预标准化Transformer在乌英机器翻译中的实现
2020-12-10陈子祥李大舟李耀松
高 巍,陈子祥,李大舟,李耀松
(沈阳化工大学 计算机科学与技术学院,沈阳110000)
1 引 言
2013年习主席提出的“一带一路”极大地促进了沿线各国的深度合作.在此基础上,各国之间的交流愈加频繁,国家语言之间的转换需求也与日俱增,机器翻译愈发受到重视.目前,机器翻译方法呈现出多语言、高质量的发展趋势,能够将一种语言翻译成多种语言,并且在一定程度上保证了翻译质量[1].然而不同语言之间在语法规则、书写形式等方面存在差异,且小语种的语料资源稀缺,因此寻求一个高质量的翻译模型成为了提高翻译的效果重要手段.
印度和巴基斯坦作为“一带一路”战略中南亚地区代表国,具有独特的地理位置和政治因素.“一带一路”战略涉及的官方语言有 50 余种[2].乌尔都语作为巴基斯坦的母语,也是印度的官方语言.它属于印欧语系印度语族,书写形式为自右至左书写,词与词之间没有空隔隔开.英语作为全球通用的官方语言,也是印度的官方语言之一.因此,实现乌尔都语与英语之间的翻译对于“一带一路”的发展具有重大意义.
本文提出了一个基于预标准化Transformer的乌英机器翻译模型.首先将源语言向量加上位置编码,然后传入预标准化层.将预标准化后的词向量作为输入传入编码器,编码器中采用多头注意力机制以充分获取源语言句子的语义信息,然后将输出结果传入解码器进行解码.经解码后的输出向量经过线性变换后再经函数处理得到反映每个目标单词概率的输出向量.将BLEU值[3]作为评价译文质量标准,输出最优译文.
2 相关工作
近年来,关于乌尔都语与英语之间的机器翻译的研究,仍以统计机器翻译[4]为主.统计机器翻译过程为以下几个阶段:处理分词、标记词性、词语对齐、语言模型的训练、翻译模型的训练、调节模型、最小错误率评分等[5,6].不仅过程繁锁,且以统计分析的方法很难获取高质量译文,因此通过改进翻译模型来提高翻译质量成为研究热点.王志洋通过对词语进行形态分析并将词干与词缀分离,再进行对齐的方法来改进翻译模型[7],提高了翻译质量.Shahnawaz等提出基于GIZA++、SRILM和MOSES解码器的英语-乌尔都语机器翻译系统模型[8],采用最小错误率训练方法,对因子翻译模型进行译码和训练.为了取得更好的翻译效果,Shahnawaz等人又提出了一种基于机器翻译实例推理(CBR)、翻译规则库模型和人工神经网络(ANN)模型的乌英机器翻译模型[9],采用CBR方法对输入的英语句子进行乌尔都语翻译规则的选择.
由于人工神经网络不能很好地利用已有的先验知识,再加上人工干预多,推理速度慢等缺点,不能很大程度地优化翻译质量[10].因此,神经机器翻译的(Neural Machine Translation,NMT)出现,对于传统机器翻译模型存在的问题有了很大的改善[11].神经机器翻译通过学习源语言表达方式分析预测出目标语言,实现双语映射[12].例如Bahdanau和Cho利用神经网络模型对词汇进行联合对齐概率计算[13,14],生成翻译候选集,进而对候选集进行评分并输出最优译文.Barret Zoph[15]等人基于长短时记忆网络(Long Short-Term Memory,LSTM)搭建了神经机器翻译系统,实现乌尔都语到英语的翻译.但是这种模型训练过程是串行进行,耗时较大,且模型对上下文的理解欠佳.因此,对乌英机器翻译模型的进一步改进成为研究热点.
针对上述问题,本文提出一种基于预标准化Transformer的翻译模型,作为乌英翻译模型中源语言编码和目标语言解码的载体.在基准Transformer模型中加入预标准化,保证数据分布一致的同时避免发生梯度消失,有效的提升了乌英机器翻译的效果.
