基于多尺度对抗学习的人体姿态估计
2020-12-11李晓明徐建华
李晓明,黄 慧,应 毅,徐建华,曾 岳,刘 洋
(1.三江学院计算机科学与工程学院,南京 210012;2.金陵科技学院软件工程学院,南京 211169;3.江苏省清江中学,江苏淮安 223001)
0 引言
机器视觉与模式识别技术应用于安全监控领域始于20 世纪90 年代,包括美国国防高等研究计划署资助的视频图像检索分析工具和远距离人体识别系统,巴黎公共交通网络提出的实时事件监测方案等。在公众场景下,人作为视频监控中的主要对象,需要对人体动作进行准确识别,以加强对图像的理解及异常行为的预警。人体姿态估计是人体行为识别的基础,它是在给定一幅图像或者一段视频中进行人体关键点位置定位的过程,对智慧医疗、智能安防及增强现实等领域具有广阔的应用前景。
近年来,学者们提出了多种人体姿态估计算法,这些算法大致可以分为两类:基于特征描述子的人体姿态估计算法和基于深度学习的人体姿态估计算法,该算法一般使用了大量特征,其中包括颜色、纹理、边缘、形状、全局特征、局部特征和块特征。其中HOG(Histogram of Oriented Gradient)特征是由Dalal 等[1]在行人检测中第一次提出来的,具有图像局部信息良好的几何和光照不变性。该特征已经广泛应用于人体姿态估计,并对人体姿态估计领域产生积极的推动作用[2-5]。基于深度学习的人体姿态估计算法一般通过卷积神经网络来提取人体各部件的特征,具有更强特征表达和学习能力。Chu等[6]提出多语境注意力机制提升模型对人体关键点空间信息建模的性能。Yang等[7]设计了金字塔残差模块来有效提取人体多尺度信息。Newell等[8]提出了堆栈沙漏网络,在人体姿态估计领域取得较理想的结果。在沙漏网络基础上,学者们又提出了多种改进模型。Chou 等[9]将生成对抗学习引入到人体姿态估计中,进一步改善生成人体部件特征的图质量。但是,现有基于对抗学习的人体姿态估计算法中,缺少对尺度人体部件信息的融合。近年来,大量的研究表明人体目标检测框一旦发生细微变化,将会对人体姿态估计的结果产生较大影响。