图纸数字化成果名称一致性复核实践探析
2020-12-14许玉德同济大学道路与交通工程教育部重点实验室
许玉德/同济大学道路与交通工程教育部重点实验室
胡述筌 刘思磊 徐国尧/上海市轨道交通结构耐久与系统安全重点实验室
当前,电子文件电子化归档和电子档案电子化管理成为档案工作的重要发展趋势。现有工作实践表明,图纸档案数字化成果信息采集已形成比较成熟的工作模式,但学界、实践部门很少讨论检验图纸名称准确性的方式方法。目前管理系统对档案信息的命名有所限制,>、<、/等特殊符号不能作为档案名称,容易导致图纸数字化成果名称与数据库目录上的图纸名称不完全一致;加之数据库的位置与图纸数字化成果档案的实际存储位置通常不会在同一个地方,二者联系需要通过超链接来实现,如数据库目录与图纸数字化成果名称不一致,二者超链接就会失效,无法通过数据库的目录查阅图纸数字化成果。工作中,需要对图纸档案数字化成果名称一致性进行复核。
中国铁路上海局集团有限公司上海高铁维修段对段内形成的所有图纸档案进行数字化扫描,受数据库系统不接受特殊符号、重复命名等限制,图纸数字化成果名称与数据库系统目录中的名称很难保证完全一致,需要对名称一致性进行复核。统计发现,需要复核的图纸超过10000张,若采用人工复核的方式,会造成效率低下、正确率得不到保障等问题。需要设计新的方法,复核图纸数字化成果档案名称的一致性。
1 复核实践分析
名称一致性复核流程如下。一是选用擅长处理海量数据的Python分别爬取已建立数据库目录上的档案名称、实际存储位置的图纸数字化成果档案名称;二是以Python中内建的模糊匹配函数,进行数据库、实际图纸数字化成果档案名称一致性复核,模糊匹配函数中的匹配度,在检查过程中需要进行循环调整,每检查一次逐渐拉高匹配度;三是每次匹配完成后,以Excel VBA中的SQL语句检验两者名称是否不一致、是否存在冗余数据;四是反复进行二、三流程,直至两者名称完全对应。
1.1 图纸数字化成果存储路径与格式
存放图纸的路径分为3个层次,即线路层、线路内的档案层、档案内的图纸层,每条线路包含了数量众多的档案,档案中又包含了众多图纸。上海高铁维修段数据库共搭建了3个存储路径,即沪宁城际(含虹桥联络线)、沪杭高铁、宁杭高铁,每条线路竣工文档册数分别为25555册、12327册、16206册,包含图纸张数分别为4646张、3447张、4628张。
1.2 Python模糊匹配方法
一是读取外部储存图纸数字化成果名称。Python自带的函数库os,提供针对系统档案信息管理的操作接口,利用该函数库提供的函数,可以实现批量读取档案存储路径、档案更名、档案存储位置移动、档案删除等功能。本次数据库使用了批量读取档案存储路径的接口函数os.walk(file_dir),作为爬取档案路径、图纸数字化成果档案名称的手段。
二是建立外部储存图纸数字化成果档案名称的字典。Python提供了一种特殊的数据类型dictionary,具体格式如下[1]。
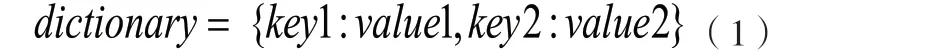
(式中key1、key2表示添加数据的键;value1、value2表示添加数据值)
该数据格式为每个数据提供唯一的键(key),通过查阅键找到添加数据值(value),添加数据值的形式不限于单一值,可以是数组(array)、列表(list)或字典(dictionary)。由于此次上海高铁维修段数据库共搭建了3个存储路径,存储的图纸数量较为庞大,所以需要用到双层字典,将第一层字典称为d_total,第二层字典称为d。其中d_total的键为线路名称,添加数据值为d,包含该线路下所有档案文件夹;d的键为存储文件夹名称,添加数据值为文档册内的图纸。通过此方式,可以完整有序地读取文件夹内所有图纸数字化成果名称,具体格式如下。
d_total={‘线路1’: d{档案1-1: [图纸1-1-1,图纸1-1-2], 档案2: [图纸1-2-1,图纸1-2-2]…},‘线路2’: d{档案2-1: [图纸2-1-1,图纸2-1-2], 档案2-2: [图纸2-2-1,图纸2-2-2]…},….}
三是模糊查找方法与实现。引入Python中的xlwt、xlrd两个函数库,读取xlsx档格式的内部查询数据库图纸目录,以列表(List)变量的形式暂存,作为遍历查找的母体。
由于数据库目录与图纸数字化成果档案名称不完全一致,如以目录名称与图纸数字化成果档案名称完全相同作为检查判断语句的条件,则太过苛刻,所以通过Python中difflib库里的difflib.get_close_matches(word, possibilities,n,cutoff)函数,使用模糊查找的方式进行一致性检核,其输入参数解释如下所示[2]。
