。为了验证算法在动态环境下的建图效果,使用TUM 数据集中的walking_halfsphere子序列,在该序列中存在着两个持续运动的行人,如图7(a)所示。本文算法将环境中的动态行人进行过滤并剔除,最终生成不包含动态物体的静态地图,并在静态地图上标注出语义信息,构建出的静态语义地图如图7(b)、7(c)所示,其中(b)为构建的点云地图,(c)为构建的八叉树地图,地图中的椅子被上色为红色,显示器被上色为蓝色。

图7 包含动态物体的图像序列与生成的静态地图Fig.7 Imagesequencescontaining dynamicobjectsand generated static maps
3 结论
本文提出了一种基于深度学习的室内动态场景下的VSLAM方法。该方法在ORB-SLAM2的系统上融入了GCNv2和ESPNetv2神经网络,分别来完成特征提取和语义分割,结合改进的移动一致性检测,将环境中的动态特征剔除,提高了系统在动态环境下的定位精度和稳定性。本文通过TUM 数据集对算法进行了实验验证。实验结果表明,本文算法可以明显提升原系统在动态环境下的定位精度。但本文算法仍有改进空间,首先语义分割网络的像素分割的准确性有待提升,后续会改用准确率更高的网络。此外,本文算法主要面向室内,未来将重点关注道路行驶等室外场景下的动态环境处理。
