基于英语枢轴的汉-越双语词典构建方法
2020-12-10陈亚豪张亚飞余正涛文永华朱俊国
陈亚豪,张亚飞,2,余正涛,2,文永华,朱俊国,2
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
随着经济全球化的深入及我国“一带一路”合作倡议的提出,中国与越南之间的交流日益频繁,对两国的语言处理产生了迫切的实际需求.汉-越双语词典是实现汉语和越南语之间信息检索、机器翻译等自然语言处理(Natural Language Processing,NLP)任务的重要双语资源,双语词典的质量对汉语与越南语的语言处理任务具有重要的影响[1].因此,对汉-越双语词典进行研究具有较大的价值.然而,针对汉-越双语词典构建的研究较少,且现有方法的词典构建效果有待提高.
近年来,国内外学者对双语词典的构建方法进行了大量研究.按照语料库资源的不同主要分为四类:基于平行语料库的方法、基于可比语料的方法、基于种子词典的方法、基于对抗网络的方法.
第一类为基于平行语料库的方法.该类方法以平行语料作为语料资源,利用语料中的文档对齐信息来进行双语词典提取.莫媛媛等人[1]、Gouws等人[2]及Luong等人[3]提出使用大型平行语料进行双语词典的抽取.由于平行语料中包含有高质量的对齐信息,因此基于平行语料构建双语词典的效果较好.但是,基于平行语料的方法通常只适用于大语种的部分领域,而小语种的平行语料非常稀缺甚至不存在,采用这类方法难以构建小语种双语词典[4].因此基于平行语料库的双语词典构建方法在实际应用中具有较大的局限性.
第二类为基于可比语料的方法.李舰等人[5]和Mogadala等人[6]提出基于可比语料来构建双语词典的方法.可比语料中含有大量交叉并非严格的互译信息,这些互译词语基本出现在语义相近但语言不同的上下文环境中,可在一定程度上缓解对平行语料的依赖,但针对低资源语言可比语料同样非常稀缺.
第三类为基于种子词典的方法.该方法通过大量单语语料来学习语言结构,并且使用少量的种子词典来学习映射关系,基于映射关系抽取双语词典[7-10].Mikolov等人[7]、Wick等人[8]通过大量单语语料来学习语言结构,并使用少量的种子词典来学习映射关系,提出了基于映射关系抽取双语词典的方法.Artetxe等人[9]提出了迭代自学习的方法从对齐数字的并行词汇表开始,逐级对齐嵌入空间.Cao等人[10]提出了一种分布模型,其利用单语数据学习双语词嵌入,将学习得到的双语词嵌入在共享向量空间中对齐,将每个单词与其对应翻译进行组合,以此实现双语词典的构建.基于种子词典的方法需要较为成熟的双语词典作为种子词典,但是由于受到小语种双语词典规模和质量的限制,性能还有很大的提升空间.
第四类为基于对抗网络的方法.Zhang等人[11]提出通过对抗网络对齐跨语言的词向量空间,同时提出了一种基于EMD(Earth Mover’s Distance)抽取双语词典的方法.而Alexis等人[12]在Zhang等人的基础上改进了对抗网络,并解决了hubness问题.由于两种语言的单语词向量空间表现出近似的同态性,存在线性映射能够近似地连接这两个空间,通过对抗网络来学习该映射关系,然后基于该映射关系抽取词典.同时提出了一个与词翻译准确性高度相关的无监督模型选择标准.该方法在有同源词的语言中表现良好,但是,由于汉语和越南语之间的语言差异性较大,直接通过对抗网络构建汉-越双语词典效果有待提高.