这一现象表明人体姿态估计对人体尺度的变化非常敏感。此外,不同人体部件的尺度也不一样,这些因素均对人体姿态估计造成了严峻的挑战。本文研究基于对抗学习的人体姿态估计算法,通过堆栈沙漏网络分别构建对抗网络中的生成器和判别器,再分别在生成器和判别器中融合多尺度人体部件信息,从而改善人体姿态估计算法的性能。
1 基于对抗学习的人体姿态估计算法
生成式对抗网络(Generative Adversarial Networks,GAN)是Goodfellow 等[10]提出的一种生成式模型,它由一个生成器和一个判别器构成,生成器的目标是尽量去学习真实数据样本的潜在分布,并生成新的数据样本;而判别器是一个二分类器,目标是尽量正确判别输入是来自真实数据还是生成的样本。如图1 所示,G表示生成器,用于生成人体各部件热图;D表示判别器,用于重构人体各部件的热图。给定一张输入图像,通过生成器G得到生成热图,然后生成热图和真值热图一起输入到判别器D中,并输出由生成热图重构的热图和由真值热图重构的热图。因此,生成器和判别器的构建在基于对抗学习的人体姿态估计中起着至关重要的作用。近年来,由于堆栈沙漏网络广泛应用于人体姿态估计的任务中,并且取得较好预测效果,本文采用堆栈沙漏网络来构建对抗网络中的生成器和判别器。
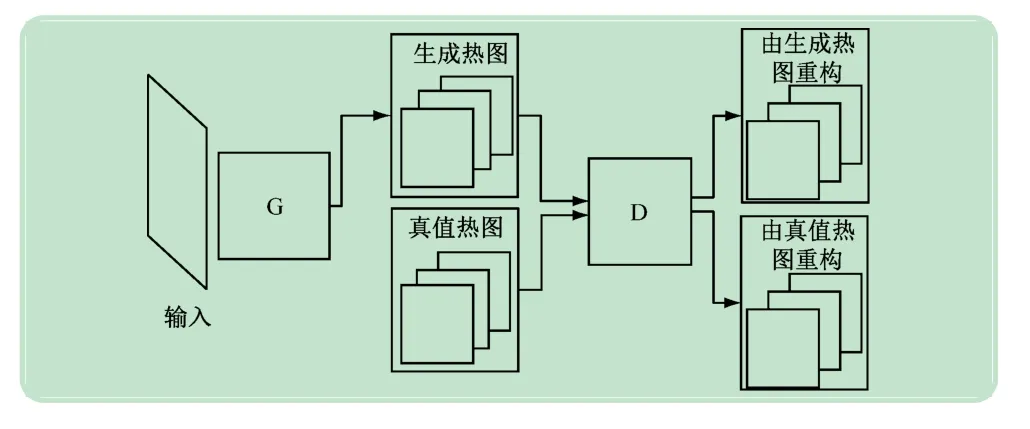
图1 基于对抗学习的人体姿态估计模型
1.1 基于沙漏网络的生成器
沙漏网络一般由残差模块、池化、卷积和反卷积部分组成,具有较好的感受野,如图2 所示。堆栈沙漏网络由多个沙漏网络串联而成。生成器主要用于学习并生成人体各部件热图,通过沙漏网络来构造生成器可以在输入图像中提取上下文特征,该沙漏网络单元由一个7 ×7 卷积层和几个残差模块构成,再输入到下一个沙漏网络单元中形成堆栈沙漏网络结构,最终输出各个关节点的热图。本文中生成器由4 个沙漏网络堆栈而成,在训练中,生成器损失函数分别来自生成器本身损失LMSE和判别器的对抗损失Ladv。来自于生成器本身的损失函数可以定义为
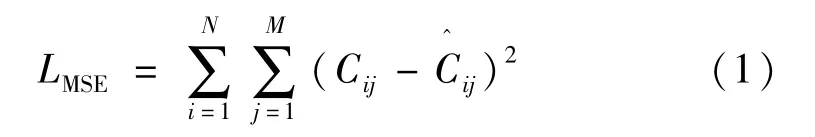
