一种两阶段的漫画自动着色模型
2020-12-10吴志强何彦辉
郭 燕,吴志强,何彦辉
1(中国科学技术大学 苏州研究院,江苏 苏州 215123) 2(中国科学技术大学 软件学院,江苏 苏州 215123)
1 引 言
在漫画的创作过程中,着色是非常重要的步骤,对漫画着色不仅需要较好的绘画技术,而且非常耗时.因此一种对漫画进行自动着色的系统将非常实用,可以满足很多用户的绘画需求并大大提高工作效率.本文提出了基于对抗生成网络[1]的分阶段漫画着色模型,对漫画线稿进行自动着色,并可以得到满意的着色结果.
漫画从线稿到着色的过程可以看作是图像生成任务[2].早期的很多图像生成任务基于非参数模型实现[3],随着深度学习的出现,提出了很多基于深度学习的图像生成模型[4].这些基于深度学习的图像生成模型当前主要用于真实照片的生成任务,例如语义分割[5]、黑白照片着色[6]等.
已有的漫画着色模型[7]在很大程度上借鉴了黑白照片着色模型的思想.黑白照片着色模型使用编码器解码器结构实现,模型对输入的黑白照片进行一系列下采样来获得特征信息,然后对获得的特征信息进行反卷积[8]操作,上采样得到着色结果.虽然这种方式可以完成黑白照片的着色,但直接的反卷积操作会对漫画着色产生负面影响.相比于真实照片,漫画的线稿没有丰富的图像纹理、阴影等信息.如在测试部分所看到的,特别是由于纹理信息的缺失,如果直接将这些方法迁移至漫画着色任务,会存在很多问题.譬如生成的着色结果会出现大量棋盘状,严重影响美观.同时直接编码解码会丢失很多底层信息,在解码器进行漫画着色的时候会由于底层信息丢失,着色位置出现偏差.本文第5部分进行了对比实验,验证了反卷积在漫画着色的场景中存在的缺陷.
为了解决这个问题,本文提出了一个分阶段的漫画着色模型.在第1阶段,使用基于U-net[9]的条件生成网络[10],同时为了保留更多的底层漫画信息,在生成器的设计中引入了inception[11]和resnet[12]结构.第1阶段的主要作用是在对线稿进行大体着色的基础上,丰富漫画的纹理,为第2阶段的任务提供更多颜色和纹理信息.第1阶段可以生成主要的颜色、

图1 原稿-线稿-提示色-着色Fig.1 From sketch to colored comic
纹理信息,但存在较多的噪声信息.第2阶段使用第1阶段的生成结果作为第2阶段的模型输入,并使用迭代反射网络[13]来处理噪声信息问题.通过迭代,纠正第1阶段的着色错误信息,以达到理想的着色效果.图1示出了漫画着色的整个过程,从左上到右下依次是漫画的原稿、线稿、提示颜色、模型着色最终效果.
2 相关工作和本文贡献
2.1 对抗生成网络
自2014年提出对抗生成网络(GAN)后,GAN就被广泛用于各个领域.对抗生成网络包括生成器和判别器两个部分,生成器从先验分布的随机信号中生成模拟样本,判别器则接受生成器生成的样本或接受真实的样本,以此判别其来源,两个部分进行对抗训练来达到平衡.普通的生成网络从随机信号开始学习,而条件生成网络则需要依靠先验的条件信息进行生成,这样增大了条件生成网络的灵活性,可以通过条件控制生成结果.条件生成网络的先验信息可以是文本、图像、颜色等,因此本文利用条件生成网络这一特性来对漫画进行着色.
2.2 pix2pix
Pix2pix模型[14]的提出是为了解决图像翻译问题,其模型的主体框架由一个生成网络构成.对于图像翻译问题,模型输入和输出的外在表现形式虽然是不同的,但是它们之间却有相同的潜在底层信息.Pix2pix模型为了保留这些底层信息,其生成器被设计为U-net结构,同时在生成器的编码解码阶段应用了跨连接的结构.Pix2pix的作者将其应用在了很多不同的图像翻译任务中,都达到了比较好的效果.就漫画着色的本质而言,也是一种图像翻译的任务.