另外,相关学者提出基于枢轴语言进行双语词典构建的方法.吴华和王海峰提出了基于枢轴语言的词翻译模型[13],在源语言和目标语言双语资源有限的情况下,该模型通过源语言-枢轴语言和枢轴语言-目标语言来对齐双语语料,最终构建出源语言到目标语言的词对齐模型.该模型仍需要源语言-目标语言的双语词典作为监督信号,且该监督信号决定了诱导模型的好坏,即决定了最终的词典抽取质量.之后他们利用基于规则的机器翻译方法对基于枢轴的短语翻译模型进行了优化[14],提出了三种基于枢轴的词翻译模型.第一种为三角剖分法,它在源-枢轴和枢轴-目标翻译模型中乘相应的翻译概率和词法权重,以得出新的源-目标短语表.第二种为转移法,利用翻译模型将源语言翻译成枢轴语言最后再翻译成目标语言来获得源语言到目标语言的句子,并且利用规则机器翻译的方法填补源语言到枢轴语言的数据空白.第三种为合成法,使用现有模型合成源语言到目标语言的可比语料.这三种方法都需要大量的监督信号及翻译性能较好的模型,且在翻译传递过程中易产生错误累积,导致最终的词典抽取结果不准确.
综上所述,针对汉-越双语词典的构建任务而言,汉-越平行语料稀缺且获取成本高昂,使得采用基于平行语料的方法难以得到较高的词典准确率.同时,基于种子词典的方法受限于低资源语言汉-越种子词典的规模及质量,其模型容易陷入局部最优,使得构建效果不太理想.基于对抗网路的方法在两种语言的差异性较小时,由其构建的双语词典准确率较高,但在语言差异性较大时词典准确率不高.基于枢轴的方法通常用于加强源语言到目标语言的对齐关系,再结合其他模型构建源语言和目标语言的词典.相关学者的研究表明了基于枢轴语言的可行性.
受到对抗网络和枢轴思想[11,14]的启发,同时考虑到汉语、英语、越南语单语语料比较丰富且具有汉-英、越-英双语词典,本文提出了一种基于英语枢轴的汉-越双语词典构建方法.该方法首先以英语作为枢轴语言,引入汉-英词典和越-英词典作为枢轴模型的弱监督信号,将汉语和越南语词向量均映射到英语词向量共享空间以减小汉语和越南语的语言差异性.然后将汉-英词向量和越-英词向量的映射建模为一个对抗游戏,通过平衡对抗网络学习汉-越的映射矩阵.最后通过相关抽取策略构建汉-越双语词典.本文将汉-英、越-英词典作为弱监督信号,避免了方法对平行语料的依赖.而且方法采用对抗网络模型,不需要任何汉-越监督信号.实验结果表明与现有方法相比本文方法明显地提升了汉-越双语词典的准确率.
2 基于英语枢轴的汉-越双语词典构建方法
目前自动构建汉-越词典的研究相对较少,大多方法需要平行语料或可比语料等监督信息的参与,费时且成本较高,且现有无监督模型对语言差异性较大的语言构建效果不佳[1,11].同时考虑到互联网中存在丰富的汉语、英语、越南语的单语语料以及汉-英、英-越双语词典.因此,本文提出了一种基于英语枢轴的汉-越双语词典的构建方法.首先通过基于种子词典的方法分别学习汉-英、越-英的映射矩阵Wxz和Wyz,然后在英语词向量共享空间中通过对抗网络进一步学习汉-越之间的映射矩阵Wxy,最后通过NN/CSLS方法[15]抽取汉-越词典.
基于英语枢轴的汉-越双语词典构建方法的基本思路可分为以下四个步骤:首先,分别对源语言、目标语言及中间语言的语料进行预处理;然后将这些已经处理好的语料分别表示为词向量;其次,以种子词典作为弱监督信号,并利用基于种子词典的方法分别学习汉-英及越-英的关系矩阵;最后,利用对抗网络进一步学习汉-越的映射矩阵,并通过不同抽取词典策略抽取词典.该构建方法的具体流程图如图1所示.