3 基于预标准化Transformer的机器翻译模型
宏观来看,Transformer是一个黑盒,输入一种语言,经过这个黑盒能输出另一种语言.宏观结构图如图1所示.它是由编码器和解码器以及它们之间的连接组成.输入乌尔都语,通过堆叠的编码器输出对应特征向量,再将编码器的输出向量作为解码器的输入,最终输出英语.
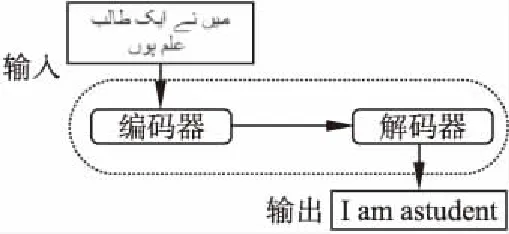
图1 Transformer宏观结构图Fig.1 Macro structure of transformer
本文提出的预标准化Transformer模型的主体结构图如图2所示.首先对源语言进行词嵌入,生成对应词向量,加上对应位置编码.将计算结果进行预标准化处理,处理后的结果经线性变换获得密钥K,值V和查询Q矩阵作为编码器的输入.编码器内部采用多头自注意力机制,聚合输入的源语言单词的信息,生成每个单词的新表示.再经前馈层得到编码器的输出.为了避免梯度爆炸,在每层网络后引入残差连接和归一化层.解码器将上一时刻的输出经掩码多头注意力层后再经线性变换得到查询Q矩阵,将编码器的输出经线性变换后得到密钥K和值V矩阵.再将K,V和Q矩阵作为多头注意力的输入,解码后的输出再通过线性变换和softmax得到每个单词概率的输出向量.
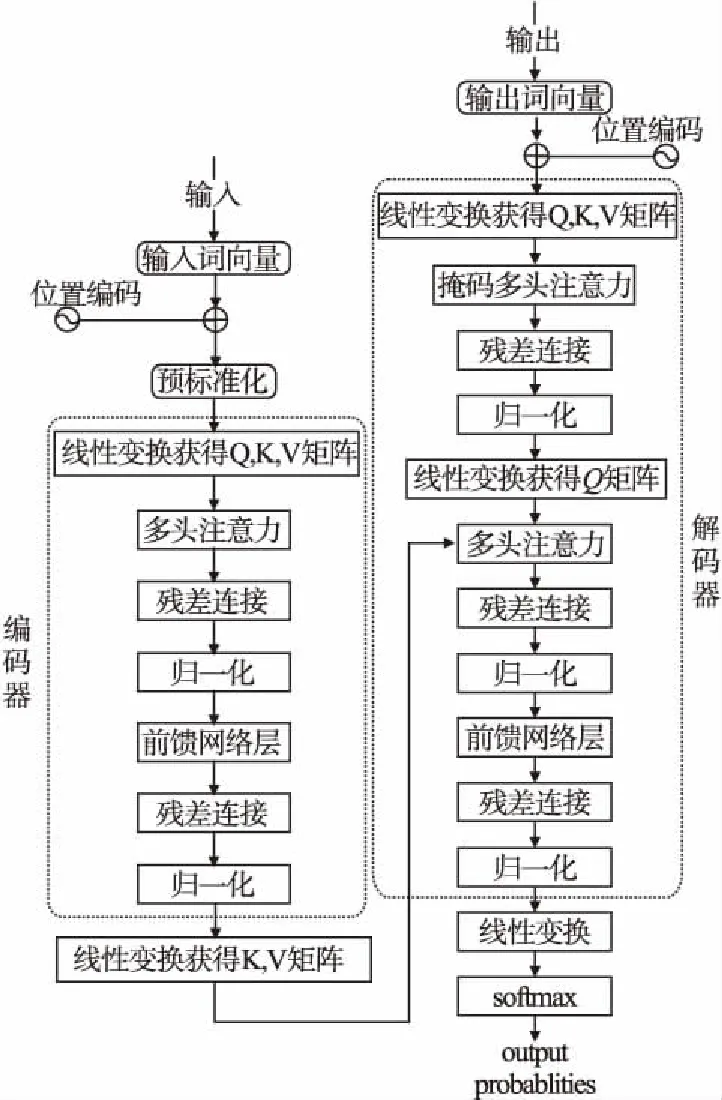
图2 预标准化Transformer模型结构Fig.2 Pre-normalized Transformer model structure
3.1 位置编码
Transformer模型是并行接收输入序列的,所以不能捕捉顺序序列.位置编码特征的嵌入可以很好地解决这个问题[16].通过在词嵌入向量中加入单词的位置信息来使Transformer能够区分不同位置上的单词.