2.3 U-net
U-net网络是基于CNN的图像分割网络,主要用于医学图像分割.这一网络分为下采样和上采样两个阶段,下采样通过卷积计算得到图像的隐层特征,上采样将隐层特征复原得到目标图像.网络结构中只有卷积层和池化层,没有全连接层.在网络结构的构建中,较浅的层用来获得高分辨率的特征解决像素定位的问题,较深的层用来获得低分辨率的特征解决像素分类的问题,从而实现图像语义级别的分割.与全连接神经网络[5]不同的是,U-net的上采样阶段与下采样阶段中的卷积操作是一一对应的,同时在这两个阶段中对应层使用了跨连接结构将其相连,使得下采样层提取的特征可以直接传递到上采样层,这使得U-net网络的像素定位更加准确,分割精度更高.
2.4 迭代反射网络
迭代反射网络(Deep Back-projection network)的提出主要是用于图片超分辨率[15].在DBPN网络出现之前,基于深度学习的图片超分辨率主要分为两个步骤,首先通过卷积运算从低分辨的图片中学习到特征信息,然后将这些特征信息映射到高分辨率的图片结果中.对比其它网络,DBPN网络中迭代的错误纠正机制能够学习低分辨率图片和高分辨率图片之间的对应关系,并达成满意的超分辨率效果.在漫画着色的第2阶段中引入了DBPN网络的思想,通过对第1阶段的颜色错误信息进行纠正来达到理想的着色结果.
2.5 本文贡献
本文针对漫画着色问题,提出了一个两阶段着色模型.该模型能根据漫画线稿和相应颜色提示信息,对漫画线稿进行自动着色.两阶段具体描述如下:
第1阶段.第1阶段模型主要根据漫画线稿和相应颜色提示,绘出漫画主体颜色并勾勒出漫画纹理.虽然这一阶段可以达到基本着色要求,但因为缺少完善的漫画具体细节,会出现较多的杂乱颜色.该阶段的主要目的是为第2阶段提供更多的颜色纹理信息.
第2阶段.第2阶段模型的目的是对第1阶段着色结果的错误颜色信息进行纠正.该阶段模型的输入是第1阶段模型产生的漫画着色结果,通过迭代地纠正颜色错误信息来改善漫画着色结果,最终产生理想的着色效果.
3 模型结构
3.1 预备工作
生成对抗网络由两个相关的网络模块组成,也即生成器模块和判别器模块,生成器主要是用来得到真实数据的分布,判别器则通过对样本进行评估,判断样本是来自于生成器还是真实样本,并对生成器模型进行优化.训练过程中这两个部分交替进行训练.模型中的生成器和判别器都使用深度卷积神经网络来实现.理想情况下模型的训练会达到纳什均衡.为了模型训练的稳定,文中用Wasserstein距离[16]进行训练,算法的公式如式(1)所示:

(1)
其中,x是来自于真实的样本数据分布pdata,z是来自于先验分布pz的随机噪音(例如,均匀分布和高斯分布).条件生成网络是对生成对抗网络的扩展,在条件生成网路中生成器和判别器都接受额外的条件变量c,相应对应着G(xmc)和D(x,c).
3.2 第1阶段
为解决使用反卷积操作导致的棋盘状问题,文中采用亚像素卷积(sub-pixel convolution)[17]的方式对生成的特征空间进行卷积操作.亚像素卷积可以生成出相应倍数的特征图,对特征图进行重新组合成最后的结果.通过这样的卷积操作方式成功解决了用反卷积出现的问题,实验也证明了在漫画着色问题中亚像素卷积相对于反卷积的更适宜性.另一方面,第1阶段着色模型中存在的另一主要问题是生成器所需的先验信息相对较少,频繁的下采样会丢失大量的底层信息,为了保留这些底层信息,在编码解码过程中采用了跨连接的结构,同时为了获得不同尺度的底层信息,模型在编码的过程中使用了res-inception的结构来实现.通过以上方式,生成器在解码操作过程中生成的图像可以更加贴近实际,不会出现颜色崩坏现象.在实验部分验证了该模型的有效性.
第1阶段的网络模型如图2所示,网络中生成器的输入是漫画的线稿和与之对应的颜色的提示,条件生成网络的判别器除了接受生成的着色结果外,还接受相应的条件信息和漫画的线稿信息.第1阶段的模型会根据线稿和颜色提示信息来对漫画进行着色,生成初步的着色结果,第1阶段的模型的输出是yi.
