一种粒度融合的新闻文本主题分类模型
2020-12-10杨春霞秦家鹏
杨春霞,李 锐,秦家鹏
1(南京信息工程大学 自动化学院,南京210044) 2(江苏省大数据分析技术重点实验室,南京 210044)
1 引 言
新闻文本的主题分类是当前信息爆炸时代的热点问题之一,也是自然语言处理的关键技术之一.针对每天产生的数以万计的新闻文本,如何能准确的对产生文本的主题进行分类,在用户推荐系统等领域中都有着重要作用.
文本分类是自然语言处理最经典的任务场景之一,文本分类首先要对相关文本进行文本处理.传统的文本处理方法有基于字符串匹配、TF-IDF等方法.随着近年来深度学习的兴起Embedding成了自然语言处理最受欢迎的文本处理方法,目前由谷歌提出的Word2Vec的Word Embedding方法由于能够较好的体现上下文信息,因此被大量的应用到自然语言任务中.Kim[1]利用CNN在Word2Vec词向量上进行特征提取,并在多个英文分类任务上进行实验.黄磊[2]等利用Word2Vec进行词向量训练并在大规模中文新闻分类任务中使用BiLSTM进行文本分类.姜恬静等[3]使用Word Embedding结合卷积和长短期记忆神经网络,通过遍历全文捕获全局信息对中文文本进行分类.而文本通常由字符组成,许多较为细腻的语义信息被蕴含在字符中,因此近年来自然语言处理中Char Embedding的方法被越来越多的人研究.Santos等[4]提出了一种基于Char Embedding的词性标注的方法,并证明了Char Embedding可以达到最新水平.Zhang[5]等提出了一种独立于语言的Char Embedding CNN模型,并在40多种混合语言信息分类任务中得到了较好的效果.Zhu等[6]用Char Embedding结合自注意力机制、卷积神经网络、门控递归单元捕获相邻字符和句子的上下文信息,并在多个数据集上进行测试得到较好的效果.
本文结合Word Embedding与Char Embedding提出一种基于字粒度与词粒度融合的新闻文本主题分类模型.通过字嵌入、词嵌入将字词转换为向量的形式,并将词中所包含字符的字向量与该词向量进行融合,构建出既包含字符属性又包含词属性的向量,再将这些向量构建成包含整个新闻文本信息特征的矩阵.然后设计卷积结构从特征矩阵中提取有效信息对新闻文本进行主题分类.由于中文独特的句法关系,文本中每个字符有其细腻的语义信息.而词语中也包含了大量的实体信息和更好的上下文信息.因此本文提出粒度融合模型能够更好的理解中文文本的语义、实体信息,同时兼顾文本上下文信息,从而获得较好的主题分类结果.
2 相关研究基础
2.1 新闻文本主题分类
新闻文本主题分类是指通过自然语言处理技术将整篇文章蕴含的主题类型进行分类.其主要过程有文本处理、模型构建、特征提取、分类、结果评估.目前有两种主流的新闻文本主题分类方法.一是基于BERT[7]、XLNET[8]这种龙骨级模型的方法,这类方法虽然有很好的效果,但由于模型过为复杂,需要非常大的算力和庞大的数据源且模型训练时间较长,故本文并未选用这种方法.二是基于词向量设计模型并提取文本特征,根据文本特征对新闻文本主题进行分类,这类方法也能达到非常好的分类效果且无需大量计算资源,故本文选用此类方法.
2.2 Word2Vec
Word2Vec是谷歌提出的一种产生词向量的模型,其通常分为CBOW与Skip-Gram两种训练模型.CBOW是根据某一词语上下文相关词向量输出该词的词向量,Skip-Gram是根据某一词语的词向量输出其上下文词的向量.本文选取CBOW模型作为实验词向量训练模型.其原理如图1所示.

图1 CBOW模型Fig.1 CBOW model
从图1中可以看出CBOW模型包括输入层、投影层和输出层.CBOW模型根据选定词w选定一个上下文窗口(图1所示选定窗口为2),将窗口中上下文词向量w(t-2)、w(t-1)、w(t+1)、w(t+2)输入至投影层,这些上下文词向量会被投影成一个向量,然后将投影层输出向量输入softmax分类层,通过softmax预测是否是当前词w,并将投影向量作为词w的词向量.
该模型的学习目标是最大化对数似然函数,计算公式如公式(1)所示.

