基于多分区注意力的行人重识别方法
2020-12-11薛丽霞朱正发汪荣贵
薛丽霞,朱正发,汪荣贵,杨 娟
基于多分区注意力的行人重识别方法
薛丽霞,朱正发,汪荣贵,杨 娟*
合肥工业大学计算机与信息学院,安徽 合肥 230009
行人重识别是计算机视觉中一项具有挑战性和实际意义的重要任务,具有广泛的应用前景。背景干扰、任意变化的行人姿态和无法控制的摄像机角度等都会给行人重识别研究带来较大的阻碍。为提取更具有辨别力的行人特征,本文提出了基于多分区注意力的网络架构,该网络能同时从全局图像和不同局部图像中学习具有鲁棒性和辨别力的行人特征表示,能高效地提高行人重识别任务的识别能力。此外,在局部分支中设计了一种双重注意力网络,由空间注意力和通道注意力共同组成,优化提取局部特征。实验结果表明,该网络在Market-1501、DukeMTMC-reID和CUHK03数据集上的平均精度均值分别达到82.94%、72.17%、71.76%。
行人重识别;局部特征;双重注意力网络;深度神经网络

1 引 言
行人重识别任务是在跨摄像头中进行指定行人检索,即对于给定一个行人图像,在多台不同角度、没有视野重叠覆盖的摄像头不同时间段拍摄的行人图像数据库中找到该行人目标。随着监控摄像头在公共区域的大量普及,行人重识别技术受关注程度越来越高,在视频内容检索、视频监控以及智能安防等领域已成为一项核心技术。
解决行人重识别任务的常见方法是从特征提取和度量学习两个方面考虑,首先是学习特征向量对行人图像进行特征表示[1-3],然后通过度量学习准确的度量图像间的相似性[4-8]。传统的行人重识别方法[4]依赖于手工提取行人特征,再进行相似性度量。但由于监控摄像头的分辨率低以及光照、角度等影响,同一个行人在不同摄像机中可能有很大差异,而不同的行人在外观上可能很相似,这使得手工提取特征很难应用到复杂的现实环境中。
近年来,由于深度学习强大的拟合和表征能力,在计算机视觉任务中都取得了出色的竞争表现[9-10]。通过深度卷积神经网络提取的行人特征比以前的手工编码特征具有更高的泛化能力,使得应用深度学习模型来解决行人重识别任务的准确率提高到了一个新的水平。与此同时,带有标签的行人重识别数据集(如CUHK03[11]、Market-1501[12]和DukeMTMC-reID[13])的出现,为深度模型的训练在数据层面上提供了可行性。
在最初的基于深度学习的行人重识别研究方法中,研究者们主要使用最直接的从行人图像的整体上提取识别特征方法,即通过网络模型在图像上提取行人全局特征向量用以相似性检索[14-15]。虽然,这类方法在各大数据集上较传统方法取得了突破性进展,但是由于只考虑到整体图像中捕获最显著的外观特征来表示不同行人之间的区别,忽略了一些不显著或不频繁的细节信息,从而导致获取的行人特征不足以准确表示复杂场景中的行人身份信息。