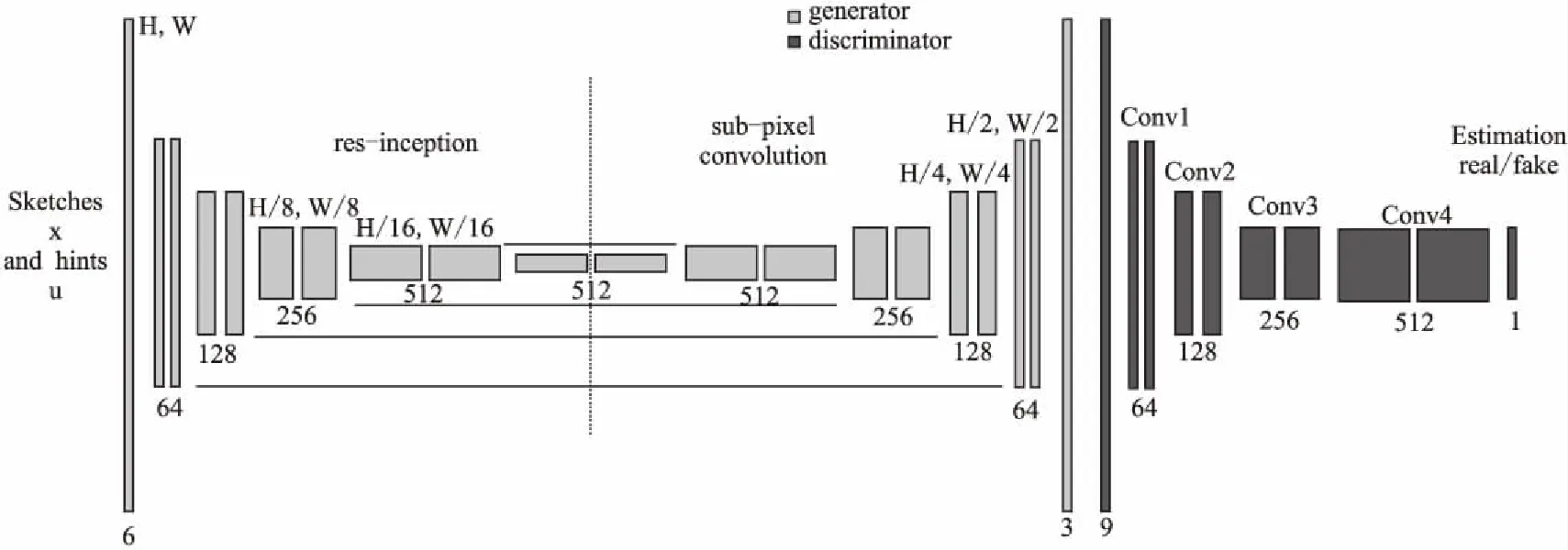
图2 第1阶段的模型结构Fig.2 Network architecture of Stage-I
第1阶段模型通过最小化式(2)的目标函数来训练.
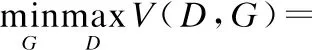
(2)
式(2)中x是输入的漫画线稿,y是漫画真实的着色的照片,u是提示颜色,G(x,u)是生成的漫画着色的照片.判别器D的输出结果是对漫画的评分,评分结果用来判断漫画是来自于真实的样本空间还是生成的样本空间中的.
生成器的目标是最小化如式(3)所示的生成损失.
LG=x,y~pdata(x,y),u~pdata(u)[log(1-D(x,G(x,u)))]
(3)
同时,加入了L1距离来控制生成漫画和真实漫画之间像素级别的相似性,并引入α进行损失函数的权重控制,最终的损失函数如式(4)所示:
L1=x,y~pdata(x,y),u~pdata(u)[‖y-G(x,u)‖1]
(4)
最终的目标函数定义为如式(5)所示:
L=LG+αL1
(5)
3.3 第2阶段
第1阶段只是对漫画的整体进行着色,而漫画着色任务中所涉及的细节较多,会出现譬如颜色位置混乱、细节出现杂色等的问题,第2阶段的主要任务是针对这些问题进行修正,以完善第1部分的着色结果.