本文模型中采用的位置编码是正余弦位置编码,位置编码的计算公式如式(1)所示.
(1)
其中PE是Positional Encoding的缩写,指的是位置编码.pos是指当前的词在句子中对应的位置,i是指向量中每个值的下标.在偶数位置,使用正弦编码;在奇数位置,使用余弦编码.
假设词嵌入的维度为4,即dmodel=4,则可以根据公式(1)写出对应的位置编码.如表1所示.

表1 位置编码表Table 1 Positional encoding table
3.2 预标准化
预标准化层如图2所示.词向量加入位置向量后会产生分布不一致,一定程度上折损了模型的翻译效果.预标准化层的加入,保证输入数据分布均匀的同时,避免了梯度消失.
预标准化的公式如式(2)所示:
(2)
Layer Normalization计算公式如式(3)所示.
(3)
式(3)中,μ、σ分别代表均值和方差,a和b是可学习的参数,ε为随机取的极小数.
3.3 编码器设计
编码器的内部结构如图2左侧虚线框内所示,编码器由多头自注意力机制和前馈神经网络两个部分组成.预标准化处理后的输入向量经过多头注意力机制得到一个上下文向量,将该向量与输入向量求和后经归一化处理传入前馈神经网络层(Feed Forward Neural Network,FFN)[16].经前馈层处理后的输出向量再与该前馈层的输入求和,对求和结果进行归一化处理之后作为编码器的输出.
3.3.1 多头自注意力机制
多头自注意力机制是Transformer的核心内容,能让模型考虑到不同位置的信息.多头注意力机制的计算相当于多个不同的单自注意力机制的集成.单头注意力机制的计算过程如图3所示,图中仅为第一个输入向量a1的计算过程.
图3中单头注意力机制的输入是经预标准化后的特征向量a1,a2,…,ai,a1,a2,…,ai分别乘以不同的权值矩阵Wq,Wk,Wv,得到Q(q1,…,qi),K(k1,k2,…,ki),V(v1,v2,…,vi).计算公式如式(4)所示.
Q=Wq·[a1a2…ai]K=Wk·[a1a2…ai]V=Wv·[a1a2…ai]
(4)
式(4)中Wq,Wk,Wv是随机初始化权重方阵.a1,a2,…,ai是输入数据经过词嵌入和位置编码相加之后的特征向量.
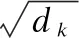
(5)
对关联度矩阵A进行softmax得到标准化矩阵B,将矩阵V与矩阵B点乘得到输出矩阵O,通过式(6)获得计算结果O.
(6)
由此可以得到特征向量Z,计算公式如(7)所示.
(7)
多头注意力机制的计算相当于多个不同的单自注意力机制的集成.多头注意力机制的计算公式如(8)、(9)所示.
(8)
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
(9)
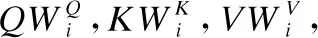
3.3.2 前馈神经网络层
前馈神经网络层(Feed Forward Neural Network,FFN)分为两个子层,第一个子层的激活函数为RELU,第二个子层的激活函数是一个线性函数,计算公式如(10)所示.
FFN(Z)=max(0,ZW1+b1)W2+b2
(10)
式(10)中,W1和W2是可学习的权重方阵,b1和b2是随机偏置向量.