因此,行人重识别研究并不仅仅只关注在全局特征上,也开始逐渐研究局部特征,并证明了结合局部特征的行人图像表示是最有效的[16-17]。局部特征提取的关键是对整体图像进行分割及局部区域的精确定位。目前,效果较好的行人重识别方法在提取局部特征的功能上有所不同,大致可以概括为两种:一是根据行人固有的身体结构,将图像在水平方向上分割成若干条条带,在其上提取局部特征[18-20];二是利用人体姿态估计和骨架关键点等先验知识来预测行人身体结构信息以裁剪出更准确的局部区域[21-22]。但是上述方法都有各自的缺陷。第一种水平分块方法没有考虑局部之间不对齐问题;第二种局部划分方法需要一个额外的骨架关键点或者姿态估计的模型,这会带来额外的姿态估计误差。
同时,研究者们还提出了针对行人重识别的注意力深度学习模型[23-24]。类似于人类视觉处理的注意力机制,有选择性地倾向于注意图像中的行人部分,而忽略其他不感兴趣的区域,有助于解决行人重识别问题。Li等[25]为展现不同层次的注意力机制感知和学习行人特征,提出了HA-CNN网络模型,用来学习互补的区域级硬注意力特征和像素级软注意力特征,增强柔和和兼容性程度,优化处理未对齐图像的特征提取技术。Liu等[26]提出了一个多级别注意力模型HydraPlus-Net,将注意力机制映射到不同的特征层,使其挖掘多级别特征信息。上述此类方法大都将区域注意力网络合并嵌入到深层的行人重识别模型中。大多数现有的行人重识别工作集中于使用全身图像进行注意力学习,忽视了从行人身体的局部部位学习的注意力特征。同时,全局注意力更多地集中在全局信息区域上,这往往会抑制或忽略行人身体部位周围的局部信息区域,从而导致当人的图像出现较大的姿态变化、严重的失调、局部遮挡等情况时,重识别效果不佳。
因而,本文重新考虑了如何利用局部特征和注意力机制学习到更加具有识别力的行人特征,设计了一个基于局部注意力的行人重识别网络,即多分区注意力网络模型(multi-division attention network,MDA)。图1展示了MDA网络的整体框架图。该网络主要从两个方面解决上述提及的困难:一是同时学习全局特征和不同分块数量的局部特征,兼顾行人的整体信息和局部细节信息,优化深度学习中的行人重识别;二是设计了一种双重局部注意力网络,分为空间注意力网络SANet和通道注意力网络CANet,二者在功能上形成很强的互补性,提高行人重识别模型的性能。
2 方 法
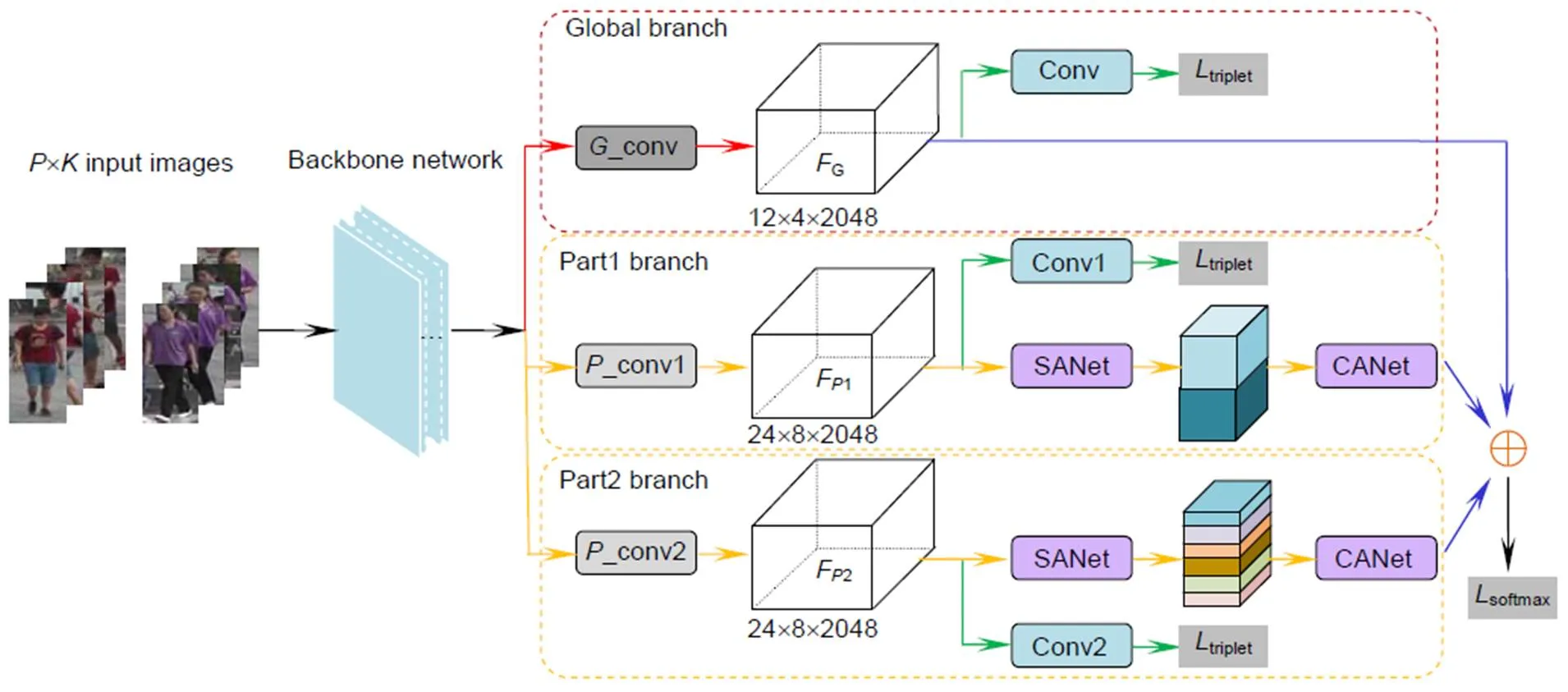
图1 MDA模型框架的概述
2.1 网络子结构
1) 主干网络
本文中主干网络采取的是ResNet50网络,借助其在行人重识别领域的优势。为适应网络模型中全局和局部特征融合需求,在网络层上都对ResNet50原始版本进行简化改动,以及只采用conv 4_1层之前的网络部分,后面连上conv和conv分别进入三个独立的分支。conv和conv结构大体相同,都是由conv 5_层组成。不同点在于为了获得更高粒度的特征图,conv删除了conv 5_1位置的下采样操作,而conv不做任何改变。