为了解决第1阶段的着色问题,第2阶段构建了迭代反射网络,其主要是使用迭代的上采样和下采样单元,通过学习错误的残差来达到纠正的目的.第2阶段的网络模型结构如图3所示,第2阶段模型的输入是第1阶段的漫画着色结果,模型的最后输出是最终的着色结果.网络结构包含两种结构单元,一种是从低分辨率到高分辨率的映射(up-projection),另一种是从高分辨率到低分辨率的映射(down-projection).其中上采样单元由式(6)定义.
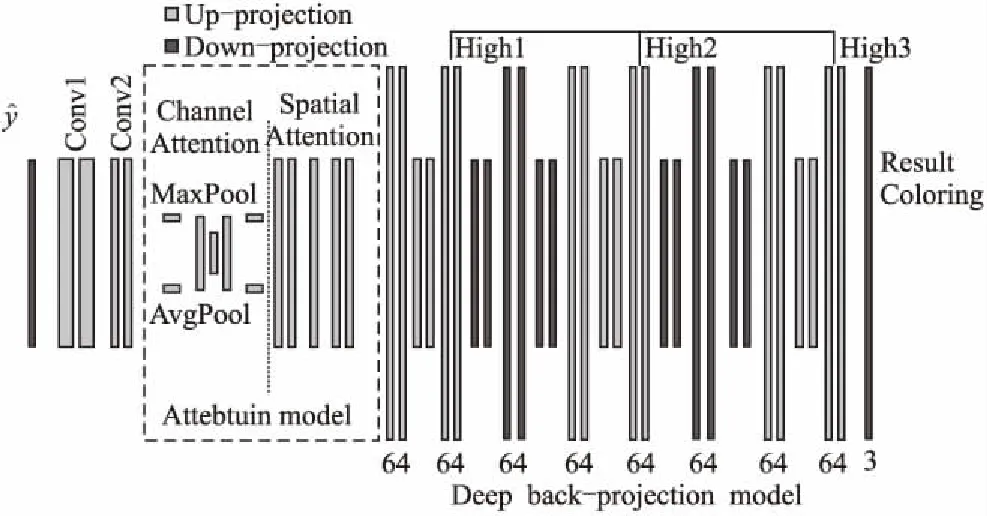
图3 第2阶段的模型结构Fig.3 Network architecture of the second stage
(6)
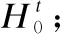
同时为了提升模型修正的效果,在第2阶段的模型中加入了卷积注意力机制[18],注意力机制用于特征提取的预处理,通过训练对不同的部分得出不同的参数,使得模型对于不同的部分有着不同程度的强调.注意力机制在特征图通道和空间两个方面上进行计算,公式如式(7)所示:
MC(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=
W0∈C/r×CW1∈C×C/r
(7)
其中,F是输入的特征图,AvgPool和MaxPool分别表示平均池化和最大池化,在通道机制中平均池化和最大池化是相对于特征图的,所以得到大小为1×c(表示通道数)的特征向量.MLP表示多层感知机模型,W0和W1表示全连接层中的权重,r表示中间特征的缩放率.这个层是两个网络共享的,将经过MLP层的两个结果进行相加通过σ函数得到最后的通道注意力的特征图,最后与输入的特征进行元素级的相乘得到的通道注意力的结果.
空间注意力机制的实现公式如式(8)所示:
Ms(F)=σ(f3×3([AvgPool(F);MaxPool(F)]))=
(8)
与通道注意力的计算不同,公式(8)中平均池化和最大池化是相对于通道的,所以得到的是与特征图F相同维度的注意力特征图.首先对平均池化和最大池化特征进行连接操作,然后将特征图用3×3卷积核进行特征融合得到最后的空间注意力特征图.该空间注意力特征图与原特征进行元素级别的乘法得到最后的特征图.通过注意力机制可以得到更好的提取特征,从而可以得到更好的修正结果.
第2阶段的网络模型通过对第1阶段的结果进行迭代修正来得到着色结果.第2阶段的目标函数如式(9)所示:
L=
(9)
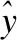
4 实 现
第1阶段的生成器使用了5对编码器解码器的卷积神经网络.在编码的过程中为了获得不同尺度的特征信息加入了res-inception的结构,res-inception的结构如图4所示,其中inception的结构是为了获得不同尺度的语义信息,resnet的结构是为了保留编码过程中的底层信息.网络中所用到的卷积大部分是用3×3或1×1者的卷积核.除了最后一层是Tanh激活函数,其他的层都是LeakyRelu激活函数来实现的.在两个阶段的网络构造中卷积层和激活层之间都加入了BatchNorm层.