(1)
公式(1)中C是文本库中所有词语集合,w是选定词,Context(w)是选定词w的上下文词语,模型通过随机梯度上升法对词w的词向量进行训练更新.
3 模型实现
为了更好的将文本中细腻的语义信息与上下文信息进行融合,提高新闻文本主题分类准确率,本文提出了一种基于粒度融合的卷积神经网络模型.其结构包括:词粒度输入、字符粒度输入、字词融合结构、卷积结构、拼接融合结构、softmax分类层,模型结构如图2所示.
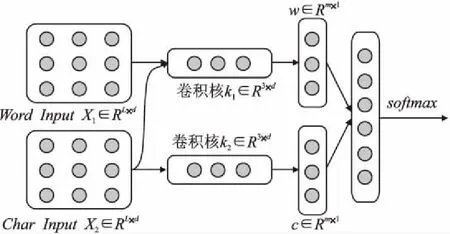
图2 粒度融合模型Fig.2 Granular fusion model
本文提出的模型主要呈一个流式结构,主要包括了4个部分内容:
1)向量输入:从图2中可以看到,向量输入部分有两个输入,其中Word InputX1∈RL×d是词粒度的向量输入,Char InputX2∈RL×d,是字符粒度的向量输入,L是分词、字后的序列长度,d是嵌入之后词向量、字向量的深度.
2)字词粒度融合:本文的字词粒度融合通过字、词、字符位置信息进行不同粒度的融合,融合过程如图3所示.
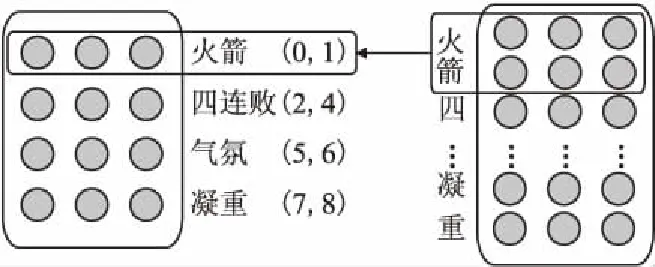
图3 粒度融合过程Fig.3 Granular fusion process
在图3中,以“火箭/四连败/气氛/凝重”为例,通过jieba分词并记录分词结果中每个词首末字符在本句话中的位置信息.如图3中“火箭(0,1)”,其中0代表“火”处于本句话第0个位置,1代表“箭”处于本句话中第1个位置.在融合过程中通过这些位置信息将每个词包含的所有字符的向量相加,再加上词向量本身得到融合后的向量.通过不同粒度的向量叠加,这样输入的特征矩阵中就能够包含字、词两种粒度属性的特征,这使得卷积层能够更好的在特征矩阵中提取到文本中的有效信息.其计算公式如公式(2)、公式(3)、公式(4)所示.
(2)
(3)
(4)

3)卷积特征提取:虽然融合后的向量已经蕴含了许多信息,但由于信息过于冗余我们无法直接使用这些向量进行主题分类.因此本文使用k∈R3×d大小的卷积进行窗口滑动提取特征,以去除冗余信息并获得一定的上下文信息与语义信息.为了得到多个卷积结果以进一步提升主题分类的准确率,我们同时对字符输入矩阵与融合后的词输入矩阵进行卷积,这样会在提取特征后得到两个相应的特征向量.计算公式如公式(5)、公式(6)所示.
w=Convk1(W1,X1)+b1
(5)
c=Convk2(W2,X2)+b2
(6)
公式(5)、公式(6)中Conv是卷积运算函数,k1、k2分别是词输入矩阵与字符输入矩阵的卷积核代称,W1、W2为卷积权重矩阵,b1、b2为偏置项.卷积后得到字符粒度与词粒度的特征向量,w∈Rm×1、c∈Rm×1是卷积后大小为m×1包含新闻文本特征的向量.
4)分类器:模型的最后将经过卷积提取的词粒度与字符粒度特征向量拼接融合形成拼接向量,再将该向量经由一个全连接层压缩至主题类别个数相同维度,然后使用softmax对文本的主题进行分类,softmax具体计算公式如公式(7)所示.
(7)
公式(7)中Si为第i个主题类别的概率得分,mi为模型输出向量第i维的值.分类器输出维度与主题类别个数相同的概率向量,每一个维度对应一个主题类别,我们将分类器所得最大概率维度对应的主题类别认定为分类主题结果.
4 实 验
4.1 实验数据与实验平台
本文使用了2个公开数据集对提出的字词粒度融合模型进行性能测试,包括THUCNews新闻文本数据集、搜狗新闻数据集.
THUCNews新闻文本数据集是由清华大学公开的大规模新闻文本数据集,THUCNews是根据新浪新闻RSS订阅频道2005-2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,共有14个新闻类别.本文选用其中10个类别的样本分别为:体育、财经、房产、家居、教育、科技、时尚、时政、游戏、娱乐.每个类别都选取5000条训练样本,500条验证样本,1000条测试样本.

表1 实验平台设置Table 1 Experimental platform settings
搜狗新闻数据集是由Sogou Lab提供的国内、国际2012年6月-7月期间体育,社会,娱乐等18个频道的新闻数据.本文选用其中9个类别样本分别为:娱乐、房地产、旅游、科技、体育、健康、教育、汽车、文化.每个类别都选取2500条训练样本,500条测试样本.
本文实验环境配置如表1所示.
4.2 模型超参数设置与模型复杂性分析
本文采用Adam作为模型优化器,使用mini-Batch进行批量训练.模型主要超参数如表2所示.