这样,进入局部分支的特征图尺寸比全局分支的特征图尺寸大一倍,会强制这两个局部分支学习更高粒度的特征和更多的细节信息。conv和conv模块独立训练,不共享参数,最小化过度拟合的风险。主干网络的更多细节参数展示在表1中。
这样,对于输入训练图像,首先使用主干网络提取图像的特征,该特征可以表示为
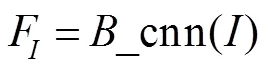

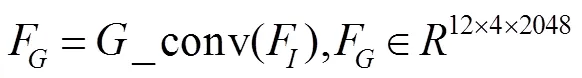
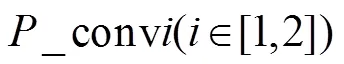
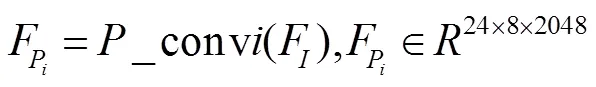
2)全局分支
全局分支的目的是从整个行人图像中学习最优的全局层次的特征表示。如图1所示,F将会经过两条线路:一条是直接与局部分支的输出做特征融合;另一条用于计算triplet损失。在计算损失这条线路上,F会经过conv层(由核为12´4最大全局池化层、1´1卷积层、BN层和ReLU层组成),可以表示为
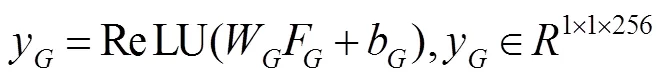
其中:W、b为卷积层的参数权重和偏置。式(4)的目的是将2048维的特征降维成256维y,用于计算triplet损失。
3) 局部分支
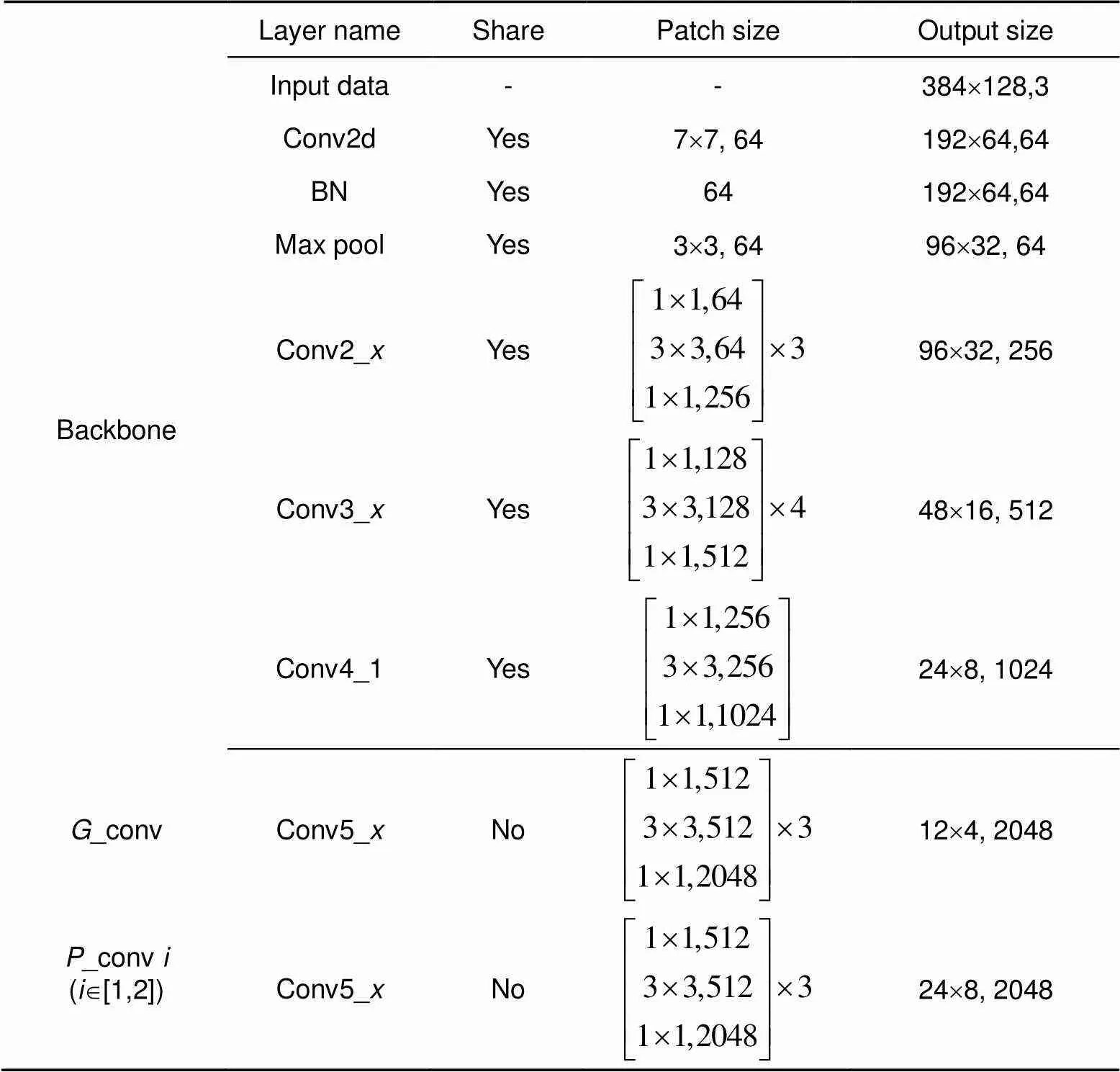
表1 Backbone network结构

4) 特征融合
特征融合部分采用并行策略来实现,同时考虑到融合过程可能会对局部注意力特征向量的某些特定维度产生过大的响应,加入一个非线性激活函数来平衡局部注意力特征响应。融合特征可以定义为

2.2 双重局部注意力
在行人重识别任务中引入注意力机制,是希望通过类似于人脑注意力的机制,利用很小的感受野处理图像中特定区域,降低了计算的维度,同时网络学习图像中高响应区域的特征表示,使得该部分区域的特征得到增强。受此思想的影响,本文在局部分支中提出利用注意力机制进一步提取出更具有分辨能力的局部特征,在具体实现过程中,运用双重局部注意力模型,即空间注意力(spatial attention network,SANet)和通道注意力(channel attention network,CANet)。
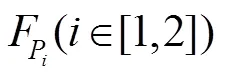
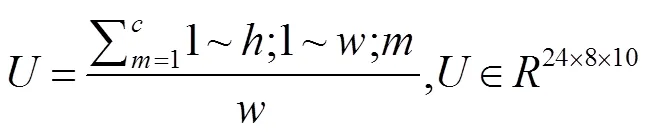
式中:U为Drop层的输出,h、w、c为特征图的高、宽和通道数。可以看出,Drop层是专门为后续卷积层的输入大小而设计的对参数进行压缩,使得参数量只有原来的。实际上,这种跨通道压缩是合理的,因为在模型设计中,所有通道共享相同的空间注意特征图。