其中,res-inception结构中的当前层获得的是前一层网络的特征信息,然后通过不同大小的卷积核和池化层来获得不同尺度的特征信息,两组相邻的inception结构构成一个整体,残差结构用来获得底层信息.这样既可以保留底层信息也可以得到高层的语义特征,对于漫画着色有着显著的提升.网络在在构建中借鉴了语义分割网络的思想,在成对的编码解码过程中保留了跨连接的层,这与U-net的结构是相同的.实验证明了文中所加入的res-inception结构对于信息保留的有效性.在解码的过程中采用的是亚像素卷积,采用亚像素卷积的方式可以克服反卷积的操作导致的着色结果中生成的很多棋盘状的方格等问题,同时也可以有效的对第1阶段的漫画进行纠正.
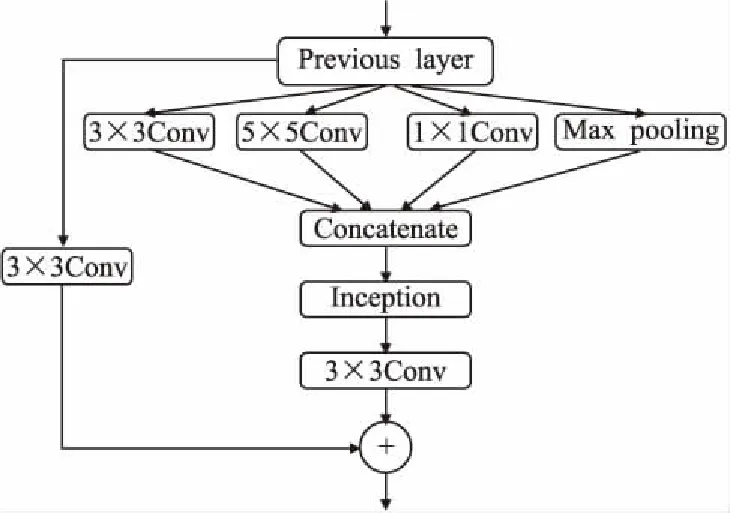
图4 Res-inception结构Fig.4 Network architecture of the Res-inception
默认情况下,在第1阶段中各个层的基数是Ng=64和Nd=64,所以生成器和判别器的层数都是64的倍数.生成器的输入是256×256×6的特征图,包括256×256×3大小的漫画线稿和与之对应的相同大小颜色提示信息.网络的输出是256×256×3的漫画着色的结果.在判别器中网络的输入大小是256×256×9的特征图,也即,除了生成器的输入外,还包括生成器着色后的输出.判别器的输出是32×32×1大小的特征图,输出的方式借鉴了patchGAN[19]的思想,在下采样的过程中通过网络的输出大小来控制输入空间的特征图大小,间接的可以控制生成器生成的着色结果的局部效果.
在第2阶段的模型构建中,因为显存的限制,不能同时将两部分结合在一起进行训练.模型训练中,先迭代的训练第1阶段的判别器和生成器20轮,然后再训练第2个阶段.在两个阶段的训练中都使用了Adam优化器,在训练过程中都使用batch大小为4的数据集.初始化的学习率是0.02,学习率每5轮会进行一次衰减.
5 实 验
5.1 数据集
为了训练文中提出的漫画着色神经网络,从公开的动漫网站(1)http://safebooru.org/上获取大约28000多张卡通图片.因为模型在训练过程中需要用到漫画原稿和与之对应的漫画线稿,但是配对的数据集相对较少不能够满足训练需求.为了训练模型,使用Styel2Paints[20]中提取线稿的方法从原始的漫画照片中提取出与之对应的漫画线稿,从而可以得到充足的配对数据集.然后.同时为了便于后面模型的训练,将得到的漫画照片都切割成了512×512大小.
第1阶段的模型生成整体的漫画颜色,为了控制生成,第1阶段中使用的是经过缩放的大小的输入输出,第1阶段的结果作为第2阶段的输入,第2阶段生成最后的结果512×512大小的输出.第1阶段的颜色提示信息从原始的照片中随机选取,随机选取30个正方形色素块作为输入,正方形大小随机从3,4,5,6,7,8中选择.
