基于深度迁移学习的垃圾分类系统设计与实现
2020-12-14张晓春段爱华
武 凌, 王 浩, 张晓春, 周 健, 段爱华
(安徽财经大学 管理科学与工程学院, 安徽 蚌埠 233030)
随着深度学习的持续火热,计算机视觉以及自然语言处理等领域通过引入深度神经网络而得到了快速的发展.卷积神经网络(convolutional neural networks,CNN)是一种包含卷积计算,具有深度结构的前馈神经网络.近几年CNN在推荐系统、遥感科学、大气科学等领域也有较好的应用,文献[1]提出了一种基于卷积神经网络的多样性关键数据并行推荐算法,文献[2]从遥感图像中学习特定特征并对图像进行分类,文献[3]提出了一种结合3D卷积网络异常检测的方法,修改了分类网络的3D卷积网络结构,提升了分类网络的性能.
在深度学习模型的应用开发中多采用迁移学习的方式通过预训练模型来训练自己的模型,使用预训练模型进行微调是深度迁移学习中非常重要的方式.随着我国城市生活垃圾产生量的迅速增长,如何做到垃圾的无害化、资源化处理是急需解决的问题,对垃圾进行有效地分类是分类处理的前提.目前垃圾识别分类的主要技术是利用传统的机器视觉算法,或者采用传感器进行筛选识别[4],人工分拣垃圾环境差、任务繁重且分拣效率低.随着深度学习的发展,利用迁移学习识别垃圾种类是完全可行的,而且自动智能识别可以在很大程度上提高垃圾识别的准确率和工作效率.陈宇超等[5]使用MobileNet模型对医疗垃圾进行分类和识别,向伟等[6]提出一种改进CaffeNet的卷积神经网络模型对水面垃圾进行识别.利用预训练模型的优点在于不需要原数据与新的图像数据一致,只是将模型的自动提取特征的能力移植过来,对相关参数进行微调,构建适合新数据的神经网络.
1 相关技术基础
1.1 深度迁移学习
典型的CNN分类器包括卷积基和分类器2个部分,重用预训练模型时,先删除原始的分类器,然后添加一个适合的新分类器,最后根据图1所示的3种策略[7]中的一种或多种对模型进行微调.
1.2 图像分类预训练模型
VGGNet是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,其成功地搭建了16~19层的深度卷积神经网络.从2014年后搭建层数更深的网络模型成为卷积神经网络的一个重要研究方向,谷歌团队提出了同时加深网络模型的深度和宽度的思想,设计出一系列的Inception模型.受到ResNet优越性能的启发,谷歌在2016年设计并开发了InceptionResNetV2,在Inception模块中引入Resnet的残差结构,缓解了增加深度带来的梯度消失问题.VGG16、InceptionV3和InceptionRes Netv2这3种模型的性能参数如表1所示.

图1 使用预训练模型的3种微调策略

表1 VGG16、InceptionV3和InceptionResNetv2准确率和网络结构的对比[8]Table 1 Comparison of VGG16、InceptionV3 and InceptionResNetv2 accuracies and network structures
2 模型设计
2.1 数据集分析
数据集中有6类可回收垃圾,共2 527张垃圾图像,其中纸板(cardboard)403张、玻璃(glass)501张、金属(metal)410张、纸张(paper)594张、塑料(plastic)482张、其他垃圾(trash)137张,每张图像高度为384像素、宽度为512像素、颜色为3通道.所有的图像按照类别放在不同的目录中,数据集总大小近47 MB.
2.2 搭建开发环境
使用Anaconda3搭建了开发和运行环境,硬件设备为Intel(R) CoreTMi5-4460 CPU @3.20 GHz、16 GB内存、8 GB NVIDIA显卡2070,采用了64位Windows 10系统、Python 3.6、Tensorflow-gpu 1.15.1、Keras 2.2.4,使用Jupyter Notebook作为开发环境.
2.3 加载数据集
首先读入6个子目录,生成文件清单列表list.txt,文件中包含了所有的图像文件所在的相对路径和对应类别.将数据集按照8∶2分割为训练集和测试集,训练集为2 022张(训练过程中还会将训练集按8∶2分割出验证集)、测试集为505张,将list.txt随机分割为训练集文件清单list_train.txt和测试集文件清单list_test.txt.读入list_train.txt和list_test.txt文件中的每一行,通过keras.preprocessing.image中的load_img函数加载每一幅图像,通过keras.preprocessing.image的img_to_array函数转换为多维数组,最后通过模型自带的preprocess_input函数处理为模型可以使用的4D张量,训练集x_train的形状为(2022, 384, 512, 3),测试集x_test的形状为(505, 384, 512, 3).