然后经过一个卷积层和ReLU层,其目的是用于提取空间注意力特征,可以表示为
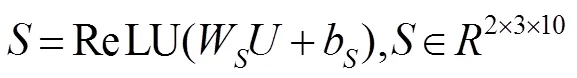
CANet是约束每一个通道上的所有特征值,最后输出长度与通道数目相同的一维向量作为特征加权输出。整个CANet有两个支路:多通道分支和直连分支,如图3所示。
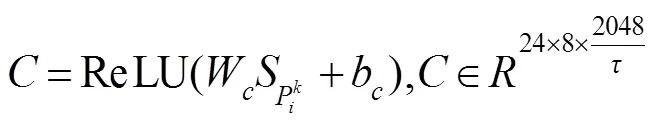
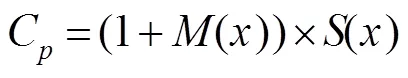
多通道分支中的Sigmoid激活函数会导致其结构①输出归一化为0到1之间,特征图的输出响应变弱,这样多通道叠加结构①会使得最终输出()的特征图每一个点上的值变得很小。因此,式(10)中将()与1相加,可以很好地解决降低特征值问题。
2.3 损失函数


图3 CANet网络结构
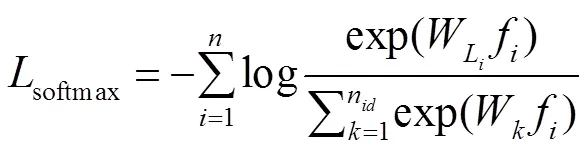

3 实 验
本文在CUHK03[11]、Market-1501[12]和DukeMTMC-reID[13]数据集上进行了充分的实验,结果表明,与现有的网络模型相比,本文提出的模型具有更好的鲁棒性和有效性。本文使用首位命中率(Rank-1)和平均精度均值(mean average precision,mAP)作为行人重识别方法的评价指标。同时,为提高结果所反映性能的准确性,使用了Re-ranking评估方法[29]。
3.1 实验细节
整个模型的实现是基于PyTorch框架来完成的,使用单个NVIDIA GEFORCE GTX 1080TI GPU来训练和测试模型。本文在ImageNet[28]数据集上预训练ResNet50网络的权重参数用来初始化主干网络。对于每个最小训练批次,随机从数据集中选取个身份的行人和从每类行人中随机选取张行人图像。在训练阶段,先将训练图像大小调整为384´128,然后依概率=0.5进行水平翻转,以及使用Random Erasing模拟物体遮挡情况进行数据增强。在测试阶段,只是将图像大小调整为384´128。本文使用随机梯度下降(SGD)进行优化,冲量为0.9,2正则化的权重衰减因子设为5E-4,初始学习率设为2E-3,每训练80个迭代次数下降10%。在每一个预测层之前使用dropout层,dropout比设置为0.5。
3.2 实验结果
在Market-1501数据集上,将本文提出的方法与9种有代表性的方法进行比较,实验结果如表2所示。可以看出,本文提出的方法取得了较好的识别效果,mAP和Rank-1分别达到了82.94%和94.03%,在使用Re-ranking技术后更是达到了90.27%和94.98%,进一步提高了识别准确率。在这里选取的比较方法有以下几种:水平分割方法(PCB+RPP[18])和借助行人姿态(Spindle[16]、PDC[22])来完成行人局部特征的提取;行人区域对齐方法提出的(Part-Aligned[24]);全局特征和局部特征的联合学习(AlignedReID[31]);结合行人属性解决行人重识别问题(APR[30]);注意力机制的引入(HA-CNN[25]、Hydraplus-net[26]、DuATM[32])。