图1 基于英语枢轴的汉-越双语词典构建方法Fig.1 Construction method of Chinese-Vietnamese dictionary based on English pivot language
在图1中,在本文方法中源语言为汉语,目标语言为越南语,中间语言为英语.方法的具体步骤及分析如下:
1)对源语言、目标语言及中间语言的语料进行预处理.首先分别去掉汉语、越南语及英语的语料中无用的标点符号,然后分别下载这三种语言的停用词表以去掉停用词,最后对汉、越、英语料进行分词操作,将中文句子通过结巴分词工具做分词处理,将越南语句子和英语句子通过空格切分.最终得到预处理之后的汉语、越南语和英语的句子,并且统计词频与单词数.其中,n为源语言的单词数,m为目标语言的单词数,u为中间语言的单词数.{xi|i=1,2,…,n}为源语言单词集合,{yj|j=1,2,…,m}为目标语言单词集合,{zk|k=1,2,…,u}为中间语言单词集合.
2)通过Fasttext模型[16]分别学习汉语、英语、越南语的词向量空间,并将汉语、英语、越南语的单词表示为词向量v.词向量维度表示为d,源语言单词对应的词向量表示为{vx1,vx2,vx3,…,vxi},其中vxi∈Rd,i∈{1,2,…,n}.中间语言单词对应的词向量表示为{vz1,vz2,vz3,…,vzk},其中,vzk∈Rd,k∈{1,2,…,u}.同样,目标语言单词对应的词向量可以表示为{vy1,vy2,vy3,…,vyj},其中,vyj∈Rd,j∈{1,2,…,m}.
3)采用基于种子词典的方法分别学习汉-英的映射矩阵Wxz及越-英的映射矩阵Wyz.基于种子词典的双语词典构建方法的前提需要源语-目标语言的双语词典,然而对于汉语和越南语来说很难获取现成的汉-越双语词典,但汉-英及越-英双语词典很丰富且易获取.因此,我们借鉴枢轴的思想基于种子词典的方法来分别学习汉-英的映射矩阵Wxz及越-英的映射矩阵Wyz,将其映射到英语词向量的共享空间中.
获取5000个汉-英的单词对{xi,zi}i∈[1,5000]及5000个越-英的单词对{yi,zi}i∈[1,5000],作为弱监督信号,学习汉-英的线性映射关系矩阵Wxz及越-英的映射关系矩阵Wyz.映射关系矩阵Wxz和Wyz可由同一个模型通过设置不同的参数获得.该映射关系计算如公式(1)所示.
(1)
其中,d表示词向量的维度,X和Y是两个大小为d×n的平行词典对齐矩阵,包含了平行词典中单词的词向量,W为训练过程中源语言到目标语言的映射矩阵,大小为d×d,Md(R)表示d×d的实数矩阵.W*表示最小化源语言到目标语言距离的映射矩阵,这里分别对应汉-英的线性映射关系矩阵Wxz及越-英的映射关系矩阵Wyz.
在获取映射矩阵W后,对于任意一个未翻译的单词s,可以通过NN最近邻搜索方法到源语言对应目标语言的词翻译.根据映射后的空间余弦相似度来进行词对齐.任意源词s对应的翻译t定义如公式(2)所示.
t=arg maxtcos(Wxs,yt)
(2)
在此基础上,通过在映射矩阵W上增加正交约束条件实现了更好的效果.将问题转化为Procrustes问题,并将YXT进行奇异值分解(SVD)得到一个近似解,具体公式如公式(3)所示.
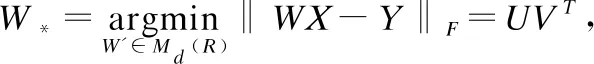
(3)
通过公式(3)可以得到源语言与目标语言距离最小化的汉-英的映射矩阵Wxz以及越-英的映射矩阵Wyz.
4)利用对抗网络进一步学习汉-越的映射矩阵Wxy.通过上述步骤将汉语及越南语的词向量均映射到英语词向量共享空间中,并把汉-英词向量和越-英词向量的映射建模为一个对抗游戏,通过平衡对抗网络最终学习到汉-越的映射矩阵Wxy.
在对抗网络中假设含有两个集合,一个集合为χ={Wxzvxi|i=1,2,…,n},表示汉语词向量映射到英语词向量空间的n个词向量的集合,可简化为χ={xi|i=1,2,…,n}.另一个集合为Ψ={Wyzvyj|j=1,2,…,m},表示目标语言越南语映射到英语词向量空间的m个目标语言的词向量的集合,可简化为Ψ={yj|j=1,2,…,m}.