2.4 模型选择
采用了3种模型来构建和训练卷积神经网络用于可回收垃圾图像的分类, 对于较浅层的VGG16和InceptionV3直接使用全部的层进行训练, 对于层数较多的InceptionResNetV2则采用2种方式进行微调. 模型测试过程共进行4次, 如表2所示, 下面给出了这3种模型搭建过程中的要点并对训练结果的性能进行了分析和对比.

表2 3种模型及其使用策略Table 2 Three models and their strategies
3种模型在数据预处理和模型架构方面有以下3点相同的地方:①都使用模型自带的预处理函数对图像进行预处理,如上述的3种模型都自带Processing预处理模块,其处理过程可以更好地使进入模型的张量适用于这种模型;②代码采用Keras进行设计,加载模型时使用参数include_top=False设定为不使用最后一层,并添加全连接层更换为需要识别的分类数,最后的全连接层输出的类别数为6,使用softmax激活函数;③通常的全连接层由于参数很多,大约占整个神经网络参数的80%,在近期一些性能优异的网络模型对全连接层进行了优化或替代,例如GoogLeNet和ResNet等新兴网络都是采用全局平均池化替代全连接层来融合学到的深度特征,用全局平均池化替代全连接层的网络通常有较好的预测性能,我们在设计模型时也采用了全局平均池化.
试验1 使用VGG16预训练模型
一开始搭建了十几层到几十层的CNN网络,经过多次调参,效果都很差;后来使用了经典的VGG16网络,分类效果还是较差,甚至结果曲线都不收敛,图2给出了VGG16模型的训练过程,训练过程中batch_size的大小为16,用训练集中的20%作为验证集,Epoch为50.从图中可以看出训练过程中损失值和准确率从第2轮训练开始就不再发生变化,这是由于相对此数据集而言,VGG16网络的层数还是较浅.

图2 VGG16的损失值和准确率不收敛Fig.2 The loss value and accuracy of VGG16 do not converge
试验2 使用InceptionV3预训练模型