表2 Market-1501数据集实验结果
"RK" refers to implementing re-ranking[29]operation
在图4中,显示了某些给定行人图像的前10个排序结果。可以看出,即使在只有查询图像4(a)的背影图时,大多数排名结果也是能够保证准确率的。对于具有相似外观的查询图像4(b)和4(c),由于网络可以提取足够的行人特征信息,因此即使待查询图像中存在不对齐情况,也可以获得良好的识别精度。在查询图像4(d)中的行人存在严重遮挡和姿态问题,本文提出的方法识别性能不是很好。
检索的图像全部来自Market-1501数据集中的图像,而不是同一张相机拍摄的图像。其中具有绿色边框的图像与给定查询图像属于同一行人,而具有红色边框的图像则不属于同一行人。
对于更大的和更具有挑战性的DukeMTMC-reID数据集,本文方法的重识别性能也很出色,分别与5种行人重识别方法进行了比较,表3给出了实验结果,其在Rank-1和mAP上的性能分别达到了84.68%和72.17%,在Rank-1指标上比PCB+RPP和HA-CNN分别高出了1.38%和4.18%,在mAP指标上比PCB+RPP和HA-CNN分别高出了2.97%和8.37%。在这个目前最具挑战性的数据集上,进一步验证了本文方法的优势。
对于CUHK03数据集提供的两种类型的标签,CUHK03-Labeled表示为手动标记行人边界框,CUHK03-Detected表示为DPM[33]检测边界框。本文提出的方法在CUHK03-Labeled上的Rank-1和mAP达到了75.36%和71.76%。同时,在CUHK03-Detected上的Rank-1和mAP达到了73.53%和65.91%。另外从表4中可以观察到CUHK03-Labeled和CUHK03-Detected之间有明显的差距。这足以证明行人图像标签的标注对行人重识别性能的重要影响,强调了高性能行人检测器的重要性。

图4 行人图像前10个排序结果

表3 DukeMTMC-ReID数据集实验结果
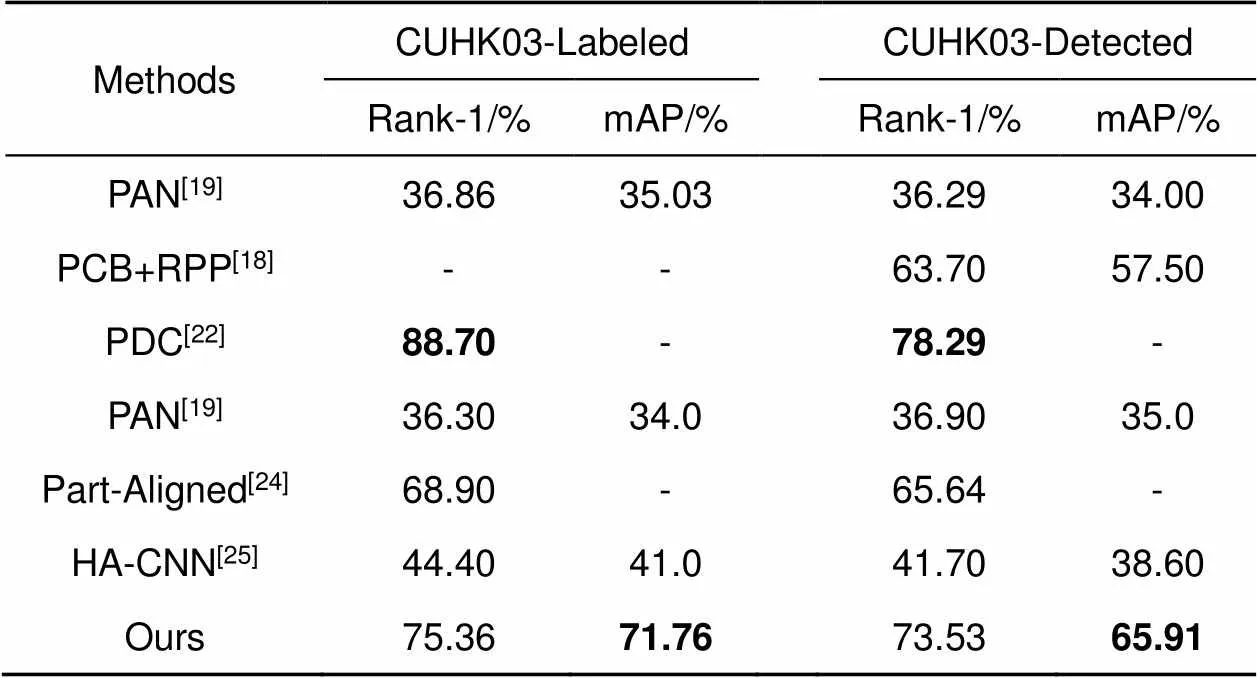
表4 CUHK03数据集实验结果
3.3 分析与讨论