word为需要查找的字符串,是读取Excel中的数据库图纸目录后,存于列表中的各个元素;possibilities为搜索匹配数据集,由创建字典的键、添加数据值,分别截取成为列表进行输入;n为达到匹配相似度的模糊搜索结果,按照相似度大小依序输出,默认值是输出的3个结果,本文只取最大匹配相似度的搜索结果,即令n等于1;cutoff为控制匹配相似度,取值0—1,默认值为0.6,设置1为精确查找,如搜索结果的匹配相似度超过既定的cutoff值,则函数按照匹配相似度大小依序输出查找结果。
该函数按照式(2)计算匹配相似度Ratio,若计算出来的Ratio大于cutoff值,代表查找字符串的匹配度超过默认值,通过检核要求。
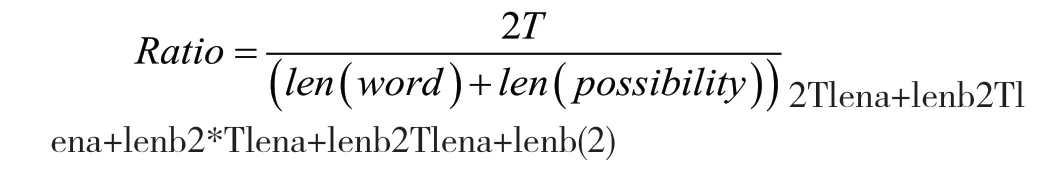
式中,len(word)为查找字符串word的长度,len(possibility)为搜索匹配数据集内某一元素字符串possibility的长度,T为word、possibility两字符串内容完全一致的长度。
审核存于列表(List)的目录所有标题,与读取存储图纸数字化成果档案名称而建立的字典d_total进行模糊匹配,查找相似度最高的存储文件夹名称、图纸数字化成果档案名称。经反复试验,发现设置cutoff为0.7时模糊查找的效果最好,设置0.8以上则不合格率太高,无助于复验。由于匹配的结果要导出Excel进行一致性检验,必须详细记录存储文件夹、图纸数字化成果档案的名称,与数据库目录名称的异同,所以如果模糊匹配结果返回空值,必须要进行标记。
1.3 Excel VBA目录一致性检验
数据库目录上的档案都有固定、唯一、连续编排的序号,可利用Excel VBA中的SQL语句,遍历选取模糊匹配而来的存储文件夹名称,如一个存储文件夹名称选取出来的数据条数,与对应的数据库目录数量一致,则无需进行人工修正;如连续编排序数与选取总条数不一致,代表发生资料冗余、数据缺失、匹配错误等现象,需对特定目录名称、存储文件夹名称进行人工修正。检查完目录上的档案标题后,如未发现存储文件夹存在数据冗余、数据缺失、匹配错误等问题,再用Excel VBA中的SQL语句往下遍历选取该存储文件夹内所有模糊匹配成功得到的图纸数字化成果档案名称,若模糊匹配所对应的图纸数字化成果档案名称选取结果条数大于1,代表存在图纸数据冗余或匹配错误,需要进行人工修正。
1.4 信息精确复核
进行数据条数核对后,可以找出数据冗余、数据缺失、匹配错误等问题,再进行人工修改标题,然后再次利用difflib库里的difflib.get_close_matches(word, possibilities,n,cutoff)函数,参照修正更新后的字典进行n=1、cutoff=1精确查找,查找完的数据汇总至Excel内,再次使用Excel VBA中的SQL语句进行遍历,对比目录上的档案名称,依次循环直到目录中的数据百分之百通过复核。
2 复核结果
按照流程进行循环复核,各循环阶段复核的结果如表1所示,可以发现第一次模糊查找的正确率为81.3%,对没有匹配上的目录名称、存储文件夹名称、图纸数字化成果档案名称进行人工修正;再次进行第二次匹配度为1的复核循环,即可得到99.8%的正确率;修正后第三次复核正确率达到100%。
3 结论
根据反复测试的结果,若初始模糊查找的相似度太高,则目录与实际存储数字化成果名称不匹配的条数过多,后续修正的工作量过大,故改采用降低模糊查找相似度(本次取0.7),可有效降低不匹配的数据条数,再利用Excel VBA,进行相关数据冗余、数据缺失、匹配错误检核,解决因不同档案文件夹、图纸数字化成果档案名称相似度太高,导致重复匹配的问题,最后检核出来需人工修正数据为2385条,占比全部图纸目录条数约18.7%。第一次模糊查找修正完后,第二次精确查找的正确率就可达到99.8%。若没有特定的辅助手段,则全部电子化名称皆须人工复核,且正确率难以保证,故该方法可以达到实现与实际档案文件夹名称、图纸数字化成果档案名称匹配正确率100%,且兼顾复核效率的目标。本次数据冗余、数据缺失、匹配错误是使用Excel VBA进行复核,其运行效率较为低下,往后可以针对该部分再进行相关算法的优化。
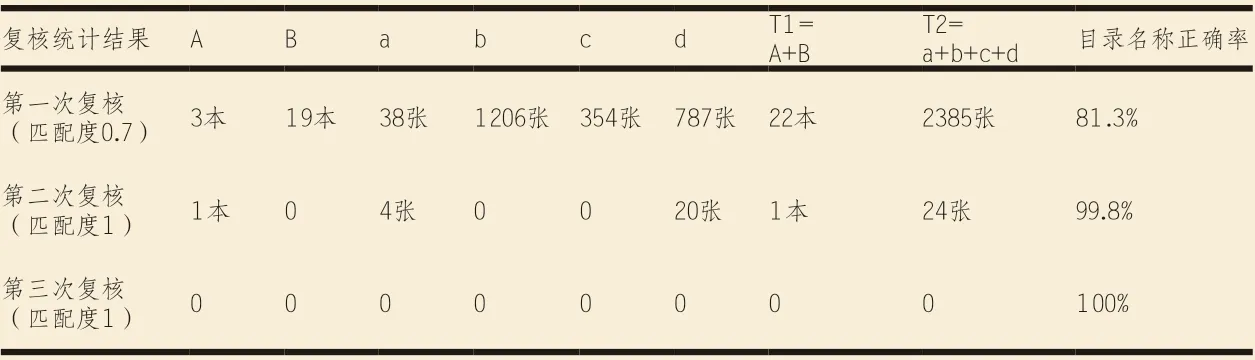
表1:图纸复核结果统计表