如图3所示是使用InceptionV3网络的损失值与准确率的变化,训练过程中batch_size的大小为16,用训练集中的20%作为验证集,Epoch为50.虽然训练出来的模型已经可以识别,但识别率比较低,只有80%左右,这是因为该垃圾数据集图像均为高384像素,宽512像素,3通道的图像,并且有些类别的垃圾特征比较接近且特征较多,较浅的网络仍然无法达到理想的识别效果.在训练集和验证集上的准确率都不高,模型处于欠拟合状态.
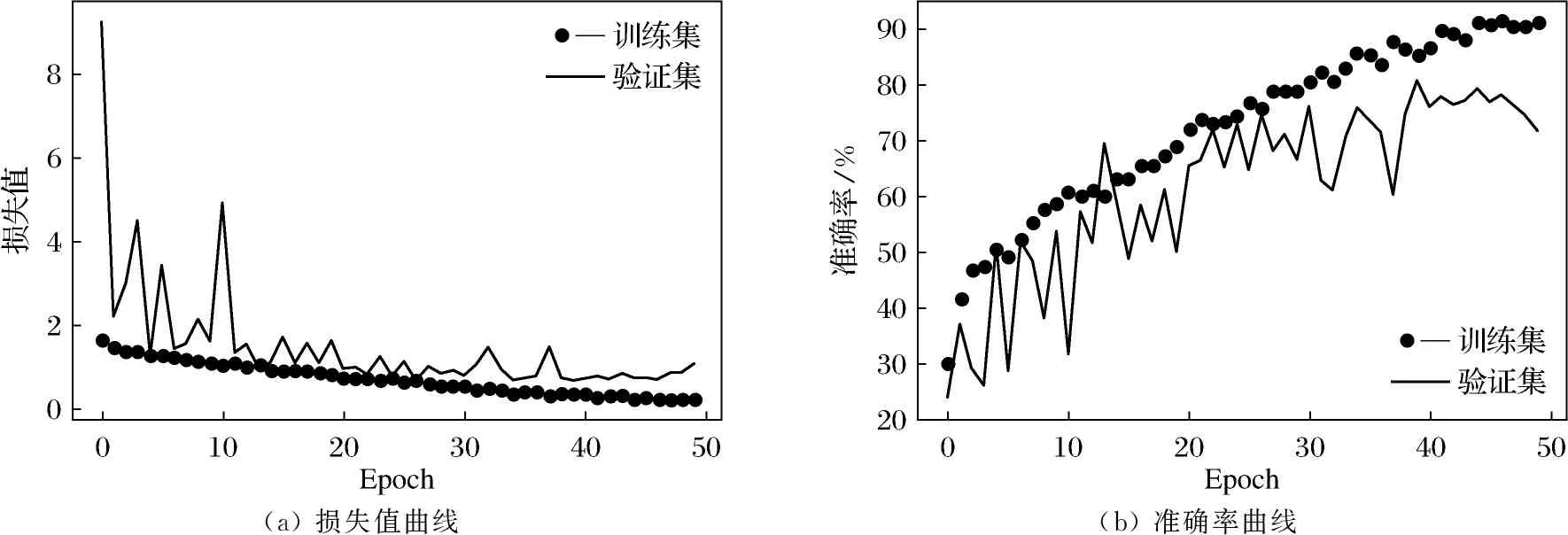
(a) 损失值曲线(b) 准确率曲线
试验3 使用InceptionResNetV2以策略1微调和训练
根据策略1的要求将卷积基全部冻结,由于InceptionResNetV2网络层数较深,batch_size较大会出现显存不够的现象,训练过程中batch_size的大小为4,用训练集中的20%作为验证集,Epoch为50,训练过程中的损失值和准确率变化如图4所示,可以看出这种方式在验证集上准确率只能达到81%左右,与InceptionV3相当,在训练集和验证集上的准确率都不高,模型处于欠拟合状态,但是损失值和准确率比InceptionV3收敛得要快,已经显示了InceptionResNetV2的优势.
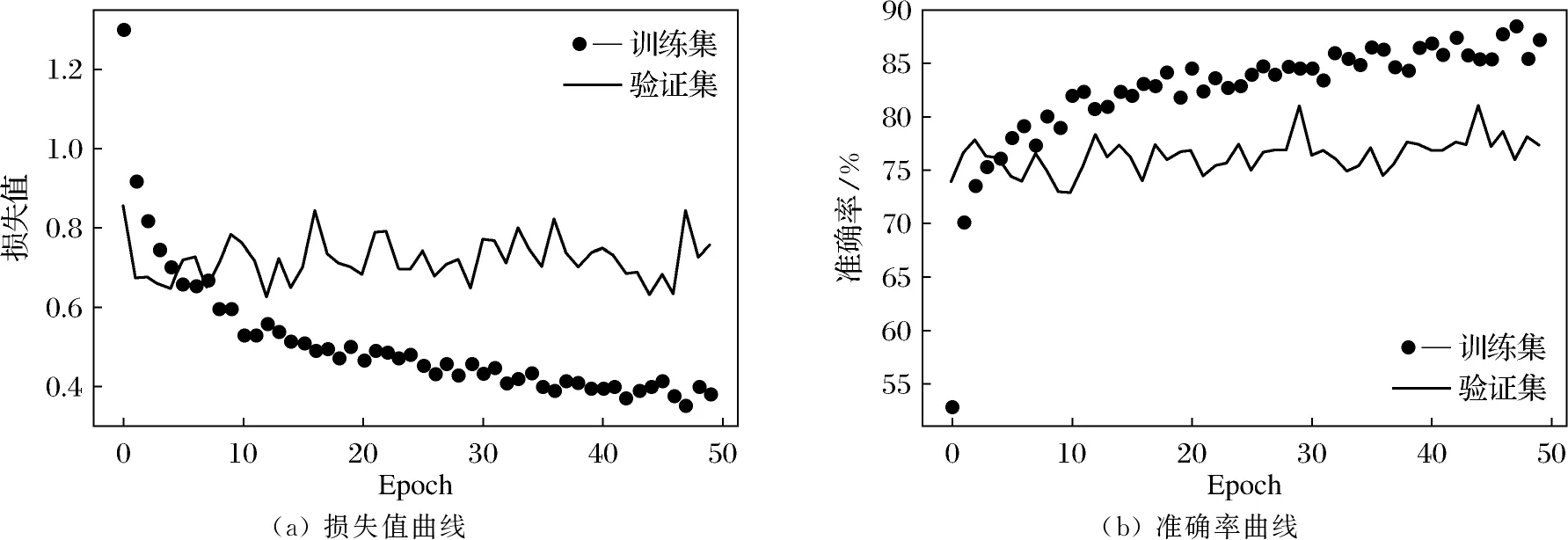
(a) 损失值曲线(b) 准确率曲线
试验4 使用InceptionResNetV2以策略3微调和训练
经过不断摸索和试验后,发现采用InceptionResNetV2网络在策略3下得到了较好的试验结果.由于模型处于欠拟合状态,在使用策略3的时候让卷积基的所有层都参与训练,batch_size的大小为4,用训练集中的20%作为验证集,Epoch增加到100.在训练过程中使用了保存点和回调技术保存训练过程中的权重文件.保存点用来存储模型的权重,这样可以继续训练或者直接开始预测.keras.callbacks中的ModelCheckpoint类提供了保存点功能.Keras有回调API,配合ModelCheckpoint可以保存每轮的网络信息,可以定义文件位置、文件名和保存时机等.训练过程中的损失值和准确率变化如图5所示.