为验证本文设计的三分支网络结构的有效性,我们在Market-1501数据集上进行了一系列不同分支设置策略的对比实验,图5展示了各分支不同组合的比较结果。将各分支的不同组合方法分为两类,一是单个分支(全局分支、Part1局部分支和Part2局部分支),二是将各分支两两进行自由组合(全局分支和Part1局部分支、全局分支和Part2局部分支、Part1局部分支和Part2局部分支)。从图中可以直观地看出,一方面,与所有的单个分支实验结果相比,本文提出的分支组合方法效果更好。在仅保留全局分支时,行人重识别结果最差,Rank-1和mAP只达到84.89%和69.12%。在单个局部分支的对比实验中,Part2分支比Part1分支在Rank-1指标上高2.65%,在mAP指标上高4.81%,这说明在一定程度上随着局部划分数量的增加,行人重识别效果越来越好。另一方面,基于本文提出的多分区注意力网络,可以增加或减少局部分支的数量,即将三个分支自由组合,则会发现性能显着下降。原因是提出的多分区注意力网络的三个分支之间存在重叠,并且可以引入不同分区之间的相关性,从而可以学习更多差异信息。
我们进一步评估提出的双重局部注意力DLA的效果,同样的是在Market-1501数据集进行的对比实验, 实验结果如图6所示。由图可知,在没有加任何注意力机制的全局和局部结合的纯网络GP中,Rank-1和mAP分别为85.33%和76.40%。在此基础上开始引入注意力机制,结合纯网络GP和空间注意力网络SANet可以使得Rank-1和mAP分别达到89.56%和80.52%,结合纯网络GP和通道注意力网络CANet可以使得Rank-1和mAP分别达到91.07%和81.16%。这说明在网络中嵌入注意力机制能提高行人重识别效果,但也反映出加入单一的注意力网络对重识别结果影响不显著。将本文提出的方法与前面三种网络进行比较,证实了提出的双重局部注意力网络能有效地帮助改进行人重识别的性能,以及说明了空间注意力和通道注意力结合的优势和有效性。
4 结 论
行人重识别是一个具有挑战性和实际意义的计算机视觉问题,本文将卷积神经网络和注意力思想引入行人重识别任务,提出了一种基于多分区注意力的网络模型,取得了显著性的进展。与大多数容易产生局部匹配错位问题或利用全局的注意力机制的现有行人重识别方法相比,本文提出的网络能够以端到端的形式,运用双重注意力机制提取具有互补效果的行人局部注意力特征,并与全局特征进行融合,从而获得具有更好的行人重识别效果性能。同时,也注意到尽管均匀分块方法简单有效,但有待改进,在接下来的工作中,可以结合行人姿态估计和骨架关键点分析,提取更加有效的局部特征,继续研究准确率更高、鲁棒性更好的行人重识别模型。

图5 不同分支组合比较结果图

图6 DLA效果图
[1] Sun R, Fang W, Gao J,. Person Re-identification in foggy weather based on dark channel prior and metric learning[J]., 2016, 43(12): 142–146.
孙锐, 方蔚, 高隽. 暗通道和测度学习的雾天行人再识别[J]. 光电工程, 2016, 43(12): 142–146.