测试集是另外获取的2000张图片,这2000张数据集在训练的数据集中没有出现过,同时人物形象也并不相似,以更好验证算法的有效性.
5.2 评价指标

图5 各个模型的对比Fig.5 Comparison of different models
对于图像生成的任务很难用一个评价标准来进行衡量,现有工作中的大部分着色模型,都是通过人为的主观意识来进行打分评判.如果用户提示颜色与漫画原稿中的颜色存在很大差异,会使漫画的着色结果与原来的颜色存在着很大的不同,在测试阶段便只能从视觉的满意程度上来对其进行评判.为了避免上述问题,在测试阶段,同样可以从测试的原稿中提出提示颜色来进行着色测试,这样生成的着色结果与原稿理论上不会存在着很大的不同.所以在本文进行测试实验的时候,提示色信息从原稿中进行提取,这样可通过比较生成结果与原稿的PSNR[21]值来对模型进行评定.PSNR即峰值信噪比,是一种评价图像的客观标准,其中PSNR值的数学定义如式(10)所示:
(10)
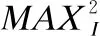
(11)
5.3 结果分析
在这一部分将对漫画着色模型的结果进行分析,对提出的模型的各个部分在数据集上进行了对比实验,同时与基准的模型pix2pix进行了对比验证.
表1示出了针对测试数据集的2000张照片,计算平均值得到对于各个模型的PSNR值的结果,表1对应于图5各个模型的结果图.第1阶段的模型由前面的3部分组成,表中对各个部分进行了对比实验,通过与baseline的模型pix2pix进行对比,验证了各个部分的有效性.表中的PSNR的值也可以得到每一部分相对于基准模型的提升.所有的模型都使用相同的数据集训练,同时测试数据集也使用相同的测试照片.虽然PSNR值只是反映了着色结果在质量上的接受程度,但从图5可以看出,不同模型有着明显的质量优劣的差异.本文的第2阶段着色的漫画人物的表情和形象都更细腻,着色的结果更符合漫画着色的结果.第2阶段成功的改善了第1阶段着色结果从在的缺陷,极大的提升了漫画着色的质量.通过以上的对比试验,验证了我们所提出的分阶段漫画着色模型的有效性.
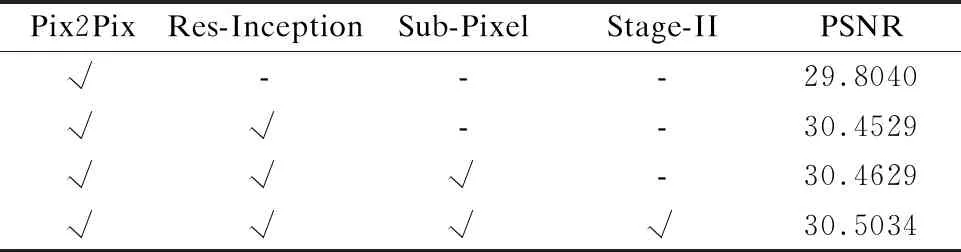
表1 不同模型的PSND值Table 1 PSNR on different models
6 总 结
本文提出了一种分阶段的漫画着色模型,通过将着色任务分解成两个子任务来实现,明显提升了漫画着色结果的质量.在第1阶段中,算法用条件生成网络来对漫画主体颜色进行填充,这一阶段的着色结果存在很多的错误和杂色等问题,但是相对于漫画的原始线稿,也丰富了漫画信息,这些信息为第2阶段的着色提供了很大的帮助.在第2阶段中,通过注意力迭代纠正的机制对第1阶段中出现的问题进行了改善,最后生成理想的着色结果.实验已经验证了此着色模型对于漫画着色问题的有效性,从数据上、实验结果的视觉感官体验上皆可感受到较好的漫画着色效果.算法从图像生成任务出发,成功构建出一个专门针对漫画着色的模型.实验中颜色提示信息都是从漫画原稿中提取的,然而在实际的着色任务中颜色会更加复杂多变,因此,后续的工作将会构建一个支持着色模型的前端框架,用户可以自己挑选颜色提示信息,以提升漫画着色的灵活性,方便用户的使用.