由图5可以看出,策略3在验证集上达到了91%的准确率,训练过程中在第65轮产生了最好的权重文件model_65-0.91.hdf5,权重文件在保存时用训练的轮数和验证集上的准确率结合起来命名.加载产生的权重文件对测试集(之前未使用的505张图像)进行测试,准确率也达到了90%,如图6所示.
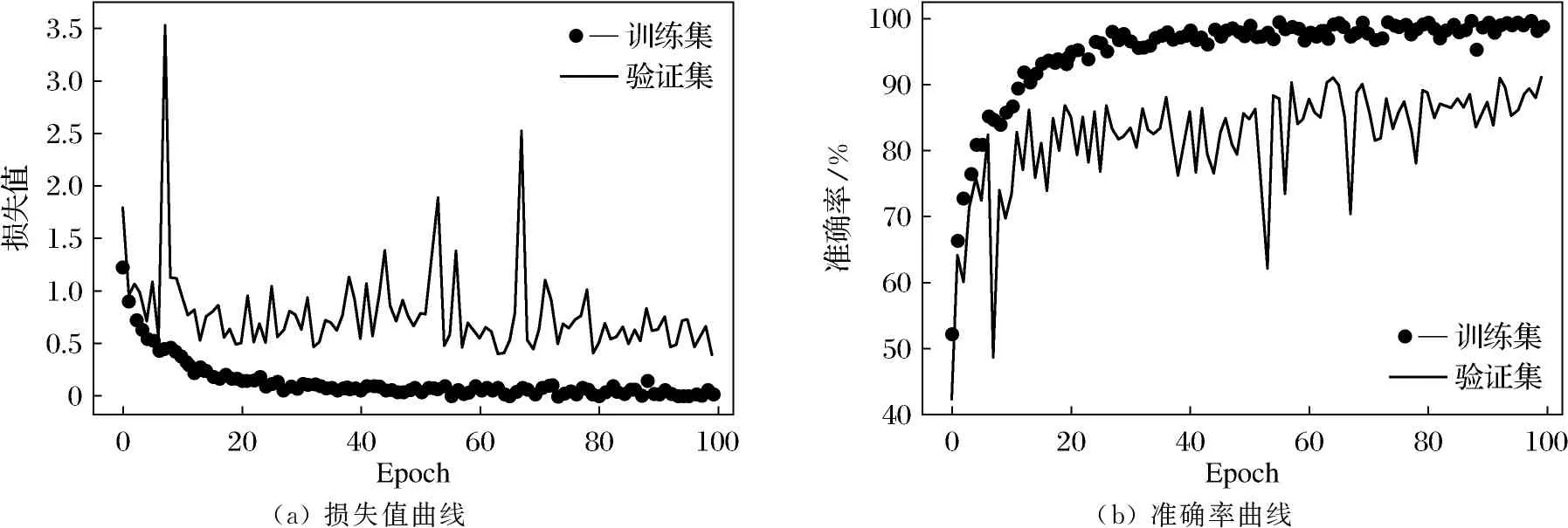
(a) 损失值曲线(b) 准确率曲线

model.load_weights('./train_model/model_65-0.91.hdf5')model.compile(optimizer='adam',loss='categorical_crossentropy',mettics=['acc'])scores=model.evaluate(x_test,y_test_ohe)scores[l]505/505 [==============================] -11s 22ms/step0.89504950554064
3 结果分析
使用试验4的模型将测试集前25幅图像的原始类别与预测的类别同时进行了显示,如图7所示,图像上方文字的涵义是编号、原始的类别和预测的类别,可以看到除了第17幅图像以外(将paper误识别为metal)大部分图像都得到了正确的识别.