[2] Su C, Zhang S L, Yang F,. Attributes driven tracklet-to-tracklet person re-identification using latent prototypes space mapping[J]., 2017, 66: 4–15.
[3] Matsukawa T, Okabe T, Suzuki E,. Hierarchical gaussian descriptor for person Re-identification[C]//, Las Vegas, NV, USA, 2016: 1363–1372.
[4] Zhao R, Ouyang W L, Wang X G. Person Re-identification by salience matching[C]//, Sydney, NSW, Australia, 2013: 2528–2535.
[5] Chen D P, Yuan Z J, Hua G,. Similarity learning on an explicit polynomial kernel feature map for person re-identification[C]//, Boston, MA, USA, 2015: 1565–1573.
[6] Sun Y F, Zheng L, Deng W J,. SVDNet for pedestrian retrieval[C]//, Venice, Italy, 2017: 3820–3828.
[7] Yang X, Wang M, Tao D C. Person Re-identification with metric learning using privileged information[J]., 2018, 27(2): 791–805.
[8] Zhang L, Xiang T, Gong S G. Learning a discriminative null space for person Re-identification[C]//, Las Vegas, NV, USA, 2016: 1239–1248.
[9] Liu H, Peng L, Wen J W. Multi-occluded pedestrian real-time detection algorithm based on preprocessing R-FCN[J]., 2019, 46(9): 180606.
刘辉, 彭力, 闻继伟. 基于改进R-FCN的多遮挡行人实时检测算法[J]. 光电工程, 2019, 46(9): 180606.
[10] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//, Red Hook, NY, United States, 2012, 25: 1097–1105.
[11] Li W, Zhao R, Xiao T,. DeepReID: deep filter pairing neural network for person Re-identification[C]//, Columbus, OH, USA, 2014: 152–159.
[12] Zheng L, Shen L Y, Tian L,. Scalable person Re-identification: a benchmark[C]//, Santiago, Chile, 2015: 1116–1124.
[13] Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person Re-identification baseline in Vitro[C]//, Venice, Italy, 2017: 3774–3782.
[14] Sudowe P, Spitzer H, Leibe B. Person attribute recognition with a jointly-trained holistic CNN model[C]//, Santiago, Chile, 2015: 329–337.
[15] Cheng D Q, Tang S X, Feng C C,. Extended HOG-CLBC for pedstrain detection[J]., 2018, 45(8): 180111.
程德强, 唐世轩, 冯晨晨, 等. 改进的HOG-CLBC的行人检测方法[J]. 光电工程, 2018, 45(8): 180111.
[16] Zhao H Y, Tian M Q, Sun S Y,. Spindle net: person Re-identification with human body region guided feature decomposition and fusion[C]//, Honolulu, HI, USA, 2017: 907–915.
[17] Wei L H, Zhang S L, Yao H T,. GLAD: global-local-alignment descriptor for pedestrian retrieval[C]//, California, Mountain View, USA, 2017: 420–428.
[18] Sun Y F, Zheng L, Yang Y,. Beyond part models: person retrieval with refined part pooling[Z]. arXiv:1711.09349[cs:CV], 2017.
[19] Zheng Z D, Zheng L, Yang Y. Pedestrian alignment network for large-scale person Re-identification[J]., 2019, 29(10): 3037–3045.
[20] Cheng D, Gong Y H, Zhou S P,. Person Re-identification by multi-channel parts-based CNN with improved triplet loss function[C]//, Las Vegas, NV, USA, 2016: 1335–1344.
[21] Zheng L, Huang Y J, Lu H C,. Pose-invariant embedding for deep person Re-identification[J]., 2019, 28(9): 4500–4509.
[22] Su C, Li J N, Zhang S L,. Pose-driven deep convolutional model for person Re-identification[C]//, Venice, Italy, 2017: 3980–3989.
[23] Li D W, Chen X T, Zhang Z,. Learning deep context-aware features over body and latent parts for person Re-identification[C]//, Honolulu, HI, USA, 2017: 7398–7407.
[24] Zhao L M, Li X, Zhuang Y T,. Deeply-learned part-aligned representations for person Re-identification[C]//, Venice, Italy, 2017: 3239–3248.
[25] Li W, Zhu X T, Gong S G. Harmonious attention network for person Re-identification[C]//, Salt Lake City, UT, USA, 2018: 2285–2294.
[26] Liu X H, Zhao H Y, Tian M Q,. HydraPlus-Net: attentive deep features for pedestrian analysis[C]//, Venice, Italy, 2017: 350–359.
[27] Hermans A, Beyer L, Leibe B. In Defense of the triplet loss for person Re-Identification[Z]. arXiv: 1703.07737[cs:CV], 2017.
[28] Deng J, Dong W, Socher R,. ImageNet: a large-scale hierarchical image database[C]//, Miami, FL, USA, 2009: 248–255.