对抗网络的模型分为两个部分,一个是生成器G,另一个是判别器D.判别器负责判别词向量来自源语言还是目标语言,它的目标是尽可能准确的判别词向量.生成器负责学习联系两个空间的线性映射,它的目标是让判别器无法判别词向量是来自源语言还是目标语言.生成器与判别器形成相互对抗的关系,从而提升生成器和判别器的性能.本文的对抗网络结构如图2所示.

图2 对抗网络的基本结构Fig.2 Basic structure of the adversarial network
在图2中,将汉-英的词向量表示为源语言词向量,将越-英的词向量表示为目标语言的词向量.方块的分布代表源语言的词分布,圆圈的分布代表目标语言的词分布.生成器G与判别器D形成相互对抗的关系,训练判别器来区分随机采样的元素是来自集合χ还是集合ψ,最终通过对抗网络学习得到源语言到目标语言的映射矩阵Wxy.综上,对抗网络的目标函数表示为minGmaxDV(D,G)的形式,其中函数V(D,G)表示为公式(4).
V(D,G)=Ey~py[logD(y)]+Ex~px[log(1-D(G(x)))]
(4)
在公式(1)中x是源语言词向量,px表示源语言词向量服从的分布,y是目标语言的词向量,Py表示目标语言词向量服从的分布.对抗网络中的判别器目标函数和生成器目标函数分别如公式(5)和公式(6)所示.
logPθD(s=0|yi)
(5)
logPθD(s=1|yi)
(6)
在训练对抗网络模型时,对于每一个输入样本需最小化判别器和生成器的目标函数,利用梯度下降方法更新各自的网络参数及映射矩阵W.然而,由于对抗网络的思想为对齐所有的词,并没考虑词频的高低,而词频低的词可能出现在不同语料库的上下文中.在这种情况下,通过对抗网络学习到的W的性能低于有监督学习性能.为了得到性能更好的映射矩阵W,本文通过由对抗训练学习到的W来构建合成并行词汇表,即考虑常用词的相互最近邻来确保获取一个具有较高质量的字典[17].最后通过对映射矩阵W添加正交约束限制进一步提升映射矩阵的质量及训练的稳定性.本文使用了更新规则来确保训练过程中映射矩阵W近似正交矩阵,如公式(7)所示.
W←(1+β)W-β(WWT)
(7)
Alexis等人的实验表明参数β为0.01时具有更好的效果,该更新方法使得每次更新后的矩阵都近似为正交矩阵.通过上述步骤可以获得一个源语言到目标语言的映射矩阵Wxy.
5)在英语词向量空间中抽取汉-越双语词典.将介绍两种抽取词典的方法:NN方法和CSLS方法.NN方法通过计算源语言词向量乘映射矩阵与目标语言的余弦距离,其计算如公式(2)所示.CSLS方法用于衡量两个单词之间(不同语言)的相似度.对每一个单词,通过CSLS方法可在另一语言中找到其K近邻,分别将源语言和目标语言用NT(s)和NS(t)表示,并定义源语言词向量为xs,目标语言词向量为yt,源语言到目标语言的距离为rT,目标语言到源语言的距离为rS.源语言到目标语言的距离通过公式(8)进行计算.
(8)
同上,用类似的方法计算rS,距离r可衡量每个单词的hubness.如果只考虑Wxs与yt的余弦关系,会产生hubness问题.为解决该问题,重新定义了CSLS距离如公式(9)所示.
CSLS(s,t)=2cos(Wxs,yt)-rT(Wxs)-rS(yt)
(9)
最后根据上述不同的抽取方法抽取相应的词向量构成汉-越词典.
3 实验结果与分析
3.1 实验数据
本文实验语料的获取主要利用网络爬虫技术从相关新闻网站中分别获取汉语、英语和越南语的单语语料数据,源语言为汉语,枢轴语言为英语,目标语言为越南语.实验语料的具体规模如表1所示.