式中:Cij是第i个堆栈中第j个关节点的真值热图,通过2D高斯函数得到是生成的热图;N表示沙漏网络堆栈数;M表示每个沙漏网络生成热图的数量。
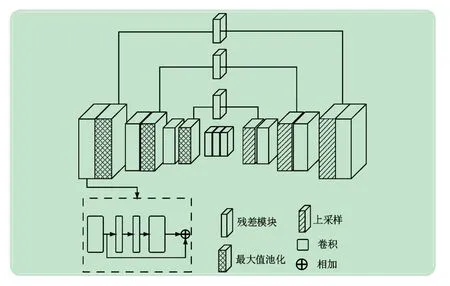
图2 沙漏网络结构图
自判别器的对抗损失函数可以表示为
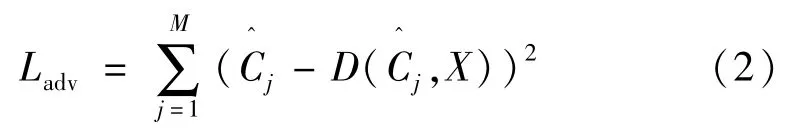
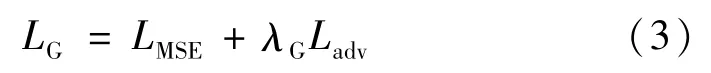
式中:λG是控制两种损失权重的超参数。
1.2 基于沙漏网络的判别器
针对给定的训练图像,通过生成器得到生成热图,并和真值热图分别输入到判别器中,生成重构热图。重构热图将分别用于计算Lreal和Lfake,在每次迭代中,判别器都使用累积梯度进行更新,该梯度是通过Lreal和Lfake进行计算。在图1 中,当判别器的输入为真实热图时,其输出为重构真值热图,需要最小化真值热图和重构真值热图之间的误差;当判别器的输入为生成热图时,需要最大化生成热图和重构生成热图之间的误差。因此,判别器的损失函数表示为:
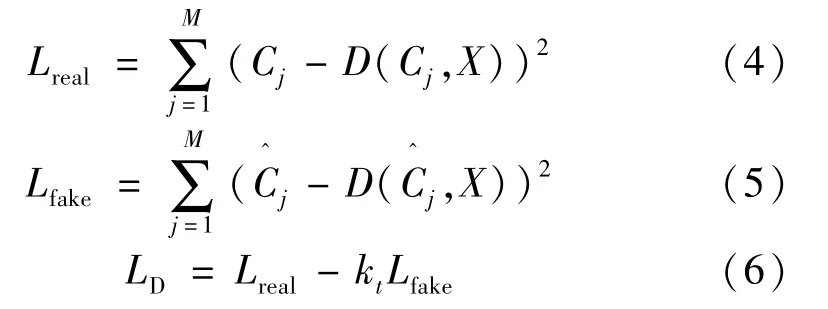
式中:kt表示超参数,用于控制生成器和判别器之间的平衡,防止整个网络由于判别器优化过快而引起的模式崩溃问题。
2 基于多尺度对抗学习的人体姿态估计算法
沙漏网络通过卷积和反卷积运算来获取丰富的人体部件特征,但是这种性能易受到多尺度金字塔结构中某一特定的尺度影响,同时还缺少鲁棒的跨尺度感知性能。因此,本文针对现有人体姿态估计算法对人体尺度变化敏感的特性,提出了基于多尺度对抗学习的人体姿态估计算法。如图3 所示,该生成器共由4个相同的沙漏网络堆栈而成,并在每个沙漏网络中引入了多尺度监督损失函数,从而提高整个网络检测不同尺度人体部件的性能。多尺度监督学习跨多个尺度的深层次特征,是通过在生成器和鉴别器沙漏模块中的每个反卷积层上添加了监督,即每一层对应着一个特征的尺度来实现的。该损失函数是由每个反卷积层上的特征图和对应尺度的真值热图运算得到:例如真值热图通过做1/2、1/4、1/8 的向下采样得到多尺度真值热图。此外,为了保证特征图和真值热图在维度上的一致性,本文使用1 ×1 卷积核降维,将高维反卷积特征图转化为所需的数量。由式(1)~(3),本文的多尺度对抗学习的生成器损失函数可以定义为:
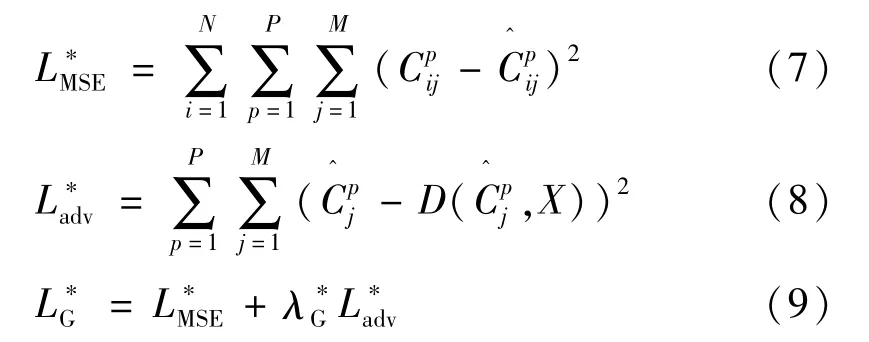
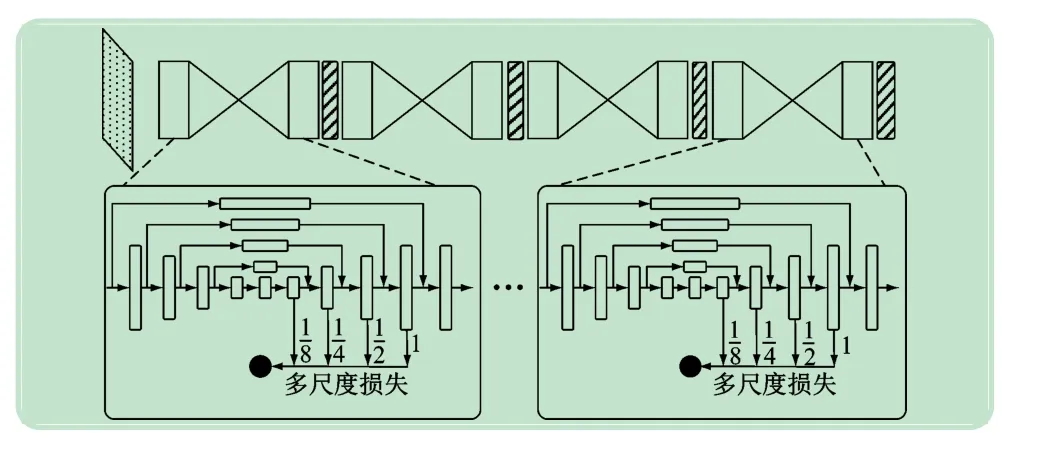
图3 多尺度对抗学习的生成器网络结构
在判别器中,同样采用了多尺度监督,其网络结构和生成器类似。判别器的输入是生成器最后一个沙漏堆栈的输出热图和真值热图,然后经过4 个相同的多尺度沙漏网络,形成多尺度对抗学习的判别器(见图4)。由式(4)~(6),多尺度对抗学习的生成器损失函数可以定义为:
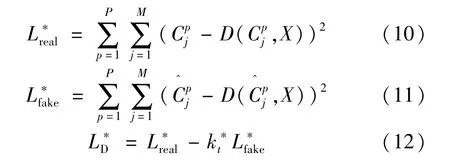
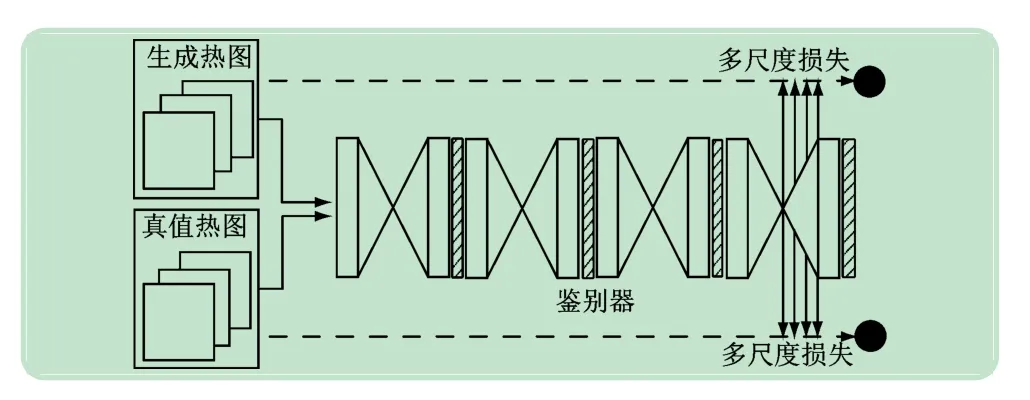
图4 多尺度对抗学习的鉴别器网络结构
3 实 验
本文采用LSP数据集(Leeds Sports Pose Dataset)、LSPE 数据集(Leeds Sports Pose -extended Dataset)、FLIC 数据集(Frames Labeled In Cinema Dataset)和MPII数据集进行人体姿态估计模型的训练与测试。LSPE数据集用来补充LSP数据集训练样本,一共包含11 000 张训练图像和1 000 张测试图像,每张图像包含一个人且标记了14 个关节点。FLIC 数据集中3 987张图像用于训练,剩余1 016 张图像用于测试,且数据集只标注了上半身人体姿态。这两类数据集中人体尺寸和着装多变,场景丰富多样,对人体姿态估计有着很大的挑战。MPII 数据集包含25 000 张带标注图片超过40 000 人,其中30 000 人用于训练,10 000 人用于测试。为了增加训练样本,本文将训练样本进行了顺时针和逆时针分别旋转30°,并做了翻转变换。整个模型采用Torch7 在NVIDIA GPU 上进行训练与测试。为了更加客观地评价模型的性能,本文采用了通用评价指标PCK(Percentage of Correct Keypoints)和PCKh(Percentage of Correct Keypoints with respect to head)。