3.4 解码器设计
解码器的内部结构如图2右侧虚线框内所示.解码器中分别包含掩码多头自注意力层、编码器-解码器注意力层和前馈神经网络层三个子层.将目标语言的词向量作为输入向量,经掩码多头注意力层后,将输出结果进行求和与归一化[17];将归一化后的结果和编码器的输出一起传入编码器-解码器注意力层;最后经前馈神经网络层得到解码器的输出.具体每层的计算过程如下.
第一层为掩码多头自注意力层,输入是目标语句的词向量.假设输入序列为Y=(y1,y2,…,yn),对yi进行预测时,掩码多头注意力层只对(y1,y2,…,yi-1)序列进行Attention计算(计算过程如3.3.1所示),防止训练时使用未来信息.
第二层为编码器-解码器注意力层,它的输入分为两部分,分别是掩码多头注意力层的输出和编码器的输出.将掩码多头注意力层的输出作为Q,编码器的输出作为K,V键值对,进行Attention,使解码器在解码当前词时充分考虑源语言的信息.
第三层为前馈神经网络层,它的输入为编码器-解码器注意力层的输出.它和编码器中的前馈神经网络层一样(计算过程如3.3.2所示).经此层输出的特征向量经线性变化和softmax函数之后得到每个单词概率的输出向量.
4 实 验
4.1 实验环境
实验的数据集共有两个来源,一是来源于由Jawaid和Zeman平行翻译的古兰经和圣经部分语句约15000行;二是来源于IPC(Indic Parallel Corpus),是亚马逊Mechanical Turk(MTURK)平台众包将六种印度次大陆语言翻译成英语的维基百科文档的集合[18].其中乌尔都语到英语平行语料库约35000行.共计有50000行数据集.其中43000行用来构建训练集,5000行构建验证集,2000行构建测试集.
首先对数据集进行Sentencepiece[19]处理.Sentencepiece算法分为两步,第一步固定词表,求一个句子困惑度最低的切分序列;第二步根据这个切分序列求固定词表,剔除一个词,计算困惑度,最后对困惑度设定一个阈值,筛选一些对语料集影响较大的词,组成词汇表.Sentencepiece处理后的部分源语句和目标语句如表2所示.

表2 SentencePiece算法处理后语料Table 2 Corpus processed by Sentencepiece algorithm
本文中采用的评价标准为BLEU.BLEU 是用来衡量机器翻译文本与参考文本之间的相似程度的指标,取值范围在[0,1].本文中最终的BLEU值截取了百分数的数值部分来进行衡量比较.
本次实验在显卡配置为RTX2070,内存8GB的笔记本上进行,系统环境为ubuntu18.04桌面版,实验时内存占用率为94%,参数量为64M.在深度学习框架TensorFlow上搭建神经机器翻译系统.模型相关参数设置如表3所示.
4.2 实验结果分析及对比
本文利用乌尔都语-英语双语料中预设的2000句对平行双语语料做测试集,采用BLEU值作为实验的评价指标.
实验每迭代一轮输出一次BLEU值.图4所示为预标准化Transformer模型迭代50轮的损失值变化情况和每轮BLEU值.由于在迭代次数到40轮之后,损失值和BLEU值的变化趋势都趋于平滑,因此,在图4中只给了迭代次数为前50轮时的变化情况.
从图4中可以看出,迭代次数在前40轮时,损失值和BLEU值的变化情况明显.随着迭代次数的增加,模型训练接近饱和,损失值变化趋于平缓.BLEU也趋于稳定,模型最优BLEU值为16.13.

图4 预标准化模型训练Loss和BLEU变化Fig.4 Changes of Loss and BLEU in pre-normalizedmodel training
本文进行了模型调参试验,对预标准化Transfromer采用控制变量法进行调参.实验设置如表4,实验结果如图5、图6所示.