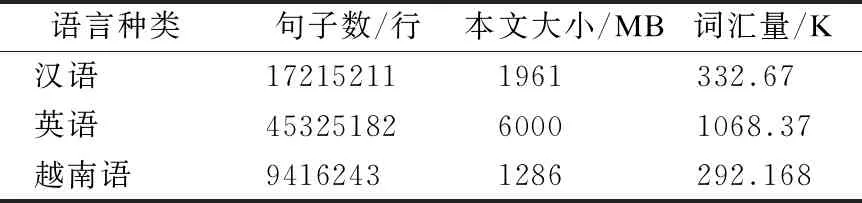
表1 实验语料规模Table 1 Size of corpus for experiment
为验证方法的有效性,本文将Alexis等人构建的汉-英词典和英-越词典作为验证词典.考虑到无法获取到可用的汉-越验证词典,重新构建了汉-越验证词典[11].具体步骤如下:第1步构建词表;第2步,通过一铭翻译平台(1)http://dmfy.emindsoft.com.cn/翻译该词表,将源语言单词进行翻译得到目标单词的多个候选翻译;第3步,将所有候选词逐个翻译为源语言单词,若候选词与源语言单词相同,则构建的词典为真实词典,若不同则舍弃该词对,进行下一个候选词的翻译,重复此步骤直到完成所有候选词的翻译;第4步,翻译完成所有的候选词后进行下一个源单词的翻译,重复第2步与第3步,直到翻译完所有的词表.通过上述方法构造的验证词典规模如表2所示.

表2 验证词典规模Table 2 Size of verification dictionary
本文将准确率P@N(前N个候选翻译的准确率)作为衡量双语词典好坏的评价指标.其中通过随机抽取验证词典的1.5K个源语言单词和对应的目标词,RT为抽取结果中单词的数量,T(wi)为抽取方法在单词wi上的抽取结果,d(wi)表示单词wi在词典中的翻译集合,具体计算公式(10)所示.
(10)
3.2 实验结果与分析
在实验中,利用Fasttext模型将汉语、越南语、英语单词转换为300维的词向量,汉-英、越-英的的映射矩阵分别为Wxz和Wyz,矩阵大小均为300×300,汉-英和越-英的种子词典分别为5000对.本文使用具有4096个隐藏层的多层感知机作为判别器,其激活函数为Leaky-ReLU.其中,Leaky-ReLU激活函数定义为:当输入值大于等于0时,输出值与输入值一致,当输入值小于0时,输出值为输入值与超参数leak的乘积.在本文中设置超参数leak=0.1,并在判别器预测中加入平滑系数s=0.3.使用随机梯度下降法对对抗网络的参数进行更新,批值大小为32,判别器和生成器的学习率均为0.1,衰减率均为0.8,对抗网络迭代次数100000次,迭代轮数10轮.每次实验的无监督验证标准降低时,学习率减半.本文将基于英语枢轴的汉-越双语词典构建方法记为EPAN.
为了验证枢轴语言的规模对本文方法准确率的影响,设置了该方法在不同英语语料规模下的实验,实验结果如图3所示.
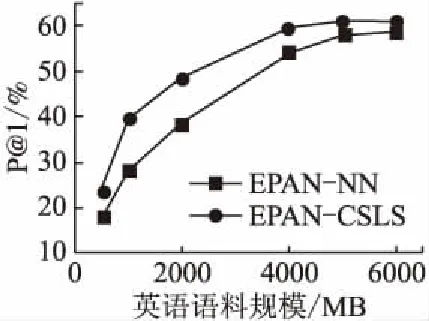
图3 本文方法在不同枢轴语料规模下的准确率Fig.3 Accuracy of the method in this paper at different pivotal corpus sizes
由图3可知,当将英语作为枢轴语言时,随着英语语料规模的增加,汉-越双语词典在P@1的准确率先上升后趋于平缓.当其规模为5000MB时本文方法的准确率曲线逐渐平滑,因此,后续实验将枢轴语料规模均设为5000MB.