[29] Zhong Z, Zheng L, Cao D L,. Re-ranking person Re-identification with k-reciprocal encoding[C]//, Honolulu, HI, USA, 2017: 3652–3661.
[30] Lin Y T, Zheng L, Zheng Z D,. Improving person Re-identification by attribute and identity learning[Z]. arXiv: 1703.07220[cs:CV], 2017.
[31] Zhang X, Luo H, Fan X,. AlignedReID: surpassing human-level performance in person Re-identification[Z]. arXiv: 1711.08184[cs:CV], 2017.
[32] Si J L, Zhang H G, Li C G,. Dual attention matching network for context-aware feature sequence based person Re-identification[C]//, Salt Lake City, UT, USA, 2018: 5363–5372.
[33] Felzenszwalb P F, McAllester D A, Ramanan D. A discriminatively trained, multiscale, deformable part model[C]//, Anchorage, AK, USA, 2008: 1–8.
Person re-identification by multi-division attention
Xue Lixia, Zhu Zhengfa, Wang Ronggui, Yang Juan*
College of Computer and Information, Hefei University of Technology, Hefei, Anhui 230009, China

Top-10 ranking list for some query images
Overview:With the popularity of surveillance cameras in public areas, person re-identification has become more and more important, and has become a core technology in video content retrieval, video surveillance, and intelligent security. However, in actual application scenarios, due to factors such as camera shooting angle, complex lighting changes, and changing pedestrian poses, occlusions, clothes, and background clutter in person images. It makes even the same person target have significant differences in different cameras, which poses a great challenge for person re-identification research. Therefore, in this paper we propose a research method based on deep convolutional networks, which combines global and local person feature and attention mechanisms to solve the problem of person re-identification. First, unlike traditional methods, we use ResNet50 network to initially extract person image features with more discriminating ability. Then, according to the person inherent body structure, the image is divided into several bands in the horizontal direction, and it is input into the local branch of the built-in attention mechanism to extract the person local attention features. At the same time, the global image is input to the global branch to extract the person global features. Finally, the person global features and local attention features are fused to calculate the loss function. In the network, in order to better extract the person local features, we design two local branches to segment the person images into different numbers of local area images. With the increase of the number of blocks, the network will learn more detailed and discriminative local features in each different local area, and at the same time, it can filter irrelevant information in local images to a large extent by combining the attention mechanism. Our proposed attention mechanism can make the network focus on the areas that need to be identified. The output person attention features usually have a stronger response than the non-target areas. Therefore, the attention networks we design include spatial attention networks and channel attention networks, which complement each other to learn the optimal attention feature, thereby extracting more discriminative local features. Experimental results show that the method proposed in this paper can effectively improve the performance of person re-identification.
Citation: Xue L X, Zhu Z F, Wang R G,. Person re-identification by multi-division attention[J]., 2020,47(11): 190628
Person re-identification by multi-division attention
Xue Lixia, Zhu Zhengfa, Wang Ronggui, Yang Juan*
College of Computer and Information, Hefei University of Technology, Hefei, Anhui 230009, China
Person re-identification is significant but a challenging task in the computer visual retrieval, which has a wide range of application prospects. Background clutters, arbitrary human pose, and uncontrollable camera angle will greatly hinder person re-identification research. In order to extract more discerning person features, a network architecture based on multi-division attention is proposed in this paper. The network can learn the robust and discriminative person feature representation from the global image and different local images simultaneously, which can effectively improve the recognition of person re-identification tasks. In addition, a novel dual local attention network is designed in the local branch, which is composed of spatial attention and channel attention and can optimize the extraction of local features. Experimental results show that the mean average precision of the network on the Market-1501, DukeMTMC-reID, and CUHK03 datasets reaches 82.94%, 72.17%, and 71.76%, respectively.
person re-identification; local features; dual attention network; deep neural networks
TP391.4;TP301.6
A
薛丽霞,朱正发,汪荣贵,等. 基于多分区注意力的行人重识别方法[J]. 光电工程,2020,47(11): 190628
10.12086/oee.2020.190628
: Xue L X, Zhu Z F, Wang R G,Person re-identification by multi-division attention[J]., 2020, 47(11): 190628
2019-10-17;
2020-03-10
薛丽霞(1976-),女,博士,副教授,硕士生导师,主要从事智能视频处理与分析、视频大数据与云计算、智能视频监控与公共安全、嵌入式多媒体技术等的研究。E-mail:xixzzm@163.com
杨娟(1983-),女,博士,讲师,硕士生导师,主要从事视频信息处理、视频大数据处理技术、深度学习与二进神经网络理论与应用等的研究。E-mail:yangjuan6985@163.com
* E-mail: yangjuan6985@163.com