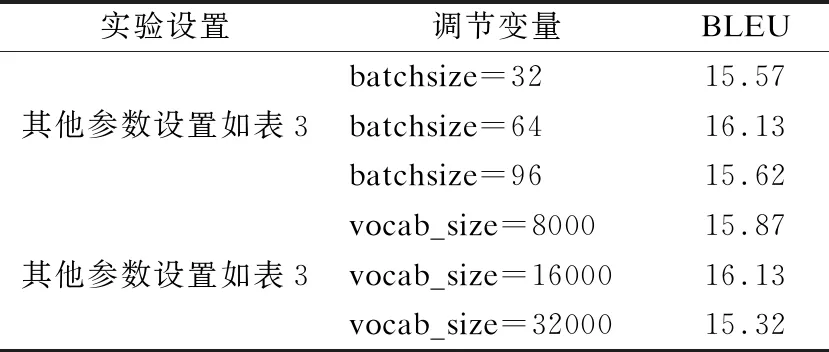
表4 调参实验设置表Table 4 Settings of parameter adjustment experiment
从图5中可以看出,batchsize为32时,模型的损失相对于其他两个更低,其BLEU值也优先收敛.但随着迭代次数增加,batchsize为64的BLEU达到最优且优于其他两个模型.因此batchsize的大小要根据具体实验情况设定.盲目增大batchsize会导致模型收敛速度变慢,而且模型易陷入局部最小值,导致模型精度较低;而batch过小则会导致模型泛化能力弱.
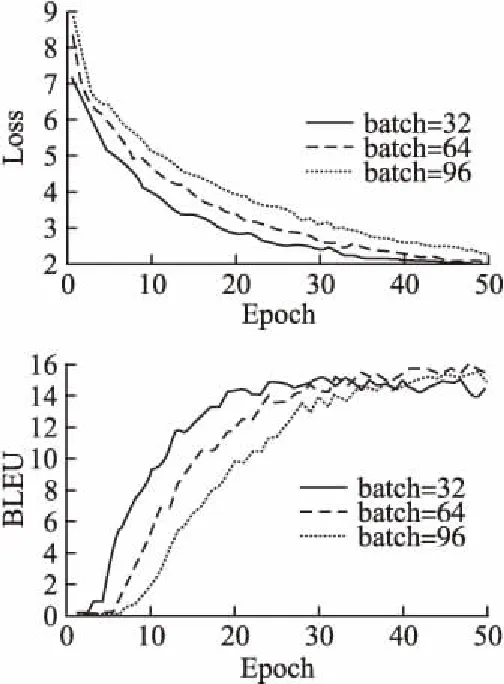
图5 不同batchsize下Loss和BLEU变化Fig.5 Changes of Loss and BLEU under different batchsize
从图6中可以看出,词汇量大小设定对于模型损失影响较小,但是,词汇量为16000时的BLEU值要略高于其他两个.因此,适当的设定词汇量大小,会使模型BLEU值有所提升.
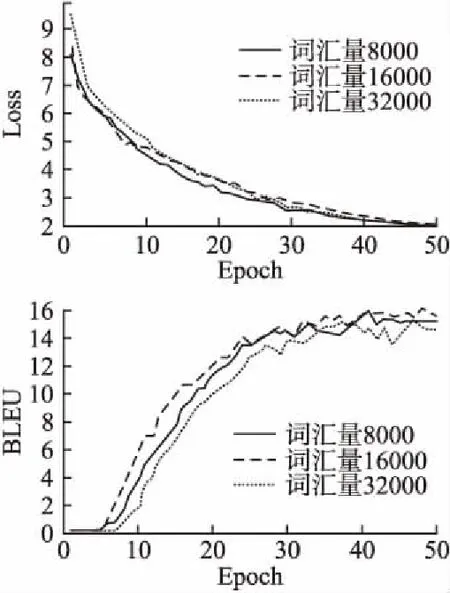
图6 不同词汇量下损失和BLEU变化Fig.6 Changes of Loss and BLEU under different vocabulary
本文又对模型网络结构进行了对比实验.实验设置如表5所示,实验结果如图7所示.