接下来实验将本文方法与基于种子词典方法及基于对抗网络的方法进行对比,进一步验证本文方法的有效性.分别记录每组实验在P@1(即抽取1个候选词)时的准确率,实验结果如表3所示.
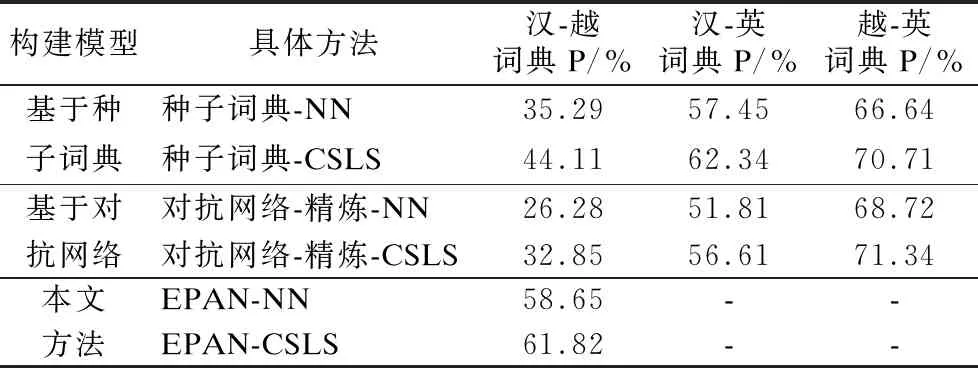
表3 本文方法与传统方法构建双语词典的准确率Table 3 Accuracy of our method and traditional methods in constructing bilingual dictionaries
分析表3的实验数据可知,基于对抗网络的方法效果接近甚至优于基于种子词典的方法的效果,验证了本文无监督模型选择标准的有效性.另外,直接采用基于种子词典的方法和基于对抗网络的方法构建汉-越双语词典的准确率较低,而本文方法下的两种抽取方法得到的汉-越词典准确率明显提高.该结果表明本文结合枢轴语言和对抗网络的方法有效提高了汉-越双语词典的准确率.
为验证方法的准确率与抽取的候选词个数之间的关系,得到汉-越词向量在英语枢轴共享空间中的具体映射情况,实验还比较了P@1、P@5和P@10的准确率.具体实验结果如表4所示.

表4 本文方法在不同P@N值下的准确率Table 4 Accuracy of the method in different P@N values
分析表4可知,本文方法的准确率均随候选词的增多而逐渐提高,候选词数量仅为1时便可获得较高的准确率,当候选词达到10个时,最高准确率可以达到80%以上.这进一步说明了不同语言在词向量空间中的同构性.
最后我们将本文方法与目前较为常用的自动构建双语词典的方法进行对比.本文利用Artetxe等人基于种子词典的迭代自学方法和Alexis等人基于对抗网络的方法以及莫媛媛等人基于平行语料的方法进行汉-越双语词典的构建实验,并与本文方法进行准确率的对比.实验选择在P@1的情况下进行准确率评价,具体实验结果如表5所示.

表5 不同方法下的汉-越词典准确率Table 5 Chinese-vietnamese dictio-nary accuracy for different methods
分析表5可知,由本文方法构建的汉-越双语词典的准确率明显优于其它三种方法.本文方法利用少量的汉-英,以及越-英监督信号,便可很好地将汉语、越南语词向量对齐到英语词向量空间,在缺少高质量大规模汉-越监督信号时,通过无监督模型选择标准能够很好的抽取汉-越词典.
4 结 论
为了提升自动构建汉-越词典的准确率,本文提出了一种基于英语枢轴的汉-越词典构建方法.在使用更少的监督信号以及不使用汉-越双语词典的情况下,本文方法能够有效的提高汉-越词典的准确率.同时也证明了在构建低资源语言词典这个任务中借鉴枢轴与对抗网络的思想可以使汉-越双语词典的构建方法具有更好的性能.下一步将继续研究词典在无监督神经机器翻译中的应用.