paper⇒papercardboard⇒cardboardplastic⇒plasticplastic⇒plasticcardboard⇒cardboardglass⇒glassglass⇒glasspaper⇒papercardboard⇒cardboardmetal⇒metalpaper⇒papermetal⇒metalpaper⇒papermetal⇒metalpaper⇒paperpaper⇒paperplastic⇒plasticpaper⇒metalpaper⇒paperplastic⇒plasticmetal⇒metalglass⇒glassglass⇒glasspaper⇒papercardboard⇒cardboard
通过上述训练过程可以看出,在不用自己搭建模型的情况下采用预训练模型并使用策略3进行微调训练,在测试集上能达到90%准确率,显示了使用InceptionResNetV2预训练模型的强大功能和快速方便的特点.图8显示了InceptionResNetV2模型的混淆矩阵可以很好地看出模型分类的效果,可以看出分类错误的图像混淆较多的是1类的glass被误分类为4类的plastic(7张),其次是2类的metal被误分类为1类的glass(6张),后期可以考虑增加glass类型的图像数量以提高识别的准确率.
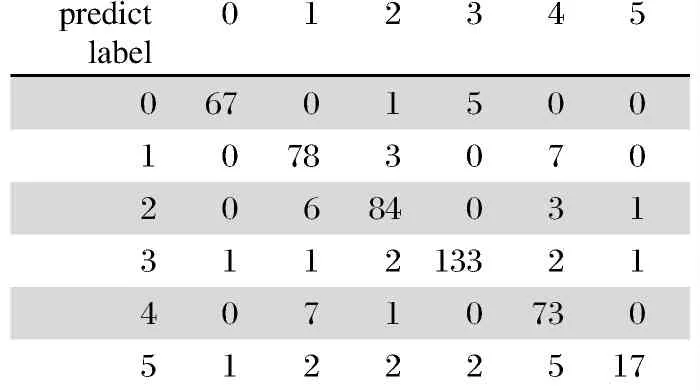
图8 InceptionResNetV2模型的混淆矩阵Fig.8 Confusion matrix of InceptionResNetV2 model
4 系统设计
模型产生后开发了在线可回收垃圾识别系统以部署和使用训练的模型,系统由服务器端和客户端2部分构成.服务器端采用了基于Flask的Web框架进行设计,在启动后只需加载1次模型便可提供实时的在线预测服务.
服务器端程序在设计时需要注意3点:①区分使用的是模型文件还是权重文件,如果加载的是权重文件,需要在加载之前产生模型的结构并对模型进行编译;②在调用模型预测之前,对用户上传图像的预处理应该与训练模型阶段的预处理方式一致,我们仍然采用了keras将图像转化为矩阵并调用preprocess_input函数进行预处理;③单幅的图像矩阵的维度在送入模型预测前应转化为4维张量,将第一维的批处理大小设置为1即可.服务器端在启动时会加载模型对服务器上的一幅图像进行预识别,并在屏幕上提示识别结果,以提示用户系统是否能正常运作,用户上传图像后会显示保存文件的路径、识别的结果和所需时间,如图9所示.
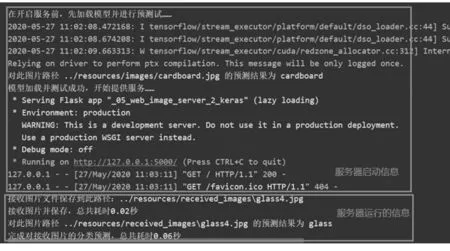
图9 服务器端启动与工作界面Fig.9 Startup and working interface of server-side
客户端采用了HTML+jQuery+Ajax方式进行设计,用户上传图像后服务器端会返回json格式的识别结果和其他数据,客户端在原网页中显示图像和识别的类别,并返回识别的概率,如图10所示.

图10 客户端界面Fig.10 Client interface
5 结 论
本文对VGG16、InceptionV3和Inception ResnetV2三种预训练模型进行了对比,经过不断试验,最终选择了InceptionResnetV2模型来开发可回收垃圾分类系统.主要思路是采用预训练的InceptionResnetV2模型,对其在ImageNet上训练好的网络参数进行迁移学习,对部分参数进行微调,并保留原模型的特征提取能力,将原模型的全连接层替换为符合本文要求的6分类softmax输出层,从而构建了基于深度迁移学习的垃圾分类识别模型.可以看到模型在验证集上的Top1准确率为90%,相比于InceptionResnet V2模型本身的准确率有一些提升,也说明在InceptionResnetV2微调之后的垃圾分类模型充分利用了原模型已经学习到的规律,并对这个特定的数据集有较好的预测能力.后期会研究以图像增强的方式扩大数据集的规模,或者搜集更多的可回收垃圾图像和种类,并进一步提高模型识别的准确率.