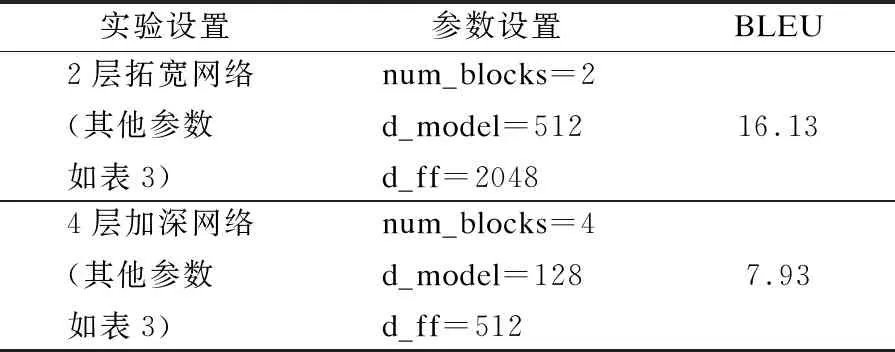
表5 结构对比实验设置表Table 5 Settings of structure comparison experiment
从图7可以看出,相同迭代次数内,拓宽网络层的损失下降速度和BLEU值远远优于加深网络层.因此,在基于Transformer的翻译模型中,增加单层网络隐藏节点数相较于堆叠网络层数翻译效果更好.
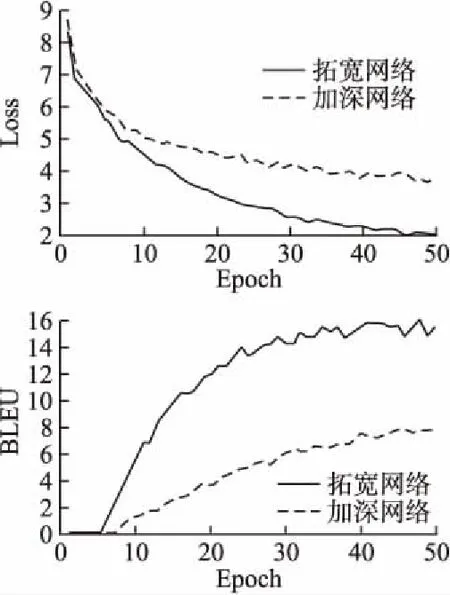
图7 拓宽网络与加深网络的Loss与BLEU变化Fig.7 Changes of Loss and BLEU between wideningnetwork and deepening network
本文预标准化模型与基准Transformer模型对比设置如表6所示,实验结果如图8所示.

表6 模型对比实验设置表Table 6 Settings of model comparison experiment

图8 预标准化模型与基准模型对比Fig.8 Comparison of pre-normalized model andbenchmark model
从图8中可以看出,本文提出的预标准化Transformer模型相较于基准Transformer模型在BLEU值上有一定的提高.且模型的翻译效果更加稳定,初始损失降低,模型收敛速度加快.这是由于预标准化的加入可以加快网络学习速度,提高模型的精度.最终本文模型的BLEU值比基准Transformer模型提高了0.71个BLEU值.
由于乌英平行语料属于低资源语料,为验证本文模型的有效性,分别在英-越、英-德大规模语料库上与基准模型进行了对比实验.实验所采用的英越平行语料为150K行,英德平行语料为200K行.实验时参数量为88M,实验所得BLEU值如表7所示.

表7 大规模数据集实验对比Table 7 Experimental comparison of large-scale data sets
由表7可得,在英-越、英-德语料库上,本文模型相较于基准模型在BLEU值上分别提升了0.48、0.45,验证了本文模型的泛化能力.
5 结束语
乌英机器翻译属于低资源语言的翻译,面临着平行语料资源稀缺的困难.为了缓解语料资源数据稀缺和词汇表受限带来的翻译质量不佳的问题,本文提出了基于预标准化Transformer的翻译模型进行乌英翻译.实验结果表明,基于预标准化Transformer的乌英机器翻译模型与基准Transformer相比,有效提升了翻译质量.预标准化的加入使得模型的收敛速度加快,模型的精度提高,且模型更加稳定.然而,Transformer每一层的结点需要和上一层的所有结点进行相关性的计算,因此,对计算成本和显存需求非常高.对于大规模数据进行高质量的特征提取和建模时,数据的预处理部分还需做进一步改进.