为了验证多尺度对抗学习的有效性,在LSP 数据集上对比了基于对抗学习的有/无融合多尺度信息的人体姿态估计算法的结果。如表1 所示,本文分别对人体的不同关节点计算了PCK指标,实验结果表明多尺度对抗学习能提升各个关节点预测的正确率。此外,在平均值上,加入多尺度信息的人体姿态估计模型比没有多尺度信息的模型提高了0.7%。
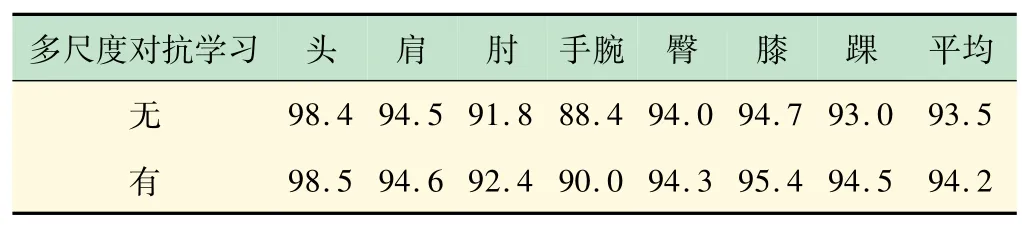
表1 对抗学习实验结果比较
表2 和表3 给出了本文算法和现有部分人体姿态估计算法分别在LSP数据集和MPII 数据集的测试样本上的正确率。从表中可以看出,本文算法和现有人体姿态估计算法相比,较为明显地提高了肢体上的关节点(肘、手腕、膝、踝)预测正确率。表4 中给出了在FLIC数据集上人体姿态估计的正确率比较,结果表明在肘和手腕的关节点上正确率均高出了传统方法。
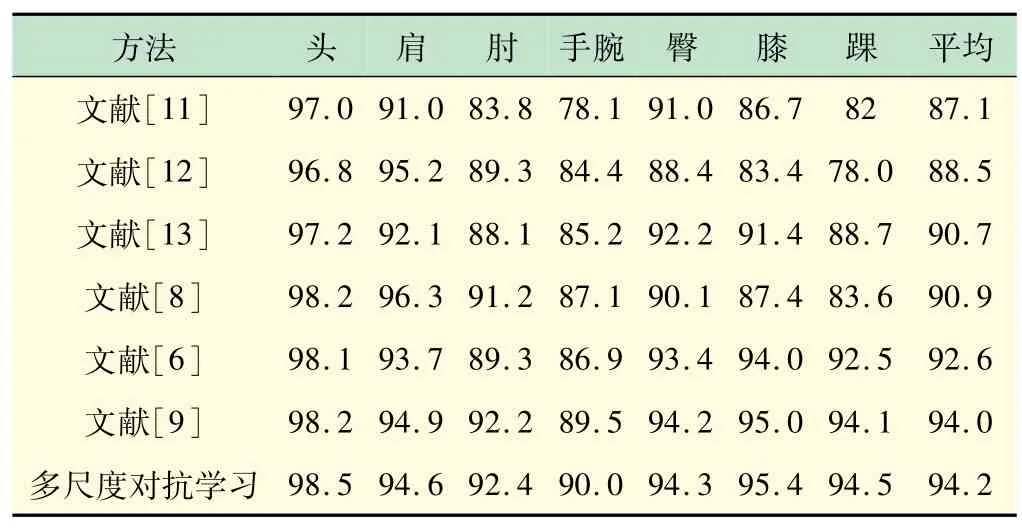
表2 LSP数据集上PCK准确率比较
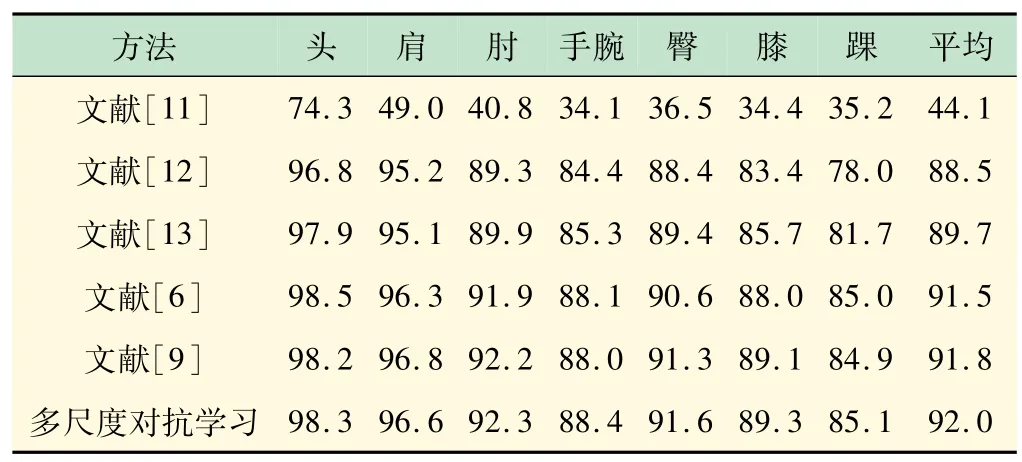
表3 MPII数据集上PCKh准确率比较

表4 FLIC数据集上PCK准确率比较
图5 给出了本文提出的基于多尺度对抗学习人体姿态估计模型对LSP 数据集中几幅示例图片的人体姿态估计结果。示例图像存在自遮挡、不同衣着、不同尺度、图像模糊等样本,从图5 中可以看出,本文提出的算法可以在这些非常具有挑战性的图像中成功定位出人体关节点,这表明了本文提出的算法具有较好鲁棒性。

图5 人体姿态估计示例
4 结语
本文主要对基于对抗学习的人体姿态估计算法进行了研究,提出了一种基于多尺度对抗学习的策略。通过堆栈沙漏网络来构造对抗学习的生成器和判别器,然后分别在生成器和判别器上融合多尺度人体部件特征。实验结果表明本文提出的基于多尺度对抗学习的人体姿态估计算法可以较明显提升姿态估计的正确率。