表2 超参数设置Table 2 Hyperparameter setting
本文模型总参数个数为1.42M,与BERT(110M、340M)等复杂的模型参数量相比非常精简.本文模型在GTX1080ti的GPU上每批次的训练时间为0.042s,在运行时间上也有着一定的优势.本文模型总复杂性较低,算力要求适中,在复杂性上具有很好的优势.
4.3 实验结果与分析
为了验证本文提出的基于粒度融合模型的有效性,本文选择了多个经典模型与多个目前在THUCNews新闻文本数据集、搜狗新闻数据集上效果较好的先进模型进行对比.对比模型包括:单层CNN、单层LSTM、单层NLSTM、CNN+NLSTM、Attention LSTM[9]、Attention BiLSTM[10]、BiLSTM+max-pooling[11]、Attention+CNLSTM[12].测试实验对比结果如表3所示.
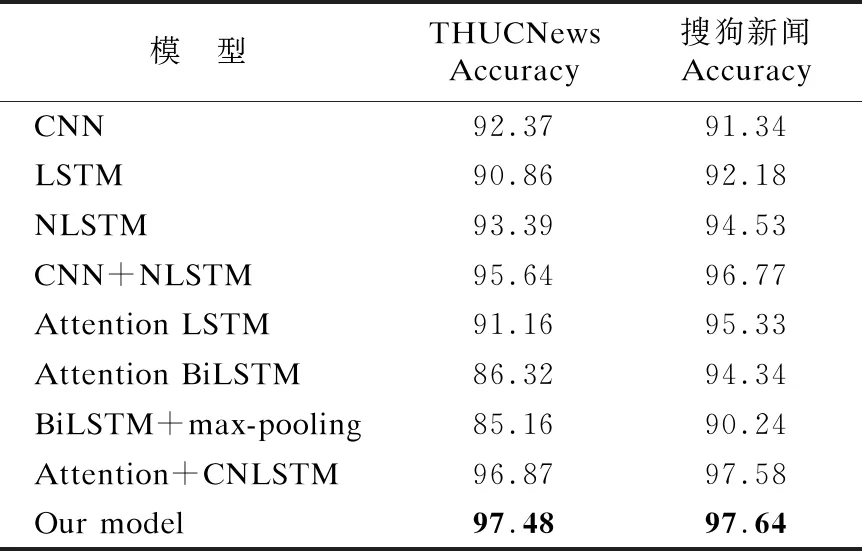
表3 不同模型的分类结果Table 3 Classification results of different models
从表3中可以看到,本文提出的模型在两个数据集上都能够得到较为领先的准确率.从CNN与本文模型对比可以看出,本文模型在使用了粒度融合后能够大幅度的提升模型的准确率.同时本文提出的字、词粒度融合模型通过与Attention BiLSTM、Attention+CNLSTM等最新模型的对比结果可以看出,不同粒度的融合确实能够更有效的提取出文本中的有效信息.
本文将THUCNews新闻文本数据集每个主题类别测试实验中的3个评价指标:精确率(precision)、recall值、f1-score分别输出,3个评价指标的结果如表4所示.
从表4中可以看出除家居主题类新闻外其余主题类别的3项评价指标均高于0.95,且各个类别的3项指标都达到了相当高的水平.

表4 各类别3项评价指标Table 4 Three evaluation indicators for each category
本文将THUCNews新闻文本数据集10个主题类别的分类测试结果的混淆矩阵进行统计,结果如表5所示.

表5 各类别分类结果混淆矩阵Table 5 Classification result confusion matrix
从表5中可以看到除家居类新闻外,其余每个主题类别(每个类别1000条新闻文本)被本文提出模型分类后分到正确类别中均超过950条,家居类别为913条.各主题类别分错类的情况非常少,其中体育、财经类的主题更是接近100%的精确率.
结合表3、表4、表5上的数据看,本文提出的字、词粒度融合模型,在结合了字符粒度细腻的语义信息、词粒度的实体信息与上下文信息后确实能更好的对文本信息进行提取并且在绝大部分类别下都有着非常优秀的主题分类效果.
5 结束语
本文将新闻文本进行分字、分词并使用Word2Vec进行嵌入.对嵌入后的字向量、词向量利用字-词的包含关系进行不同粒度上的融合.通过粒度融合将字符粒度中细腻的语义信息与词粒度中的实体信息有效的结合,在此基础上通过卷积神经网络进行特征提取减少了文本中的冗余信息.在公开数据集THUCNews、搜狗新闻上进行模型性能测试,实验表明,本文提出的模型能够有效的提升中文新闻文本主题分类任务的准确率.但通过研究发现,本文提出的模型在语义特征提取时采用的CNN结构存在一定的无序性缺陷,CNN并不能理解文字中每个字符、词语的顺序输入关系以及字符、词语之间的关注关系,因此本文下一步研究将尝试解决上述问题.
